steg för steg: så här konfigurerar du en SQL SERVER 2008 R2 failover-KLUSTERINSTANS på WINDOWS SERVER 2008 R2 i AZURE eller AZURE STACK
den 9 juli 2019 upphör stödet för SQL Server 2008 och 2008 R2. Det betyder slutet på vanliga säkerhetsuppdateringar. Men om du flyttar dessa SQL Server-instanser till Azure eller Azure Stack (jag kommer helt enkelt att hänvisa till båda som Azure för resten av guiden), kommer Microsoft att ge dig tre års utökade säkerhetsuppdateringar utan extra kostnad. Om du för närvarande kör SQL Server 2008/2008 R2 och du inte kan uppdatera till en senare version av SQL Server före juli 9th deadline, vill du dra nytta av detta erbjudande snarare än att riskera att möta en framtida säkerhetsproblem. En opatchad instans av SQL Server kan leda till dataförlust, driftstopp eller en förödande dataintrång.
en av utmaningarna du kommer att möta när du kör SQL Server 2008/2008 R2 i Azure är att säkerställa hög tillgänglighet. På lokaler kan du köra en SQL Server Failover Cluster (FCI) instans för hög tillgänglighet, eller kanske du kör SQL Server i en virtuell maskin och förlitar sig på VMware HA eller en Hyper-V kluster för tillgänglighet. När du flyttar till Azure är inget av dessa alternativ tillgängliga. Driftstopp i Azure är en mycket verklig möjlighet att du måste vidta åtgärder för att mildra.
för att minska risken för driftstopp och kvalificera sig för Azures 99,95% eller 99.99% SLA, du måste utnyttja SIOS DataKeeper. DataKeeper övervinner Azure brist på delad lagring och låter dig bygga en SQL Server FCI i Azure som utnyttjar lokalt ansluten lagring på varje instans. SIOS DataKeeper stöder inte bara SQL Server 2008 R2 och Windows Server 2008 R2 som dokumenterats i den här guiden, den stöder alla versioner av Windows Server, från 2008 R2 till Windows Server 2019 och alla versioner av SQL Server från från SQL Server 2008 till SQL Server 2019.
den här guiden går igenom processen för att skapa en SQL Server 2008 R2 Failover Cluster Instance (FCI) med två noder i Azure, som körs på Windows Server 2008 R2. Även om SIOS DataKeeper också stöder kluster som spänner över tillgänglighetszoner eller regioner, antar den här guiden att varje nod finns i samma Azure-Region, men olika Feldomäner. SIOS DataKeeper kommer att användas i stället för den delade lagring som normalt krävs för att skapa en SQL Server 2008 R2 FCI.
förutsättningar
Active Directory
den här guiden förutsätter att du har en befintlig Active Directory-domän. Du kan hantera dina egna domänkontrollanter eller använda Azure Active Directory Domain Services. För denna handledning kommer vi att ansluta till en domän som heter contoso.lokalt. Naturligtvis kommer du att ansluta till din egen domän när du följer denna handledning.
öppna brandväggsportar
– SQL Server: 1433 för standardinstans
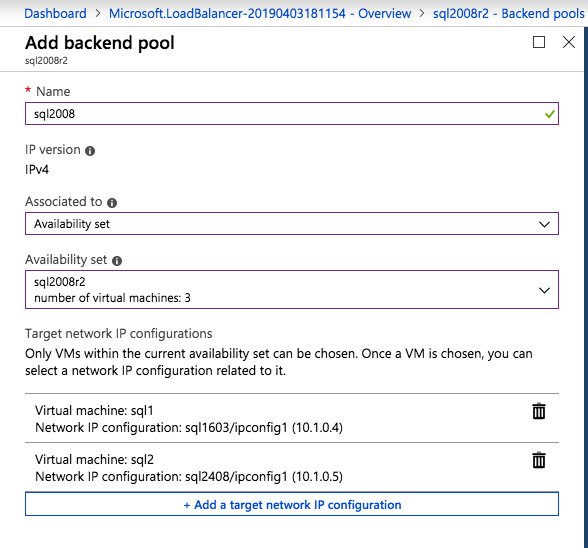
– ladda Balancer Health Probe: 59999
– DataKeeper: dessa brandväggsregler läggs till i Windows host-baserad brandvägg automatiskt under installationen. För mer information om vilka portar som öppnas, se Sios-dokumentationen.
– Tänk på att om du har någon nätverksbaserad säkerhet på plats som blockerar portar mellan klusternoden måste du också ta hänsyn till dessa portar där.
