Webbsökning med Python

webbsökning är en kraftfull teknik för att samla in data från webben genom att hitta alla webbadresser för en eller flera domäner. Python har flera populära webbsökningsbibliotek och ramverk.
i den här artikeln kommer vi först att introducera olika krypningsstrategier och användningsfall. Sedan bygger vi en enkel webbsökare från början i Python med två bibliotek: förfrågningar och vacker soppa. Därefter kommer vi att se varför det är bättre att använda ett webbsökningsramverk som Scrapy. Slutligen kommer vi att bygga ett exempel sökrobot med Scrapy att samla film metadata från IMDb och se hur Scrapy skalor till webbplatser med flera miljoner sidor.
Vad är en sökrobot?
webbsökning och webbskrapning är två olika men relaterade begrepp. Webbsökning är en del av webbskrapning, sökrobotens logik hittar webbadresser som ska behandlas av skrapkoden.
en webbsökare börjar med en lista med webbadresser att besöka, kallad fröet. För varje URL hittar sökroboten länkar i HTML, filtrerar dessa länkar baserat på vissa kriterier och lägger till de nya länkarna i en kö. All HTML eller viss specifik information extraheras för att behandlas av en annan pipeline.
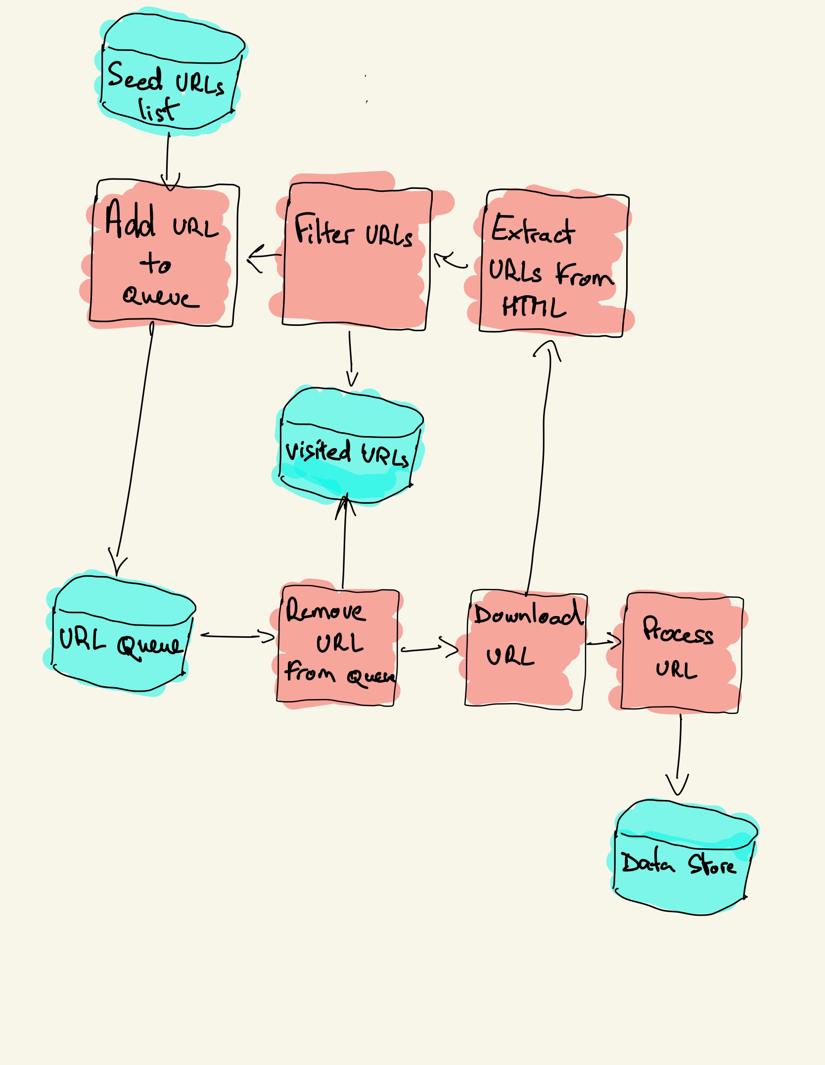
webbsökningsstrategier
i praktiken besöker webbsökare bara en delmängd sidor beroende på sökrobotbudgeten, vilket kan vara ett maximalt antal sidor per domän, djup eller körningstid.
mest populära webbplatser ger en robotar.txt-fil för att ange vilka områden på webbplatsen som inte får genomsökas av varje användaragent. Motsatsen till robots-filen är webbplatskartan.xml-fil, som listar de sidor som kan genomsökas.
populära webbrobotanvändningsfall inkluderar:
- sökmotorer (Googlebot, bingbot, Yandex Bot…) samlar all HTML för en betydande del av webben. Dessa data indexeras för att göra det sökbart.
