PASO A PASO: CÓMO CONFIGURAR UNA INSTANCIA DE CLÚSTER DE CONMUTACIÓN POR ERROR DE SQL SERVER 2008 R2 EN WINDOWS SERVER 2008 R2 EN AZURE O AZURE STACK
El 9 de julio de 2019 finalizará la compatibilidad con SQL Server 2008 y 2008 R2. Eso significa el fin de las actualizaciones de seguridad regulares. Sin embargo, si mueve esas instancias de SQL Server a Azure o Azure Stack (simplemente me referiré a ambos como Azure para el resto de la guía), Microsoft le dará tres años de Actualizaciones de seguridad ampliadas sin cargo adicional. Si actualmente está ejecutando SQL Server 2008/2008 R2 y no puede actualizar a una versión posterior de SQL Server antes de la fecha límite del 9 de julio, querrá aprovechar esta oferta en lugar de correr el riesgo de enfrentar una vulnerabilidad de seguridad futura. Una instancia de SQL Server sin parchear podría provocar pérdida de datos, tiempo de inactividad o una violación de datos devastadora.
Uno de los desafíos a los que se enfrentará al ejecutar SQL Server 2008/2008 R2 en Azure es garantizar una alta disponibilidad. En las instalaciones, puede estar ejecutando una instancia de clúster de conmutación por error (FCI) de SQL Server para alta disponibilidad, o posiblemente esté ejecutando SQL Server en una máquina virtual y dependa de VMware HA o de un clúster Hyper-V para disponibilidad. Al mudarse a Azure, ninguna de esas opciones está disponible. El tiempo de inactividad en Azure es una posibilidad muy real que debe tomar medidas para mitigarla.
Para mitigar la posibilidad de tiempo de inactividad y calificar para el 99,95% o 99 de Azure.99% SLA, tienes que aprovechar el buscador de datos SIOS. DataKeeper supera la falta de almacenamiento compartido de Azure y le permite crear una FCI de SQL Server en Azure que aproveche el almacenamiento conectado localmente en cada instancia. SIO DataKeeper no sólo es compatible con SQL Server 2008 R2 y Windows Server 2008 R2, como se explica en esta guía, es compatible con cualquier versión de Windows Server, desde 2008 R2, Windows Server 2019 y cualquier versión de SQL Server de SQL Server 2008 a través de SQL Server 2019.
Esta guía explicará el proceso de creación de una instancia de clúster de conmutación por error (FCI) de SQL Server 2008 R2 de dos nodos en Azure, que se ejecuta en Windows Server 2008 R2. Aunque SIOS DataKeeper también admite clústeres que abarcan Zonas o Regiones de disponibilidad, esta guía asume que cada nodo reside en la misma Región de Azure, pero en dominios de error diferentes. El buscador de datos SIOS se utilizará en lugar del almacenamiento compartido que normalmente se requiere para crear una FCI SQL Server 2008 R2.
Requisitos previos
Active Directory
Esta guía supone que tiene un dominio de Active Directory existente. Puede administrar sus propios Controladores de dominio o usar los servicios de dominio de Azure Active Directory. Para este tutorial nos conectaremos a un dominio llamado contoso.local. Por supuesto, se conectará a su propio dominio al seguir este tutorial.
Puertos de firewall abiertos
– SQL Server:1433 para la instancia predeterminada
– Sonda de estado del equilibrador de carga: 59999
– DataKeeper: estas reglas de firewall se agregan automáticamente al firewall basado en host de Windows durante la instalación. Para obtener más información sobre qué puertos se abren, consulte la documentación de SIOS.
– Tenga en cuenta que si tiene alguna seguridad basada en la red que bloquea los puertos entre los nodos del clúster, también deberá tener en cuenta estos puertos allí.
Cuenta de servicio DataKeeper
Crear una cuenta de dominio. Especificaremos esta cuenta cuando instalemos DataKeeper. Esta cuenta deberá agregarse al grupo Administradores local de cada nodo del clúster.
Crear la primera instancia de SQL Server en Azure
Esta guía aprovechará la imagen de SQL Server 2008R2SP3 en Windows Server 2008R2 publicada en Azure Marketplace.
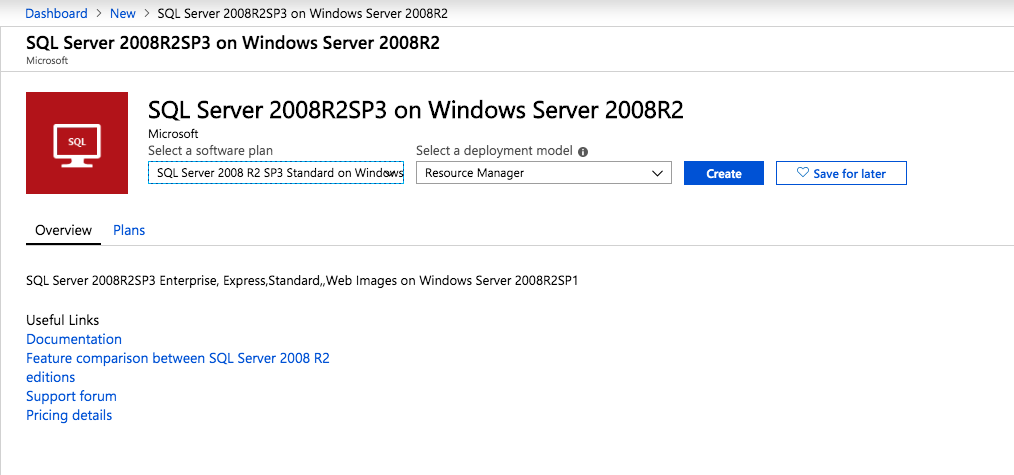
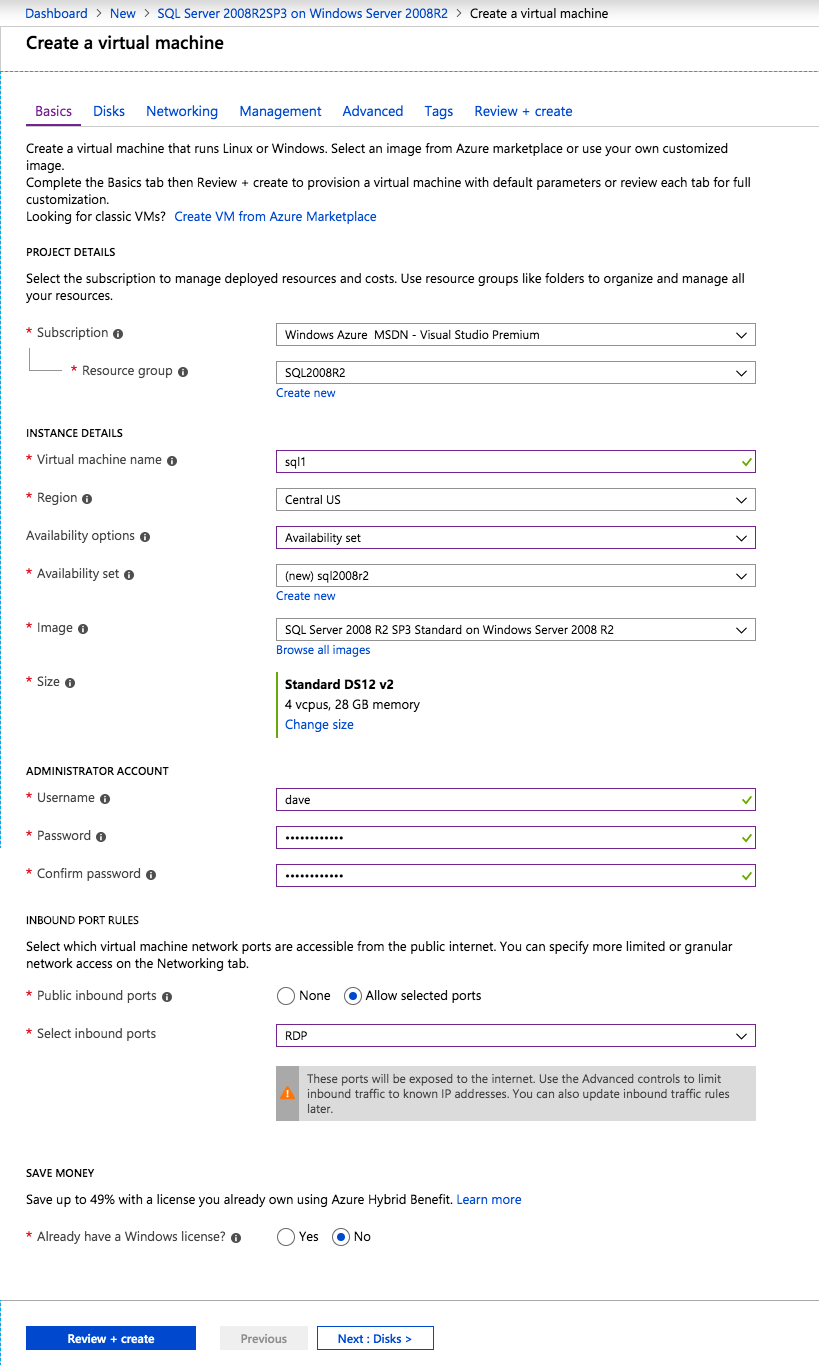
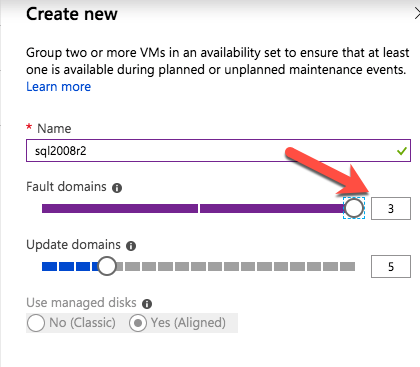
Cuando aprovisione la primera instancia, tendrá que crear un nuevo Conjunto de disponibilidad. Durante este proceso, asegúrese de aumentar el número de Dominios de falla a 3. Esto permite que los dos nodos del clúster y el testigo del recurso compartido de archivos residan en su propio dominio de errores.
Si aún no tiene configurada una red virtual, permita que el asistente de creación cree una nueva para usted.
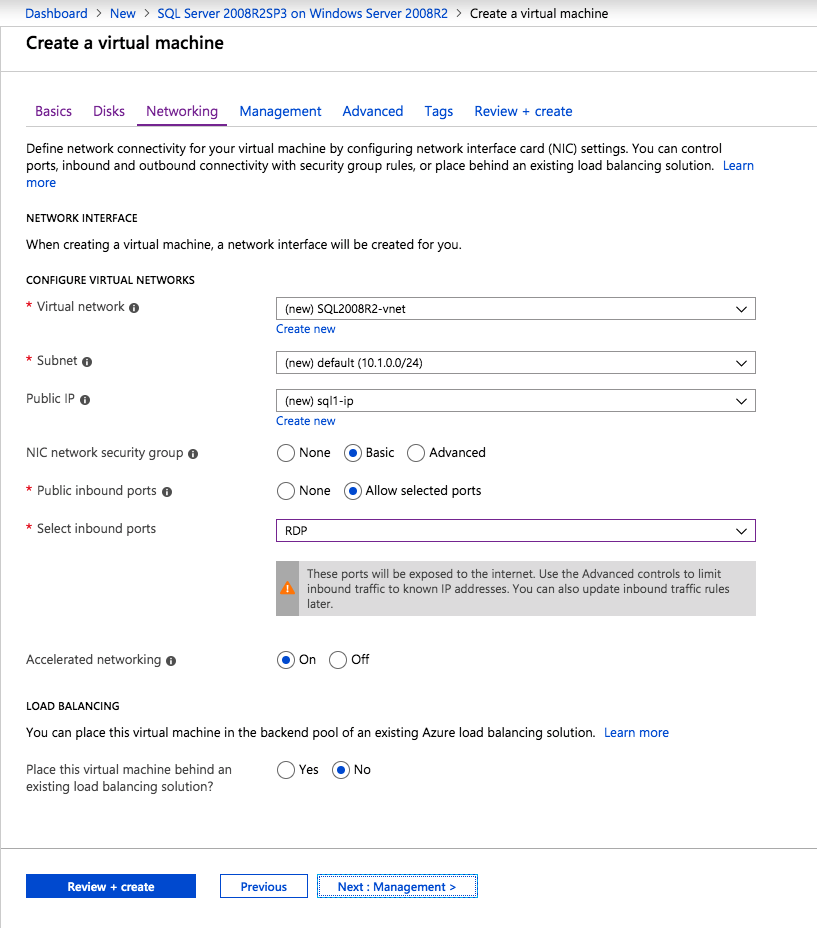
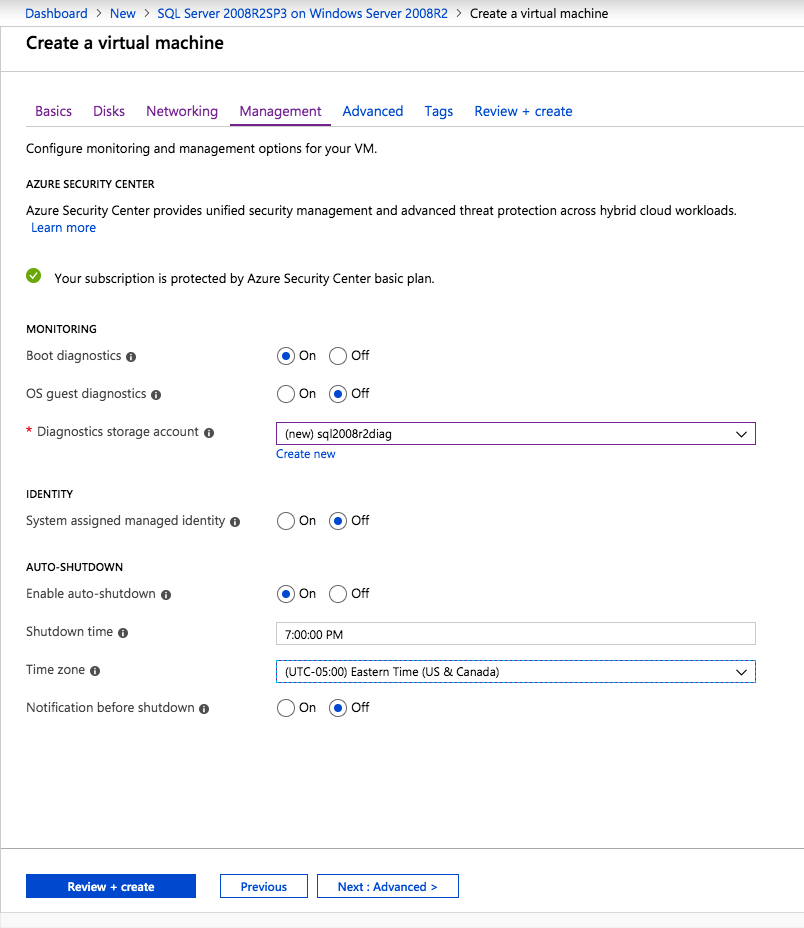
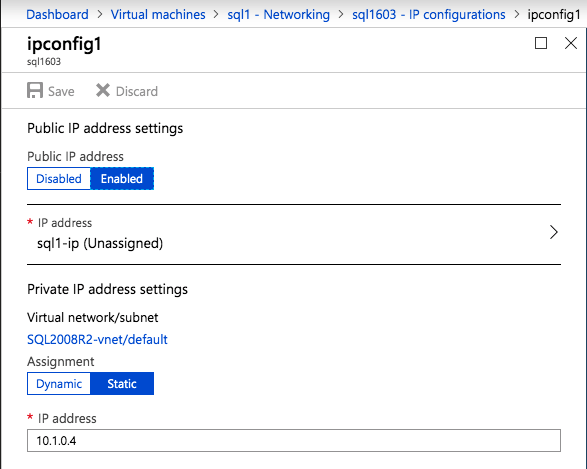
una Vez creada la instancia, ir a las configuraciones IP y hacer que la dirección IP Privada estática. Esto es necesario para el DataKeeper de SIOS y es una práctica recomendada para las instancias en clúster.