DataKeeper Service Account
skapa ett domänkonto. Vi kommer att ange detta konto när vi installerar DataKeeper. Det här kontot måste läggas till i gruppen lokala administratörer på varje nod i klustret.
skapa den första SQL Server-instansen i Azure
den här guiden utnyttjar SQL Server 2008r2sp3 på Windows Server 2008R2-bilden som publiceras på Azure Marketplace.
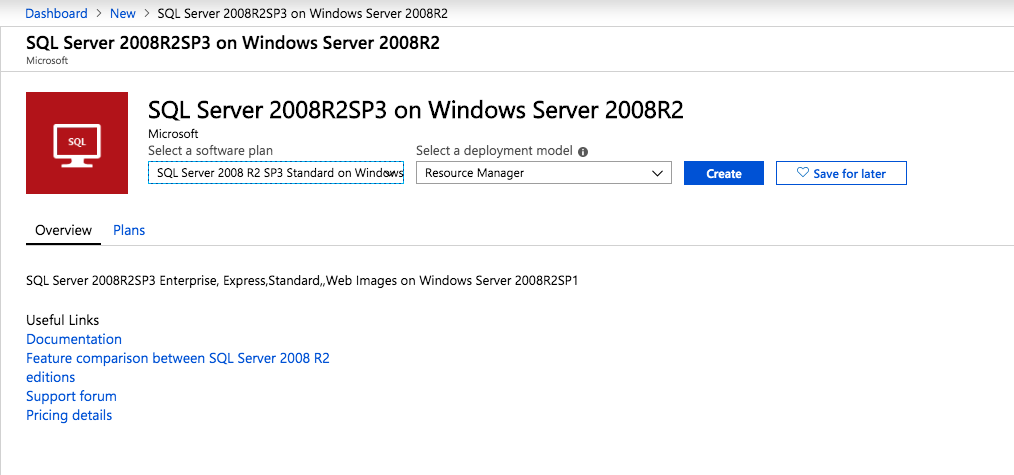
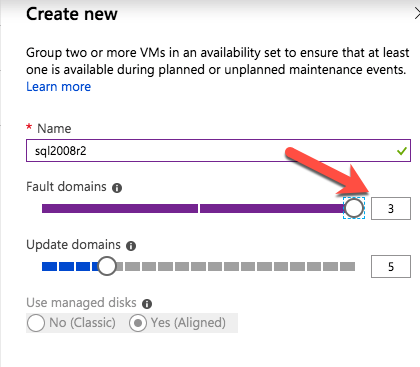
när du tillhandahåller den första instansen måste du skapa en ny Tillgänglighetsuppsättning. Under denna process