- SEO-analysverktyg utöver att samla in HTML samlar också in metadata som svarstid, svarsstatus för att upptäcka trasiga sidor och länkarna mellan olika domäner för att samla in bakåtlänkar.
- Prisövervakningsverktyg genomsöker e-handelswebbplatser för att hitta produktsidor och extrahera metadata, särskilt priset. Produktsidorna revideras sedan regelbundet.
- Common Crawl upprätthåller ett öppet arkiv med webbgenomsökningsdata. Till exempel innehåller arkivet från oktober 2020 2,71 miljarder webbsidor.
därefter kommer vi att jämföra tre olika strategier för att bygga en webbsökare i Python. Först använder du bara standardbibliotek, sedan tredjepartsbibliotek för att göra HTTP-förfrågningar och analysera HTML och slutligen ett webbsökningsramverk.
bygga en enkel sökrobot i Python från början
för att bygga en enkel sökrobot i Python behöver vi minst ett bibliotek för att ladda ner HTML från en URL och ett HTML-analysbibliotek för att extrahera länkar. Python tillhandahåller standardbibliotek urllib för att göra HTTP-förfrågningar och html.parser för att analysera HTML. Ett exempel Python-sökrobot byggd endast med standardbibliotek finns på Github.
standard Python-bibliotek för förfrågningar och HTML-tolkning är inte särskilt utvecklarvänliga. Andra populära bibliotek som requests, märkta som HTTP för människor, och Beautiful Soup ger en bättre utvecklarupplevelse.
om du vill veta mer kan du kolla den här guiden om den bästa Python HTTP-klienten.
du kan installera de två biblioteken lokalt.
pip install requests bs4en grundläggande sökrobot kan byggas enligt det tidigare arkitekturdiagrammet.
import loggingfrom urllib.parse import urljoinimport requestsfrom bs4 import BeautifulSouplogging.basicConfig( format='%(asctime)s %(levelname)s:%(message)s', level=logging.INFO)class Crawler: def __init__(self, urls=): self.visited_urls = self.urls_to_visit = urls def download_url(self, url): return requests.get(url).text def get_linked_urls(self, url, html): soup = BeautifulSoup(html, 'html.parser') for link in soup.find_all('a'): path = link.get('href') if path and path.startswith('/'): path = urljoin(url, path) yield path def add_url_to_visit(self, url): if url not in self.visited_urls and url not in self.urls_to_visit: self.urls_to_visit.append(url) def crawl(self, url): html = self.download_url(url) for url in self.get_linked_urls(url, html): self.add_url_to_visit(url) def run(self): while self.urls_to_visit: url = self.urls_to_visit.pop(0) logging.info(f'Crawling: {url}') try: self.crawl(url) except Exception: logging.exception(f'Failed to crawl: {url}') finally: self.visited_urls.append(url)if __name__ == '__main__': Crawler(urls=).run()koden ovan definierar en Sökrobotklass med hjälpmetoder för att ladda ner_url med hjälp av förfrågningsbiblioteket, get_linked_urls med det vackra Soppbiblioteket och add_url_to_visit för att filtrera webbadresser. Webbadresserna att besöka och de besökta webbadresserna lagras i två separata listor. Du kan köra sökroboten på din terminal.
python crawler.pysökroboten loggar en rad för varje besökt URL.
2020-12-04 18:10:10,737 INFO:Crawling: https://www.imdb.com/2020-12-04 18:10:11,599 INFO:Crawling: https://www.imdb.com/?ref_=nv_home2020-12-04 18:10:12,868 INFO:Crawling: https://www.imdb.com/calendar/?ref_=nv_mv_cal2020-12-04 18:10:13,526 INFO:Crawling: https://www.imdb.com/list/ls016522954/?ref_=nv_tvv_dvd2020-12-04 18:10:19,174 INFO:Crawling: https://www.imdb.com/chart/top/?ref_=nv_mv_2502020-12-04 18:10:20,624 INFO:Crawling: https://www.imdb.com/chart/moviemeter/?ref_=nv_mv_mpm2020-12-04 18:10:21,556 INFO:Crawling: https://www.imdb.com/feature/genre/?ref_=nv_ch_grkoden är väldigt enkel men det finns många prestanda-och användbarhetsproblem att lösa innan du lyckas genomsöka en komplett webbplats.
