Procházení webu s Pythonem

procházení webu je výkonná technika pro sběr dat z webu vyhledáním všech adres URL pro jednu nebo více domén. Python má několik populárních knihoven a rámců pro procházení webu.
v tomto článku nejprve představíme různé strategie procházení a případy použití. Poté vytvoříme jednoduchý webový prohledávač od nuly v Pythonu pomocí dvou knihoven: žádosti a krásná polévka. Dále uvidíme, proč je lepší použít rámec pro procházení webu, jako je Scrapy. Nakonec vytvoříme prolézací modul s Scrapy, který shromažďuje metadata filmu z IMDb a uvidí, jak se Scrapy mění na webové stránky s několika miliony stránek.
co je webový prohledávač?
procházení webu a škrábání webu jsou dva různé, ale související pojmy. Procházení webu je součástí škrabání na webu, logika prohledávače najde adresy URL, které mají být zpracovány kódem škrabky.
webový prohledávač začíná seznamem adres URL, které chcete navštívit, nazvaný semeno. Pro každou adresu URL prohledávač najde odkazy v HTML, filtruje tyto odkazy na základě některých kritérií a přidá nové odkazy do fronty. Všechny HTML nebo některé konkrétní informace jsou extrahovány, aby byly zpracovány jiným potrubím.
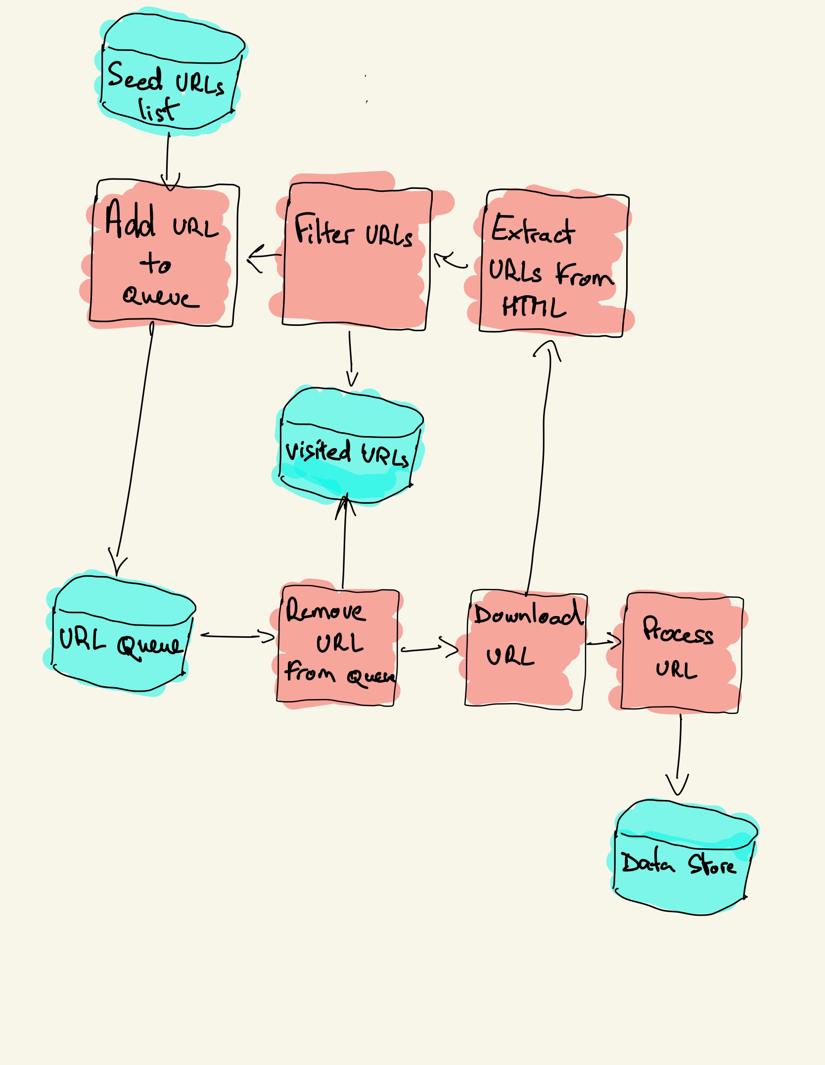
strategie procházení webu
v praxi webové prohledávače navštěvují pouze podmnožinu stránek v závislosti na rozpočtu prohledávače, což může být maximální počet stránek na doménu, hloubku nebo dobu provádění.