måste du öka antalet Feldomäner till 3. Detta gör att de två klusternoderna och fildelningen bevittnar var och en att bo i sin egen Feldomän.
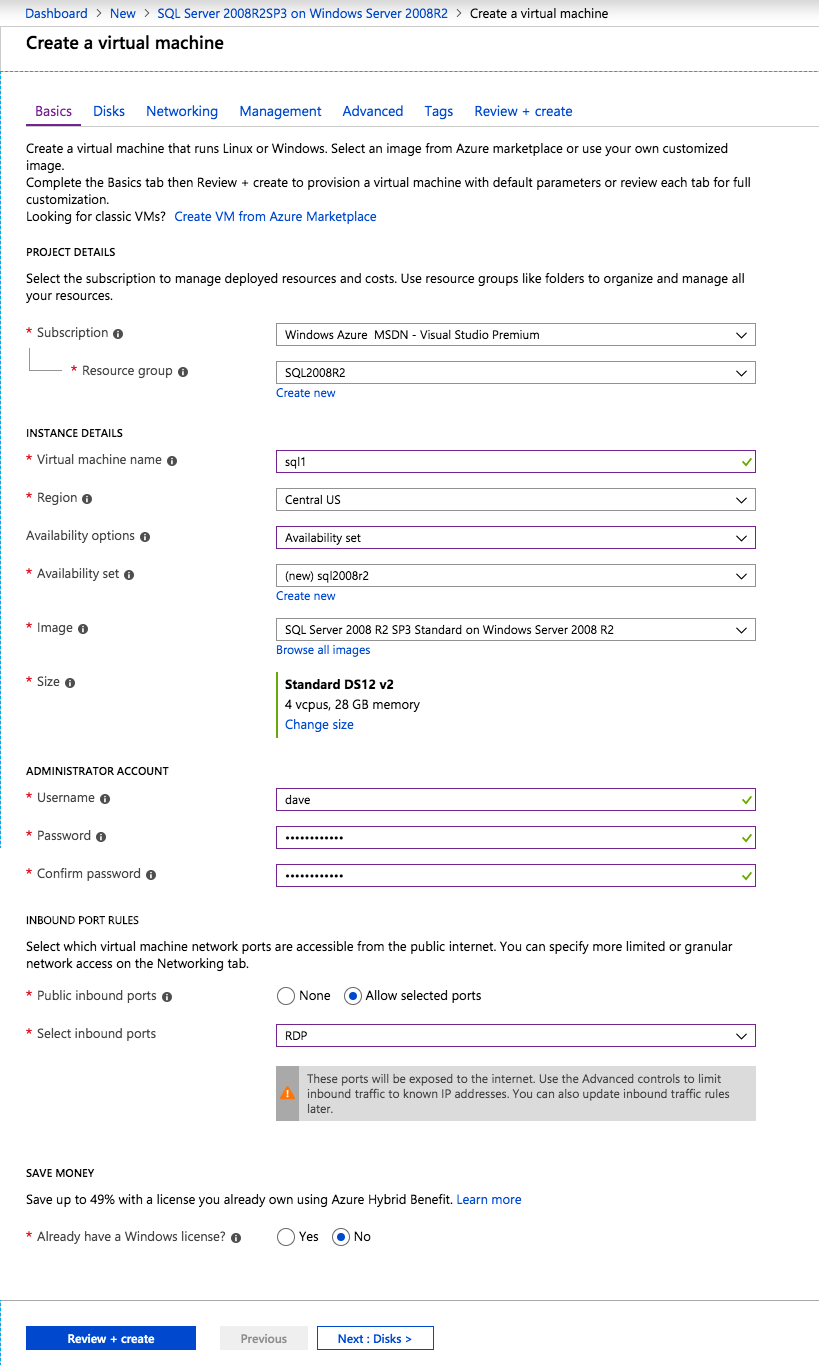
om du inte redan har ett virtuellt nätverk konfigurerat tillåter du skapningsguiden att skapa ett nytt åt dig.
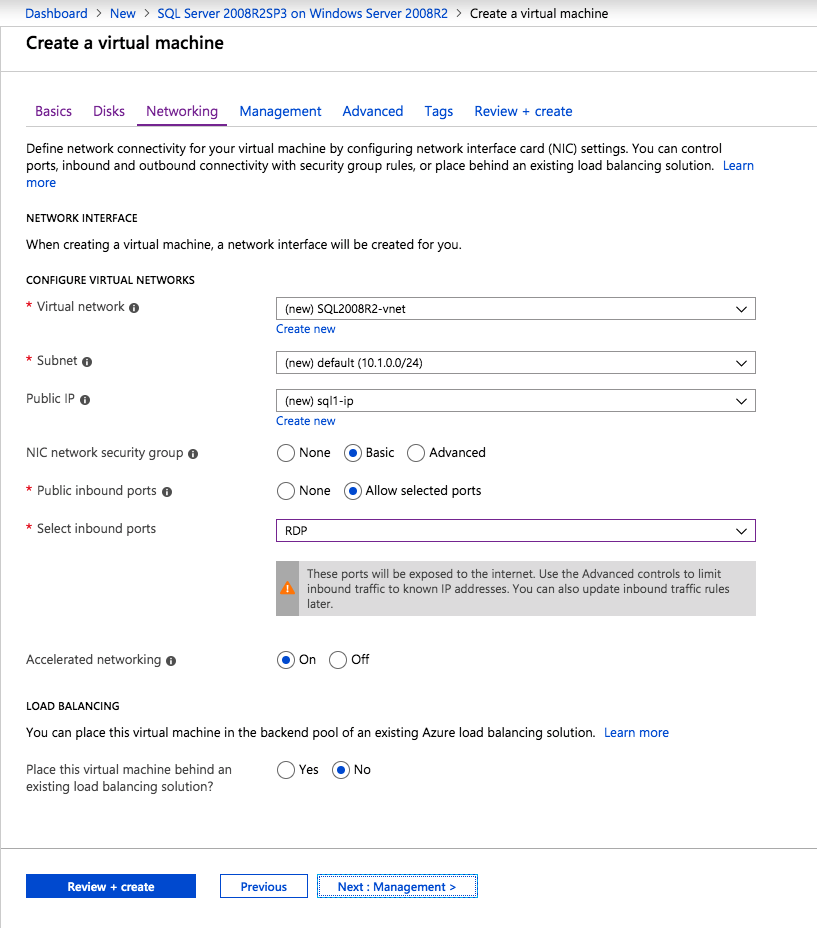
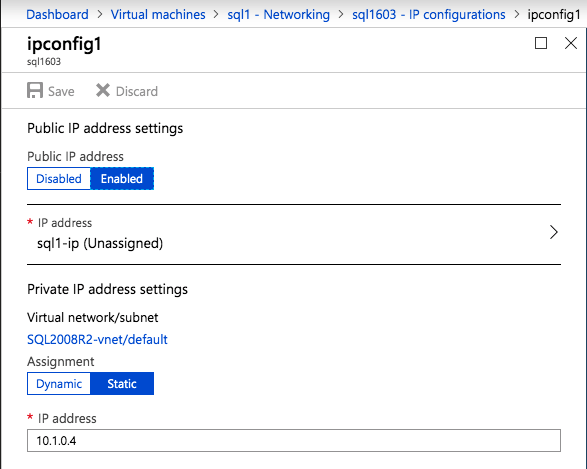
när instansen har skapats går du in i IP-konfigurationerna och gör den privata IP-adressen statisk. Detta krävs för SIOS DataKeeper och är bästa praxis för grupperade instanser.
