Web crawling cu Python

crawling-ul Web este o tehnică puternică de colectare a datelor de pe web prin găsirea tuturor adreselor URL pentru unul sau mai multe domenii. Python are mai multe biblioteci și cadre populare de crawling web.
în acest articol, vom introduce mai întâi diferite strategii de crawling și cazuri de utilizare. Apoi vom construi un simplu crawler web de la zero în Python folosind două biblioteci: cereri și supă frumoasă. În continuare, vom vedea de ce este mai bine să folosiți un cadru de crawling web precum Scrapy. În cele din urmă, vom construi un exemplu de crawler cu Scrapy pentru a colecta metadate de film de la IMDb și a vedea cum scale Scrapy la site-uri cu mai multe milioane de pagini.
ce este un crawler web?
web crawling și Web scraping sunt două concepte diferite, dar conexe. Crawling-ul Web este o componentă a razuirii web, logica crawler găsește adresele URL care trebuie procesate de codul scraper.
un crawler web începe cu o listă de adrese URL de vizitat, numită seed. Pentru fiecare URL, crawlerul găsește linkuri în HTML, filtrează aceste linkuri pe baza unor criterii și adaugă noile linkuri la o coadă. Toate HTML sau unele informații specifice sunt extrase pentru a fi procesate de o conductă diferită.
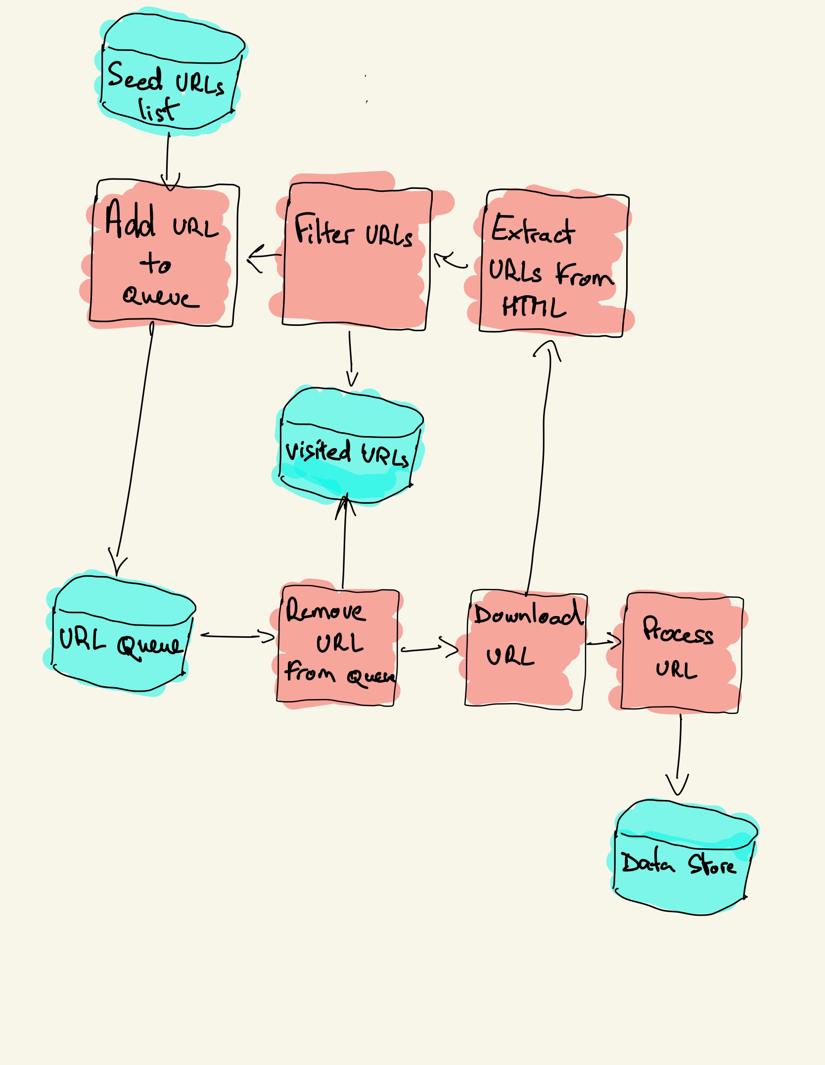
strategii de crawling Web
în practică, crawlerele web vizitează doar un subset de pagini în funcție de bugetul crawlerului, care poate fi un număr maxim de pagini pe domeniu, adâncime sau timp de execuție.
