Log4j Tutorial: Jak nakonfigurovat Logger Pro efektivní protokolování Java aplikací
získání viditelnosti do vaší aplikace je zásadní při spuštění kódu ve výrobě. Co máme na mysli viditelností? Především věci, jako je výkon aplikací pomocí metrik, zdraví aplikací a dostupnost, jeho protokoly, pokud je potřebujete řešit, nebo jeho stopy, pokud potřebujete zjistit, co je pomalé a jak to zrychlit.
metriky vám poskytnou informace o výkonu každého z prvků vaší infrastruktury. Traces vám ukáže širší pohled na provádění a tok kódu spolu s metrikami provádění kódu. A konečně, dobře vytvořené protokoly poskytnou neocenitelný pohled na provádění logiky kódu a na to, co se ve vašem kódu děje. Každý z uvedených kusů je rozhodující pro vaši aplikaci a skutečně celkovou pozorovatelnost systému. Dnes se zaměříme pouze na jeden kus-protokoly. Přesněji – na protokolech Java aplikací. Máte – li zájem o metriky, podívejte se na náš článek o klíčových metrikách JVM, které byste měli sledovat.
než se do toho dostaneme, pojďme se zabývat problémem, který ovlivnil komunitu pomocí tohoto rámce. 9. Prosince 2021 byla hlášena kritická zranitelnost přezdívaná Log4Shell. Identifikováno jako CVE-2021-44228, umožňuje útočníkovi převzít úplnou kontrolu nad strojem se systémem Apache Log4j 2 verze 2.14.1 nebo nižší, což jim umožňuje provádět libovolný kód na zranitelném serveru. V našem nedávném blogu o zranitelnosti Log4jShell jsme podrobně popsali, jak zjistit, zda jste ovlivněni, jak problém vyřešit a co jsme v Sematextu udělali pro ochranu našeho systému a uživatelů.
Log4j 1.x konec života
mějte na paměti, že 5. srpna 2015 Výbor pro řízení projektů loging Services oznámil, že Log4j 1.x dosáhl svého konce života. Všem uživatelům se doporučuje migrovat na Log4j 2.x. v tomto blogu, pomůžeme vám pochopit vaše aktuální nastavení Log4j-konkrétně, log4j 2.x verze-a poté vám pomůžu přejít na nejnovější a největší verzi Log4j.
“ používám Log4j 1.x, co mám dělat?“. Nepropadejte panice, na tom není nic špatného. Vytvořte plán přechodu na Log4j 2.x. ukážu vám, jak jen pokračujte ve čtení :). Vaše aplikace vám za to poděkuje. Po migraci získáte opravy zabezpečení, vylepšení výkonu a mnohem více funkcí.
“ začínám nový projekt, co mám dělat?“. Stačí použít Log4j 2.x hned, ani nemysli na Log4j 1.x. Pokud s tím potřebujete pomoc, podívejte se na tento tutoriál pro protokolování Java, kde vysvětlím vše, co potřebujete.
přihlášení v Javě
za přihlášením v Javě není žádné kouzlo. Všechno jde o použití vhodné třídy Java a jejích metod pro generování událostí protokolu. Jak jsme diskutovali v Příručce pro protokolování Java, existuje několik způsobů, jak začít
samozřejmě, že nejvíce naivní a ne nejlepší cesta, kterou je třeba následovat, je pouze použití systému.ven a systém.err třídy. Ano, můžete to udělat a vaše zprávy se dostanou pouze na standardní výstup a standardní chybu. Obvykle to znamená, že bude vytištěn na konzoli nebo zapsán do souboru nějakého druhu nebo dokonce odeslán do / dev / null a navždy zapomenut. Příklad takového kódu by mohl vypadat takto:
public class SystemExample { public static void main(String args) { System.out.println("Starting my awesome application"); // some work to be done System.out.println( String.format("My application %s started successfully", SystemExample.class) ); }}
výstup výše uvedeného provedení kódu by byl následující:
Starting my awesome applicationMy application class com.sematext.logging.log4jsystem.SystemExample started successfully
to není dokonalé, že? Nemám žádné informace o tom, která třída vygenerovala zprávu a mnoho, mnoho dalších „malých“ věcí, které jsou při ladění zásadní a důležité.