nejoblíbenější webové stránky poskytují roboty.txt soubor označující, které oblasti webu jsou zakázány procházet každým agentem uživatele. Opakem souboru robotů je soubor sitemap.xml soubor, který obsahuje seznam stránek, které lze procházet.
mezi oblíbené případy použití webového prohledávače patří:
- vyhledávače (Googlebot, Bingbot, Yandex Bot…) shromažďují veškerý HTML pro významnou část webu. Tato data jsou indexována, aby byla prohledávatelná.
- nástroje SEO analytics kromě shromažďování HTML také shromažďují metadata, jako je doba odezvy, stav odezvy pro detekci rozbitých stránek a odkazy mezi různými doménami pro shromažďování zpětných odkazů.
- nástroje pro monitorování cen procházejte webové stránky elektronického obchodování a najděte stránky produktů a extrahujte metadata, zejména cenu. Stránky produktů jsou pak pravidelně revidovány.
- Common Crawl udržuje otevřené úložiště dat procházení webu. Například archiv z října 2020 obsahuje 2,71 miliardy webových stránek.
dále porovnáme tři různé strategie pro vytváření webového prohledávače v Pythonu. Nejprve pomocí standardních knihoven, poté knihoven třetích stran pro vytváření požadavků HTTP a analýzu HTML a nakonec webového prolézacího rámce.
vytvoření jednoduchého webového prohledávače v Pythonu od nuly
Chcete-li vytvořit jednoduchý webový prohledávač v Pythonu, potřebujeme alespoň jednu knihovnu ke stažení HTML z adresy URL a HTML parsovací knihovnu k extrahování odkazů. Python poskytuje standardní knihovny urllib pro vytváření požadavků HTTP a html.analyzátor pro analýzu HTML. Příklad Python crawler postavený pouze se standardními knihovnami lze nalézt na Github.
standardní knihovny Pythonu pro požadavky a analýzu HTML nejsou příliš přátelské pro vývojáře. Další populární knihovny, jako jsou žádosti, značkové jako HTTP pro lidi, a krásná polévka poskytují lepší zážitek pro vývojáře.
pokud se chcete dozvědět více, můžete si přečíst tuto příručku o nejlepším klientovi Python HTTP.
obě knihovny můžete nainstalovat lokálně.
pip install requests bs4základní prolézací modul lze sestavit podle předchozího diagramu architektury.
import loggingfrom urllib.parse import urljoinimport requestsfrom bs4 import BeautifulSouplogging.basicConfig( format='%(asctime)s %(levelname)s:%(message)s', level=logging.INFO)class Crawler: def __init__(self, urls=): self.visited_urls = self.urls_to_visit = urls def download_url(self, url): return requests.get(url).text def get_linked_urls(self, url, html): soup = BeautifulSoup(html, 'html.parser') for link in soup.find_all('a'): path = link.get('href') if path and path.startswith('/'): path = urljoin(url, path) yield path def add_url_to_visit(self, url): if url not in self.visited_urls and url not in self.urls_to_visit: self.urls_to_visit.append(url) def crawl(self, url): html = self.download_url(url) for url in self.get_linked_urls(url, html): self.add_url_to_visit(url) def run(self): while self.urls_to_visit: url = self.urls_to_visit.pop(0) logging.info(f'Crawling: {url}') try: self.crawl(url) except Exception: logging.exception(f'Failed to crawl: {url}') finally: self.visited_urls.append(url)if __name__ == '__main__': Crawler(urls=).run()výše uvedený kód definuje třídu prohledávačů s pomocnými metodami pro download_url pomocí knihovny požadavků, get_linked_urls pomocí knihovny Beautiful Soup a add_url_to_visit pro filtrování adres URL. Adresy URL, které chcete navštívit, a navštívené adresy URL jsou uloženy ve dvou samostatných seznamech. Prohledávač můžete spustit na svém terminálu.
python crawler.pyprohledávač zaznamenává jeden řádek pro každou navštívenou adresu URL.