- sökroboten är långsam och stöder ingen parallellitet. Som framgår av tidsstämplarna tar det ungefär en sekund att genomsöka varje URL. Varje gång sökroboten gör en begäran väntar den på att begäran ska lösas och inget arbete görs däremellan.
- hämtningsadressen logiken har ingen retry mekanism, URL kön är inte en riktig kö och inte mycket effektiv med ett stort antal webbadresser.
- länkutvinningslogiken stöder inte standardisering av webbadresser genom att ta bort url-frågesträngsparametrar, hanterar inte webbadresser som börjar med #, stöder inte filtrering av webbadresser efter domän eller filtrering av förfrågningar till statiska filer.
- sökroboten identifierar sig inte och ignorerar robotarna.txt-fil.
därefter kommer vi att se hur Scrapy tillhandahåller alla dessa funktioner och gör det enkelt att utöka för dina anpassade genomsökningar.
webbsökning med Scrapy
Scrapy är det mest populära Webbskrapnings-och krypnings Python-ramverket med 40k-stjärnor på Github. En av fördelarna med Scrapy är att förfrågningar planeras och hanteras asynkront. Detta innebär att Scrapy kan skicka en annan begäran innan den föregående är klar eller göra något annat arbete däremellan. Scrapy kan hantera många samtidiga förfrågningar men kan också konfigureras för att respektera webbplatserna med anpassade inställningar, som vi ser senare.
Scrapy har en flerkomponentarkitektur. Normalt kommer du att genomföra minst två olika klasser: spindel och Pipeline. Webbskrapning kan ses som en ETL där du extraherar data från webben och laddar den till din egen lagring. Spindlar extraherar data och rörledningar laddar den i lagringen. Transformation kan hända både i spindlar och rörledningar, men jag rekommenderar att du ställer in en anpassad Scrapy pipeline för att omvandla varje objekt oberoende av varandra. På det här sättet, att inte bearbeta ett objekt har ingen effekt på andra objekt.
utöver allt detta kan du lägga till spider och downloader middlewares mellan komponenter som det kan ses i diagrammet nedan.
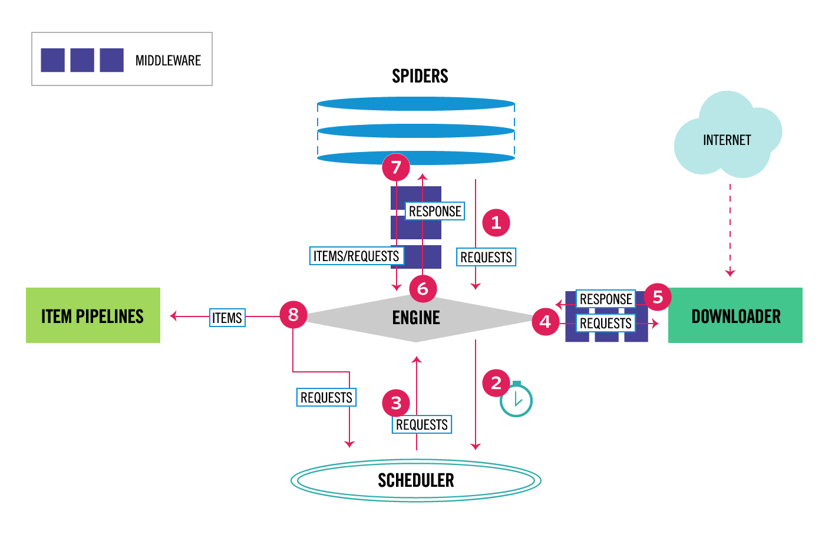
Scrapy Architecture Overview
om du har använt Scrapy tidigare vet du att en webbskrapa definieras som en klass som ärver från base Spider-klassen och implementerar en tolkningsmetod för att hantera varje svar. Om du är ny på Scrapy kan du läsa den här artikeln för enkel skrapning med Scrapy.
from scrapy.spiders import Spiderclass ImdbSpider(Spider): name = 'imdb' allowed_domains = start_urls = def parse(self, response): passScrapy ger också flera generiska spindel klasser: CrawlSpider, XMLFeedSpider, CSVFeedSpider och SitemapSpider. Crawlspider-klassen ärver från base Spider-klassen och ger ett extra regelattribut för att definiera hur man genomsöker en webbplats. Varje regel använder en LinkExtractor för att ange vilka länkar som extraheras från varje sida. Därefter kommer vi att se hur man använder var och en av dem genom att bygga en sökrobot för IMDb, Internet Movie Database.
