Rastreo web con Python

El rastreo web es una técnica poderosa para recopilar datos de la web al encontrar todas las URL de uno o varios dominios. Python tiene varias bibliotecas y frameworks de rastreo web populares.
En este artículo, primero presentaremos diferentes estrategias de rastreo y casos de uso. Luego construiremos un rastreador web simple desde cero en Python usando dos bibliotecas: requests y Beautiful Soup. A continuación, veremos por qué es mejor usar un marco de rastreo web como Scrapy. Finalmente, construiremos un rastreador de ejemplo con Scrapy para recopilar metadatos de películas de IMDb y ver cómo Scrapy escala a sitios web con varios millones de páginas.
¿Qué es un rastreador web?
El rastreo web y el raspado web son dos conceptos diferentes pero relacionados. El rastreo web es un componente del raspado web, la lógica del rastreador encuentra las URL para ser procesadas por el código del raspador.
Un rastreador web comienza con una lista de URL para visitar, llamada la semilla. Para cada URL, el rastreador encuentra enlaces en el HTML, filtra esos enlaces en función de algunos criterios y agrega los nuevos enlaces a una cola. Todo el HTML o alguna información específica se extrae para ser procesada por una canalización diferente.
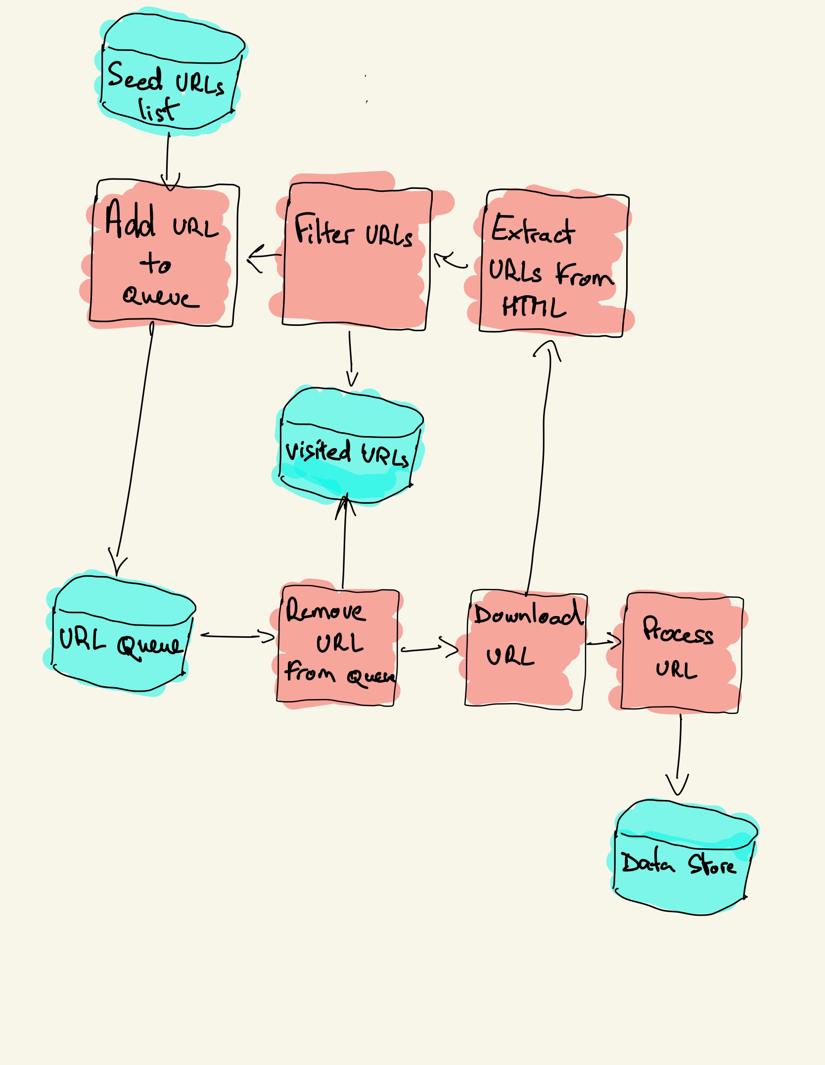
Estrategias de rastreo web
En la práctica, los rastreadores web solo visitan un subconjunto de páginas en función del presupuesto del rastreador, que puede ser un número máximo de páginas por dominio, profundidad o tiempo de ejecución.