Asegúrese de que su red virtual esté configurada para que el servidor DNS sea un controlador local de Windows AD para asegurarse de que podrá unirse al dominio en un paso posterior.
Después de aprovisionar las máquinas virtuales, agregue al menos dos discos adicionales a cada instancia. Se recomiendan SSD Premium o Ultra. Deshabilite el almacenamiento en caché en los discos utilizados para los archivos de registro SQL. Habilite el almacenamiento en caché de solo lectura en el disco utilizado para los archivos de datos SQL. Consulte las directrices de rendimiento para SQL Server en máquinas virtuales de Azure para obtener información adicional sobre las prácticas recomendadas de almacenamiento.
Crear la segunda instancia de SQL Server en Azure
Siga los mismos pasos anteriores, excepto asegúrese de colocar esta instancia en la misma red virtual y el mismo Conjunto de disponibilidad que creó con la primera instancia.
Crear una instancia de Testigo de uso compartido de archivos (FSW)
Para que el clúster de conmutación por error de Windows Server (WSFC) funcione de forma óptima, debe crear otra instancia de Windows Server y colocarla en el mismo Conjunto de disponibilidad que las instancias de SQL Server. Al colocarlo en el mismo Conjunto de disponibilidad, se asegura de que cada nodo de clúster y el FSW residan en dominios de error diferentes, lo que garantiza que el clúster permanezca en línea en caso de que todo un dominio de error se desconecte. Estas instancias no requieren SQL Server, puede ser un simple servidor de Windows, ya que todo lo que necesita hacer es alojar un simple recurso compartido de archivos.
Esta instancia alojará el testigo de uso compartido de archivos requerido por WSFC. No es necesario que esta instancia tenga el mismo tamaño, ni que se adjunte ningún disco adicional. Su único propósito es alojar un simple recurso compartido de archivos. De hecho, puede utilizarse para otros fines. En mi entorno de laboratorio, mi FSW también es mi controlador de dominio.
Desinstalar SQL Server 2008 R2
Cada una de las dos instancias de SQL Server aprovisionadas ya tiene instalado SQL Server 2008 R2. Sin embargo, se instalan como instancias independientes de SQL Server, no como instancias agrupadas. SQL Server debe desinstalarse de cada una de estas instancias antes de poder instalar la instancia del clúster. La forma más fácil de hacerlo es ejecutar la configuración de SQL como se muestra a continuación.
Cuando ejecuta la configuración.exe / Action-RunDiscovery verá todo lo que está preinstalado
setup.exe /Action=RunDiscovery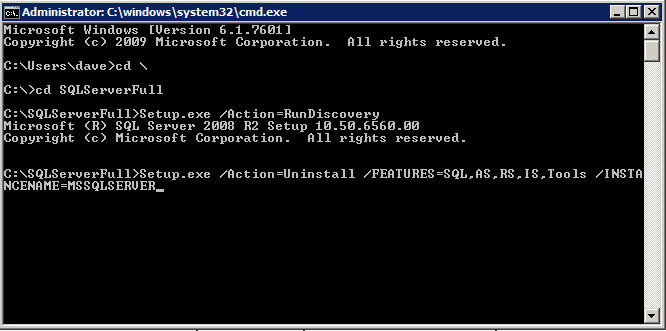

Configuración en marcha.exe / Action = Uninstall / FEATURES = SQL, AS, RS, IS, Tools/INSTANCENAME = MSSQLSERVER inicia el proceso de desinstalación
setup.exe /Action=Uninstall /FEATURES=SQL,AS,RS,IS,Tools /INSTANCENAME=MSSQLSERVER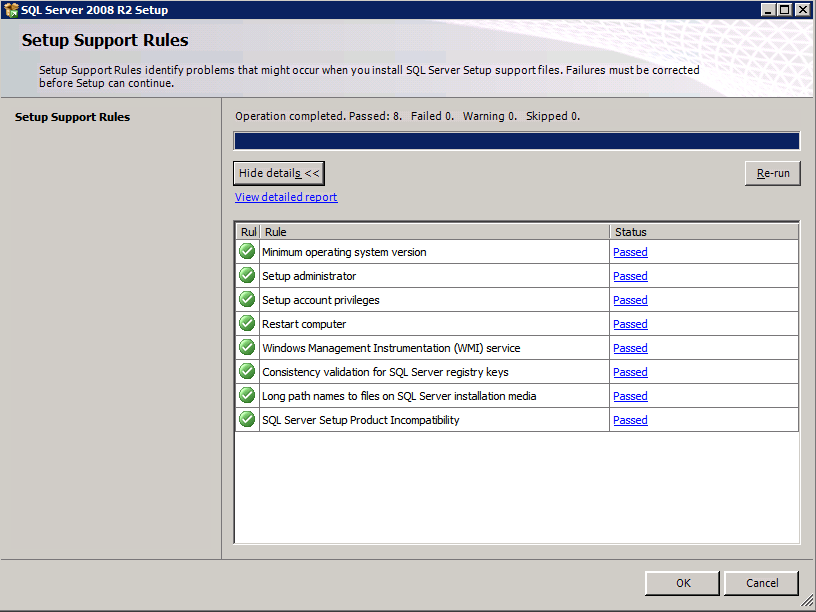
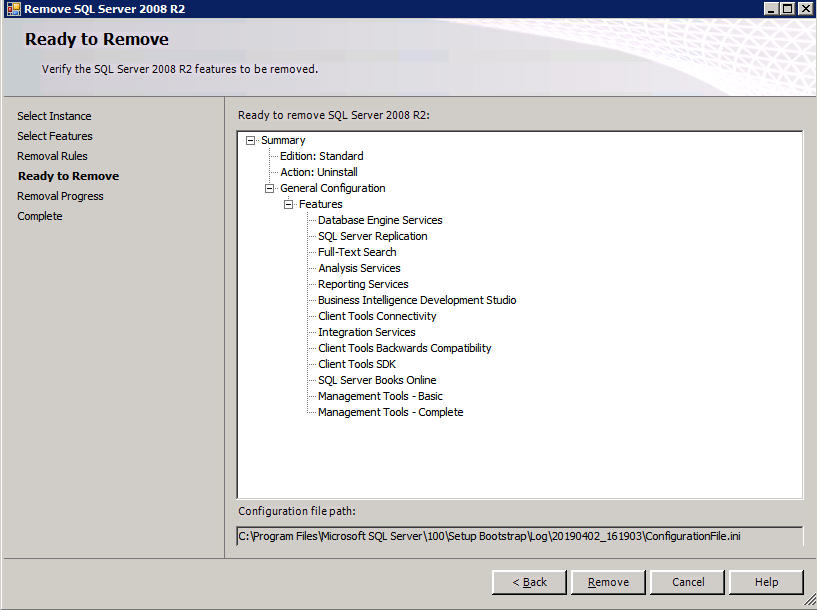
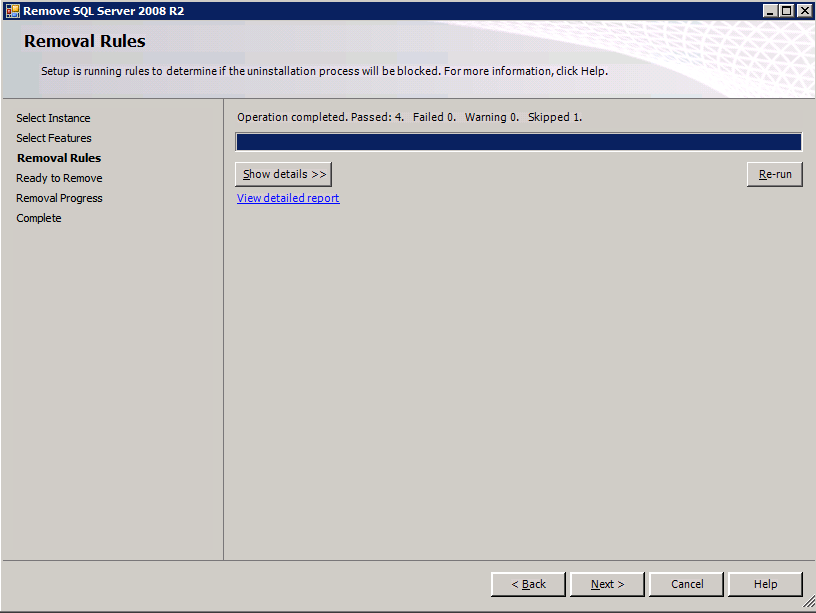
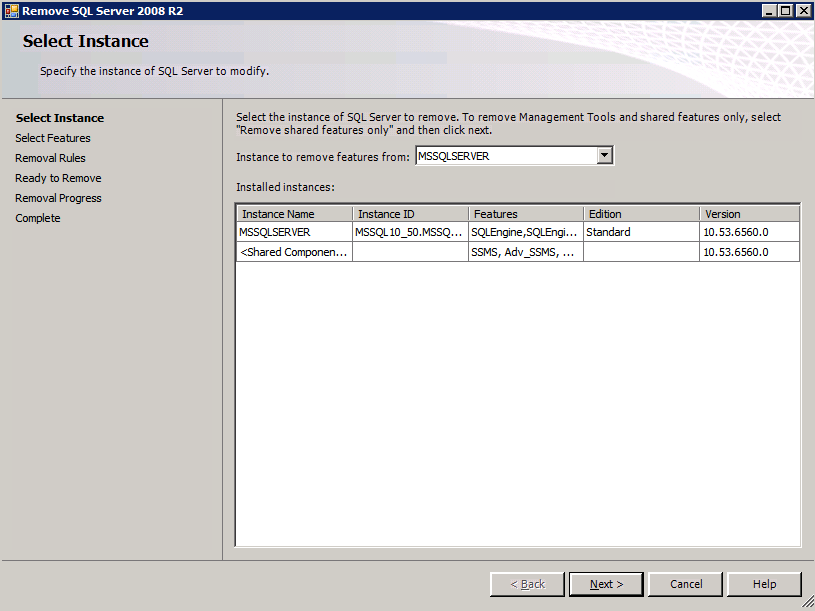
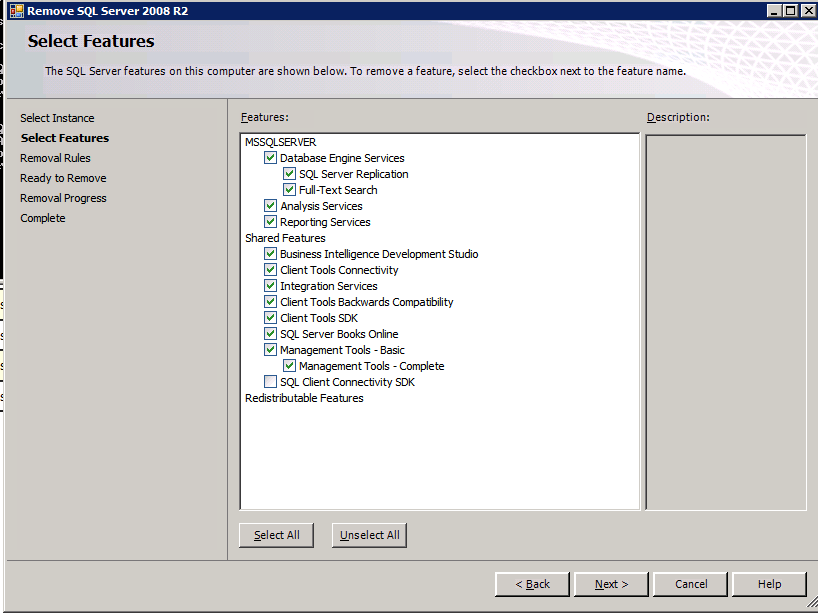
Configuración en marcha.exe / Action-RunDiscovery confirma la desinstalación completada
setup.exe /Action-RunDiscovery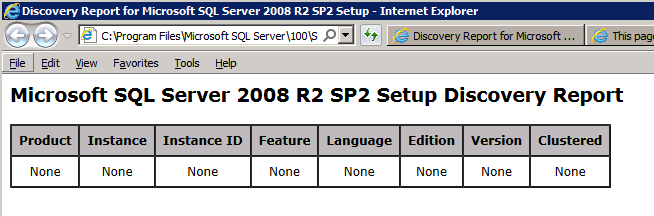
Ejecute este proceso de desinstalación de nuevo en la segunda instancia.