cele mai populare site-uri web oferă roboți.fișier txt pentru a indica ce zone ale site-ului web nu sunt permise să acceseze cu crawlere de către fiecare agent utilizator. Opusul fișierului robots este sitemap-ul.fișier xml, care listează paginile care pot fi accesate cu crawlere.
cazurile populare de utilizare a crawlerelor web includ:
- motoarele de căutare (Googlebot, Bingbot, Yandex Bot…) colectează tot HTML-ul pentru o parte semnificativă a Web-ului. Aceste date sunt indexate pentru a le face căutate.
- instrumentele de analiză SEO pe lângă colectarea HTML colectează, de asemenea, metadate precum timpul de răspuns, starea răspunsului pentru a detecta paginile rupte și legăturile dintre diferite domenii pentru a colecta backlink-uri.
- instrumente de monitorizare a prețurilor accesează cu crawlere site-urile de comerț electronic pentru a găsi pagini de produse și pentru a extrage metadate, în special prețul. Paginile de produse sunt apoi revizuite periodic.
- Crawl comun menține un depozit deschis de date crawl web. De exemplu, arhiva din octombrie 2020 conține 2,71 miliarde de pagini web.
în continuare, vom compara trei strategii diferite pentru construirea unui crawler web în Python. Mai întâi, folosind doar biblioteci standard, apoi biblioteci terțe pentru a face cereri HTTP și a analiza HTML și, în final, un cadru de crawling web.
construirea unui crawler web simplu în Python de la zero
pentru a construi un crawler web simplu în Python avem nevoie de cel puțin o bibliotecă pentru a descărca HTML dintr-o adresă URL și o bibliotecă de analiză HTML pentru a extrage linkuri. Python oferă biblioteci standard urllib pentru a face cereri HTTP și html.parser pentru parsarea HTML. Un exemplu de crawler Python construit numai cu biblioteci standard poate fi găsit pe Github.
bibliotecile Python standard pentru solicitări și parsarea HTML nu sunt foarte prietenoase pentru dezvoltatori. Alte biblioteci populare, cum ar fi cererile, marcate ca HTTP pentru oameni, și Beautiful Soup oferă o experiență mai bună pentru dezvoltatori.
dacă doriți să aflați mai multe, puteți verifica acest ghid despre cel mai bun client HTTP Python.
puteți instala cele două biblioteci la nivel local.
pip install requests bs4un crawler de bază poate fi construit urmând diagrama de arhitectură anterioară.
import loggingfrom urllib.parse import urljoinimport requestsfrom bs4 import BeautifulSouplogging.basicConfig( format='%(asctime)s %(levelname)s:%(message)s', level=logging.INFO)class Crawler: def __init__(self, urls=): self.visited_urls = self.urls_to_visit = urls def download_url(self, url): return requests.get(url).text def get_linked_urls(self, url, html): soup = BeautifulSoup(html, 'html.parser') for link in soup.find_all('a'): path = link.get('href') if path and path.startswith('/'): path = urljoin(url, path) yield path def add_url_to_visit(self, url): if url not in self.visited_urls and url not in self.urls_to_visit: self.urls_to_visit.append(url) def crawl(self, url): html = self.download_url(url) for url in self.get_linked_urls(url, html): self.add_url_to_visit(url) def run(self): while self.urls_to_visit: url = self.urls_to_visit.pop(0) logging.info(f'Crawling: {url}') try: self.crawl(url) except Exception: logging.exception(f'Failed to crawl: {url}') finally: self.visited_urls.append(url)if __name__ == '__main__': Crawler(urls=).run()codul de mai sus definește o clasă pe șenile cu metode de ajutor pentru a download_url folosind biblioteca cereri, get_linked_urls folosind biblioteca supa frumos și add_url_to_visit pentru a filtra URL-uri. Adresele URL de vizitat și adresele URL vizitate sunt stocate în două liste separate. Puteți rula crawlerul pe terminalul dvs.
python crawler.pycrawlerul înregistrează o linie pentru fiecare adresă URL vizitată.
