Web krypende Med Python

web crawling er en kraftig teknikk for å samle inn data fra nettet ved å finne Alle Nettadressene for ett eller flere domener. Python har flere populære web crawling biblioteker og rammer.
i denne artikkelen vil vi først introdusere forskjellige krypteringsstrategier og brukstilfeller. Da vil vi bygge en enkel web crawler fra bunnen Av I Python ved hjelp av to biblioteker: forespørsler Og Vakker Suppe. Deretter vil vi se hvorfor det er bedre å bruke et webkrypende rammeverk som Scrapy. Til slutt vil vi bygge et eksempel crawler Med Scrapy å samle film metadata Fra IMDb og se Hvordan Scrapy skalerer til nettsteder med flere millioner sider.
Hva er en web crawler?
web crawling og web scraping er to forskjellige, men relaterte begreper. Web crawling er en del av nettskraping, finner crawler logikk Nettadresser som skal behandles av skraperen kode.
en søkerobot starter med en Liste Over Nettadresser som skal besøkes, kalt frøet. For HVER URL finner søkeroboten koblinger I HTML, filtrerer disse koblingene basert på noen kriterier og legger til de nye koblingene i en kø. ALL HTML eller noen spesifikk informasjon er hentet for å bli behandlet av en annen rørledning.
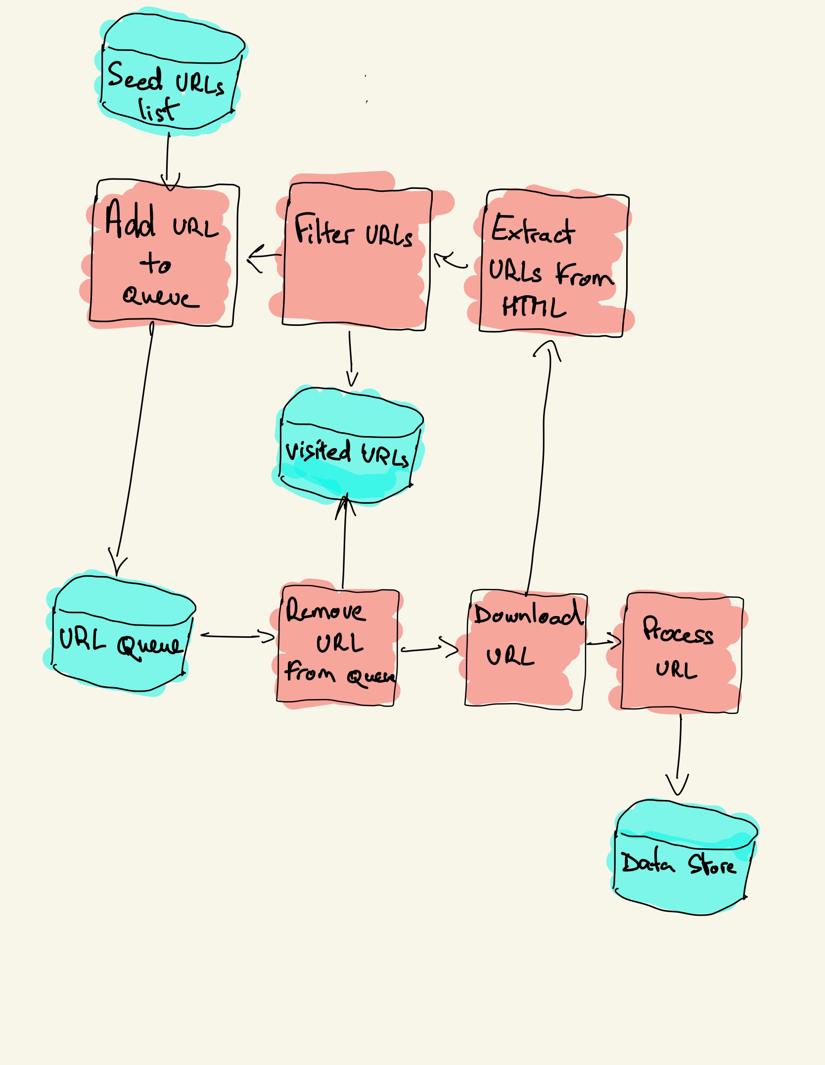
web crawling strategies
i praksis besøker web crawlere bare et delsett av sider avhengig av crawlerbudsjettet, som kan være maksimalt antall sider per domene, dybde eller kjøretid.