se till att ditt virtuella nätverk är konfigurerat för att ställa in DNS-servern som en lokal Windows AD-kontroller för att säkerställa att du kommer att kunna gå med i domänen i ett senare steg.
när de virtuella maskinerna har tillhandahållits lägger du till minst två ytterligare diskar i varje instans. Premium eller Ultra SSD rekommenderas. Inaktivera caching på diskarna som används för SQL-loggfilerna. Aktivera skrivskyddad cachning på disken som används för SQL-datafilerna. Se Prestandariktlinjer för SQL Server i Azure Virtual Machines för ytterligare information om bästa praxis för lagring.
skapa den 2: a SQL Server-instansen i Azure
följ samma steg som ovan, utom se till att placera den här instansen i samma virtuella nätverk och Tillgänglighetsuppsättning som du skapade med den 1: a instansen.
skapa en FSW-instans (File Share Witness)
för att Windows Server Failover Cluster (WSFC) ska fungera optimalt måste du skapa en annan Windows Server-instans och placera den i samma Tillgänglighetsuppsättning som SQL Server-instanserna. Genom att placera den i samma Tillgänglighetsuppsättning säkerställer du att varje klusternod och FSW bor i olika Feldomäner, vilket säkerställer att ditt kluster stannar på rad om en hel Feldomän går ur linje. Dessa instanser kräver inte SQL Server, det kan vara en enkel Windows-Server eftersom allt det behöver göra är att vara värd för en enkel fildelning.
denna instans kommer att vara värd för fildelningsvittnet som krävs av WSFC. Denna instans behöver inte ha samma storlek, och det kräver inte heller några ytterligare diskar som ska bifogas. Det enda syftet är att vara värd för en enkel fildelning. Det kan faktiskt användas för andra ändamål. I min labbmiljö är min FSW också min domänkontrollant.
Avinstallera SQL Server 2008 R2
var och en av de två SQL Server-instanser som tillhandahålls har redan SQL Server 2008 R2 installerat på dem. De installeras dock som fristående SQL Server-instanser, inte grupperade instanser. SQL Server måste avinstalleras från var och en av dessa instanser innan vi kan installera klusterinstansen. Det enklaste sättet att göra det är att köra SQL-inställningen som visas nedan.