bygga ett exempel Scrapy crawler för IMDb
innan jag försökte krypa IMDb kontrollerade jag IMDb-robotar.txt-fil för att se vilka URL-sökvägar som är tillåtna. Robots-filen tillåter endast 26 sökvägar för alla användaragenter. Scrapy läser robotarna.txt-fil i förväg och respekterar det när ROBOTSTXT_OBEY inställningen är inställd på true. Detta är fallet för alla projekt som genereras med Scrapy-kommandot startproject.
scrapy startproject scrapy_crawlerdet här kommandot skapar ett nytt projekt med Standardstrukturen för Scrapy – projektmapp.
scrapy_crawler/├── scrapy.cfg└── scrapy_crawler ├── __init__.py ├── items.py ├── middlewares.py ├── pipelines.py ├── settings.py └── spiders ├── __init__.pydå kan du skapa en spindel i scrapy_crawler/spiders/imdb.py med en regel att extrahera alla länkar.
from scrapy.spiders import CrawlSpider, Rulefrom scrapy.linkextractors import LinkExtractorclass ImdbCrawler(CrawlSpider): name = 'imdb' allowed_domains = start_urls = rules = (Rule(LinkExtractor()),)du kan starta sökroboten i terminalen.
scrapy crawl imdb --logfile imdb.logdu kommer att få massor av loggar, inklusive en logg för varje begäran. När jag undersökte loggarna märkte jag att även om vi ställde in allowed_domains att bara genomsöka webbsidor under https://www.imdb.com, fanns det förfrågningar till externa domäner, till exempel amazon.com.
2020-12-06 12:25:18 DEBUG: Redirecting (302) to <GET https://www.amazon.com/b/?&node=5160028011&ref_=ft_iba> from <GET (https://www.imdb.com/whitelist-offsite?url=https%3A%2F%2Fwww.amazon.com%2Fb%2F%3F%26node%3D5160028011%26ref_%3Dft_iba&page-action=ft-iba&ref=ft_iba)>IMDb omdirigerar från webbadresser sökvägar under vitlista-offsite och vitlista till externa domäner. Det finns ett open Scrapy Github-problem som visar att externa webbadresser inte filtreras bort när Offsitemidleware tillämpas innan Redirectmidleware. För att åtgärda problemet kan vi konfigurera link extractor för att neka webbadresser som börjar med två reguljära uttryck.
class ImdbCrawler(CrawlSpider): name = 'imdb' allowed_domains = start_urls = rules = ( Rule(LinkExtractor( deny=, )), )regel-och LinkExtractor-klasser stöder flera argument för att filtrera bort webbadresser. Du kan till exempel ignorera specifika URL-tillägg och minska antalet dubbla webbadresser genom att sortera frågesträngar. Om du inte hittar ett specifikt argument för ditt användningsfall kan du skicka en anpassad funktion till process_links i LinkExtractor eller process_values i Rule.
IMDb har till exempel två olika webbadresser med samma innehåll.
https://www.imdb.com/namn / nm1156914/
https://www.imdb.com/namn / nm1156914/?mode=desktop&ref_=m_ft_dsk
för att begränsa antalet genomsökta webbadresser kan vi ta bort alla frågesträngar från webbadresser med url_query_cleaner-funktionen från w3lib-biblioteket och använda den i process_links.
from w3lib.url import url_query_cleanerdef process_links(links): for link in links: link.url = url_query_cleaner(link.url) yield linkclass ImdbCrawler(CrawlSpider): name = 'imdb' allowed_domains = start_urls = rules = ( Rule(LinkExtractor( deny=, ), process_links=process_links), )nu när vi har begränsat antalet förfrågningar att bearbeta kan vi lägga till en parse_item-metod för att extrahera data från varje sida och skicka den till en pipeline för att lagra den. Till exempel kan vi antingen extrahera hela svaret.text för att bearbeta den i en annan pipeline eller välj HTML-metadata. För att välja HTML-metadata i rubriktaggen kan vi koda våra egna XPATHs men jag tycker att det är bättre att använda ett bibliotek, extruct, som extraherar alla metadata från en HTML-sida. Du kan installera det med pip install extract.
import refrom scrapy.linkextractors import LinkExtractorfrom scrapy.spiders import CrawlSpider, Rulefrom w3lib.url import url_query_cleanerimport extructdef process_links(links): for link in links: link.url = url_query_cleaner(link.url) yield linkclass ImdbCrawler(CrawlSpider): name = 'imdb' allowed_domains = start_urls = rules = ( Rule( LinkExtractor( deny=, ), process_links=process_links, callback='parse_item', follow=True ), ) def parse_item(self, response): return { 'url': response.url, 'metadata': extruct.extract( response.text, response.url, syntaxes= ), }jag ställer in följande attribut till True så att Scrapy fortfarande följer alla länkar från varje svar även om vi gav en anpassad parse-metod. Jag konfigurerade också extruct för att extrahera endast Open Graph metadata och JSON-LD, en populär metod för kodning av länkade data med JSON på webben, som används av IMDb. Du kan köra sökroboten och lagra objekt i JSON lines-format till en fil.
scrapy crawl imdb --logfile imdb.log -o imdb.jl -t jsonlinesutdatafilen imdb.jl innehåller en rad för varje genomsökt objekt. Till exempel ser den extraherade Open Graph-metadata för en film som tagits från <meta> – taggarna i HTML ut så här.