Los sitios web más populares proporcionan robots.archivo txt para indicar qué áreas del sitio web no están permitidas para rastrear por cada agente de usuario. Lo opuesto al archivo robots es el mapa del sitio.archivo xml, que enumera las páginas que se pueden rastrear.
Los casos de uso populares de rastreadores web incluyen:
- Los motores de búsqueda (Googlebot, Bingbot, Yandex Bot…) recopilan todo el HTML de una parte significativa de la Web. Estos datos se indexan para que se puedan buscar.
- Las herramientas de análisis SEO, además de recopilar el HTML, también recopilan metadatos como el tiempo de respuesta, el estado de respuesta para detectar páginas rotas y los enlaces entre diferentes dominios para recopilar backlinks.
- Las herramientas de monitoreo de precios rastrean sitios web de comercio electrónico para encontrar páginas de productos y extraer metadatos, especialmente el precio. Las páginas de productos se revisan periódicamente.
- Common Crawl mantiene un repositorio abierto de datos de rastreo web. Por ejemplo, el archivo de octubre de 2020 contiene 2.71 mil millones de páginas web.
A continuación, compararemos tres estrategias diferentes para construir un rastreador web en Python. Primero, usar solo bibliotecas estándar, luego bibliotecas de terceros para realizar solicitudes HTTP y analizar HTML y, finalmente, un marco de rastreo web.
Construyendo un rastreador web simple en Python desde cero
Para construir un rastreador web simple en Python necesitamos al menos una biblioteca para descargar el HTML de una URL y una biblioteca de análisis HTML para extraer enlaces. Python proporciona bibliotecas estándar urllib para realizar solicitudes HTTP y html.analizador para analizar HTML. Un ejemplo de rastreador de Python construido solo con bibliotecas estándar se puede encontrar en Github.
Las bibliotecas estándar de Python para solicitudes y análisis HTML no son muy fáciles de usar para desarrolladores. Otras bibliotecas populares, como requests, con la marca HTTP para humanos y Beautiful Soup, proporcionan una mejor experiencia para desarrolladores.
Si desea obtener más información, puede consultar esta guía sobre el mejor cliente HTTP Python.
Puede instalar las dos bibliotecas localmente.
pip install requests bs4Se puede construir un rastreador básico siguiendo el diagrama de arquitectura anterior.
import loggingfrom urllib.parse import urljoinimport requestsfrom bs4 import BeautifulSouplogging.basicConfig( format='%(asctime)s %(levelname)s:%(message)s', level=logging.INFO)class Crawler: def __init__(self, urls=): self.visited_urls = self.urls_to_visit = urls def download_url(self, url): return requests.get(url).text def get_linked_urls(self, url, html): soup = BeautifulSoup(html, 'html.parser') for link in soup.find_all('a'): path = link.get('href') if path and path.startswith('/'): path = urljoin(url, path) yield path def add_url_to_visit(self, url): if url not in self.visited_urls and url not in self.urls_to_visit: self.urls_to_visit.append(url) def crawl(self, url): html = self.download_url(url) for url in self.get_linked_urls(url, html): self.add_url_to_visit(url) def run(self): while self.urls_to_visit: url = self.urls_to_visit.pop(0) logging.info(f'Crawling: {url}') try: self.crawl(url) except Exception: logging.exception(f'Failed to crawl: {url}') finally: self.visited_urls.append(url)if __name__ == '__main__': Crawler(urls=).run()El código anterior define una clase de Rastreador con métodos auxiliares para descargar_url usando la biblioteca de solicitudes, get_linked_urls usando la hermosa biblioteca de Sopa y add_url_to_visit para filtrar las URL. Las URL a visitar y las URL visitadas se almacenan en dos listas separadas. Puede ejecutar el rastreador en su terminal.
python crawler.pyEl rastreador registra una línea por cada URL visitada.