Agregar instancias al dominio
Las tres instancias deberán agregarse a un dominio de Windows. Como se menciona en la sección Requisitos previos, debe tener acceso para unirse a un Directorio activo de Windows existente. En nuestro caso, nos unimos a un dominio llamado contoso.local.
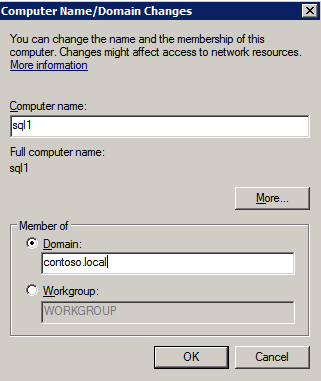
Agregar Característica de Clúster de Conmutación por error de Windows
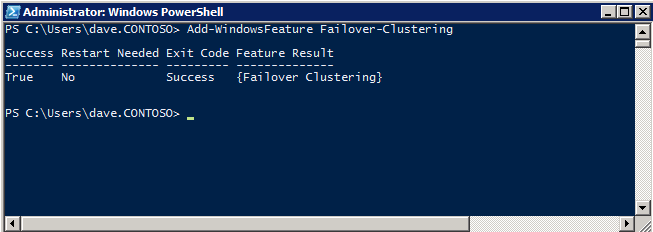
La característica de Clúster de conmutación por error debe agregarse a las dos instancias de SQL Server
Add-WindowsFeature Failover-Clustering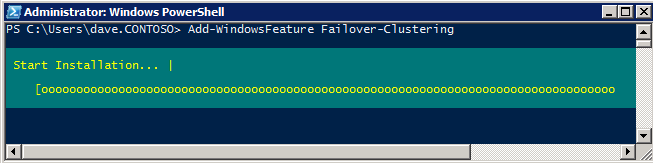
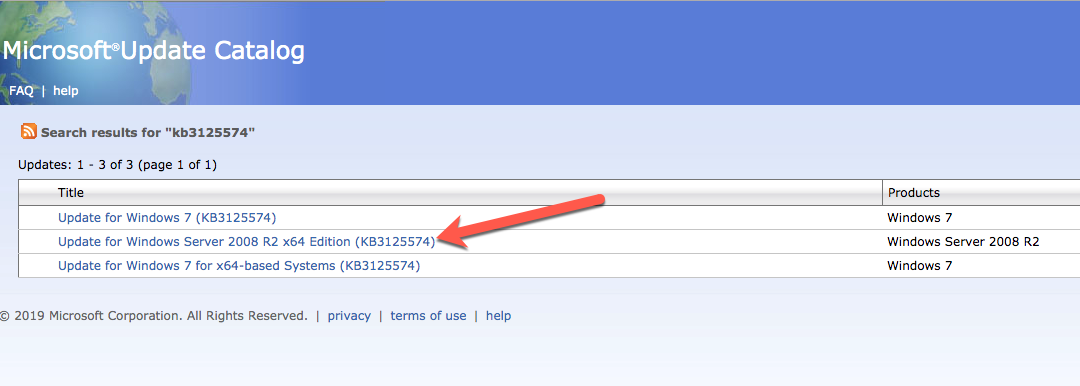
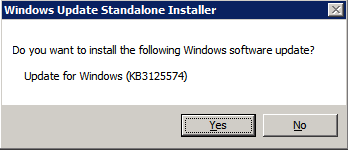
Instalar Actualización acumulativa conveniente para Windows Server 2008 R2 SP1
Hay una actualización crítica (kb2854082) que se requiere para configurar una instancia de Windows Server 2008 R2 en Azure. Esa actualización y muchas más se incluyen en la actualización acumulativa de conveniencia para Windows Server 2008 R2 SP1. Instale esta actualización en cada una de las dos instancias de SQL Server.
Formato de Almacenamiento
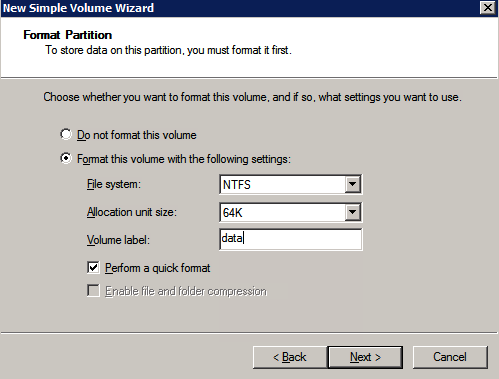
Los discos adicionales que se adjuntan, cuando los dos instancias de SQL Server se aprovisionan necesitan ser formateados. Haga lo siguiente para cada volumen de cada instancia.
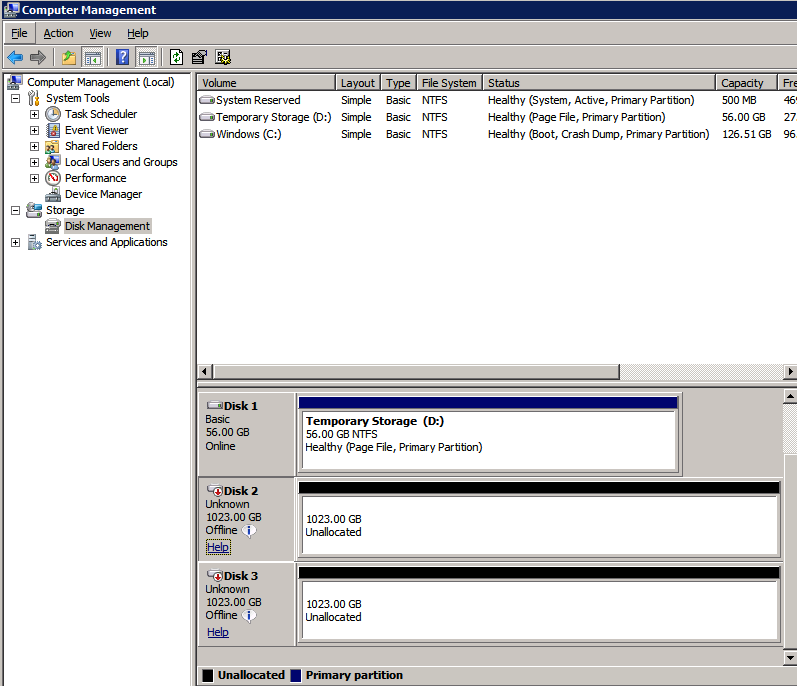
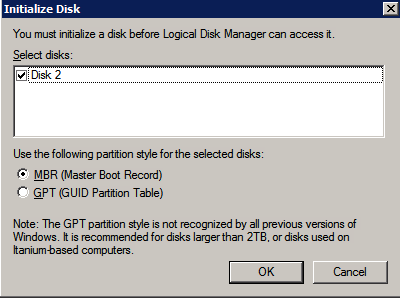
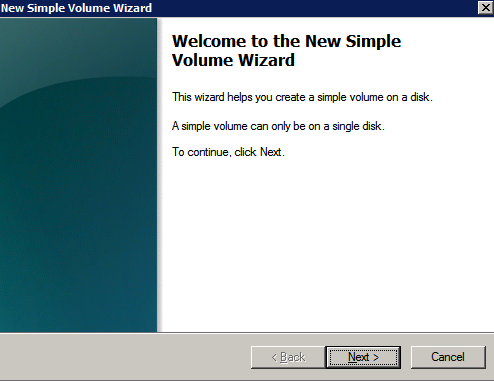
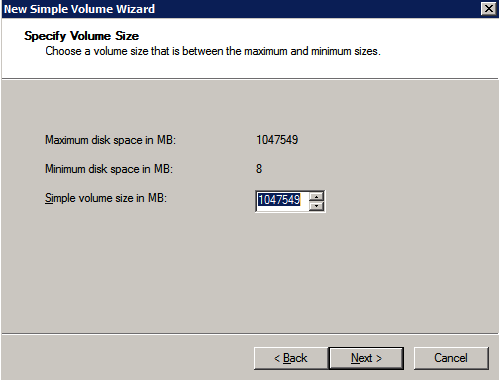
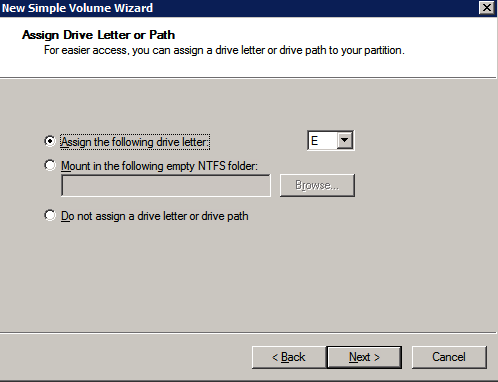
las mejores prácticas de Microsoft dice lo siguiente…
«NTFS tamaño de unidad de asignación: Al formatear el disco de datos, se recomienda utilizar un tamaño de unidad de asignación de 64 KB para los archivos de datos y registro, así como TempDB.»
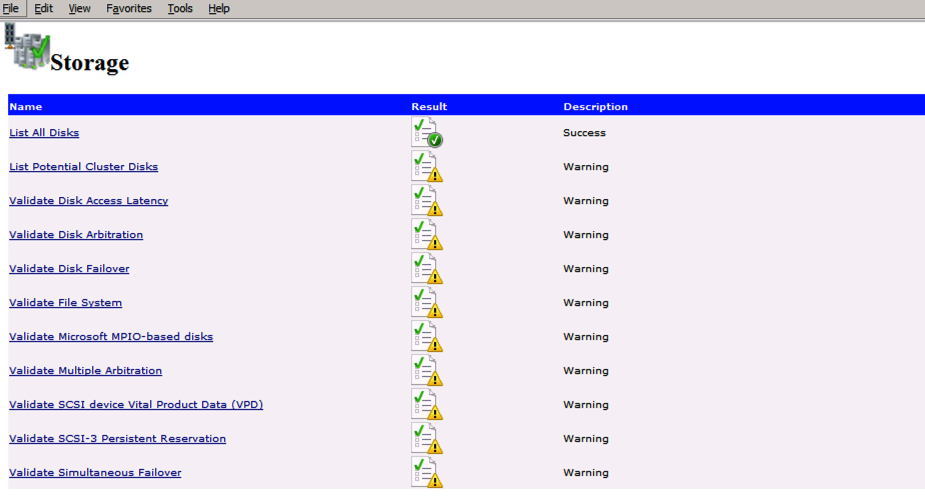
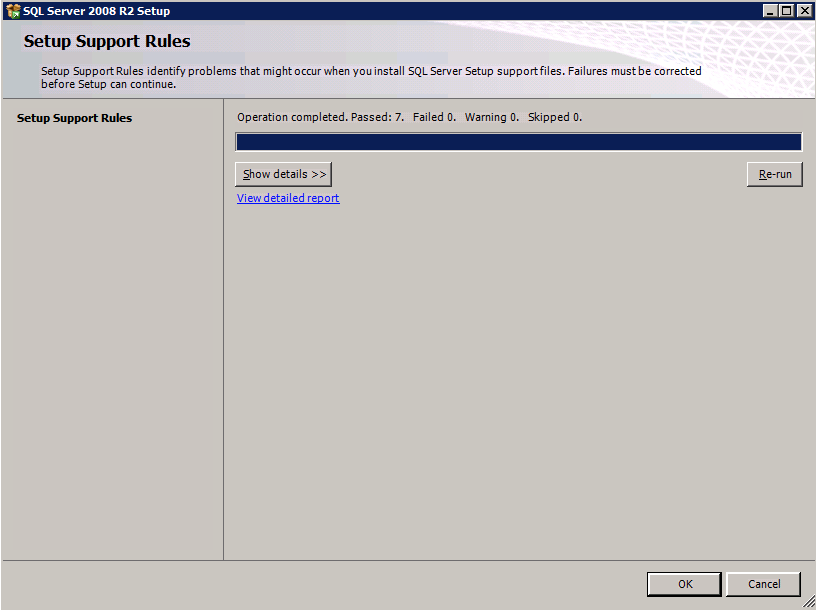
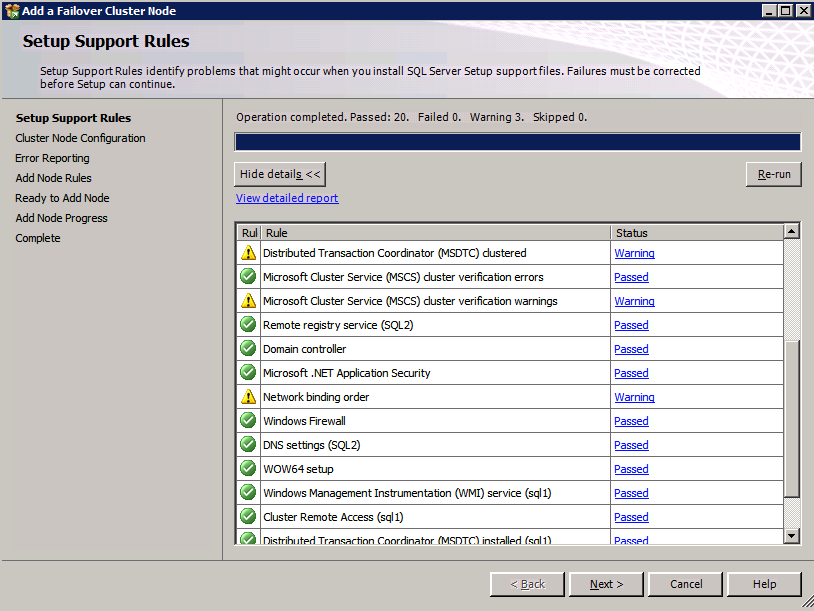
Ejecute la validación del clúster
Ejecute la validación del clúster para asegurarse de que todo esté listo para agruparse.