Mest populære nettsteder gir en roboter.txt-fil for å indikere hvilke områder av nettstedet som ikke er tillatt å gjennomsøke av hver brukeragent. Det motsatte av robots-filen er sitemap.xml-fil, som viser sidene som kan gjennomsøkes.
Populære web crawler bruk tilfeller inkluderer:
- Søkemotorer (Googlebot, Bingbot, Yandex Bot…) samle ALL HTML for en betydelig del av Nettet. Disse dataene er indeksert for å gjøre det søkbart.
- SEO analytics verktøy på toppen av å samle HTML også samle metadata som responstid, responsstatus for å oppdage ødelagte sider og koblingene mellom ulike domener for å samle tilbakekoblinger.
- Pris overvåking verktøy gjennomgå e-handel nettsteder for å finne produktsider og trekke ut metadata, spesielt prisen. Produktsider blir deretter periodisk revidert.
- Common Crawl opprettholder et åpent repository av web crawl data. For eksempel inneholder arkivet fra oktober 2020 2,71 milliarder nettsider.
deretter vil vi sammenligne tre forskjellige strategier for å bygge en web crawler I Python. Først bruker du bare standardbiblioteker, deretter tredjepartsbiblioteker for Å LAGE HTTP-forespørsler og analysere HTML og til slutt et rammeverk for webkryptering.
Bygge en enkel web crawler I Python fra scratch
for å bygge en enkel web crawler I Python trenger vi minst ett bibliotek for å laste NED HTML fra EN URL og EN HTML parsing bibliotek for å trekke ut koblinger. Python gir standard biblioteker urllib for Å LAGE HTTP-forespørsler og html.parser for analyse AV HTML. Et Eksempel Python crawler bygget bare med standard biblioteker kan bli funnet På Github.
Standard Python-biblioteker for forespørsler og HTML-parsing er ikke veldig utviklervennlige. Andre populære biblioteker som forespørsler, merket SOM HTTP for mennesker, og Vakker Suppe gir en bedre utvikleropplevelse.
hvis du vil lære mer, kan du sjekke denne veiledningen om den beste Python HTTP-klienten.
du kan installere de to bibliotekene lokalt.
pip install requests bs4en grunnleggende crawler kan bygges etter det forrige arkitekturdiagrammet.
import loggingfrom urllib.parse import urljoinimport requestsfrom bs4 import BeautifulSouplogging.basicConfig( format='%(asctime)s %(levelname)s:%(message)s', level=logging.INFO)class Crawler: def __init__(self, urls=): self.visited_urls = self.urls_to_visit = urls def download_url(self, url): return requests.get(url).text def get_linked_urls(self, url, html): soup = BeautifulSoup(html, 'html.parser') for link in soup.find_all('a'): path = link.get('href') if path and path.startswith('/'): path = urljoin(url, path) yield path def add_url_to_visit(self, url): if url not in self.visited_urls and url not in self.urls_to_visit: self.urls_to_visit.append(url) def crawl(self, url): html = self.download_url(url) for url in self.get_linked_urls(url, html): self.add_url_to_visit(url) def run(self): while self.urls_to_visit: url = self.urls_to_visit.pop(0) logging.info(f'Crawling: {url}') try: self.crawl(url) except Exception: logging.exception(f'Failed to crawl: {url}') finally: self.visited_urls.append(url)if __name__ == '__main__': Crawler(urls=).run()koden ovenfor definerer En Crawler klasse med hjelpemetoder for å laste ned_url ved hjelp av forespørsler biblioteket, get_linked_urls ved Hjelp Av Den Vakre Suppe bibliotek og add_url_to_visit å filtrere Nettadresser. Nettadressene som skal besøkes og de besøkte Nettadressene lagres i to separate lister. Du kan kjøre crawler på terminalen.
python crawler.pysøkeroboten logger en linje for hver besøkte URL.