2020-12-04 18:10:10,737 INFO:Crawling: https://www.imdb.com/2020-12-04 18:10:11,599 INFO:Crawling: https://www.imdb.com/?ref_=nv_home2020-12-04 18:10:12,868 INFO:Crawling: https://www.imdb.com/calendar/?ref_=nv_mv_cal2020-12-04 18:10:13,526 INFO:Crawling: https://www.imdb.com/list/ls016522954/?ref_=nv_tvv_dvd2020-12-04 18:10:19,174 INFO:Crawling: https://www.imdb.com/chart/top/?ref_=nv_mv_2502020-12-04 18:10:20,624 INFO:Crawling: https://www.imdb.com/chart/moviemeter/?ref_=nv_mv_mpm2020-12-04 18:10:21,556 INFO:Crawling: https://www.imdb.com/feature/genre/?ref_=nv_ch_grkód je velmi jednoduchý, ale před úspěšným procházením kompletního webu je třeba vyřešit mnoho problémů s výkonem a použitelností.
- prolézací modul je pomalý a nepodporuje paralelismus. Jak je vidět z časových razítek, procházení každé adresy URL trvá asi jednu sekundu. Pokaždé, když prohledávač podá požadavek, čeká na vyřešení požadavku a mezi tím se neprovádí žádná práce.
- logika URL stahování nemá mechanismus opakování, fronta URL není skutečná fronta a není příliš efektivní s vysokým počtem adres URL.
- logika extrakce odkazů nepodporuje standardizaci adres URL odstraněním parametrů řetězce dotazu URL, nezpracovává adresy URL začínající#, nepodporuje filtrování adres URL podle domény nebo filtrování požadavků na statické soubory.
- prohledávač se neidentifikuje a ignoruje roboty.txt soubor.
dále uvidíme, jak Scrapy poskytuje všechny tyto funkce a usnadňuje rozšíření pro vaše vlastní procházení.
Web crawling with Scrapy
Scrapy je nejoblíbenější webový scraping a procházení Python framework s 40k hvězdami na Githubu. Jednou z výhod Scrapy je, že požadavky jsou naplánovány a zpracovávány asynchronně. To znamená, že Scrapy může odeslat další požadavek před dokončením předchozího nebo provést nějakou jinou práci mezi tím. Scrapy zvládne mnoho souběžných požadavků, ale může být také nakonfigurován tak, aby respektoval webové stránky s vlastními nastaveními, jak uvidíme později.
Scrapy má vícesložkovou architekturu. Normálně budete implementovat alespoň dvě různé třídy: Spider a Pipeline. Webové škrábání lze považovat za ETL, kde extrahujete data z webu a nahrajete je do vlastního úložiště. Pavouci extrahují data a potrubí je načtou do úložiště. Transformace se může stát jak v pavoucích, tak v potrubí, ale doporučuji nastavit vlastní Scrapy potrubí pro transformaci každé položky nezávisle na sobě. Tímto způsobem nemá zpracování položky žádný vliv na jiné položky.
kromě toho můžete mezi komponenty přidat Spider a downloader middlewares, jak je vidět na obrázku níže.