2020-12-04 18:10:10,737 INFO:Crawling: https://www.imdb.com/2020-12-04 18:10:11,599 INFO:Crawling: https://www.imdb.com/?ref_=nv_home2020-12-04 18:10:12,868 INFO:Crawling: https://www.imdb.com/calendar/?ref_=nv_mv_cal2020-12-04 18:10:13,526 INFO:Crawling: https://www.imdb.com/list/ls016522954/?ref_=nv_tvv_dvd2020-12-04 18:10:19,174 INFO:Crawling: https://www.imdb.com/chart/top/?ref_=nv_mv_2502020-12-04 18:10:20,624 INFO:Crawling: https://www.imdb.com/chart/moviemeter/?ref_=nv_mv_mpm2020-12-04 18:10:21,556 INFO:Crawling: https://www.imdb.com/feature/genre/?ref_=nv_ch_grEl código es muy simple, pero hay muchos problemas de rendimiento y usabilidad que resolver antes de rastrear con éxito un sitio web completo.
- El rastreador es lento y no admite paralelismo. Como se puede ver en las marcas de tiempo, se tarda aproximadamente un segundo en rastrear cada URL. Cada vez que el rastreador realiza una solicitud, espera a que se resuelva la solicitud y no se realiza ningún trabajo entre ambas.
- La lógica de URL de descarga no tiene mecanismo de reintento, la cola de URL no es una cola real y no es muy eficiente con un gran número de URL.
- La lógica de extracción de enlaces no admite la estandarización de direcciones URL mediante la eliminación de parámetros de cadena de consulta de URL, no maneja direcciones URL que comiencen con #, no admite el filtrado de direcciones URL por dominio o el filtrado de solicitudes a archivos estáticos.
- El rastreador no se identifica e ignora a los robots.archivo txt.
A continuación, veremos cómo Scrapy proporciona todas estas funcionalidades y hace que sea fácil de extender para sus rastreos personalizados.
Rastreo web con Scrapy
Scrapy es el framework de Python de rastreo y extracción web más popular con 40k estrellas en Github. Una de las ventajas de Scrapy es que las solicitudes se programan y manejan de forma asíncrona. Esto significa que Scrapy puede enviar otra solicitud antes de que se complete la anterior o hacer algún otro trabajo en el medio. Scrapy puede manejar muchas solicitudes simultáneas, pero también se puede configurar para respetar los sitios web con configuraciones personalizadas, como veremos más adelante.
Scrapy tiene una arquitectura de varios componentes. Normalmente, implementará al menos dos clases diferentes: Spider y Pipeline. La extracción de datos web se puede considerar como un ETL en el que extrae datos de la web y los carga en su propio almacenamiento. Las arañas extraen los datos y las canalizaciones los cargan en el almacenamiento. La transformación puede ocurrir tanto en arañas como en canalizaciones, pero te recomiendo que establezcas una canalización Scrapy personalizada para transformar cada elemento de forma independiente. De esta manera, no procesar un elemento no tiene efecto en otros elementos.
Además de todo eso, puede agregar middlewares spider y downloader entre los componentes, como se puede ver en el diagrama a continuación.