när du kör setup.exe / Action-RunDiscovery du kommer att se allt som är förinstallerat
setup.exe /Action=RunDiscovery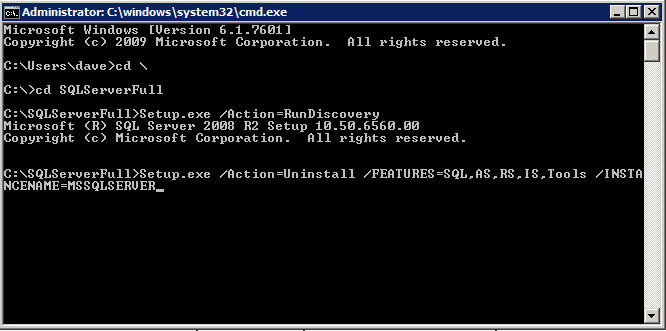

kör inställning.exe / Action = Avinstallera / funktioner=SQL, AS, RS, IS, Tools / INSTANCENAME=MSSQLSERVER startar avinstallationsprocessen
setup.exe /Action=Uninstall /FEATURES=SQL,AS,RS,IS,Tools /INSTANCENAME=MSSQLSERVER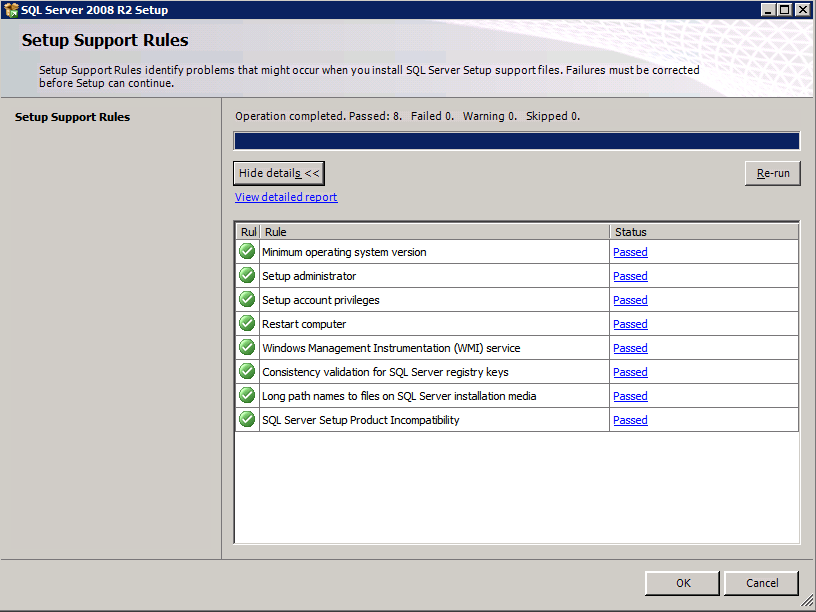