2020-12-04 18:10:10,737 INFO:Crawling: https://www.imdb.com/2020-12-04 18:10:11,599 INFO:Crawling: https://www.imdb.com/?ref_=nv_home2020-12-04 18:10:12,868 INFO:Crawling: https://www.imdb.com/calendar/?ref_=nv_mv_cal2020-12-04 18:10:13,526 INFO:Crawling: https://www.imdb.com/list/ls016522954/?ref_=nv_tvv_dvd2020-12-04 18:10:19,174 INFO:Crawling: https://www.imdb.com/chart/top/?ref_=nv_mv_2502020-12-04 18:10:20,624 INFO:Crawling: https://www.imdb.com/chart/moviemeter/?ref_=nv_mv_mpm2020-12-04 18:10:21,556 INFO:Crawling: https://www.imdb.com/feature/genre/?ref_=nv_ch_grkoden er veldig enkel, men det er mange ytelses-og bruksproblemer å løse før du lykkes med å gjennomgå et komplett nettsted.
- søkeroboten er treg og støtter ingen parallellitet. Som det fremgår av tidsstemplene, tar det omtrent ett sekund å gjennomgå hver URL. Hver gang søkeroboten gjør en forespørsel, venter den på at forespørselen skal løses, og det gjøres ikke noe arbeid i mellom.
- last NED URL-logikken har ingen prøvemekanisme, URL-køen er ikke en ekte kø og ikke veldig effektiv med et høyt antall Nettadresser.
- koblingsutvinningslogikken støtter ikke standardisering Av Nettadresser ved å fjerne url – spørringsstrengparametere, håndterer Ikke Nettadresser som starter med#, støtter ikke filtrering Av Nettadresser etter domene eller filtrering av forespørsler til statiske filer.
- robotsøkeprogrammet identifiserer seg ikke og ignorerer robotene.txt-fil.
Neste, vil Vi se hvordan Scrapy gir alle disse funksjonene og gjør det enkelt å utvide for dine egendefinerte kravlesøk.
web krypende Med Scrapy
Scrapy er den mest populære web skraping Og gjennomgang Python rammeverk med 40k stjerner På Github. En av fordelene Med Scrapy er at forespørsler er planlagt og håndtert asynkront. Dette betyr At Scrapy kan sende en annen forespørsel før den forrige er fullført eller gjøre noe annet arbeid i mellom. Scrapy kan håndtere mange samtidige forespørsler, men kan også konfigureres til å respektere nettsteder med egendefinerte innstillinger, som vi vil se senere.
Scrapy har en flerkomponentarkitektur. Normalt vil du implementere minst to forskjellige klasser: Spider og Pipeline. Nettskraping kan betraktes som en ETL hvor du trekker ut data fra nettet og laster det til din egen lagring. Edderkopper trekke ut data og rørledninger laste den inn i lagring. Transformasjon kan skje både i edderkopper og rørledninger, men jeg anbefaler at du setter en tilpasset Skrapeledning for å transformere hvert element uavhengig av hverandre. På denne måten, unnlater å behandle et element har ingen effekt på andre elementer.
på toppen av alt dette kan du legge til spider og downloader middlewares i mellom komponenter som det kan ses i diagrammet nedenfor.