Import-Module FailoverClustersTest-Cluster -Node "SQL1", "SQL2"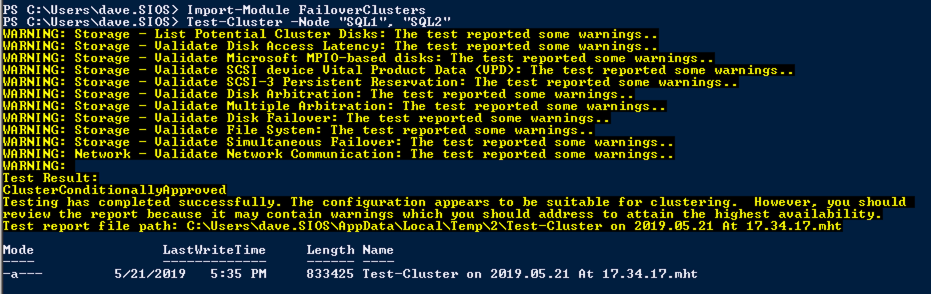
Su informe contendrá ADVERTENCIAS sobre Almacenamiento y redes. Puede ignorar esas advertencias, ya que sabemos que no hay discos compartidos y que solo existe una única conexión de red entre los servidores. También puede recibir una advertencia sobre el orden de enlace de red que también se puede ignorar. Si encuentra algún ERROR, debe corregirlo antes de continuar.
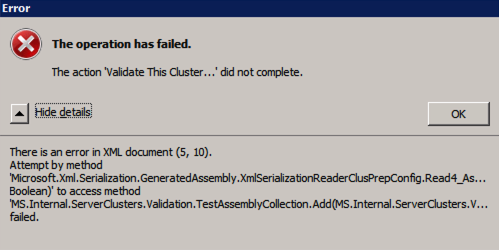
Error al intentar ejecutar la Validación del Clúster?
He encontrado este error en algunas ocasiones y todavía estoy tratando de resolver en qué condiciones ocurre esto. Ocasionalmente, encontrará que el clúster de pruebas no se ejecuta como se describe en la publicación del foro.
Test-ClusterUnable to Validate a Cluster Configuration. The operation has failed. The action validate a configuration did not completeThere is an error in XML document (5, 73). Attempt by methodMicrosoft.Xml.Serialzation.GeneratedAssembly.XmlSerialzationReaderClusterPrep.Config.Read4_As...Bolean) to access methodMS.Internal.ServerClusters.Validation.TestAssemblyCollection.Add(MS.Internal.ServerClusters.V....FailedSi esto te sucede, he encontrado que la siguiente corrección recomendada en la publicación del foro funciona para mí.
Inside C:\Windows\System32\WindowsPowerShell\v1.0 make a copy of powershell_ise.exe.config file (make a copy inside C:\Windows\System32\WindowsPowerShell\v1.0)- rename it to powershell.exe.configOpen it with notepad- delete current config line and paste:<?xml version="1.0" encoding="utf-8" ?><configuration> <system.xml.serialization> <xmlSerializer useLegacySerializerGeneration="true"/> </system.xml.serialization></configuration>- save and run test-clusterAunque esta corrección le permitirá ejecutar test-cluster desde Powershell, he descubierto que ejecutar Validate a través de la interfaz gráfica de usuario genera un error, incluso con esta corrección. Tengo una consulta en Microsoft para ver si tienen una solución, pero por ahora, si necesita ejecutar la validación de clúster, puede que tenga que usar Test-Cluster en Powershell.
Crear el clúster
Las prácticas recomendadas para crear un clúster en Azure consistirían en usar Powershell para crear un clúster, especificando una dirección IP estática. Powershell nos permite especificar una dirección IP estática, mientras que el método GUI no lo hace. Desafortunadamente, la implementación de DHCP de Azure no funciona bien con WSFC, por lo que si usa el método GUI, terminará con una dirección IP duplicada como la Dirección IP del clúster que deberá arreglarse antes de que el clúster se pueda usar.
Sin embargo, lo que he encontrado es que el comando típico de powershell de Nuevo clúster con el comando-StaticAddress no funciona. Para evitar el problema de la dirección IP duplicada, tenemos que recurrir al clúster.utilidad exe y ejecute el siguiente comando.
cluster /cluster:cluster1 /create /nodes:"sql1 sql2" /ipaddress:10.0.0.100/255.255.255.0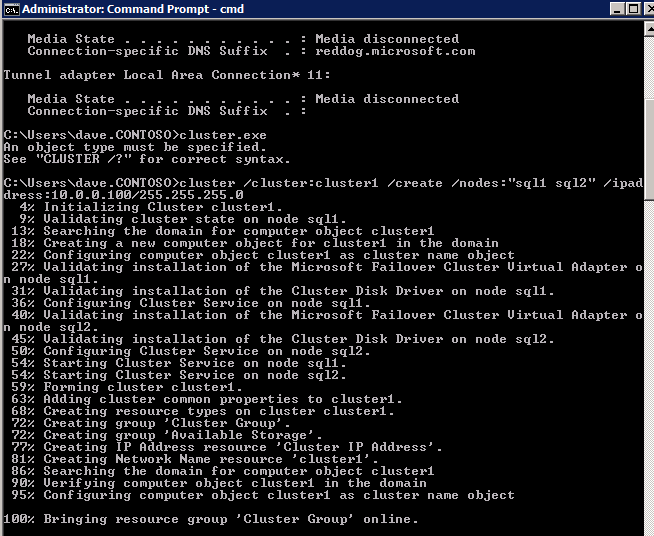
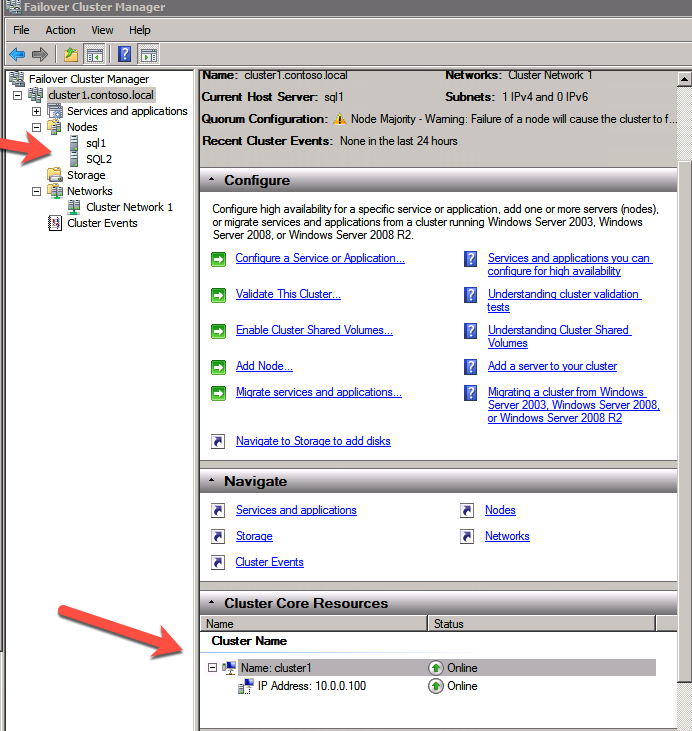
Agregar el Testigo de Uso compartido de archivos
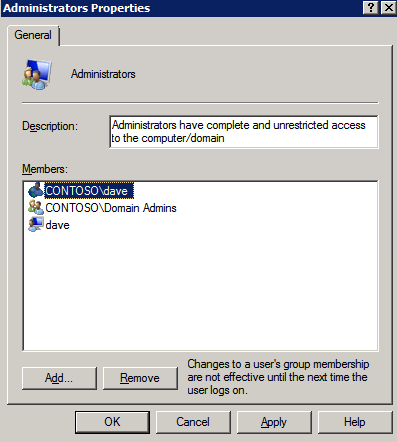
A continuación, necesitamos agregar el Testigo de Uso compartido de archivos. En el 3er servidor que aprovisionamos como FSW, cree una carpeta y compártala como se muestra a continuación. Deberá conceder permisos de lectura/escritura al Objeto de nombre de clúster (CNO) en los niveles de uso compartido y de seguridad, como se muestra a continuación.
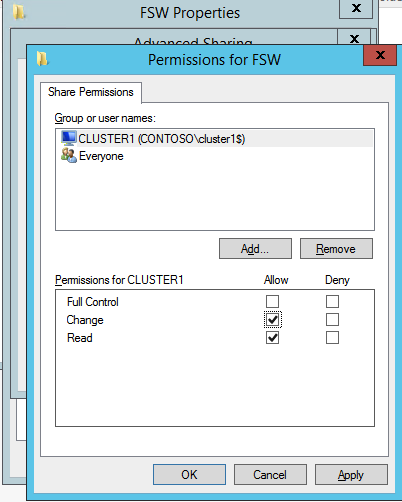
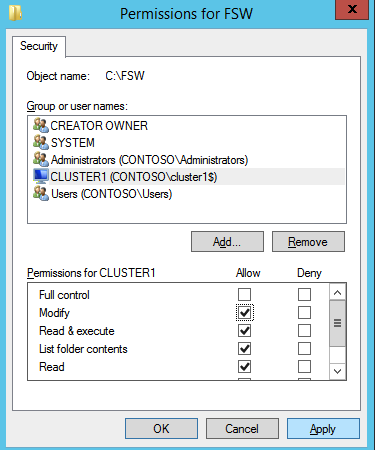
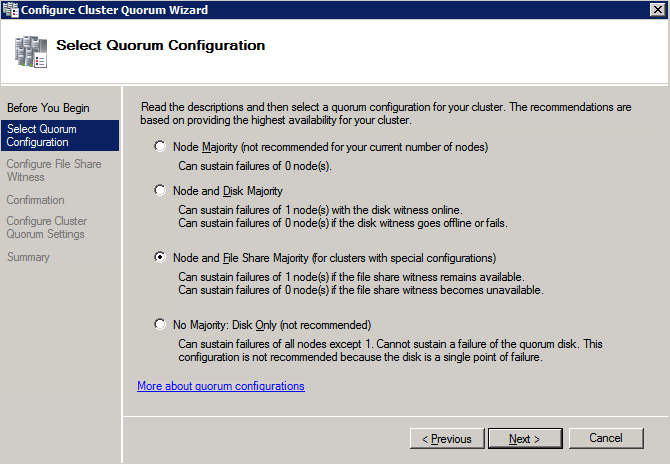
Una vez creado el recurso compartido, ejecute el asistente para configurar quórum de clúster en uno de los nodos del clúster y siga los pasos que se muestran a continuación.