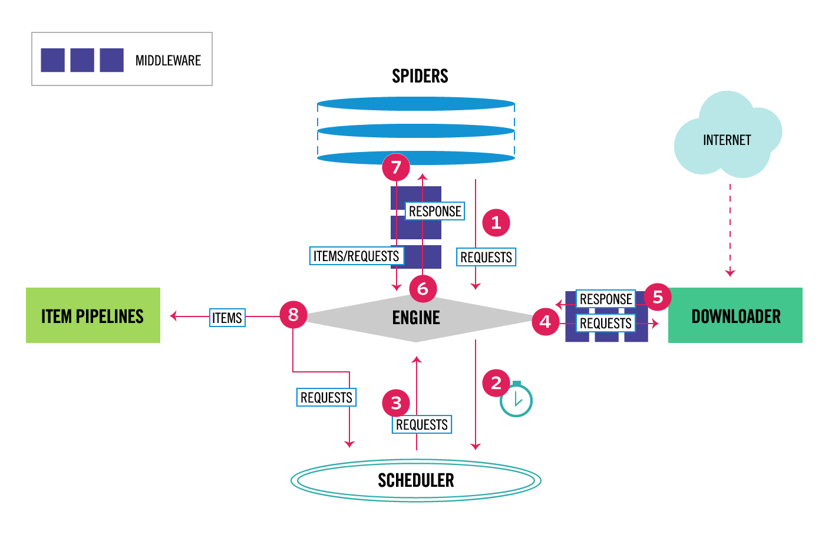
přehled architektury Scrapy
pokud jste Scrapy použili dříve, víte, že webová škrabka je definována jako třída, která dědí ze základní třídy Spider a implementuje metodu analýzy pro zpracování každé odpovědi. Pokud jste novým Scrapy, můžete si přečíst tento článek pro snadné škrábání pomocí Scrapy.
from scrapy.spiders import Spiderclass ImdbSpider(Spider): name = 'imdb' allowed_domains = start_urls = def parse(self, response): passScrapy také poskytuje několik generických tříd pavouků: CrawlSpider, XMLFeedSpider, CSVFeedSpider a SitemapSpider. Třída CrawlSpider dědí ze základní třídy Spider a poskytuje další atribut pravidel, který definuje, jak procházet web. Každé pravidlo používá LinkExtractor určit, které odkazy jsou extrahovány z každé stránky. Dále uvidíme, jak používat každý z nich vytvořením prohledávacího modulu pro IMDb, Internet Movie Database.
vytvoření příkladu Scrapy crawler pro IMDb
než se pokusíte procházet IMDb, zkontroloval jsem IMDb roboty.txt soubor zjistit, které cesty URL jsou povoleny. Soubor robotů zakazuje pouze 26 cest pro všechny uživatele-agenty. Scrapy čte roboty.txt soubor předem a respektuje jej, když je nastavení ROBOTSTXT_OBEY nastaveno na hodnotu true. To je případ všech projektů generovaných příkazem Scrapy startproject.
scrapy startproject scrapy_crawlertento příkaz vytvoří nový projekt s výchozí strukturou složek projektu Scrapy.
scrapy_crawler/├── scrapy.cfg└── scrapy_crawler ├── __init__.py ├── items.py ├── middlewares.py ├── pipelines.py ├── settings.py └── spiders ├── __init__.pypak můžete vytvořit pavouka v scrapy_crawler/spiders/imdb.py s pravidlem extrahovat všechny odkazy.
from scrapy.spiders import CrawlSpider, Rulefrom scrapy.linkextractors import LinkExtractorclass ImdbCrawler(CrawlSpider): name = 'imdb' allowed_domains = start_urls = rules = (Rule(LinkExtractor()),)prohledávač můžete spustit v terminálu.
scrapy crawl imdb --logfile imdb.logzískáte spoustu protokolů, včetně jednoho protokolu pro každý požadavek. Při zkoumání protokolů jsem si všiml, že i když jsme nastavili allowed_domains pouze pro procházení webových stránek pod https://www.imdb.com, existovaly požadavky na externí domény, jako například amazon.com.