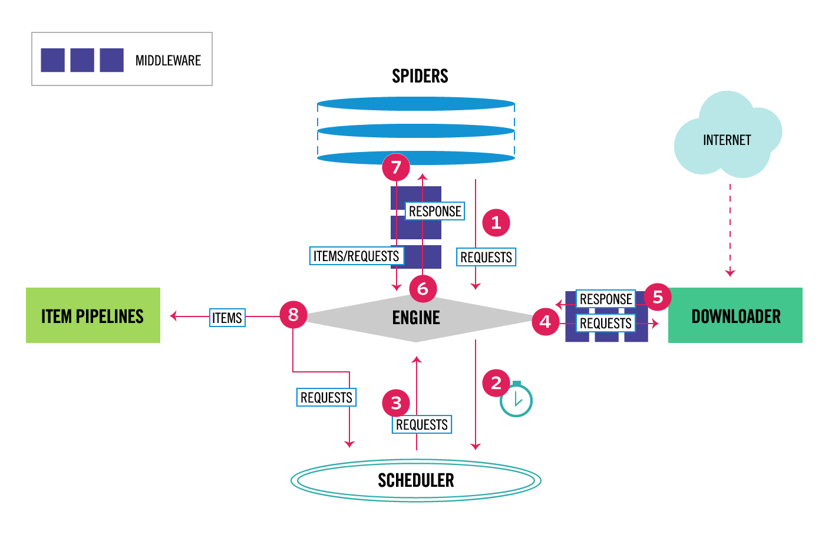
Scrappy Architecture Overview
hvis Du har brukt Scrappy før, vet du at en webskraper er definert som en klasse som arver fra base Spider-klassen og implementerer en analysemetode for å håndtere hvert svar. Hvis Du er ny På Scrapy, kan du lese denne artikkelen for enkel skraping med Scrapy.
from scrapy.spiders import Spiderclass ImdbSpider(Spider): name = 'imdb' allowed_domains = start_urls = def parse(self, response): passScrapy gir også flere generiske edderkopp klasser: CrawlSpider, XMLFeedSpider, CSVFeedSpider Og SitemapSpider. CrawlSpider-klassen arver fra base Spider-klassen og gir et ekstra regelattributt for å definere hvordan man gjennomsøker et nettsted. Hver regel bruker En LinkExtractor for å angi hvilke koblinger som er hentet fra hver side. Deretter vil vi se hvordan du bruker hver enkelt av dem ved å bygge en crawler For IMDb, Internet Movie Database.
Bygge et Eksempel Scrapy crawler For IMDb
før jeg prøvde Å krype IMDb, sjekket Jeg IMDb roboter.txt-fil for å se hvilke URL-baner som er tillatt. Robots-filen forbyr bare 26 baner for alle brukeragenter. Scrapy leser robotene.txt-filen på forhånd og respekterer den når ROBOTSTXT_OBEY-innstillingen er satt til true. Dette er tilfelle for alle prosjekter generert med Scrapy kommandoen startproject.
scrapy startproject scrapy_crawlerdenne kommandoen oppretter et nytt prosjekt med Standardmappestruktur For Scrapy-prosjekt.
scrapy_crawler/├── scrapy.cfg└── scrapy_crawler ├── __init__.py ├── items.py ├── middlewares.py ├── pipelines.py ├── settings.py └── spiders ├── __init__.pyDeretter kan du lage en edderkopp i scrapy_crawler/spiders/imdb.py med en regel for å trekke ut alle koblinger.
from scrapy.spiders import CrawlSpider, Rulefrom scrapy.linkextractors import LinkExtractorclass ImdbCrawler(CrawlSpider): name = 'imdb' allowed_domains = start_urls = rules = (Rule(LinkExtractor()),)du kan starte crawleren i terminalen.
scrapy crawl imdb --logfile imdb.logDu vil få mange logger, inkludert en logg for hver forespørsel. Utforske loggene jeg la merke til at selv om vi satte allowed_domains til bare å gjennomsøke nettsider under https://www.imdb.com, var det forespørsler til eksterne domener, for eksempel amazon.com.