chybí další věci, které nejsou skutečně spojeny s laděním. Zamyslete se nad prováděcím prostředím, více aplikacemi nebo mikroslužbami a potřebou sjednotit protokolování, aby se zjednodušila konfigurace centralizačního potrubí protokolu. Pomocí systému.ven, nebo / a systém.err v našem kódu pro účely protokolování by nás přinutil opakovat všechna místa, kde je používáme, kdykoli potřebujeme upravit formát protokolování. Vím, že je to extrémní, ale věřte mi, viděli jsme použití systému.ve výrobním kódu v „tradičních“ modelech nasazení aplikací! Samozřejmě přihlášení do systému.out je správné řešení pro kontejnerové aplikace a měli byste použít výstup, který vyhovuje vašemu prostředí. Pamatuj si to!
ze všech uvedených důvodů a mnoha dalších, o kterých ani nemyslíme, byste se měli podívat do jedné z možných knihoven protokolování, jako je Log4 j, Log4j 2, Logback nebo dokonce java.util.protokolování, které je součástí vývojové sady Java. Pro tento blogový příspěvek použijeme Log4j.
abstrakční vrstva-SLF4J
Téma výběru správného logovacího řešení pro vaši Java aplikaci je něco, o čem jsme již diskutovali v našem tutoriálu o přihlášení v Javě. Důrazně doporučujeme přečíst si alespoň uvedenou část.
budeme používat SLF4J, abstrakční vrstvu mezi naším kódem Java a Log4j-knihovnou protokolování podle našeho výběru. Jednoduchá fasáda protokolování poskytuje vazby pro běžné rámce protokolování, jako jsou Log4j, Logback a java.util.protokolování. Představte si proces psaní zprávy protokolu následujícím zjednodušeným způsobem:
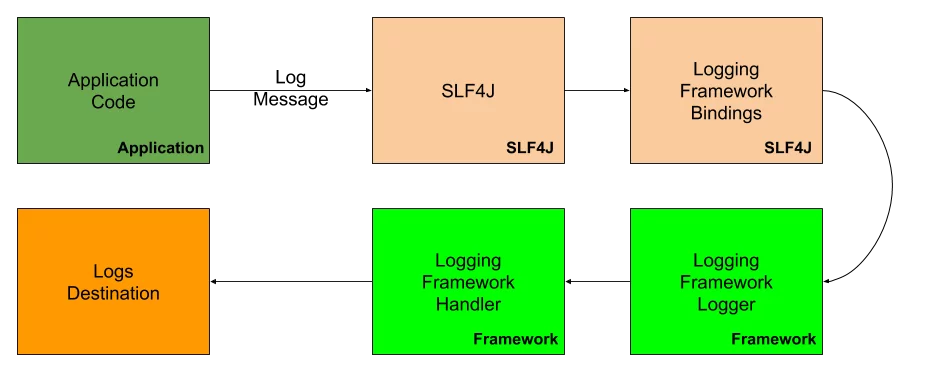
můžete se zeptat, Proč používat abstrakční vrstvu vůbec? Odpověď je poměrně jednoduchá-nakonec možná budete chtít změnit rámec protokolování, Upgradovat jej, sjednotit jej se zbytkem technologického zásobníku. Při použití abstrakční vrstvy je taková operace poměrně jednoduchá – stačí vyměnit závislosti rámce protokolování a poskytnout nový balíček. Pokud bychom nepoužívali abstrakční vrstvu – museli bychom změnit kód, potenciálně hodně kódu. Každá třída, která něco přihlásí. Není to moc pěkný vývojový zážitek.
Logger
kód vaší Java aplikace bude interagovat se standardní sadou klíčových prvků, které umožňují vytváření a manipulaci událostí protokolu. V našem tutoriálu pro protokolování Java jsme se zabývali klíčovými, ale dovolte mi, abych vám připomněl jednu z tříd – které budeme neustále používat-Logger.