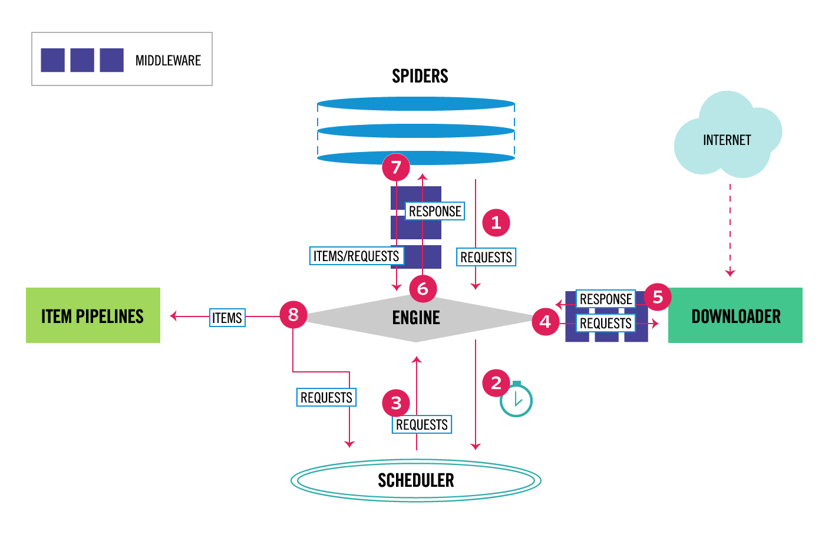
Descripción general de la arquitectura de Scrapy
Si ha utilizado Scrapy antes, sabe que un raspador web se define como una clase que hereda de la clase base Spider e implementa un método de análisis para manejar cada respuesta. Si eres nuevo en Scrapy, puedes leer este artículo para raspar fácilmente con Scrapy.
from scrapy.spiders import Spiderclass ImdbSpider(Spider): name = 'imdb' allowed_domains = start_urls = def parse(self, response): passScrapy también proporciona varias clases genéricas de araña: CrawlSpider, XMLFeedSpider, CSVFeedSpider y SitemapSpider. La clase CrawlSpider hereda de la clase Araña base y proporciona un atributo de reglas extra para definir cómo rastrear un sitio web. Cada regla utiliza un LinkExtractor para especificar qué enlaces se extraen de cada página. A continuación, veremos cómo usar cada uno de ellos construyendo un rastreador para IMDb, la Base de Datos de Películas de Internet.
Construyendo un rastreador rasposo de ejemplo para IMDb
Antes de intentar rastrear IMDb, revisé los robots de IMDb.archivo txt para ver qué rutas de URL están permitidas. El archivo robots solo no permite 26 rutas para todos los agentes de usuario. Scrapy lee los robots.archivo txt de antemano y lo respeta cuando la configuración ROBOTSTXT_OBEY se establece en true. Este es el caso de todos los proyectos generados con el comando Scrapy startproject.
scrapy startproject scrapy_crawlerEste comando crea un nuevo proyecto con la estructura de carpetas de proyecto Scrapy predeterminada.
scrapy_crawler/├── scrapy.cfg└── scrapy_crawler ├── __init__.py ├── items.py ├── middlewares.py ├── pipelines.py ├── settings.py └── spiders ├── __init__.pyA continuación, puede crear una araña en scrapy_crawler/spiders/imdb.py con una regla para extraer todos los enlaces.
from scrapy.spiders import CrawlSpider, Rulefrom scrapy.linkextractors import LinkExtractorclass ImdbCrawler(CrawlSpider): name = 'imdb' allowed_domains = start_urls = rules = (Rule(LinkExtractor()),)Puede iniciar el rastreador en la terminal.
scrapy crawl imdb --logfile imdb.logObtendrá muchos registros, incluido un registro por cada solicitud. Al explorar los registros, noté que incluso si configuramos allowed_domains para rastrear solo páginas web en https://www.imdb.com, había solicitudes a dominios externos, como amazon.com.