2020-12-06 12:25:18 DEBUG: Redirecting (302) to <GET https://www.amazon.com/b/?&node=5160028011&ref_=ft_iba> from <GET (https://www.imdb.com/whitelist-offsite?url=https%3A%2F%2Fwww.amazon.com%2Fb%2F%3F%26node%3D5160028011%26ref_%3Dft_iba&page-action=ft-iba&ref=ft_iba)>IMDb omdirigerer fra Url-baner under hviteliste-offsite og hviteliste til eksterne domener. Det er et åpent Scrapy Github-problem som viser at eksterne Nettadresser ikke blir filtrert ut når OffsiteMiddleware brukes før RedirectMiddleware. For å løse dette problemet, kan vi konfigurere link extractor å nekte Nettadresser som starter med to regulære uttrykk.
class ImdbCrawler(CrawlSpider): name = 'imdb' allowed_domains = start_urls = rules = ( Rule(LinkExtractor( deny=, )), )Rule og LinkExtractor klasser støtter flere argumenter for å filtrere Ut Nettadresser. Du kan for eksempel ignorere bestemte URL-utvidelser og redusere antallet dupliserte Url-Adresser ved å sortere spørringsstrenger. Hvis du ikke finner et bestemt argument for brukstilfellet ditt, kan du sende en egendefinert funksjon til process_links I LinkExtractor eller process_values i Rule.
For Eksempel Har IMDb to Forskjellige Nettadresser med samme innhold.
https://www.imdb.com/navn / nm1156914/
https://www.imdb.com/navn / nm1156914/?mode=desktop & ref_=m_ft_dsk
for å begrense antall krypterte Nettadresser, kan vi fjerne alle spørringsstrenger fra Nettadresser med url_query_cleaner-funksjonen fra w3lib-biblioteket og bruke den i process_links.
from w3lib.url import url_query_cleanerdef process_links(links): for link in links: link.url = url_query_cleaner(link.url) yield linkclass ImdbCrawler(CrawlSpider): name = 'imdb' allowed_domains = start_urls = rules = ( Rule(LinkExtractor( deny=, ), process_links=process_links), )Nå som vi har begrenset antall forespørsler om å behandle, kan vi legge til en parse_item-metode for å trekke ut data fra hver side og sende den til en rørledning for å lagre den. For eksempel kan vi enten trekke ut hele svaret.tekst for å behandle den i en annen rørledning eller velg HTML-metadataene. For å velge HTML metadata i header tag vi kan kode våre Egne XPATHs, men jeg synes det er bedre å bruke et bibliotek, extruct, som trekker ut alle metadata fra EN HTML-side. Du kan installere den med pip install extract.
import refrom scrapy.linkextractors import LinkExtractorfrom scrapy.spiders import CrawlSpider, Rulefrom w3lib.url import url_query_cleanerimport extructdef process_links(links): for link in links: link.url = url_query_cleaner(link.url) yield linkclass ImdbCrawler(CrawlSpider): name = 'imdb' allowed_domains = start_urls = rules = ( Rule( LinkExtractor( deny=, ), process_links=process_links, callback='parse_item', follow=True ), ) def parse_item(self, response): return { 'url': response.url, 'metadata': extruct.extract( response.text, response.url, syntaxes= ), }jeg setter følg-attributtet Til True slik At Scrapy fortsatt følger alle koblinger fra hvert svar, selv om vi ga en tilpasset analysemetode. Jeg konfigurerte også extruct for å trekke ut Bare Åpne Grafmetadata og JSON-LD, en populær metode for koding av koblede data ved HJELP AV JSON på Nettet, brukt Av IMDb. Du kan kjøre crawler og lagre elementer I json linjer format til en fil.
scrapy crawl imdb --logfile imdb.log -o imdb.jl -t jsonlinesutdatafilen imdb.jl inneholder en linje for hvert kravlesøkt element. For eksempel ser de utpakkede Åpne Grafmetadataene for en film tatt fra <meta> – kodene i HTML slik ut.
{ "url": "http://www.imdb.com/title/tt2442560/", "metadata": {"opengraph": , , , , , ] }]}}JSON-LD for et enkelt element er for lang til å bli inkludert i artikkelen, her er et eksempel på Hva Scripy trekker ut fra <script type= «application/ld + json» > taggen.