Logger je hlavní entita, kterou aplikace používá k volání protokolování-vytváření událostí protokolu. Objekt Logger se obvykle používá pro jednu třídu nebo jednu komponentu, aby poskytl kontext vázaný na konkrétní případ použití. Poskytuje metody pro vytváření událostí protokolu s odpovídající úrovní protokolu a předání pro další zpracování. Obvykle vytvoříte statický objekt, se kterým budete komunikovat, například takto:
... Logger LOGGER = LoggerFactory.getLogger(MyAwesomeClass.class);
a to je vše. Nyní, když víme, co můžeme očekávat, podívejme se na knihovnu Log4j.
Log4j
nejjednodušší způsob, jak začít s Log4j, je zahrnout knihovnu do třídy vaší Java aplikace. Za tímto účelem zahrnujeme nejnovější dostupnou knihovnu log4j, což znamená verzi 1.2.17 v našem sestavovacím souboru.
používáme Gradle a v naší jednoduché aplikaci a sekci závislostí pro Gradle build soubor vypadá následovně:
dependencies { implementation 'log4j:log4j:1.2.17'}
můžeme začít vyvíjet kód a zahrnout protokolování pomocí Log4j:
package com.sematext.blog;import org.apache.log4j.Logger;public class ExampleLog4j { private static final Logger LOGGER = Logger.getLogger(ExampleLog4j.class); public static void main(String args) { LOGGER.info("Initializing ExampleLog4j application"); }}
jak můžete vidět ve výše uvedeném kódu, inicializovali jsme objekt loggeru pomocí statické metody getLogger a poskytli jsme název třídy. Poté můžeme snadno přistupovat k objektu statického loggeru a použít jej k vytváření událostí protokolu. Můžeme to udělat v hlavní metodě.
jedna boční poznámka-metodu getLogger lze také volat pomocí řetězce jako argumentu, například:
private static final Logger LOGGER = Logger.getLogger("com.sematext.blog");
znamenalo by to, že chceme vytvořit logger a přiřadit název com.sematext.blog s ním. Pokud budeme používat stejný název kdekoli jinde v kódu Log4j vrátí stejnou instanci loggeru. To je užitečné, pokud chceme kombinovat protokolování z více různých tříd na jednom místě. Například protokoly týkající se platby v jediném vyhrazeném souboru protokolu.
Log4j poskytuje seznam metod umožňujících vytváření nových událostí protokolu pomocí příslušné úrovně protokolu. To jsou:
- public void trace (Object message)
- public void debug (Object message)
- public void info (Object message)
- public void warn (Object message)
- public void error (Object message)
- public void fatal (Object message)
a jedna obecná metoda:
- public void log (úroveň, objektová zpráva)
mluvili jsme o úrovních protokolování Java v našem blogu Java logging tutorial. Pokud si nejste vědomi z nich, prosím trvat několik minut, aby si na ně zvyknout, protože úrovně protokolu jsou rozhodující pro protokolování. Pokud teprve začínáte s úrovněmi protokolování, doporučujeme vám také projít náš průvodce úrovněmi protokolu. Vysvětlujeme vše od toho, co jsou, až po to, jak vybrat ten správný a jak je využít k získání smysluplných poznatků.