2020-12-04 18:10:10,737 INFO:Crawling: https://www.imdb.com/2020-12-04 18:10:11,599 INFO:Crawling: https://www.imdb.com/?ref_=nv_home2020-12-04 18:10:12,868 INFO:Crawling: https://www.imdb.com/calendar/?ref_=nv_mv_cal2020-12-04 18:10:13,526 INFO:Crawling: https://www.imdb.com/list/ls016522954/?ref_=nv_tvv_dvd2020-12-04 18:10:19,174 INFO:Crawling: https://www.imdb.com/chart/top/?ref_=nv_mv_2502020-12-04 18:10:20,624 INFO:Crawling: https://www.imdb.com/chart/moviemeter/?ref_=nv_mv_mpm2020-12-04 18:10:21,556 INFO:Crawling: https://www.imdb.com/feature/genre/?ref_=nv_ch_grcodul este foarte simplu, dar există multe probleme de performanță și utilizare de rezolvat înainte de a accesa cu succes un site web complet.
- crawlerul este lent și nu acceptă paralelism. După cum se poate observa din marcajele de timp, este nevoie de aproximativ o secundă pentru a accesa cu crawlere fiecare adresă URL. De fiecare dată când crawlerul face o cerere, așteaptă ca cererea să fie rezolvată și nu se lucrează între ele.
- logica URL-ului de descărcare nu are niciun mecanism de reîncercare, coada URL nu este o coadă reală și nu este foarte eficientă cu un număr mare de adrese URL.
- logica de extragere a legăturilor nu acceptă standardizarea adreselor URL prin eliminarea parametrilor șirului de interogare URL, nu gestionează adresele URL începând cu #, nu acceptă filtrarea adreselor URL după domeniu sau filtrarea cererilor către fișiere statice.
- crawlerul nu se identifică și ignoră roboții.fișier txt.
în continuare, vom vedea cum Scrapy oferă toate aceste funcționalități și facilitează extinderea pentru crawl-urile personalizate.
web crawling cu Scrapy
Scrapy este cel mai popular web scraping și crawling cadru Python cu stele 40K pe Github. Unul dintre avantajele Scrapy este că cererile sunt programate și tratate asincron. Aceasta înseamnă că Scrapy poate trimite o altă solicitare înainte ca cea anterioară să fie finalizată sau să facă alte lucrări între ele. Scrapy poate gestiona multe solicitări concurente, dar poate fi configurat și pentru a respecta site-urile web cu setări personalizate, așa cum vom vedea mai târziu.
Scrapy are o arhitectură multi-componentă. În mod normal, veți implementa cel puțin două clase diferite: Spider și Pipeline. Răzuirea Web poate fi gândită ca un ETL în care extrageți date de pe web și le încărcați în propriul spațiu de stocare. Păianjenii extrag datele și conductele le încarcă în depozit. Transformarea se poate întâmpla atât în păianjeni, cât și în conducte, dar vă recomand să setați o conductă Scrapy personalizată pentru a transforma fiecare element independent unul de celălalt. În acest fel, eșecul de a procesa un element nu are nici un efect asupra altor elemente.
în plus, puteți adăuga middlewares spider și downloader între componente, așa cum se poate vedea în diagrama de mai jos.