"json-ld": , "contentRating": "TV-MA", "actor": ... }]Utforske loggene, la jeg merke til et annet vanlig problem med crawlere. Ved å klikke på filtre i rekkefølge, genererer søkeroboten Nettadresser med samme innhold, bare at filtrene ble brukt i en annen rekkefølge.
https://www.imdb.com/navn / nm2900465 / videogallery/content_type-trailer/related_titles-tt0479468
https://www.imdb.com/navn / nm2900465 / videogallery/related_titles-tt0479468 / content_type-trailer
Lange filter-Og Søkeadresser er et vanskelig problem som delvis kan løses ved å begrense Lengden På Nettadresser med En Skrapinnstilling, URLLENGTH_LIMIT.
jeg brukte IMDb som et eksempel for å vise grunnleggende om å bygge en web crawler I Python. Jeg lot ikke crawleren løpe lenge, da jeg ikke hadde et bestemt brukstilfelle for dataene. I tilfelle du trenger spesifikke data Fra IMDb, kan Du sjekke IMDb Datasett prosjekt som gir en daglig eksport Av IMDb data Og IMDbPY, En Python pakke for å hente og administrere data.
nettkryp i skala
hvis du prøver å gjennomsøke et stort nettsted Som IMDb, med over 45 MILLIONER sider basert På Google, er det viktig å gjennomsøke ansvarlig ved å konfigurere følgende innstillinger. Du kan identifisere søkeroboten din og oppgi kontaktinformasjon i BOT_NAME-innstillingen. For å begrense trykket du legger på nettstedets servere kan DU øke DOWNLOAD_DELAY, begrense CONCURRENT_REQUESTS_PER_DOMAIN eller angi AUTOTHROTTLE_ENABLED som vil tilpasse disse innstillingene dynamisk basert på responstider fra serveren.
Legg Merke til At Scrapy-kravlesøk er optimalisert for et enkelt domene som standard. Hvis du gjennomsøker flere domener, må du kontrollere disse innstillingene for å optimalisere for brede kravlesøk, inkludert å endre standard gjennomsøkingsrekkefølge fra dybde-først til pust-først. Hvis du vil begrense gjennomsøkingsbudsjettet, kan du begrense antall forespørsler med innstillingen CLOSESPIDER_PAGECOUNT for utvidelsen lukk spider.
Med standardinnstillingene kryper Scrapy rundt 600 sider per minutt for et nettsted Som IMDb. For å krype 45M sider vil det ta mer enn 50 dager for en enkelt robot. Hvis du trenger å gjennomgå flere nettsteder, kan det være bedre å starte separate crawlere for hver stor nettside eller gruppe nettsteder. Hvis du er interessert i distribuerte webkryp, kan du lese hvordan en utvikler gjennomsøkte 250m sider Med Python på 40 timer ved hjelp av 20 Amazon EC2-maskinforekomster.
i noen tilfeller kan du støte på nettsteder som krever At Du kjører JavaScript-kode for å gjengi ALL HTML. Unnlater å gjøre det, og du kan ikke samle alle koblinger på nettstedet. Fordi i dag er det veldig vanlig for nettsteder å gjengi innhold dynamisk i nettleseren, skrev jeg En Scrappy mellomvare for å gjengi JavaScript-sider ved Hjelp Av ScrapingBee ‘ S API.
Konklusjon
vi sammenlignet koden Til En Python-crawler ved hjelp av tredjepartsbiblioteker for å laste Ned Nettadresser og analysere HTML med en crawler bygget ved hjelp av et populært webkrypingsramme. Scrapy er en svært performant web crawling rammeverk og det er lett å utvide med den egendefinerte koden. Men du trenger å vite alle stedene hvor du kan koble din egen kode og innstillingene for hver komponent.
Konfigurering Av Scrapy riktig blir enda viktigere når du gjennomsøker nettsteder med millioner av sider. Hvis du vil lære mer om webkryping, foreslår jeg at du velger et populært nettsted og prøver å krype det. Du vil definitivt løpe inn i nye problemer, noe som gjør emnet fascinerende!