pokud bychom spustili výše uvedený kód, výstup, který bychom dostali na standardní konzoli, by byl následující:
log4j:WARN No appenders could be found for logger (com.sematext.blog.ExampleLog4j).log4j:WARN Please initialize the log4j system properly.log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
neviděli jsme zprávu protokolu, kterou jsme očekávali. Log4j nás informoval, že neexistuje žádná konfigurace. Oooops, pojďme mluvit o tom, jak nakonfigurovat Log4j …
konfigurace Log4j
existuje několik způsobů, jak můžeme nakonfigurovat naše Log4j protokolování. Můžeme to udělat programově – například zahrnutím statického inicializačního bloku:
static { BasicConfigurator.configure();}
výše uvedený kód konfiguruje Log4j pro výstup protokolů do konzoly ve výchozím formátu. Výstup spuštění naší ukázkové aplikace bude vypadat následovně:
0 INFO com.sematext.blog.ExampleLog4jProgrammaticConfig - Initializing ExampleLog4j application
programové nastavení Log4j však není příliš běžné. Nejběžnějším způsobem by bylo použití souboru vlastností nebo souboru XML. Můžeme změnit náš kód a zahrnout soubor log4j. properties s následujícím obsahem:
log4j.rootLogger=DEBUG, MAINlog4j.appender.MAIN=org.apache.log4j.ConsoleAppenderlog4j.appender.MAIN.layout=org.apache.log4j.PatternLayoutlog4j.appender.MAIN.layout.ConversionPattern=%r %-5p %c %x - %m%n
tímto způsobem jsme řekli Log4j, že vytvoříme kořenový logger, který bude použit ve výchozím nastavení. Jeho výchozí úroveň protokolování je nastavena na DEBUG, což znamená, že budou zahrnuty události protokolu s laděním závažnosti nebo vyšší. Takže ladění, informace, varování, chyba a fatální. Také jsme dali našemu loggeru jméno-MAIN. Dále nakonfigurujeme logger nastavením jeho výstupu na konzoli a pomocí rozvržení vzoru. O tom budeme hovořit později v blogu. Výstup spuštění výše uvedeného kódu by byl následující:
0 INFO com.sematext.blog.ExampleLog4jProperties - Initializing ExampleLog4j application
pokud si přejeme, můžeme také změnit soubor log4j.properties a použít jeden s názvem log4j.xml. Stejná konfigurace pomocí formátu XML bude vypadat následovně:
<!DOCTYPE log4j:configuration SYSTEM "log4j.dtd"><log4j:configuration> <appender name="MAIN" class="org.apache.log4j.ConsoleAppender"> <param name="Target" value="System.out"/> <layout class="org.apache.log4j.PatternLayout"> <param name="ConversionPattern" value="%r %-5p %c %x - %m%n" /> </layout> </appender> <root> <priority value ="debug"></priority> <appender-ref ref="MAIN" /> </root></log4j:configuration>
pokud bychom nyní změnili log4j. properties pro log4j.xml jeden a udržujte jej v classpath provedení naší příkladové aplikace by bylo následující:
0 INFO com.sematext.blog.ExampleLog4jXML - Initializing ExampleLog4j application
jak tedy Log4j ví, který soubor použít? Podívejme se na to.
Inicializační proces
je důležité vědět, že Log4j nevytváří žádné předpoklady týkající se prostředí, ve kterém běží. Log4j nepředpokládá žádné výchozí cíle událostí protokolu. Při spuštění vyhledá vlastnost log4j.configuration a pokusí se načíst zadaný soubor jako jeho konfiguraci. Pokud umístění souboru nelze převést na adresu URL nebo soubor není k dispozici, pokusí se načíst soubor z classpath.
to znamená, že můžeme přepsat konfiguraci Log4j z classpath poskytnutím konfigurace-Dlog4j. během spuštění a nasměrováním na správné umístění. Například pokud zahrneme soubor nazvaný jiný.xml s následujícím obsahem:
<!DOCTYPE log4j:configuration SYSTEM "log4j.dtd"><log4j:configuration> <appender name="MAIN" class="org.apache.log4j.ConsoleAppender"> <param name="Target" value="System.out"/> <layout class="org.apache.log4j.PatternLayout"> <param name="ConversionPattern" value="%r %-5p %c %x - %m%n" /> </layout> </appender> <root> <priority value ="debug"></priority> <appender-ref ref="MAIN" /> </root></log4j:configuration>
a pak spusťte kód s-Dlog4j. configuration= / opt/sematext / other.xml výstup z našeho kódu bude následující:
0 INFO com.sematext.blog.ExampleLog4jXML - Initializing ExampleLog4j application
Log4j Appenders
appenders jsme již použili v našich příkladech … no, opravdu jen jeden-ConsoleAppender. Jeho jediným účelem je zapisovat události protokolu do konzoly. Samozřejmě, s velkým počtem událostí protokolu a systémů běžících v různých prostředích psaní čistých textových dat na standardní výstup nemusí být nejlepší nápad, pokud neběžíte v kontejnerech. Proto Log4j podporuje více typů Appenderů. Zde je několik běžných příkladů aplikací Log4j:
- ConsoleAppender – appender, který připojí události protokolu do systému.ven nebo systém.chybovat s výchozím systémem.mimo. Při použití tohoto appenderu uvidíte své protokoly v konzole aplikace.