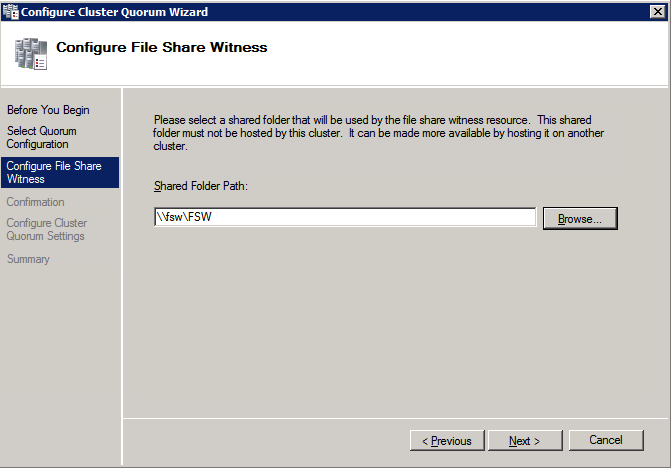
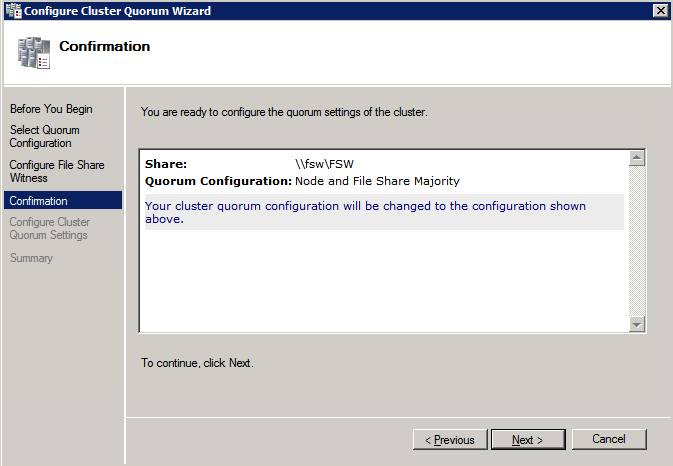
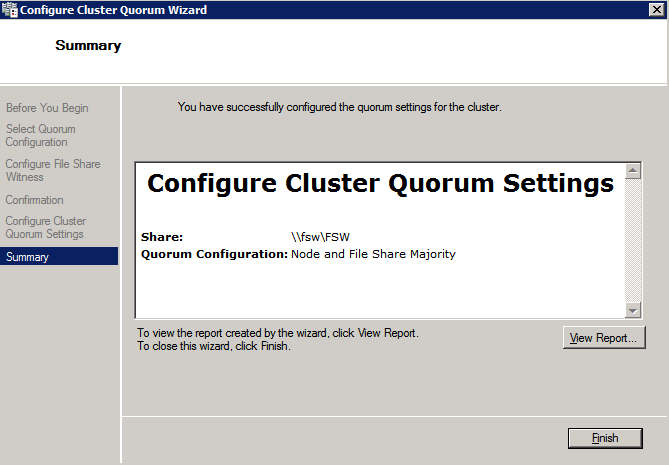
Instalar DataKeeper
Instalar DataKeeper en cada uno de los dos nodos de clúster de SQL Server, como se muestra a continuación.
Aquí es donde especificaremos la cuenta de dominio que agregamos a cada uno de los grupos de Administradores de Dominio locales.
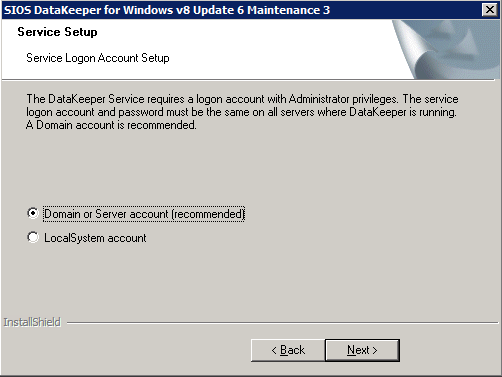
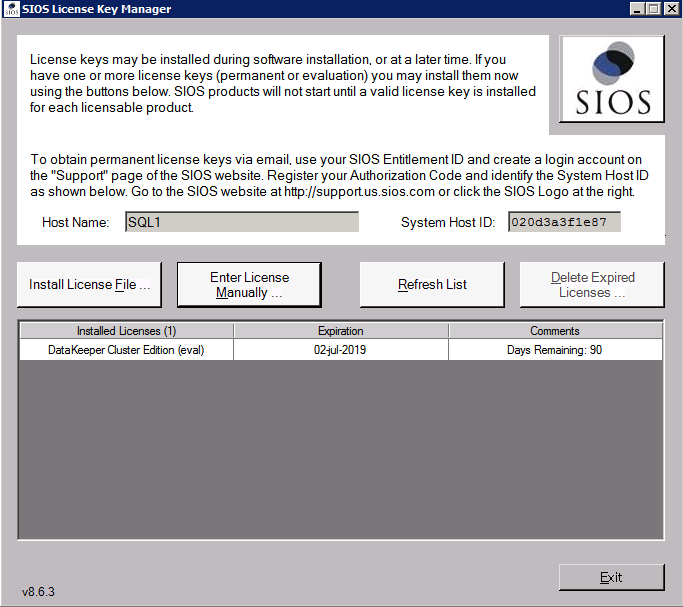
Configurar DataKeeper
Una vez instalado DataKeeper en cada uno de los dos nodos del clúster, estará listo para configurar DataKeeper.
NOTA: El error más común que se encuentra en los siguientes pasos está relacionado con la seguridad, en la mayoría de los casos debido a grupos de seguridad de Azure preexistentes que bloquean los puertos necesarios. Consulte la documentación de SIOS para asegurarse de que los servidores puedan comunicarse a través de los puertos requeridos.
Primero debe conectarse a cada uno de los dos nodos.
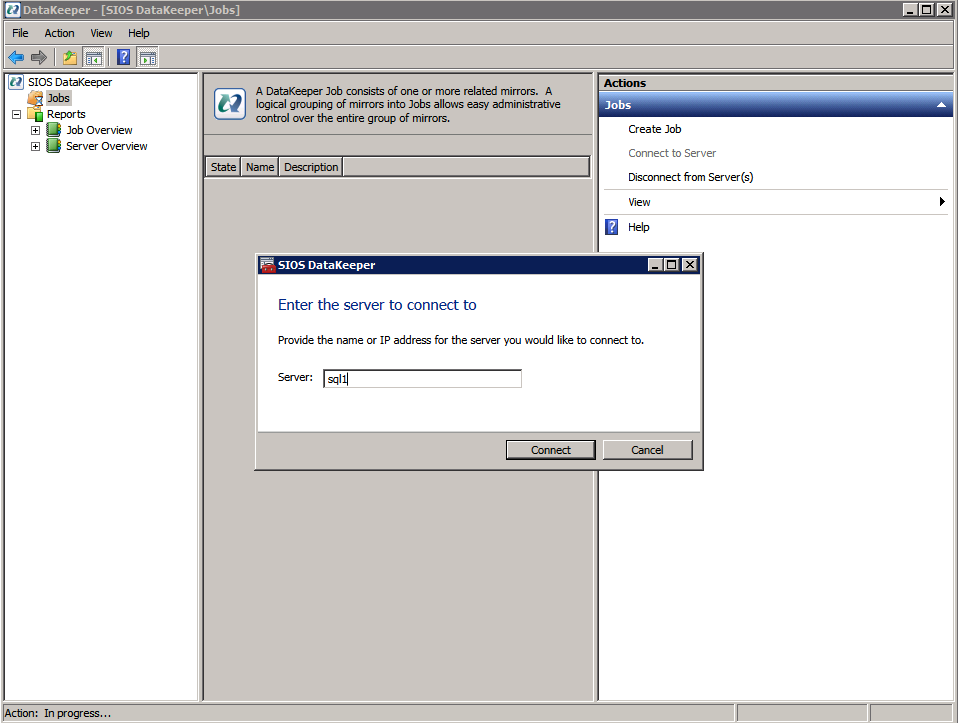
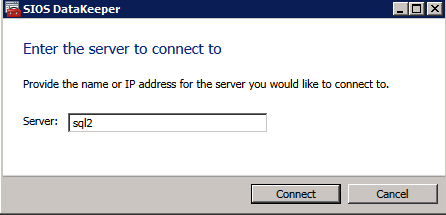
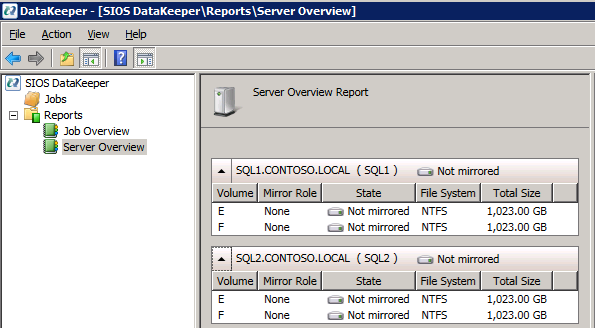
Si todo está configurado correctamente, debería ver lo siguiente en el Servidor de informe general.
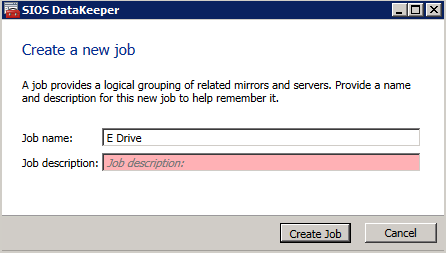
A continuación, cree un nuevo trabajo y siga los pasos que se ilustran a continuación
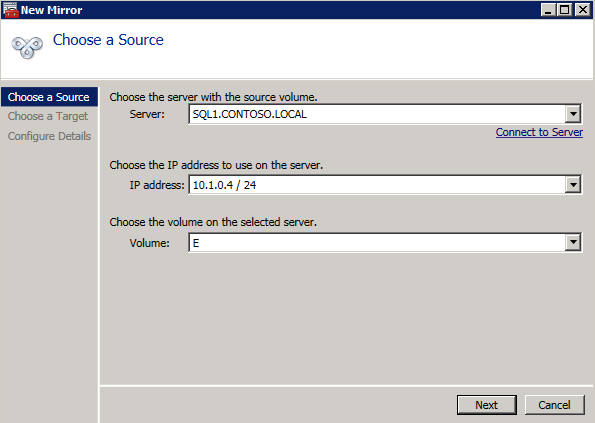
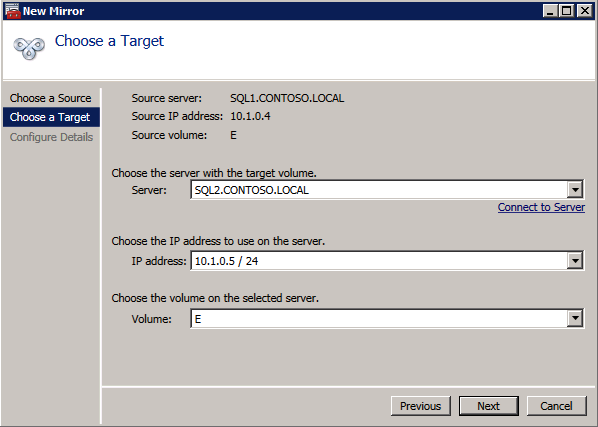
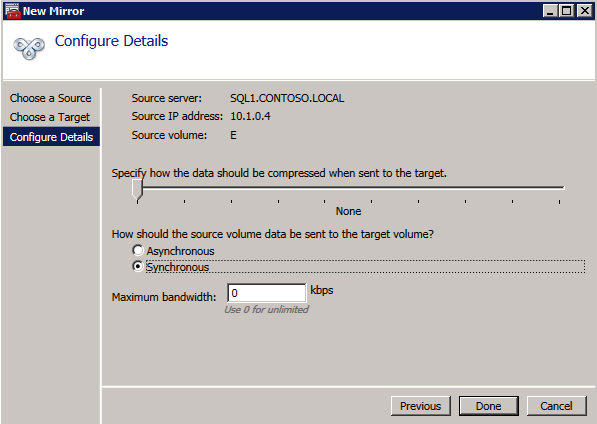
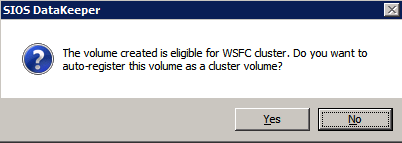
Elija Sí aquí para registrar el recurso de volumen DataKeeper en el Almacenamiento Disponible
Complete los pasos anteriores para cada uno de los volúmenes. Una vez que haya terminado, debería ver lo siguiente en la interfaz de usuario de WSFC.
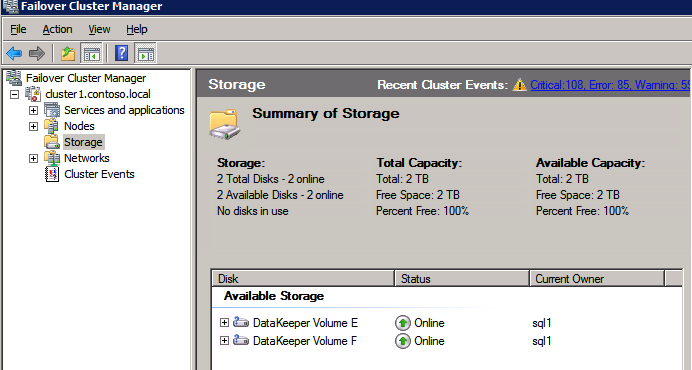
ahora está listo para instalar SQL Server en el clúster.