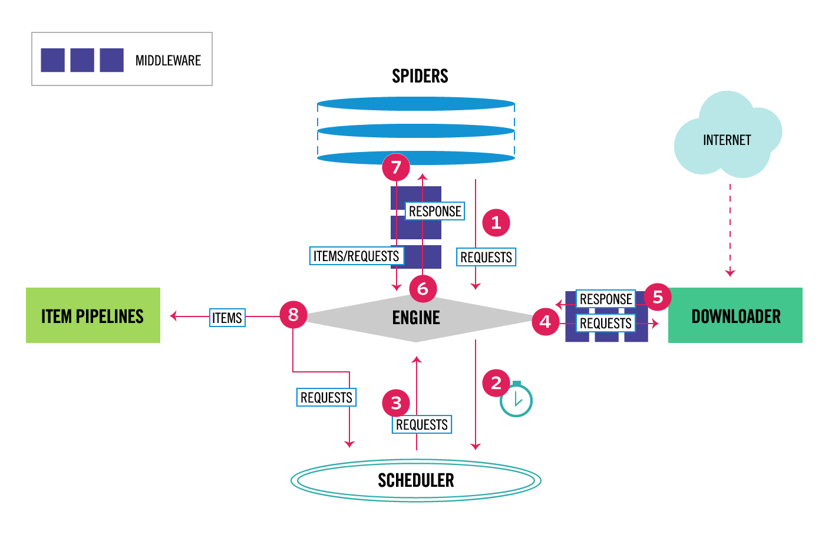
Prezentare generală a arhitecturii Scrapy
dacă ați folosit Scrapy înainte, știți că un răzuitor web este definit ca o clasă care moștenește din clasa Spider de bază și implementează o metodă de analiză pentru a gestiona fiecare răspuns. Dacă sunteți nou la Scrapy, puteți citi acest articol pentru răzuire ușoară cu Scrapy.
from scrapy.spiders import Spiderclass ImdbSpider(Spider): name = 'imdb' allowed_domains = start_urls = def parse(self, response): passScrapy oferă, de asemenea, mai multe clase de păianjen generice: CrawlSpider, XMLFeedSpider, CSVFeedSpider și SitemapSpider. Clasa CrawlSpider moștenește din clasa Spider de bază și oferă un atribut suplimentar de reguli pentru a defini modul de accesare cu crawlere a unui site web. Fiecare regulă utilizează un LinkExtractor pentru a specifica ce link-uri sunt extrase din fiecare pagină. În continuare, vom vedea cum să le folosim pe fiecare dintre ele construind un crawler pentru IMDb, baza de date Internet Movie.
construirea unui exemplu de crawler Scrapy pentru IMDb
înainte de a încerca să accesez cu crawlere IMDb, Am verificat roboți IMDb.fișier txt pentru a vedea ce căi URL sunt permise. Fișierul robots nu permite decât 26 de căi pentru toți agenții utilizator. Scrapy citește roboții.fișier TXT în prealabil și îl respectă atunci când setarea ROBOTSTXT_OBEY este setată la true. Acesta este cazul pentru toate proiectele generate cu comanda Scrapy startproject.
scrapy startproject scrapy_crawleraceastă comandă creează un nou proiect cu structura implicită a folderului de proiect Scrapy.
scrapy_crawler/├── scrapy.cfg└── scrapy_crawler ├── __init__.py ├── items.py ├── middlewares.py ├── pipelines.py ├── settings.py └── spiders ├── __init__.pyapoi puteți crea un păianjen în scrapy_crawler/spiders/imdb.py cu o regulă pentru a extrage toate legăturile.
from scrapy.spiders import CrawlSpider, Rulefrom scrapy.linkextractors import LinkExtractorclass ImdbCrawler(CrawlSpider): name = 'imdb' allowed_domains = start_urls = rules = (Rule(LinkExtractor()),)puteți lansa crawlerul în terminal.
scrapy crawl imdb --logfile imdb.logveți obține o mulțime de jurnale, inclusiv un jurnal pentru fiecare cerere. Explorând jurnalele am observat că, chiar dacă am setat allowed_domains să acceseze cu crawlere doar paginile web sub https://www.imdb.com, au existat solicitări către domenii externe, cum ar fi amazon.com.