- FileAppender-appender, který připojí události protokolu k definovanému souboru, který je ukládá do systému souborů.
- RollingFileAppender-appender, který rozšiřuje FileAppender a otáčí soubor, když dosáhne definované velikosti. Použití RollingFileAppender zabraňuje soubory protokolu z stává velmi velký a těžko udržovat.
- SyslogAppender-appender odesílání událostí protokolu do vzdáleného syslog démona.
- JDBCAppender-appender, který ukládá události protokolu do databáze. Mějte na paměti, že tento appender nebude ukládat chyby a obecně není nejlepší nápad ukládat události protokolu do databáze.
- SocketAppender-appender, který odešle serializované události protokolu do vzdáleného soketu. Mějte na paměti, že tento appender nepoužívá rozvržení, protože odesílá serializované události surového protokolu.
- NullAppender-appender, který jen zahodí události protokolu.
a co víc, můžete mít nakonfigurováno více Appenderů pro jednu aplikaci. Můžete například odeslat protokoly do konzoly a do souboru. Následující log4j.obsah souboru vlastností by to udělal přesně:
log4j.rootLogger=DEBUG, MAIN, ROLLINGlog4j.appender.MAIN=org.apache.log4j.ConsoleAppenderlog4j.appender.MAIN.layout=org.apache.log4j.PatternLayoutlog4j.appender.MAIN.layout.ConversionPattern=%r %-5p %c %x - %m%nlog4j.appender.ROLLING=org.apache.log4j.RollingFileAppenderlog4j.appender.ROLLING.File=/var/log/sematext/awesome.loglog4j.appender.ROLLING.MaxFileSize=1024KBlog4j.appender.ROLLING.MaxBackupIndex=10log4j.appender.ROLLING.layout=org.apache.log4j.PatternLayoutlog4j.appender.ROLLING.layout.ConversionPattern=%r %-5p %c %x - %m%n
náš kořenový logger je nakonfigurován tak, aby zaznamenával vše od závažnosti ladění a odesílal protokoly dvěma Appenderům-hlavní a rolovací. Hlavní logger je ten, který jsme již viděli-ten, který odesílá data do konzoly.
druhý logger, který se nazývá válcování, je v tomto příkladu zajímavější. Používá RollingFileAppender, který zapisuje data do souboru a pojďme definovat, jak velký soubor může být a kolik souborů zachovat. V našem případě by se soubory protokolu měly nazývat úžasné.protokolujte a zapisujte data do adresáře/var/log/ sematext/. Každý soubor by měl mít maximálně 1024 kB a nemělo by být uloženo více než 10 souborů. Pokud je více souborů, budou odstraněny ze systému souborů, jakmile je log4j uvidí.
po spuštění kódu s výše uvedenou konfigurací konzole vytiskne následující obsah:
0 INFO com.sematext.blog.ExampleAppenders - Starting ExampleAppenders application1 WARN com.sematext.blog.ExampleAppenders - Ending ExampleAppenders application
v /var/log/sematext/úžasné.soubor protokolu, který bychom viděli:
0 INFO com.sematext.blog.ExampleAppenders - Starting ExampleAppenders application1 WARN com.sematext.blog.ExampleAppenders - Ending ExampleAppenders application
Appender Log Level
pěkná věc, o Appenders je, že mohou mít svou úroveň, která by měla být brána v úvahu při protokolování. Všechny příklady, které jsme dosud viděli, zaznamenaly každou zprávu, která měla závažnost ladění nebo vyšší. Co kdybychom to chtěli změnit pro všechny třídy v com.sematext.blogový balíček? Museli bychom pouze upravit náš soubor log4j. properties:
log4j.rootLogger=DEBUG, MAINlog4j.appender.MAIN=org.apache.log4j.ConsoleAppenderlog4j.appender.MAIN.layout=org.apache.log4j.PatternLayoutlog4j.appender.MAIN.layout.ConversionPattern=%r %-5p %c %x - %m%nlog4j.logger.com.sematext.blog=WARN
podívejte se na poslední řádek ve výše uvedeném konfiguračním souboru. Použili jsme předponu log4j. logger a řekl, že logger volal com.sematext.blog by měl být používán pouze pro úrovně závažnosti a vyšší, takže chyba a fatální.