2020-12-06 12:25:18 DEBUG: Redirecting (302) to <GET https://www.amazon.com/b/?&node=5160028011&ref_=ft_iba> from <GET (https://www.imdb.com/whitelist-offsite?url=https%3A%2F%2Fwww.amazon.com%2Fb%2F%3F%26node%3D5160028011%26ref_%3Dft_iba&page-action=ft-iba&ref=ft_iba)>IMDb přesměruje z adres URL cesty pod whitelist-offsite a whitelist na externí domény. K dispozici je otevřený Scrapy GitHub problém, který ukazuje, že externí adresy URL nejsou odfiltrovány, když je použit OffsiteMiddleware před RedirectMiddleware. Chcete-li tento problém vyřešit, můžeme nakonfigurovat extraktor odkazů tak, aby odepřel adresy URL začínající dvěma regulárními výrazy.
class ImdbCrawler(CrawlSpider): name = 'imdb' allowed_domains = start_urls = rules = ( Rule(LinkExtractor( deny=, )), )třídy Rule a LinkExtractor podporují několik argumentů pro odfiltrování adres URL. Můžete například ignorovat konkrétní přípony URL a snížit počet duplicitních adres URL tříděním řetězců dotazů. Pokud nenajdete konkrétní argument pro váš případ použití, můžete předat vlastní funkci process_links v Lintextractor nebo process_values v pravidle.
například IMDb má dvě různé adresy URL se stejným obsahem.
https://www.imdb.com/jméno / nm1156914/
https://www.imdb.com/jméno / nm1156914/?mode = desktop& ref_=m_ft_dsk
Chcete-li omezit počet procházených adres URL, můžeme odstranit všechny řetězce dotazů z adres URL pomocí funkce url_query_cleaner z knihovny w3lib a použít ji v process_links.
from w3lib.url import url_query_cleanerdef process_links(links): for link in links: link.url = url_query_cleaner(link.url) yield linkclass ImdbCrawler(CrawlSpider): name = 'imdb' allowed_domains = start_urls = rules = ( Rule(LinkExtractor( deny=, ), process_links=process_links), )Nyní, když jsme omezili počet požadavků na zpracování, můžeme přidat metodu parse_item pro extrahování dat z každé stránky a předat je do potrubí pro jejich uložení. Například můžeme buď extrahovat celou odpověď.text pro zpracování v jiném potrubí nebo výběr metadat HTML. Chcete-li vybrat metadata HTML ve značce záhlaví, můžeme kódovat vlastní Xpathy, ale považuji za lepší použít knihovnu, extruct, která extrahuje všechna metadata ze stránky HTML. Můžete jej nainstalovat pomocí pip install extract.
import refrom scrapy.linkextractors import LinkExtractorfrom scrapy.spiders import CrawlSpider, Rulefrom w3lib.url import url_query_cleanerimport extructdef process_links(links): for link in links: link.url = url_query_cleaner(link.url) yield linkclass ImdbCrawler(CrawlSpider): name = 'imdb' allowed_domains = start_urls = rules = ( Rule( LinkExtractor( deny=, ), process_links=process_links, callback='parse_item', follow=True ), ) def parse_item(self, response): return { 'url': response.url, 'metadata': extruct.extract( response.text, response.url, syntaxes= ), }nastavil jsem atribut follow Na True, takže Scrapy stále sleduje všechny odkazy z každé odpovědi, i když jsme poskytli vlastní metodu analýzy. Také jsem nakonfiguroval extruct extrahovat pouze Open Graph metadata a JSON-LD, populární metoda pro kódování propojených dat pomocí JSON na webu, používá IMDb. Můžete spustit prohledávač a ukládat položky ve formátu JSON lines do souboru.
scrapy crawl imdb --logfile imdb.log -o imdb.jl -t jsonlinesvýstupní soubor imdb.jl obsahuje jeden řádek pro každou procházenou položku. Například extrahovaná metadata otevřeného grafu pro film převzatá ze značek <meta> v HTML vypadá takto.
{ "url": "http://www.imdb.com/title/tt2442560/", "metadata": {"opengraph": , , , , , ] }]}}JSON-LD pro jednu položku je příliš dlouhý na to, aby byl zahrnut do článku, zde je ukázka toho, co Scrapy výtažky z <script type=“application/ld+json“ > tag.