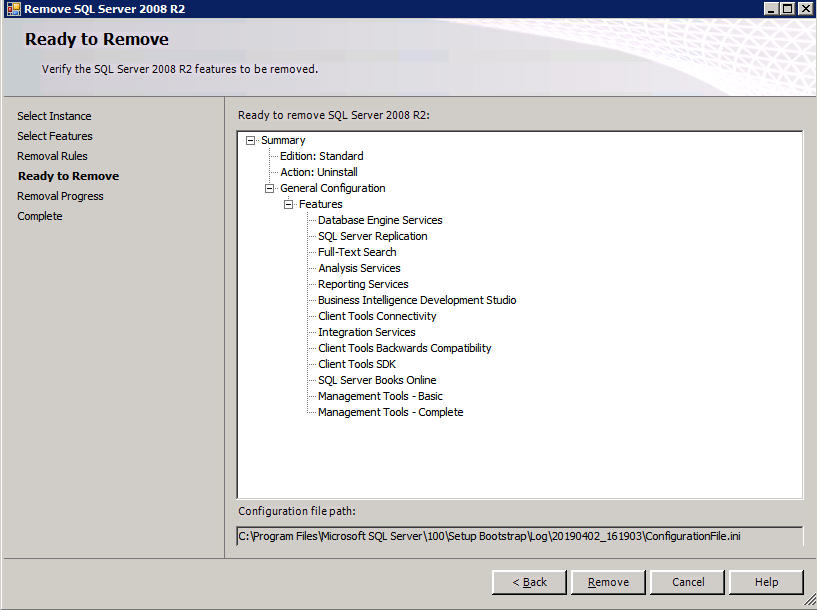
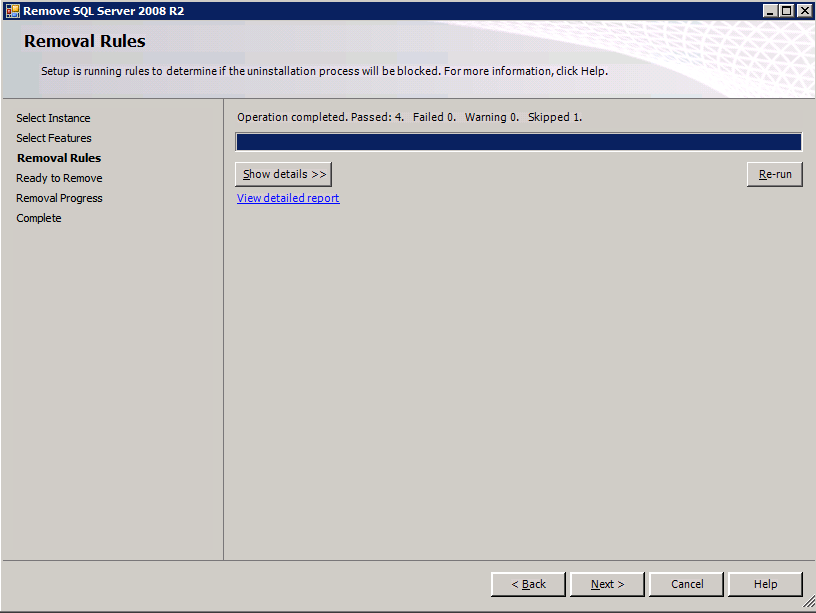
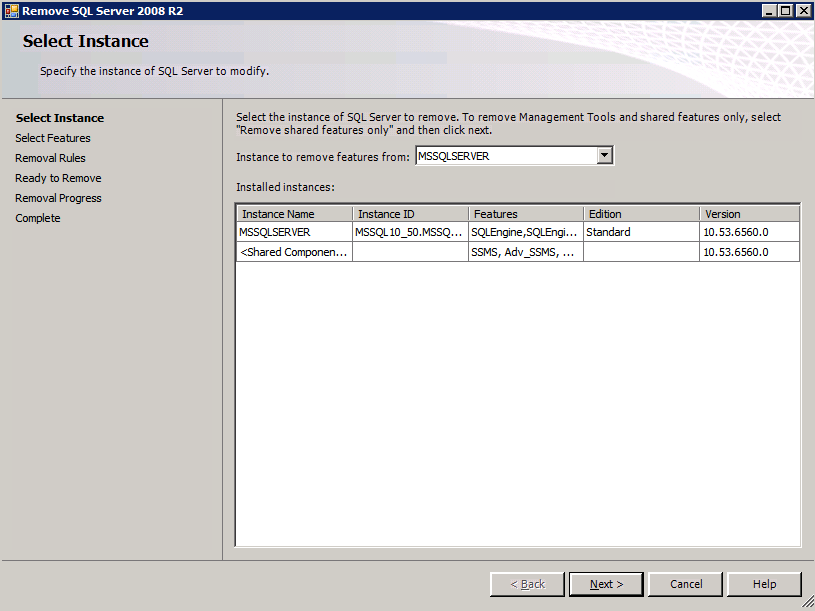
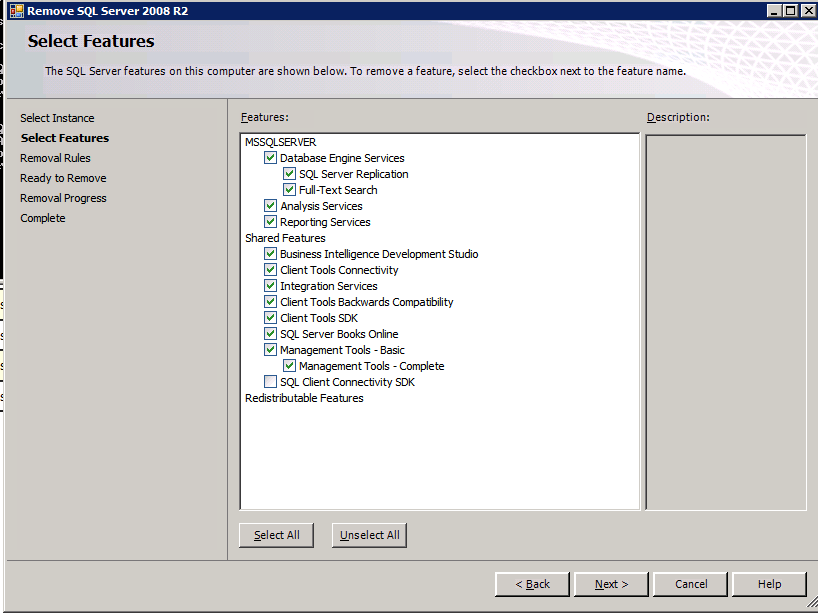
kör inställning.exe / Action-RunDiscovery bekräftar avinstallationen klar
setup.exe /Action-RunDiscovery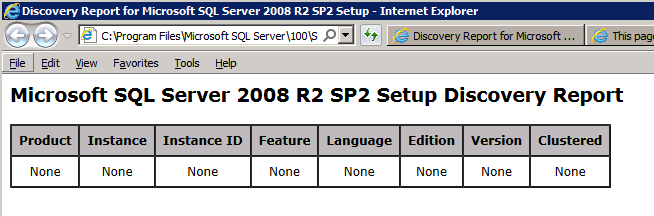
kör denna avinstallationsprocess igen på 2: a instansen.