náš příklad aplikace kód vypadá takto:
public static void main(String args) { LOGGER.info("Starting ExampleAppenderLevel application"); LOGGER.warn("Ending ExampleAppenderLevel application");}
s výše uvedenou konfigurací Log4j vypadá výstup protokolování následovně:
0 WARN com.sematext.blog.ExampleAppenderLevel - Ending ExampleAppenderLevel application
jak vidíte, byl zahrnut pouze protokol úrovně varování. To je přesně to, co jsme chtěli.
Log4j Layouts
konečně, část Log4j protokolování rámce, který řídí způsob, jakým jsou naše data strukturována v našem souboru protokolu-layout – Log4j poskytuje několik výchozích implementací, jako je PatternLayout, SimpleLayout, XMLLayout, HTMLLayout, EnchancedPatternLayout a DateLayout.
ve většině případů narazíte na PatternLayout. Myšlenka tohoto rozvržení je, že můžete poskytnout různé možnosti formátování pro definování struktury protokolů. Některé z příkladů jsou:
- d-datum a čas události protokolu,
- m-zpráva spojená s událostí protokolu,
- název t-vlákna,
- n-platform dependent line separator,
- úroveň protokolu p.
pro více informací o dostupných možnostech přejděte na oficiální Log4j Javadocs pro PatternLayout.
při použití PatternLayout můžeme nakonfigurovat, kterou možnost chceme použít. Předpokládejme, že bychom chtěli napsat datum, závažnost události protokolu, vlákno obklopené hranatými závorkami a zprávu události protokolu. Mohli bychom použít takový vzor:
%d %-5p - %m%n
celý soubor log4j. properties v tomto případě může vypadat následovně:
log4j.rootLogger=DEBUG, MAINlog4j.appender.MAIN=org.apache.log4j.ConsoleAppenderlog4j.appender.MAIN.layout=org.apache.log4j.PatternLayoutlog4j.appender.MAIN.layout.ConversionPattern=%d %-5p - %m%n
používáme %d pro zobrazení data, % – 5p pro zobrazení závažnosti pomocí 5 znaků, %t pro vlákno, %m pro zprávu a %n pro oddělovač řádků. Výstup, který je zapsán do konzoly po spuštění našeho příkladového kódu, vypadá následovně:
2021-02-02 11:49:49,003 INFO - Initializing ExampleLog4jFormatter application
vnořený diagnostický kontext
ve většině reálných aplikací událost protokolu neexistuje sama o sobě. Je obklopen určitým kontextem. Pro poskytnutí takového kontextu, na vlákno, Log4j poskytuje takzvaný vnořený diagnostický kontext. Tímto způsobem můžeme dané vlákno spojit s dalšími informacemi, například identifikátorem relace, stejně jako v naší příkladové aplikaci:
NDC.push(String.format("Session ID: %s", "1234-5678-1234-0987"));LOGGER.info("Initializing ExampleLog4jNDC application");
při použití vzoru, který obsahuje proměnnou x, budou do každé logline pro daný podproces zahrnuty další informace. V našem případě bude výstup vypadat takto:
0 INFO com.sematext.blog.ExampleLog4jNDC Session ID: 1234-5678-1234-0987 - Initializing ExampleLog4jNDC application
můžete vidět, že informace o identifikátoru relace jsou v logline. Jen pro informaci, soubor log4j. properties, který jsme použili v tomto příkladu, vypadá následovně:
log4j.rootLogger=DEBUG, MAINlog4j.appender.MAIN=org.apache.log4j.ConsoleAppenderlog4j.appender.MAIN.layout=org.apache.log4j.PatternLayoutlog4j.appender.MAIN.layout.ConversionPattern=%r %-5p %c %x - %m%n
mapovaný diagnostický kontext
druhým typem kontextových informací, které můžeme zahrnout do našich událostí protokolu, je mapovaný diagnostický kontext. Pomocí třídy MDC můžeme poskytnout další informace týkající se klíčové hodnoty. Podobně jako vnořený diagnostický kontext je mapovaný diagnostický kontext vázán na vlákno.