{ "url": "http://www.imdb.com/title/tt2442560/", "metadata": {"opengraph": , , , , , ] }]}}JSON-LD för ett enda objekt är för långt för att inkluderas i artikeln, här är ett exempel på vad Scrapy extraherar från <script type=”application/ld+json”> taggen.
"json-ld": , "contentRating": "TV-MA", "actor": ... }]utforska loggarna märkte jag ett annat vanligt problem med sökrobotar. Genom att sekventiellt klicka på filter genererar sökroboten webbadresser med samma innehåll, bara att filtren applicerades i en annan ordning.
https://www.imdb.com/namn / nm2900465 / videogalleri / content_type-trailer/related_titles-tt0479468
https://www.imdb.com/namn/nm2900465/videogallery/related_titles-tt0479468 / content_type-trailer
Långfilter och sökadresser är ett svårt problem som delvis kan lösas genom att begränsa längden på webbadresser med en Scrapy-inställning, URLLENGTH_LIMIT.
jag använde IMDb som ett exempel för att visa grunderna för att bygga en webbsökare i Python. Jag lät inte sökroboten springa länge eftersom jag inte hade ett specifikt användningsfall för data. Om du behöver specifika data från IMDb kan du kontrollera IMDb-Datasetsprojektet som ger en daglig export av IMDb-data och IMDbPY, ett Python-paket för att hämta och hantera data.
webbsökning i skala
om du försöker genomsöka en stor webbplats som IMDb, med över 45 miljoner sidor baserade på Google, är det viktigt att genomsöka ansvarsfullt genom att konfigurera följande inställningar. Du kan identifiera din sökrobot och ange kontaktuppgifter i BOT_NAME-inställningen. För att begränsa trycket du lägger på webbplatsens servrar kan du öka DOWNLOAD_DELAY, begränsa CONCURRENT_REQUESTS_PER_DOMAIN eller ställa in AUTOTHROTTLE_ENABLED som anpassar dessa inställningar dynamiskt baserat på svarstiderna från servern.
Lägg märke till att Scrapy crawls är optimerade för en enda domän som standard. Om du genomsöker flera domäner kontrollerar du dessa inställningar för att optimera för breda genomsökningar, inklusive att ändra standardgenomsökningsordningen från djup först till andetag först. För att begränsa din genomsökningsbudget kan du begränsa antalet förfrågningar med inställningen CLOSESPIDER_PAGECOUNT för tillägget close spider.
med standardinställningarna kryper Scrapy cirka 600 sidor per minut för en webbplats som IMDb. För att genomsöka 45m sidor tar det mer än 50 dagar för en enda robot. Om du behöver genomsöka flera webbplatser kan det vara bättre att starta separata sökrobotar för varje stor webbplats eller grupp av webbplatser. Om du är intresserad av distribuerade webbsökningar kan du läsa hur en utvecklare genomsökte 250m-sidor med Python på 40 timmar med 20 Amazon EC2-maskininstanser.
i vissa fall kan du stöta på webbplatser som kräver att du kör JavaScript-kod för att göra all HTML. Misslyckas med att göra det, och du får inte samla alla länkar på webbplatsen. Eftersom det idag är mycket vanligt att webbplatser gör innehåll dynamiskt i webbläsaren skrev jag en Scrapy middleware för att göra JavaScript-sidor med Scrapingbees API.
slutsats
vi jämförde koden för en Python-sökrobot med hjälp av tredjepartsbibliotek för nedladdning av webbadresser och tolkning av HTML med en sökrobot byggd med ett populärt webbsökningsramverk. Scrapy är en mycket performant webbgenomsökning ram och det är lätt att utöka med din egen kod. Men du måste veta alla platser där du kan ansluta din egen kod och inställningarna för varje komponent.
konfigurera Scrapy ordentligt blir ännu viktigare när du genomsöker webbplatser med miljontals sidor. Om du vill lära dig mer om webbsökning föreslår jag att du väljer en populär webbplats och försöker genomsöka den. Du kommer definitivt att stöta på nya problem, vilket gör ämnet fascinerande!