2020-12-06 12:25:18 DEBUG: Redirecting (302) to <GET https://www.amazon.com/b/?&node=5160028011&ref_=ft_iba> from <GET (https://www.imdb.com/whitelist-offsite?url=https%3A%2F%2Fwww.amazon.com%2Fb%2F%3F%26node%3D5160028011%26ref_%3Dft_iba&page-action=ft-iba&ref=ft_iba)>IMDb Redirecționează de la URL-uri căi sub whitelist-offsite și whitelist la domenii externe. Există o problemă deschisă Scrapy Github care arată că URL-urile externe nu se filtrează atunci când OffsiteMiddleware este aplicat înainte de RedirectMiddleware. Pentru a remedia această problemă, putem configura extractorul de legături pentru a refuza adresele URL începând cu două expresii regulate.
class ImdbCrawler(CrawlSpider): name = 'imdb' allowed_domains = start_urls = rules = ( Rule(LinkExtractor( deny=, )), )clasele Rule și LinkExtractor acceptă mai multe argumente pentru a filtra adresele URL. De exemplu, puteți ignora anumite extensii URL și puteți reduce numărul de adrese URL duplicate prin sortarea șirurilor de interogare. Dacă nu găsiți un argument specific pentru cazul dvs. de utilizare, puteți trece o funcție personalizată la process_links în LinkExtractor sau process_values în regulă.
de exemplu, IMDb are două URL-uri diferite cu același conținut.
https://www.imdb.com/nume / nm1156914/
https://www.imdb.com/nume / nm1156914/?mode = desktop & ref_ = m_ft_dsk
pentru a limita numărul de adrese URL accesate cu crawlere, putem elimina toate șirurile de interogare din adresele URL Cu funcția url_query_cleaner din biblioteca w3lib și o putem folosi în process_links.
from w3lib.url import url_query_cleanerdef process_links(links): for link in links: link.url = url_query_cleaner(link.url) yield linkclass ImdbCrawler(CrawlSpider): name = 'imdb' allowed_domains = start_urls = rules = ( Rule(LinkExtractor( deny=, ), process_links=process_links), )acum că am limitat numărul de solicitări de procesat, putem adăuga o metodă parse_item pentru a extrage date din fiecare pagină și a le transmite unei conducte pentru a le stoca. De exemplu, putem extrage întregul răspuns.text pentru a procesa într-o conductă diferită sau selectați metadatele HTML. Pentru a selecta metadatele HTML din eticheta antet, putem codifica propriile noastre XPATHs, dar mi se pare mai bine să folosesc o bibliotecă, extruct, care extrage toate metadatele dintr-o pagină HTML. Puteți să-l instalați cu extract de instalare pip.
import refrom scrapy.linkextractors import LinkExtractorfrom scrapy.spiders import CrawlSpider, Rulefrom w3lib.url import url_query_cleanerimport extructdef process_links(links): for link in links: link.url = url_query_cleaner(link.url) yield linkclass ImdbCrawler(CrawlSpider): name = 'imdb' allowed_domains = start_urls = rules = ( Rule( LinkExtractor( deny=, ), process_links=process_links, callback='parse_item', follow=True ), ) def parse_item(self, response): return { 'url': response.url, 'metadata': extruct.extract( response.text, response.url, syntaxes= ), }am setat atributul follow la True, astfel încât Scrapy urmează în continuare toate linkurile din fiecare răspuns, chiar dacă am furnizat o metodă de analiză personalizată. De asemenea, am configurat extruct pentru a extrage doar metadatele Open Graph și JSON-LD, o metodă populară pentru codificarea datelor legate folosind JSON în Web, utilizată de IMDb. Puteți rula crawlerul și stoca elemente în format JSON lines într-un fișier.
scrapy crawl imdb --logfile imdb.log -o imdb.jl -t jsonlinesfișierul de ieșire imdb.jl conține o linie pentru fiecare element accesat cu crawlere. De exemplu, metadatele grafice deschise extrase pentru un film preluate din etichetele <meta> din HTML arată astfel.
{ "url": "http://www.imdb.com/title/tt2442560/", "metadata": {"opengraph": , , , , , ] }]}}JSON-LD pentru un singur element este prea lung pentru a fi incluse în articol, aici este un eșantion de ceea ce Scrapy extrage din <script type=”application/ld+json”> tag-ul.