2020-12-06 12:25:18 DEBUG: Redirecting (302) to <GET https://www.amazon.com/b/?&node=5160028011&ref_=ft_iba> from <GET (https://www.imdb.com/whitelist-offsite?url=https%3A%2F%2Fwww.amazon.com%2Fb%2F%3F%26node%3D5160028011%26ref_%3Dft_iba&page-action=ft-iba&ref=ft_iba)>IMDb redirige desde rutas de URL en lista blanca-fuera del sitio y lista blanca a dominios externos. Hay un problema de Github rasposo abierto que muestra que las URL externas no se filtran cuando se aplica el software OffsiteMiddleware antes del software RedirectMiddleware. Para solucionar este problema, podemos configurar el extractor de enlaces para denegar direcciones URL que comiencen con dos expresiones regulares.
class ImdbCrawler(CrawlSpider): name = 'imdb' allowed_domains = start_urls = rules = ( Rule(LinkExtractor( deny=, )), )Las clases Rule y LinkExtractor admiten varios argumentos para filtrar direcciones URL. Por ejemplo, puede ignorar extensiones de URL específicas y reducir el número de URL duplicadas ordenando cadenas de consulta. Si no encuentra un argumento específico para su caso de uso, puede pasar una función personalizada a process_links en LinkExtractor o process_values en Rule.
Por ejemplo, IMDb tiene dos URL diferentes con el mismo contenido.
https://www.imdb.com/nombre/nm1156914/
https://www.imdb.com/nombre/nm1156914/?mode = desktop& ref_ = m_ft_dsk
Para limitar el número de URL rastreadas, podemos eliminar todas las cadenas de consulta de las URL con la función url_query_cleaner de la biblioteca w3lib y usarla en process_links.
from w3lib.url import url_query_cleanerdef process_links(links): for link in links: link.url = url_query_cleaner(link.url) yield linkclass ImdbCrawler(CrawlSpider): name = 'imdb' allowed_domains = start_urls = rules = ( Rule(LinkExtractor( deny=, ), process_links=process_links), )Ahora que hemos limitado el número de solicitudes a procesar, podemos agregar un método parse_item para extraer datos de cada página y pasarlos a una canalización para almacenarlos. Por ejemplo, podemos extraer la respuesta completa.texto para procesarlo en una canalización diferente o seleccionar los metadatos HTML. Para seleccionar los metadatos HTML en la etiqueta de encabezado podemos codificar nuestros propios XPaths, pero me parece mejor usar una biblioteca, extract, que extrae todos los metadatos de una página HTML. Puede instalarlo con pip install extract.
import refrom scrapy.linkextractors import LinkExtractorfrom scrapy.spiders import CrawlSpider, Rulefrom w3lib.url import url_query_cleanerimport extructdef process_links(links): for link in links: link.url = url_query_cleaner(link.url) yield linkclass ImdbCrawler(CrawlSpider): name = 'imdb' allowed_domains = start_urls = rules = ( Rule( LinkExtractor( deny=, ), process_links=process_links, callback='parse_item', follow=True ), ) def parse_item(self, response): return { 'url': response.url, 'metadata': extruct.extract( response.text, response.url, syntaxes= ), }Establecí el atributo follow en True para que Scrapy siga todos los enlaces de cada respuesta, incluso si proporcionamos un método de análisis personalizado. También configuré extract para extraer solo metadatos de Open Graph y JSON-LD, un método popular para codificar datos vinculados utilizando JSON en la Web, utilizado por IMDb. Puede ejecutar el rastreador y almacenar elementos en formato de líneas JSON en un archivo.
scrapy crawl imdb --logfile imdb.log -o imdb.jl -t jsonlinesEl archivo de salida imdb.jl contiene una línea para cada elemento rastreado. Por ejemplo, los metadatos de Open Graph extraídos para una película tomada de las etiquetas <meta> en el HTML se ven así.
{ "url": "http://www.imdb.com/title/tt2442560/", "metadata": {"opengraph": , , , , , ] }]}}El JSON-LD para un solo elemento es demasiado largo para ser incluido en el artículo, aquí hay una muestra de lo que extrae Rasposo de la etiqueta <script type=»application/ld+json»>.