NOTA: En este punto, el volumen replicado solo es accesible en el nodo que aloja el almacenamiento disponible actualmente. Eso es lo que se espera, así que no te preocupes!
Instalar SQL Server en el primer nodo
Si desea crear scripts para la instalación, he incluido el ejemplo siguiente de una instalación de clúster con scripts de SQL Server 2008 R2 en el primer nodo del clúster. El script para agregar un nodo al clúster existente se encuentra más abajo en la guía.
Por supuesto, ajuste para su entorno.
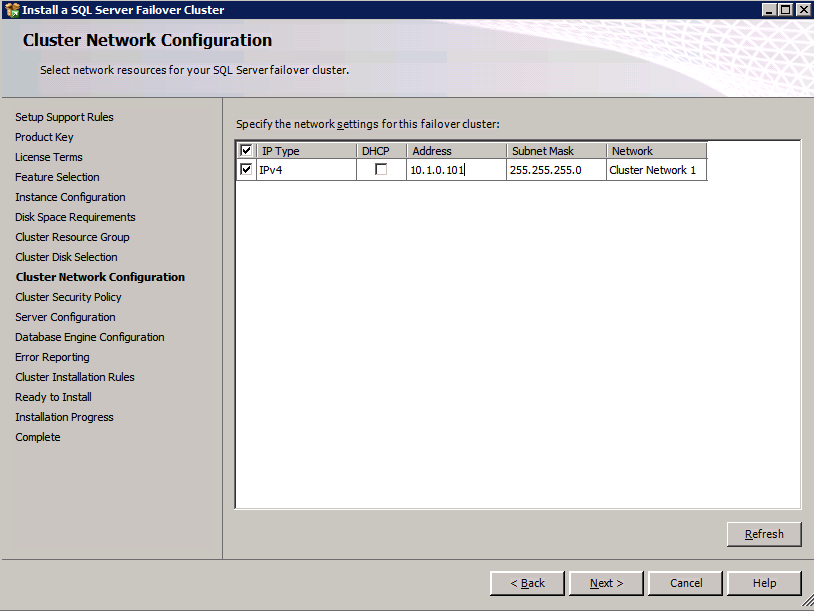
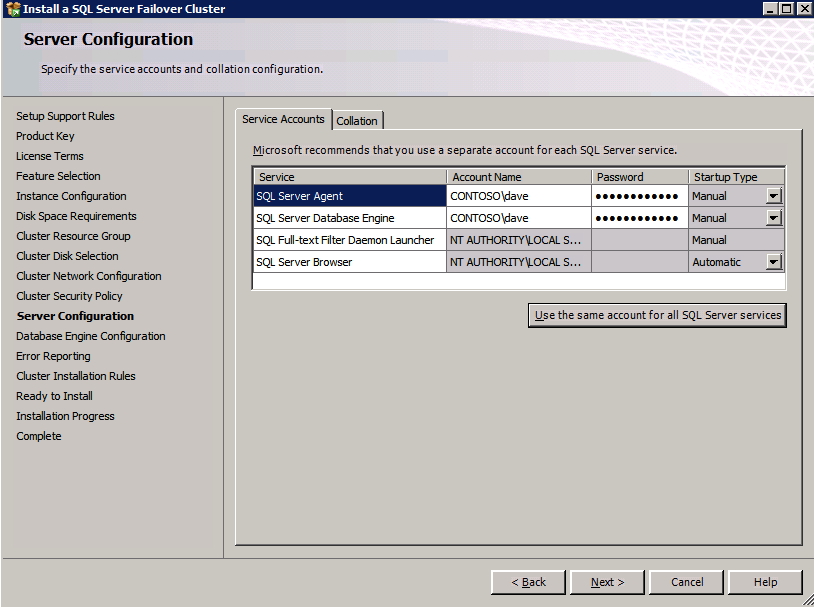
c:\SQLServerFull\setup.exe /q /ACTION=InstallFailoverCluster /FEATURES=SQL /INSTANCENAME="MSSQLSERVER" /INSTANCEDIR="C:\Program Files\Microsoft SQL Server" /INSTALLSHAREDDIR="C:\Program Files\Microsoft SQL Server" /SQLSVCACCOUNT="contoso\admin" /SQLSVCPASSWORD="xxxxxxxxx" /AGTSVCACCOUNT="contoso\admin" /AGTSVCPASSWORD="xxxxxxxxx" /SQLDOMAINGROUP="contoso\SQLAdmins" /AGTDOMAINGROUP="contoso\SQLAdmins" /SQLCOLLATION="SQL_Latin1_General_CP1_CI_AS" /FAILOVERCLUSTERGROUP="SQL Server 2008 R2 Group" /FAILOVERCLUSTERDISKS="DataKeeper Volume E" "DataKeeper Volume F" /FAILOVERCLUSTERIPADDRESSES="IPv4;10.0.0.101;Cluster Network 1;255.255.255.0" /FAILOVERCLUSTERNETWORKNAME="SQL2008Cluster" /SQLSYSADMINACCOUNTS="contoso\admin" /SQLUSERDBLOGDIR="E:\MSSQL10.MSSQLSERVER\MSSQL\Log" /SQLTEMPDBLOGDIR="F:\MSSQL10.MSSQLSERVER\MSSQL\Log" /INSTALLSQLDATADIR="F:\MSSQL10.MSSQLSERVER\MSSQLSERVER" /IAcceptSQLServerLicenseTermsSi prefiere usar la interfaz gráfica de usuario, simplemente siga las capturas de pantalla a continuación.
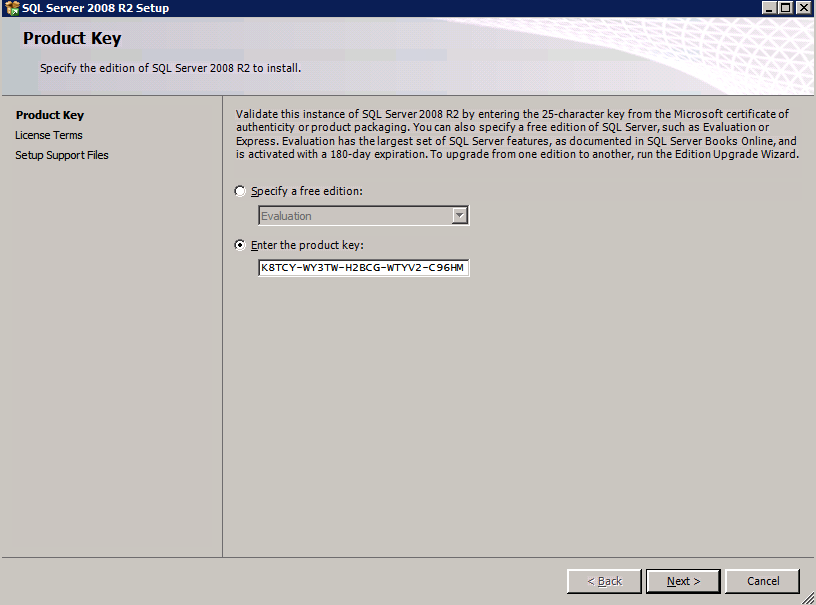
En el primer nodo, ejecute la configuración de SQL Server.
Elija Nueva instalación de clúster de conmutación por error de SQL Server y siga los pasos que se muestran en la imagen.
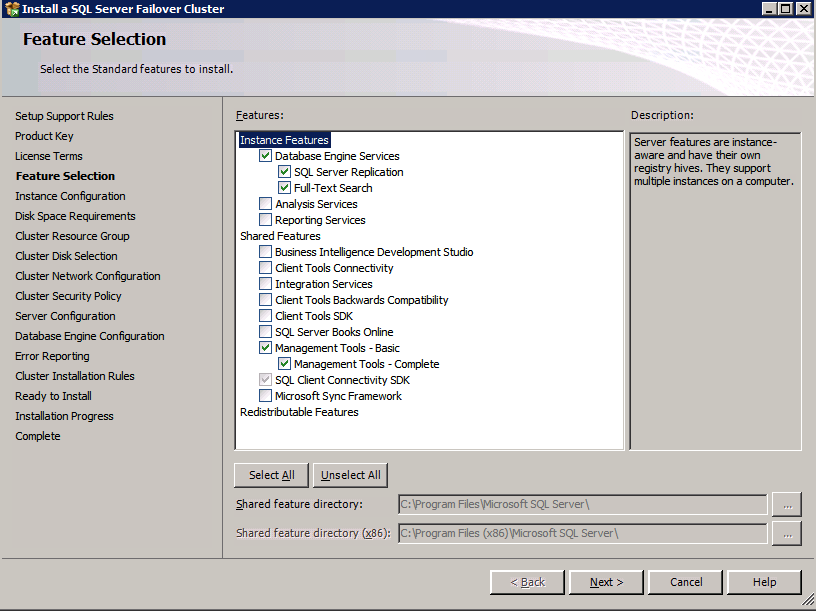
Elija sólo las opciones que usted necesita.
Tenga en cuenta que este documento asume que está utilizando la instancia predeterminada de SQL Server. Si usa una instancia con nombre, debe asegurarse de bloquear el puerto en el que escucha y usar ese puerto más adelante cuando configure el equilibrador de carga. También necesitará crear una regla de equilibrador de carga para el servicio de explorador de SQL Server (UDP 1434) para conectarse a una instancia con nombre. Ninguno de estos dos requisitos está cubierto en esta guía, pero si necesita una instancia con nombre, funcionará si realiza esos dos pasos adicionales.
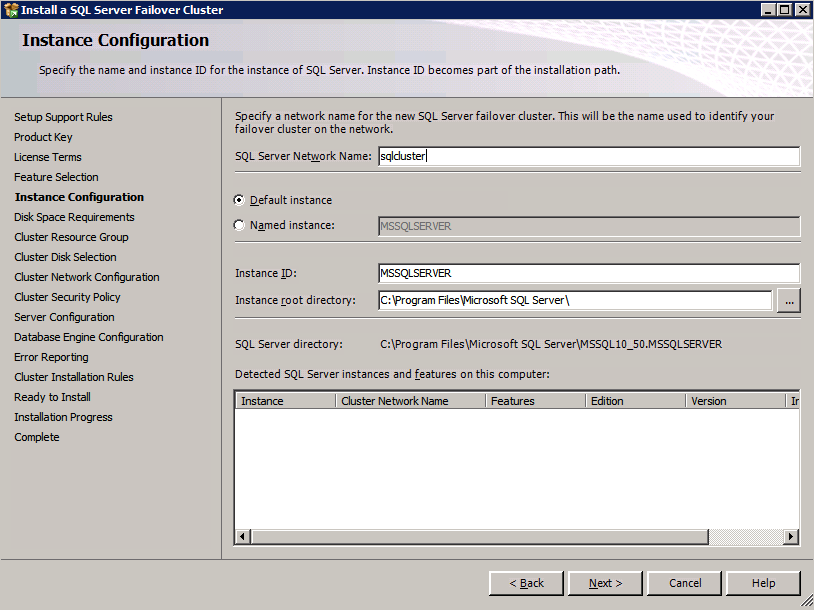
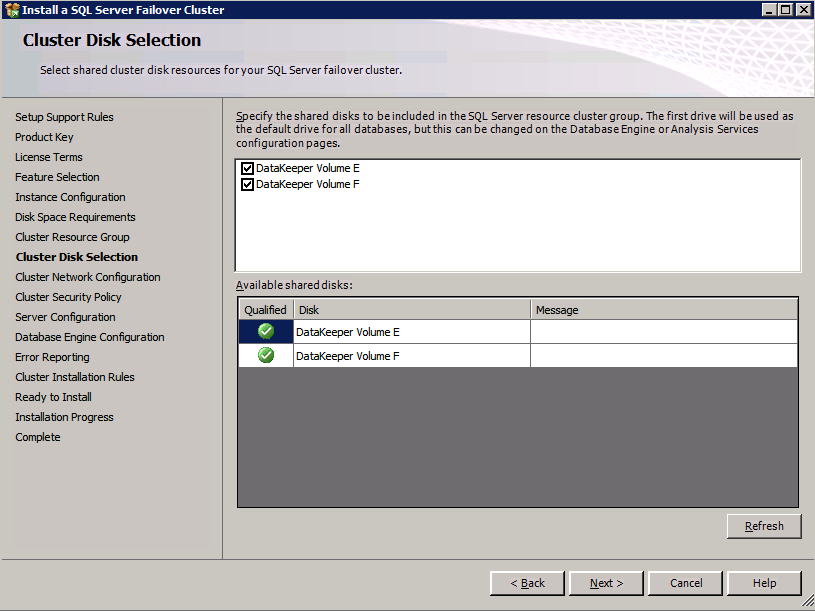
Aquí usted tendrá que especificar una dirección IP no utilizada
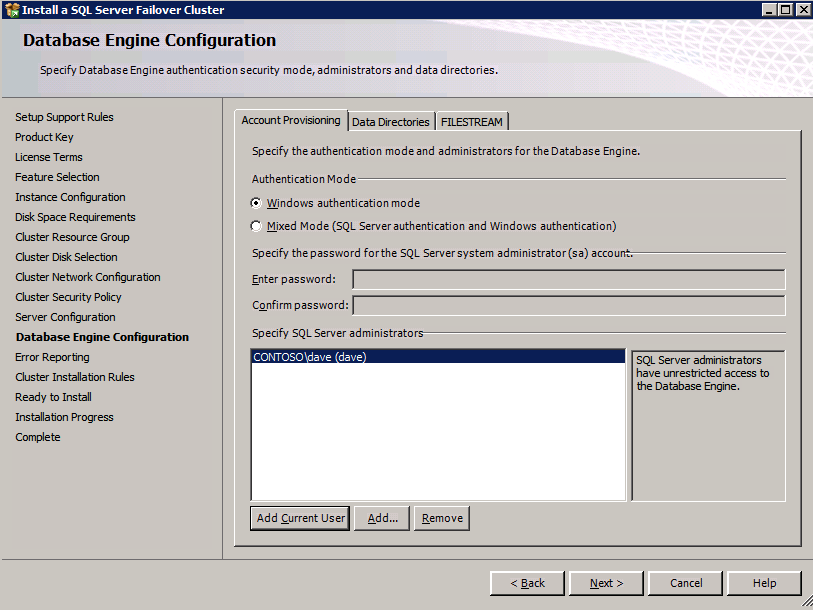
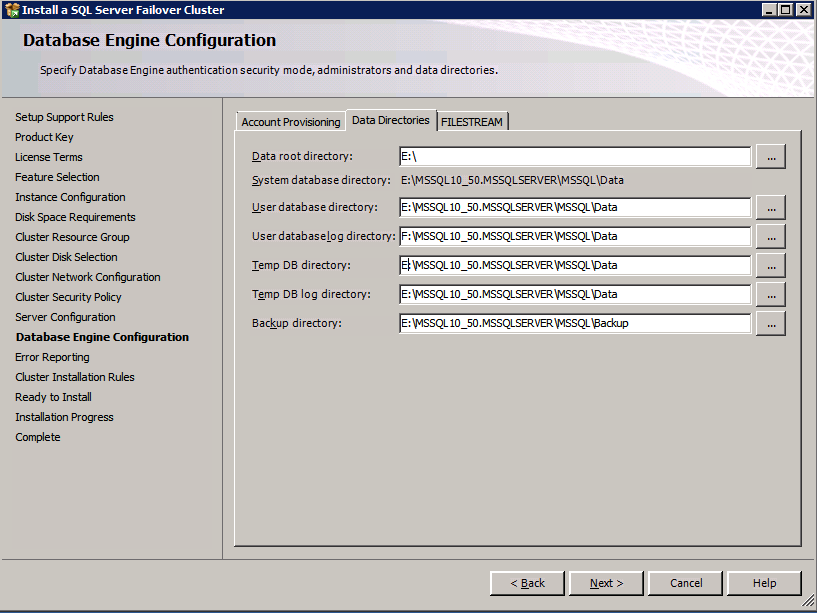
Ir a los Directorios de Datos de la ficha y reubicar a los datos y los archivos de registro. Al final de esta guía, hablamos sobre la reubicación de tempdb a un volumen DataKeeper sin espejo para un rendimiento óptimo. Por ahora, guárdelo en uno de los discos agrupados.