"json-ld": , "contentRating": "TV-MA", "actor": ... }]explorând jurnalele, am observat o altă problemă comună cu crawlerele. Făcând clic secvențial pe filtre, crawlerul generează adrese URL cu același conținut, doar că filtrele au fost aplicate într-o ordine diferită.
https://www.imdb.com/nume / nm2900465 / Galerie video / content_type-trailer / related_titles-tt0479468
https://www.imdb.com/nume / nm2900465 / videogallery / related_titles-tt0479468/content_type-trailer
URL-uri lungi de filtrare și căutare este o problemă dificilă care poate fi rezolvată parțial prin limitarea lungimii URL-urilor cu o setare Scrapy, URLLENGTH_LIMIT.
am folosit IMDb ca exemplu pentru a arăta elementele de bază ale construirii unui crawler web în Python. Nu am lăsat crawlerul să ruleze mult timp, deoarece nu aveam un caz de utilizare specific pentru date. În cazul în care aveți nevoie de date specifice de la IMDb, puteți verifica proiectul Seturi de date IMDb care oferă un export zilnic de date IMDb și IMDbPY, un pachet Python pentru preluarea și gestionarea datelor.
web crawling la scară
dacă încercați să accesați cu crawlere un site web mare precum IMDb, cu peste 45 de milioane de pagini bazate pe Google, este important să accesați cu crawlere responsabil prin configurarea următoarelor setări. Puteți identifica crawlerul și puteți furniza detalii de contact în setarea BOT_NAME. Pentru a limita presiunea pe care o puneți pe serverele site-ului web, puteți crește DOWNLOAD_DELAY, limita CONCURRENT_REQUESTS_PER_DOMAIN sau setați AUTOTHROTTLE_ENABLED care va adapta aceste setări dinamic pe baza timpilor de răspuns de la server.
observați că crawlerele Scrapy sunt optimizate pentru un singur domeniu în mod implicit. Dacă accesați cu crawlere mai multe domenii, verificați aceste setări pentru a optimiza crawl-urile largi, inclusiv modificarea ordinii implicite de accesare cu crawlere de la adâncime la respirație. Pentru a vă limita bugetul de accesare cu crawlere, puteți limita numărul de solicitări cu setarea CLOSESPIDER_PAGECOUNT a extensiei close spider.
cu setările implicite, Scrapy accesează cu crawlere aproximativ 600 de pagini pe minut pentru un site web precum IMDb. Pentru a accesa cu crawlere 45m pagini va dura mai mult de 50 de zile pentru un singur robot. Dacă aveți nevoie să accesați cu crawlere mai multe site-uri web, poate fi mai bine să lansați crawlere separate pentru fiecare site web mare sau grup de site-uri web. Dacă sunteți interesat de crawlerele web distribuite,puteți citi cum un dezvoltator a accesat cu crawlere 250m pagini cu Python în 40 de ore folosind 20 de instanțe Amazon EC2.
în unele cazuri, puteți rula pe site-uri web care necesită executarea codului JavaScript pentru a reda tot codul HTML. Nu reușiți să faceți acest lucru și este posibil să nu colectați toate linkurile de pe site. Pentru că în zilele noastre este foarte comun pentru site-uri pentru a face conținut dinamic în browser-ul am scris un middleware Scrapy pentru redarea paginilor JavaScript folosind API ScrapingBee lui.
concluzie
am comparat codul unui crawler Python folosind biblioteci terțe pentru descărcarea adreselor URL și analizarea HTML cu un crawler construit folosind un cadru popular de crawling web. Scrapy este un cadru de crawling web foarte performant și este ușor de extins cu codul personalizat. Dar trebuie să cunoașteți toate locurile în care vă puteți conecta propriul cod și setările pentru fiecare componentă.
configurarea corectă a Scrapy devine și mai importantă atunci când accesați cu crawlere site-uri web cu milioane de pagini. Dacă doriți să aflați mai multe despre accesarea cu crawlere pe web, vă sugerez să alegeți un site web popular și să încercați să îl accesați cu crawlere. Cu siguranță veți întâlni probleme noi, ceea ce face subiectul fascinant!