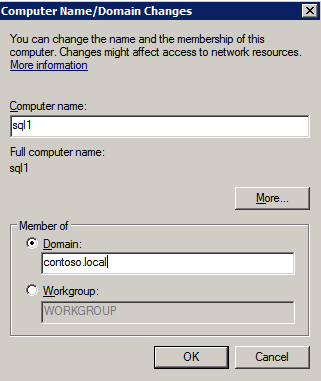
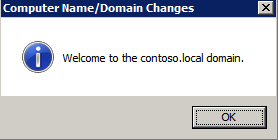
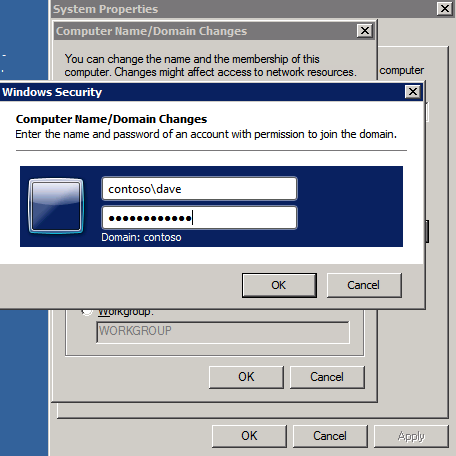
Lägg till instanser i domänen
alla tre av dessa instanser måste läggas till i en Windows-domän. Som nämnts i avsnittet förutsättningar måste du ha åtkomst för att gå med i en befintlig Windows Active Directory. I vårt fall går vi med i en domän som heter contoso.lokalt.
Lägg till Windows Failover Clustering Feature
Failover Clustering Feature måste läggas till i de två SQL Server-instanserna
Add-WindowsFeature Failover-Clustering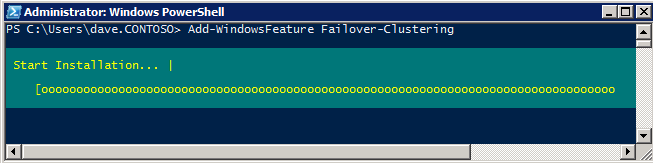
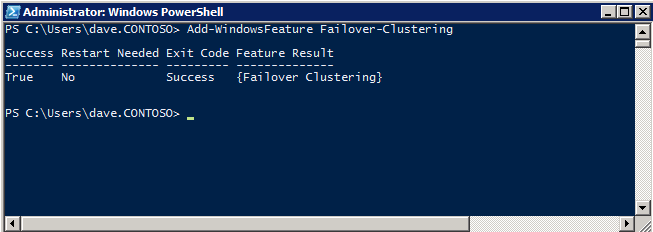
installera Convenience Rollup Update för Windows Server 2008 R2 SP1
det finns en kritisk uppdatering ( kb2854082) som krävs för att konfigurera en Windows Server 2008 R2-instans i Azure. Den