podívejme se na náš příklad kódu aplikace:
MDC.put("user", "[email protected]");MDC.put("step", "initial");LOGGER.info("Initializing ExampleLog4jNDC application");MDC.put("step", "launch");LOGGER.info("Starting ExampleLog4jNDC application");
máme dvě kontextová pole-uživatel a krok. Pro zobrazení všech mapovaných diagnostických kontextových informací spojených s událostí protokolu používáme proměnnou X v naší definici vzoru. Například:
log4j.rootLogger=DEBUG, MAINlog4j.appender.MAIN=org.apache.log4j.ConsoleAppenderlog4j.appender.MAIN.layout=org.apache.log4j.PatternLayoutlog4j.appender.MAIN.layout.ConversionPattern=%r %-5p %c %X - %m%n
spuštění výše uvedeného kódu spolu s konfigurací by mělo za následek následující výstup:
0 INFO com.sematext.blog.ExampleLog4jMDC {{step,initial}{user,[email protected]}} - Initializing ExampleLog4jNDC application1 INFO com.sematext.blog.ExampleLog4jMDC {{step,launch}{user,[email protected]}} - Starting ExampleLog4jNDC application
můžeme také zvolit, které informace použít změnou vzoru. Chcete-li například zahrnout uživatele z mapovaného diagnostického kontextu, mohli bychom napsat vzor, jako je tento:
%r %-5p %c %X{user} - %m%n
tentokrát by výstup vypadal následovně:
0 INFO com.sematext.blog.ExampleLog4jMDC [email protected] - Initializing ExampleLog4jNDC application0 INFO com.sematext.blog.ExampleLog4jMDC [email protected] - Starting ExampleLog4jNDC application
můžete vidět, že místo obecného %X jsme použili %X{user}. To znamená, že nás zajímá uživatelská proměnná z mapovaného diagnostického kontextu spojeného s danou událostí protokolu.
migrace do Log4j 2
migrace z Log4j 1.x na Log4j 2.x není těžké a v některých případech to může být velmi snadné. Pokud jste nepoužili Žádný interní Log4j 1.x tříd, jste použili konfigurační soubory přes programově nastavení loggerů a vy jste nepoužili DOMConfigurator a PropertyConfigurator tříd migrace by měla být stejně jednoduché jako včetně log4j-1.2-api.soubor jar jar místo Log4j 1.Soubory x jar. To by umožnilo Log4j 2.x pracovat s kódem. Budete muset přidat Log4j 2.Soubory X jar, upravte konfiguraci a voilà-máte hotovo.
pokud se chcete dozvědět více o Log4j 2.x podívejte se na náš Java protokolování tutorial a jeho Log4j 2.x vyhrazená sekce.
Nicméně, pokud jste použili interní Log4j 1.třídy x, oficiální průvodce migrací o tom, jak přejít z Log4j 1.x na Log4j 2.x bude velmi užitečné. Popisuje potřebné změny kódu a konfigurace a v případě pochybností bude neocenitelný.
centralizované protokolování pomocí nástrojů pro správu protokolů
odesílání událostí protokolu do konzoly nebo souboru může být dobré pro jednu aplikaci, ale manipulace s více instancemi vaší aplikace a korelace protokolů z více zdrojů není zábavná, když jsou události protokolu v textových souborech na různých počítačích. V takových případech se množství dat rychle stává nezvládnutelným a vyžaduje vyhrazená řešení – buď hostovaná, nebo pocházející od jednoho z dodavatelů. A co kontejnery, kde obvykle ani nepíšete protokoly do souborů? Jak řešíte a ladíte aplikaci, jejíž protokoly byly vysílány na standardní výstup nebo jejíž kontejner byl zabit?