"json-ld": , "contentRating": "TV-MA", "actor": ... }]Al explorar los registros, noté otro problema común con los rastreadores. Al hacer clic secuencialmente en los filtros, el rastreador genera URLs con el mismo contenido, solo que los filtros se aplicaron en un orden diferente.
https://www.imdb.com/nombre / nm2900465 / videogallery / content_type-trailer / related_titles-tt0479468
https://www.imdb.com/name / nm2900465/videogallery/related_titles-tt0479468 / content_type-trailer
El filtro largo y las URL de búsqueda son un problema difícil que se puede resolver parcialmente limitando la longitud de las URL con una configuración rasposa, URLLENGTH_LIMIT.
Utilicé IMDb como ejemplo para mostrar los conceptos básicos de la construcción de un rastreador web en Python. No dejé que el rastreador se ejecutara por mucho tiempo, ya que no tenía un caso de uso específico para los datos. En caso de que necesite datos específicos de IMDb, puede verificar el proyecto de conjuntos de datos de IMDb que proporciona una exportación diaria de datos de IMDb e IMDbPY, un paquete de Python para recuperar y administrar los datos.
Rastreo web a escala
Si intentas rastrear un sitio web grande como IMDb, con más de 45 millones de páginas basadas en Google, es importante rastrear de manera responsable configurando los siguientes ajustes. Puede identificar su rastreador y proporcionar detalles de contacto en la configuración BOT_NAME. Para limitar la presión que ejerce sobre los servidores del sitio web, puede aumentar el TIEMPO DE DESCARGA, limitar el DOMINIO CONCURRENT_REQUESTS_PER_DOMAIN o establecer AUTOTHROTTLE_ENABLED que adaptará esos ajustes dinámicamente en función de los tiempos de respuesta del servidor.
Observe que los rastreos rasposos están optimizados para un solo dominio de forma predeterminada. Si está rastreando varios dominios, compruebe esta configuración para optimizar los rastreos amplios, incluido el cambio del orden de rastreo predeterminado de primero en profundidad a primero en respiración. Para limitar tu presupuesto de rastreo, puedes limitar el número de solicitudes con la configuración CLOSESPIDER_PAGECOUNT de la extensión close spider.
Con la configuración predeterminada, Scrapy rastrea unas 600 páginas por minuto para un sitio web como IMDb. Para rastrear páginas de 45M, un solo robot tardará más de 50 días. Si necesitas rastrear varios sitios web, puede ser mejor lanzar rastreadores separados para cada sitio web grande o grupo de sitios web. Si está interesado en rastreos web distribuidos, puede leer cómo un desarrollador rastreó 250 millones de páginas con Python en 40 horas utilizando 20 instancias de máquina de Amazon EC2.
En algunos casos, puede encontrarse con sitios web que requieren que ejecute código JavaScript para renderizar todo el HTML. Si no lo hace, y no puede recopilar todos los enlaces en el sitio web. Debido a que hoy en día es muy común que los sitios web rendericen contenido dinámicamente en el navegador, escribí un middleware Scrapy para renderizar páginas JavaScript utilizando la API de ScrapingBee.
Conclusión
Comparamos el código de un rastreador de Python utilizando bibliotecas de terceros para descargar URL y analizar HTML con un rastreador construido utilizando un popular marco de rastreo web. Scrapy es un framework de rastreo web muy eficiente y es fácil de extender con su código personalizado. Pero necesita conocer todos los lugares donde puede enganchar su propio código y la configuración de cada componente.
Configurar Scrapy correctamente se vuelve aún más importante cuando se rastrean sitios web con millones de páginas. Si quieres aprender más sobre el rastreo web, te sugiero que elijas un sitio web popular e intentes rastrearlo. ¡Definitivamente te encontrarás con nuevos temas, lo que hace que el tema sea fascinante!