"json-ld": , "contentRating": "TV-MA", "actor": ... }]při zkoumání protokolů jsem si všiml dalšího běžného problému s prohledávači. Postupným kliknutím na filtry prolézací modul generuje adresy URL se stejným obsahem, pouze pokud byly filtry použity v jiném pořadí.
https://www.imdb.com/name / nm2900465 / videogalerie / content_type-trailer/related_titles-tt0479468
https://www.imdb.com/name / nm2900465 / videogalerie / related_titles-tt0479468 / content_type-trailer
dlouhý filtr a vyhledávací adresy URL je obtížný problém, který lze částečně vyřešit omezením délky adres URL s nastavením Scrapy, URLLENGTH_LIMIT.
jako příklad jsem použil IMDb, abych ukázal základy vytváření webového prolézacího modulu v Pythonu. Nenechal jsem prohledávač běžet dlouho, protože jsem neměl konkrétní případ použití dat. V případě, že potřebujete konkrétní data z IMDb, můžete zkontrolovat Projekt IMDb Datasets, který poskytuje denní export dat IMDb a IMDbPY, balíček Python pro načítání a správu dat.
procházení webu v měřítku
pokud se pokusíte procházet velké webové stránky, jako je IMDb, s více než 45M stránkami založenými na Googlu, je důležité procházet zodpovědně konfigurací následujících nastavení. Můžete identifikovat svůj prohledávač a poskytnout kontaktní údaje v nastavení BOT_NAME. Chcete-li omezit tlak vyvíjený na webové servery, můžete zvýšit DOWNLOAD_DELAY, omezit CONCURRENT_REQUESTS_PER_DOMAIN nebo nastavit AUTOTHROTTLE_ENABLED, který tato nastavení dynamicky přizpůsobí na základě doby odezvy ze serveru.
Všimněte si, že Scrapy procházení jsou optimalizovány pro jednu doménu ve výchozím nastavení. Pokud procházíte více domén, zkontrolujte tato nastavení, abyste optimalizovali široké procházení, včetně změny výchozího pořadí procházení z hloubky na dech. Chcete-li omezit rozpočet procházení, můžete omezit počet požadavků nastavením CLOSESPIDER_PAGECOUNT v rozšíření close spider.
s výchozím nastavením Scrapy prochází asi 600 stránek za minutu pro web, jako je IMDb. Procházení 45M stránek bude trvat déle než 50 dní pro jednoho robota. Pokud potřebujete procházet více webů, může být lepší spustit samostatné prohledávače pro každý velký web nebo skupinu webů. Máte-li zájem o distribuované webové procházení, můžete si přečíst, jak vývojář procházel 250M stránky s Pythonem za 40 hodin pomocí 20 instancí stroje Amazon EC2.
v některých případech můžete narazit na webové stránky, které vyžadují spuštění kódu JavaScript k vykreslení veškerého HTML. Pokud tak neučiníte, nemusíte shromažďovat všechny odkazy na webových stránkách. Protože v dnešní době je velmi běžné, že webové stránky dynamicky vykreslují obsah v prohlížeči, napsal jsem Scrapy middleware pro vykreslování stránek JavaScript pomocí rozhraní API ScrapingBee.
závěr
porovnali jsme kód prolézacího modulu Python pomocí knihoven třetích stran pro stahování adres URL a analýzu HTML s prolézacím strojem vytvořeným pomocí populárního webového prolézacího rámce. Scrapy je velmi výkonný rámec pro procházení webu a je snadné jej rozšířit pomocí vlastního kódu. Musíte však znát všechna místa, kde můžete připojit svůj vlastní kód a nastavení pro každou součást.
správná konfigurace Scrapy se stává ještě důležitější při procházení webových stránek s miliony stránek. Pokud se chcete dozvědět více o procházení webu, doporučujeme vám vybrat populární web a pokusit se jej procházet. Určitě narazíte na nové problémy, díky nimž je téma fascinující!