zde vstupují do hry služby správy protokolů, nástroje pro analýzu protokolů a služby protokolování cloudů. Je to nepsaná Java protokolování nejlepší praxe mezi inženýry používat taková řešení, když jste vážně o správě protokolů a získat co nejvíce z nich. Například protokoly Sematext, náš software pro monitorování a správu protokolů, řeší všechny výše uvedené problémy a další.
s plně spravovaným řešením, jako jsou protokoly Sematext, nemusíte spravovat další část prostředí-vaše řešení pro protokolování DIY, obvykle vytvořené pomocí kusů elastického zásobníku. Taková nastavení mohou začít malé a levné, často však rostou velké a drahé. Nejen z hlediska nákladů na infrastrukturu, ale také nákladů na správu. Víš, čas a výplata. Více o výhodách používání spravované služby vysvětlujeme v našem blogu o osvědčených postupech při protokolování.
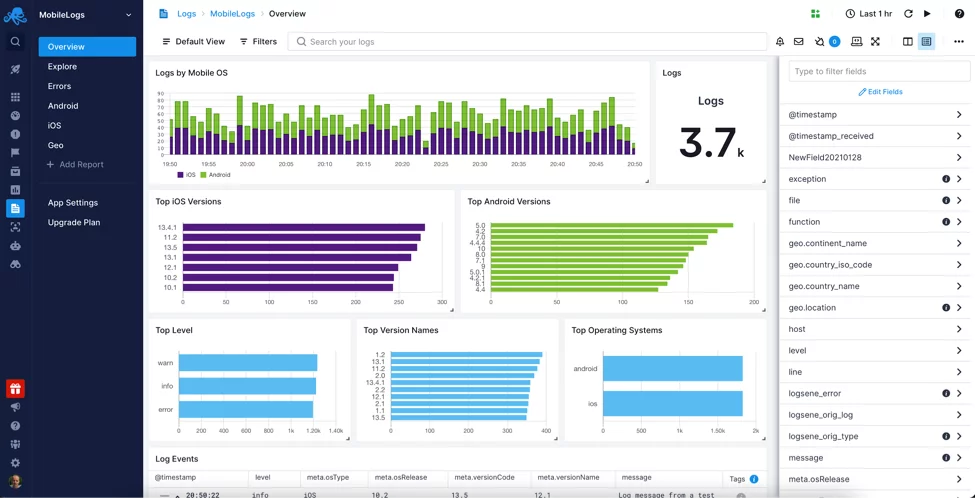
upozornění a agregace protokolu jsou také zásadní při řešení problémů. Nakonec, pro Java aplikace, možná budete chtít mít protokoly sběru odpadků, jakmile zapnete přihlášení k odběru odpadu a začnete analyzovat protokoly. Takové protokoly korelované s metrikami jsou neocenitelným zdrojem informací pro řešení problémů souvisejících se sběrem odpadků.
shrnutí
i když Log4j 1.x dosáhl svého konce života již dávno je stále přítomen ve velkém počtu starších aplikací používaných po celém světě. Přechod na mladší verzi je poměrně jednoduchý, ale může vyžadovat značné zdroje a čas a obvykle není nejvyšší prioritou. Zejména ve velkých podnicích, kde postupy, právní požadavky nebo obojí vyžadují audity, po nichž následuje dlouhé a nákladné testování, než se v již běžícím systému může něco změnit. Ale pro ty z nás, kteří právě začínají nebo přemýšlejí o migraci-pamatujte, Log4j 2.x je tam, je již zralý, rychlý, bezpečný a velmi schopný.
ale bez ohledu na rámec, který používáte pro protokolování aplikací Java, rozhodně doporučujeme vzít si své úsilí s plně spravovaným řešením správy protokolů,jako jsou protokoly Sematext. Zkuste to! K dispozici je 14denní bezplatná zkušební verze, kterou můžete vyzkoušet.
šťastné přihlášení!