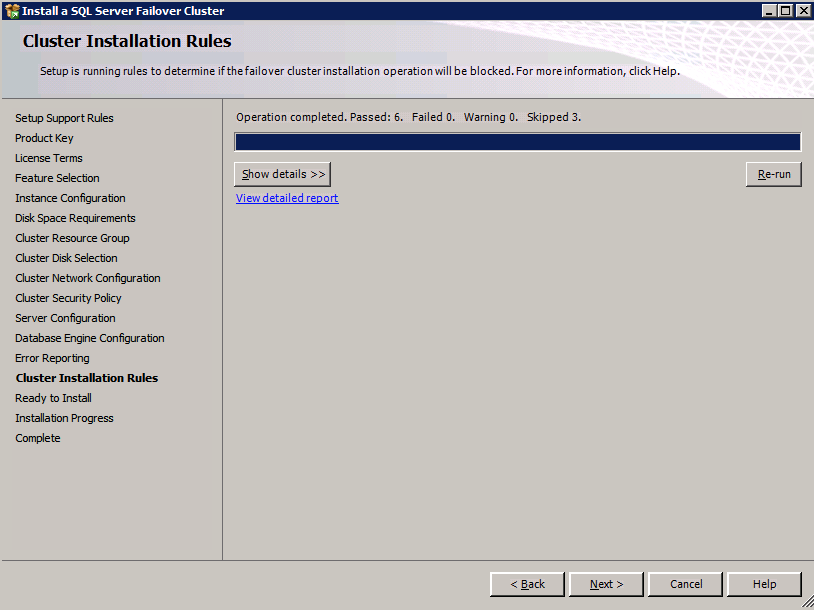
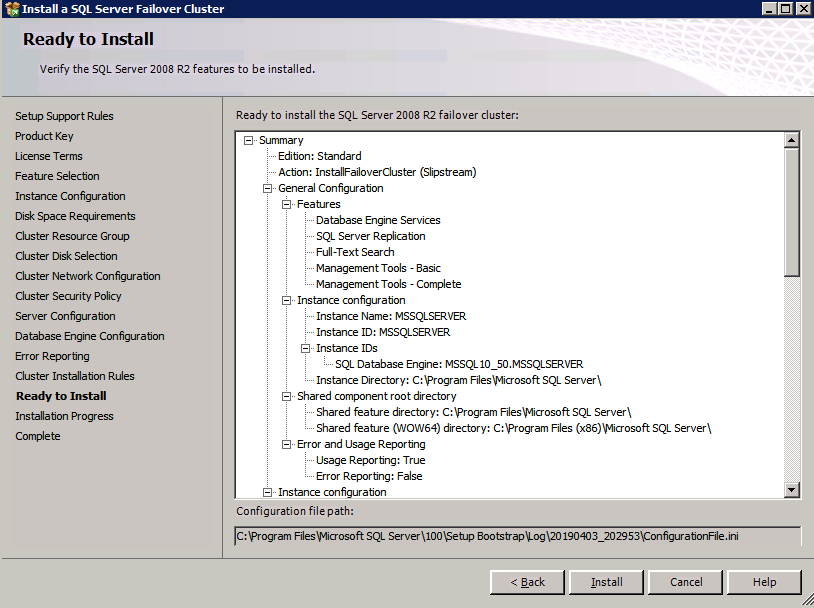
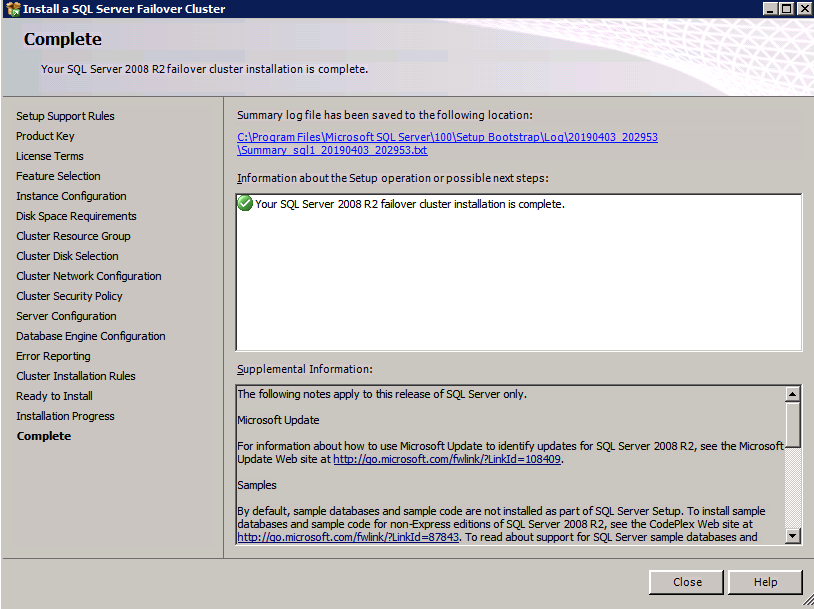
Instalar SQL Server en el segundo nodo
A continuación se muestra un ejemplo del comando que puede ejecutar para agregar un nodo R2 de SQL Server 2008 adicional a un clúster existente.
c:\SQLServerFull\setup.exe /q /ACTION=AddNode /INSTANCENAME="MSSQLSERVER" /SQLSVCACCOUNT="contoso\admin" /SQLSVCPASSWORD="xxxxxxxxx" /AGTSVCACCOUNT="contoso\admin" /AGTSVCPASSWORD="xxxxxxxx" /IAcceptSQLServerLicenseTermsSi prefiere usar la interfaz gráfica de usuario, siga las siguientes capturas de pantalla.
Ejecute de nuevo la configuración de SQL Server en el segundo nodo y elija Agregar nodo a un clúster de conmutación por error de SQL Server.
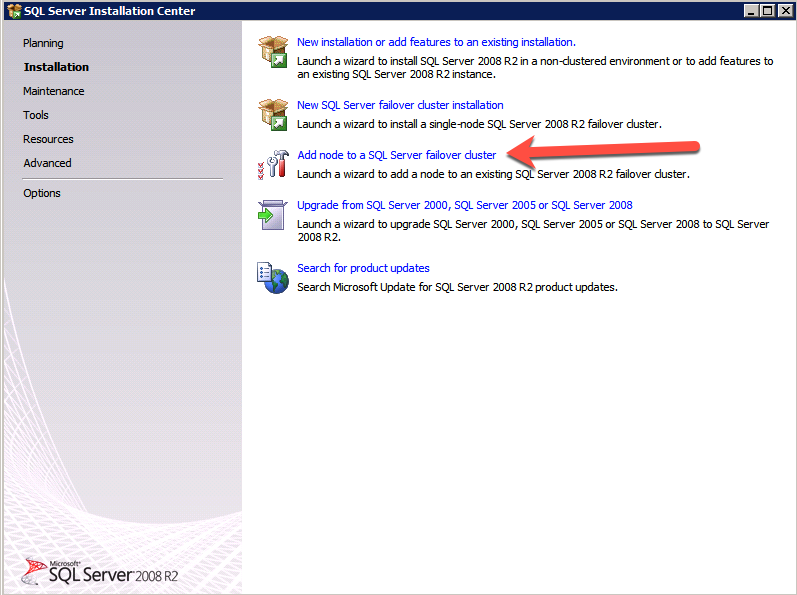
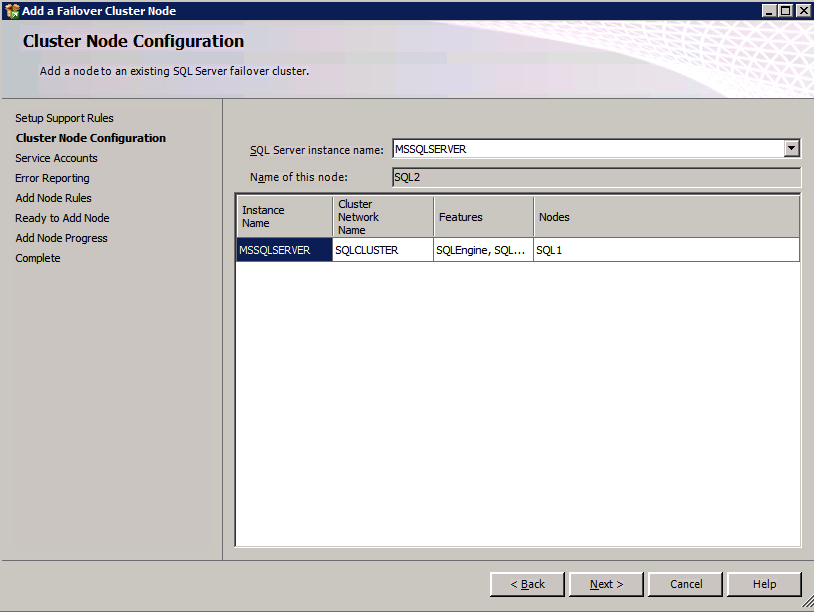
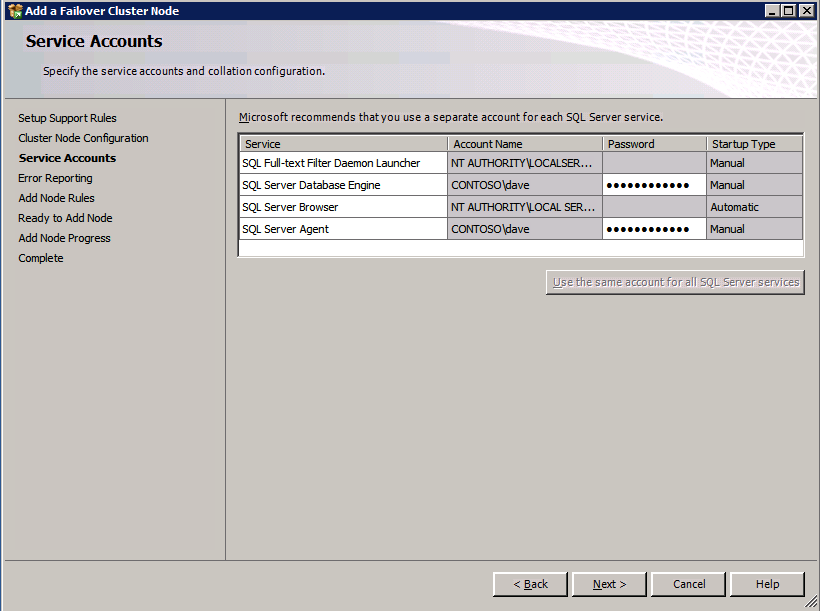
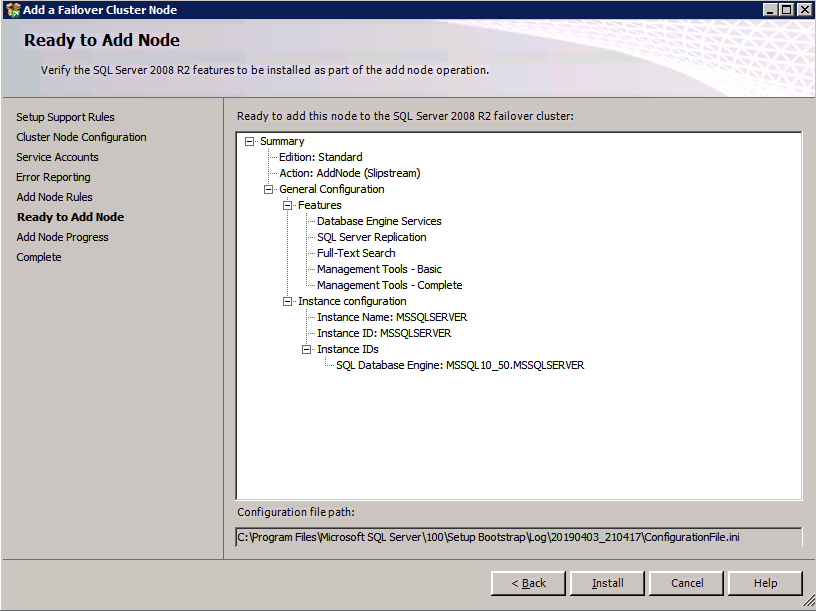
Congratulations está casi terminada! Sin embargo, debido a la falta de soporte de Azure para ARP gratuito, necesitaremos configurar un Equilibrador de carga Interno (ILB) para ayudar con la redirección de clientes, como se muestra en los siguientes pasos.
Actualizar la dirección IP del clúster SQL
Para que ILB funcione correctamente, debe ejecutar el siguiente comando desde uno de los nodos del clúster. IP de clúster SQL permite que la dirección IP del clúster SQL responda a la sonda de mantenimiento de ILB y, al mismo tiempo, establece la máscara de subred en 255.255.255.255 para evitar conflictos de direcciones IP con la sonda de mantenimiento.
cluster res <IPResourceName> /priv enabledhcp=0 address=<ILBIP> probeport=59999 subnetmask=255.255.255.255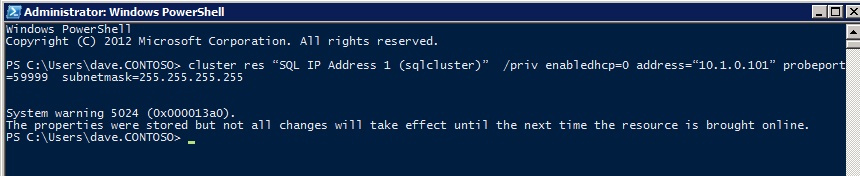
NOTA-No se si es una casualidad, pero en ocasiones he ejecutado este comando y parece que se ejecuta, pero no completa el trabajo y tengo que ejecutarlo de nuevo. La forma en que puedo saber si funcionó es mirando la Máscara de Subred del Recurso IP de SQL Server, si no es 255.255.255.255, entonces sabe que no se ejecutó correctamente. Puede ser un simple problema de actualización de la interfaz gráfica de usuario, por lo que también puede intentar reiniciar la interfaz gráfica de usuario del clúster para verificar que la máscara de subred se actualizó.
Después de que se ejecute correctamente, desconecte el recurso y vuelva a ponerlo en línea para que los cambios surtan efecto.
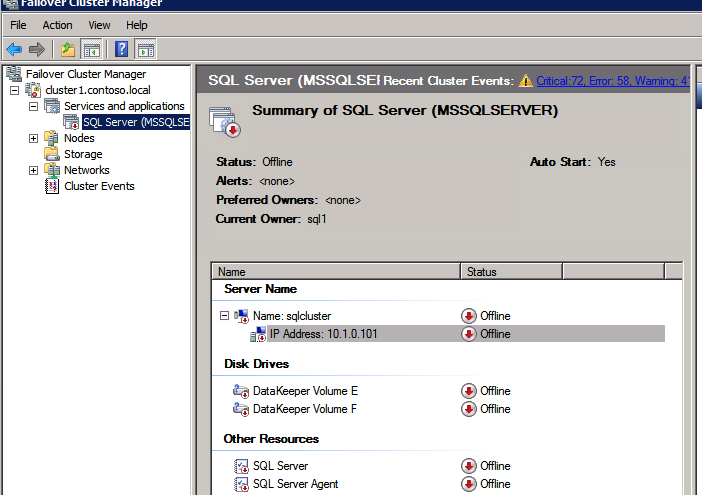
Crear el Equilibrador de Carga
El último paso es crear el equilibrador de carga. En este caso, asumimos que está ejecutando la instancia predeterminada de SQL Server, escuchando en el puerto 1433.
La dirección IP privada que defina al crear el equilibrador de carga será exactamente la misma dirección que utiliza la FCI de SQL Server.
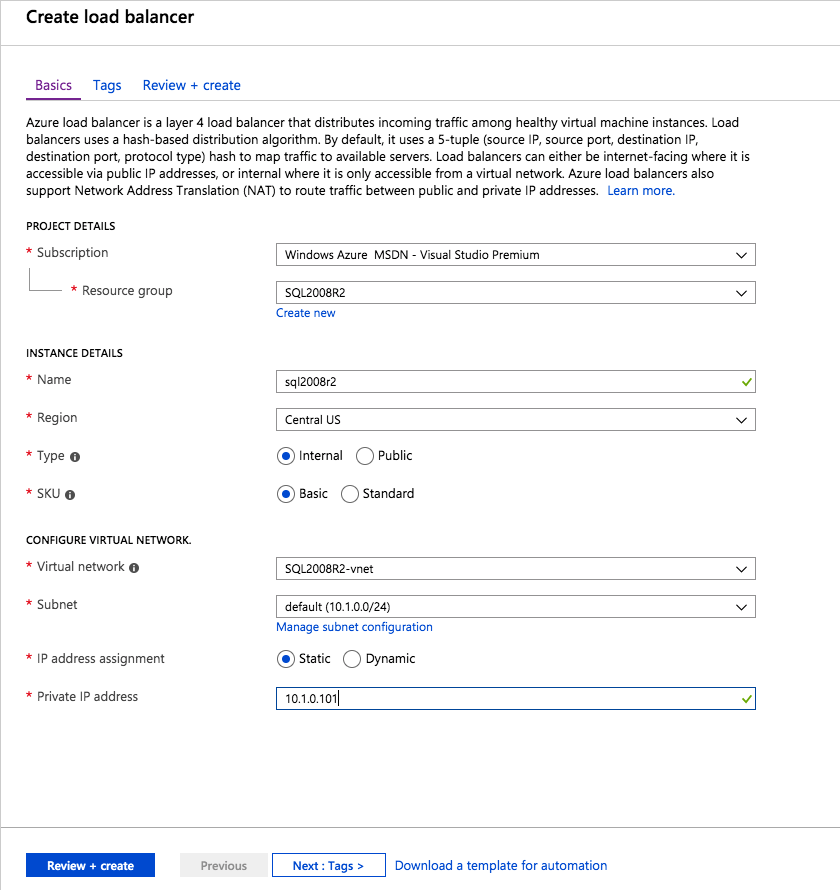
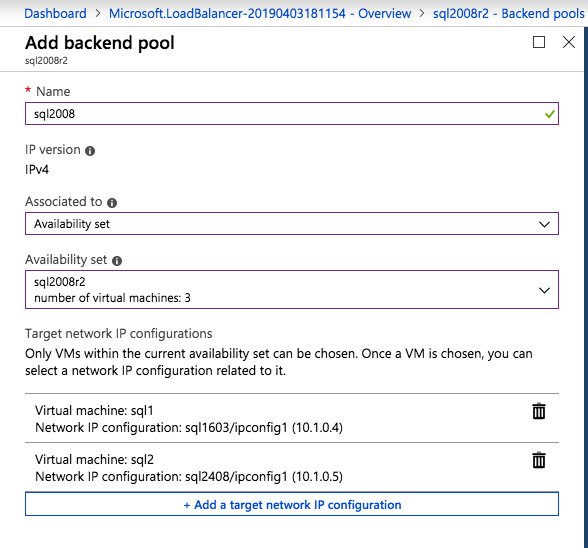
Agregue solo las dos instancias de SQL Server al grupo de backend. NO agregue el FSW al grupo de backend.
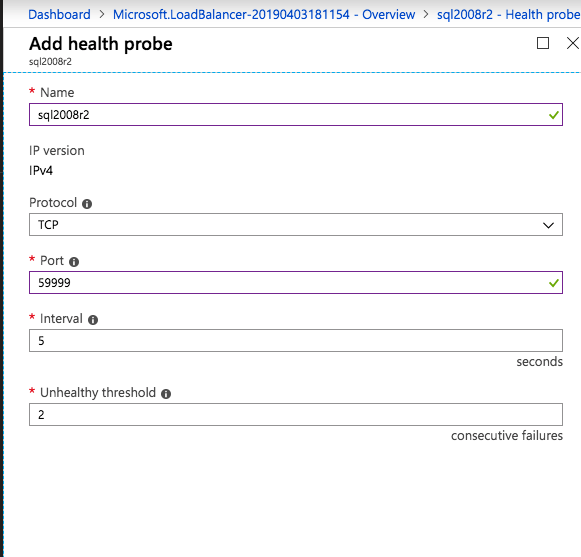
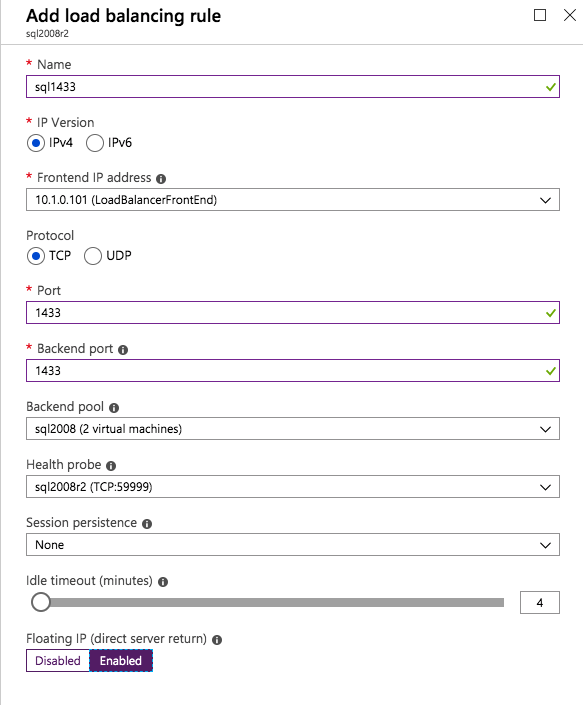
En esta regla de equilibrio de carga, debe habilitar la IP flotante
Validar el clúster
Antes de continuar, ejecute la validación del clúster una vez más. El informe de validación del clúster debe devolver las mismas advertencias de red y almacenamiento que la primera vez que lo ejecutó. Suponiendo que no haya nuevos errores o advertencias, el clúster está configurado correctamente.
Editar sqlserv.archivo de configuración exe
En el directorio C:\Program Archivos (x86)\Microsoft SQL Server\100\Tools \ Binn creamos un sqlps.exe.archivo de configuración y sqlservr.exe.configuración con las siguientes líneas en el archivo de configuración:
<configuration> <startup> <supportedRuntime version="v2.0.50727"/> </startup></configuration>Estos archivos, por defecto, no existirán y pueden ser creados. Si este archivo ya existe para su instalación, la línea <supportedRuntime version=»v2.0.50727″/> simplemente debe colocarse con la sub-sección <inicio>
Probar el clúster
La prueba más sencilla es abrir SQL Server Management Studio en el nodo pasivo y conectarse al clúster. ¡Si podéis conectar, enhorabuena, habéis hecho todo correctamente! Si no puedes conectarte, no temas, no serías la primera persona en cometer un error. Escribí un artículo de blog para ayudar a solucionar el problema. Administrar el clúster es exactamente lo mismo que administrar un clúster de almacenamiento compartido tradicional. Todo se controla a través del Administrador de clúster de conmutación por error.
Opcional: Reubicar Tempdb
Para un rendimiento óptimo, sería recomendable mover tempdb a la SSD local, no replicada. Sin embargo, SQL Server 2008 R2 requiere que tempdb esté en un disco en clúster. SIOS tiene una solución llamada Recurso de volumen no duplicado que soluciona este problema. Sería aconsejable crear un recurso de volumen no duplicado de la unidad SSD local y mover tempdb allí. Sin embargo, la unidad SSD local no es persistente, por lo que debe asegurarse de que la carpeta que contiene tempdb y los permisos de esa carpeta se vuelvan a crear cada vez que se reinicie el servidor.