uppdateringen och många fler ingår i Convenience Rollup Update för Windows Server 2008 R2 SP1. Installera den här uppdateringen på var och en av de två SQL Server-instanserna.
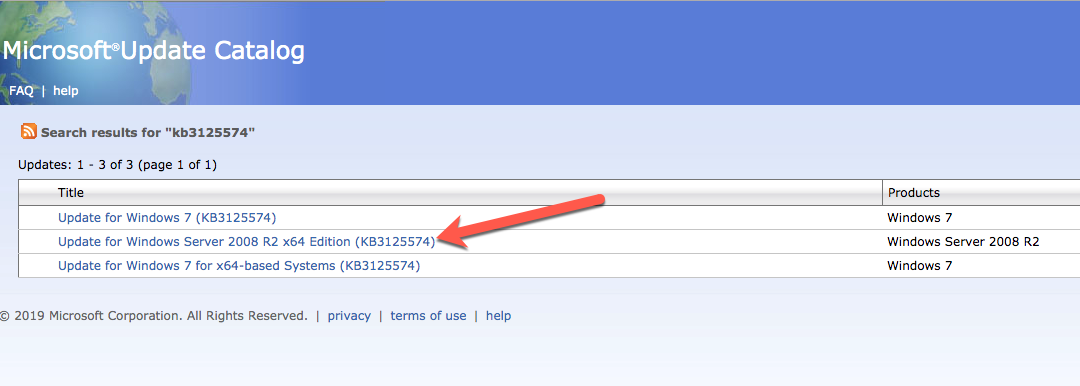
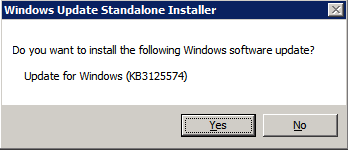
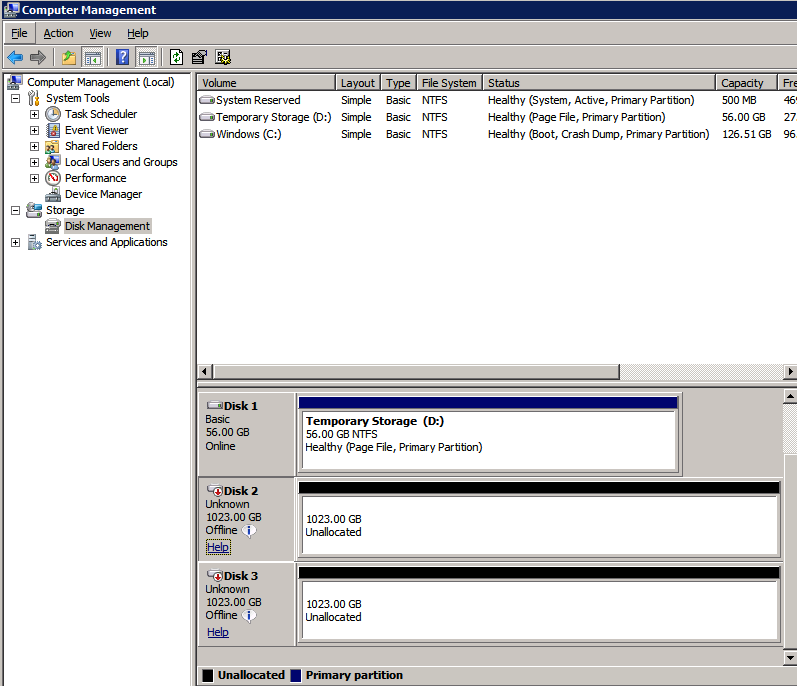
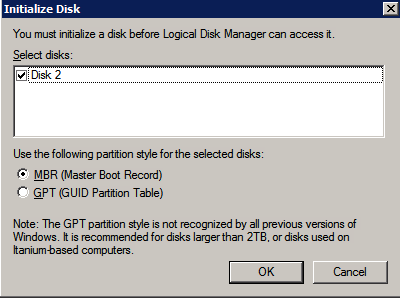
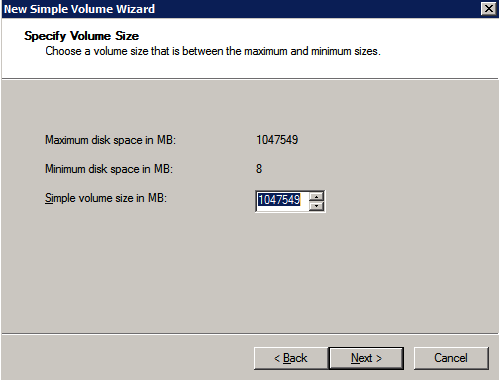
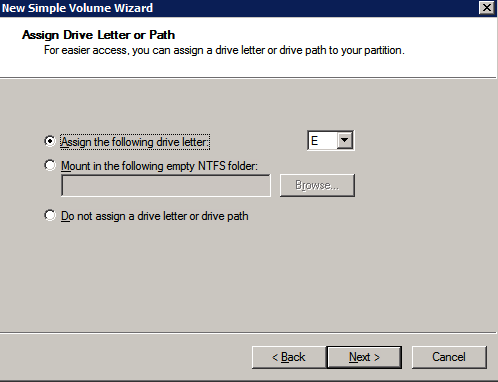
formatera lagringen
de ytterligare diskar som bifogades när de två SQL Server-instanserna tillhandahölls måste formateras. Gör följande för varje volym i varje instans.
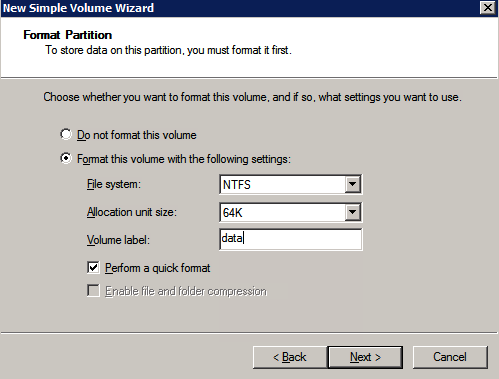
Microsoft best practices säger följande …
”NTFS allokeringsenhet storlek: När du formaterar datadisken rekommenderas att du använder en storlek på 64 KB allokeringsenhet för data-och loggfiler samt TempDB.”
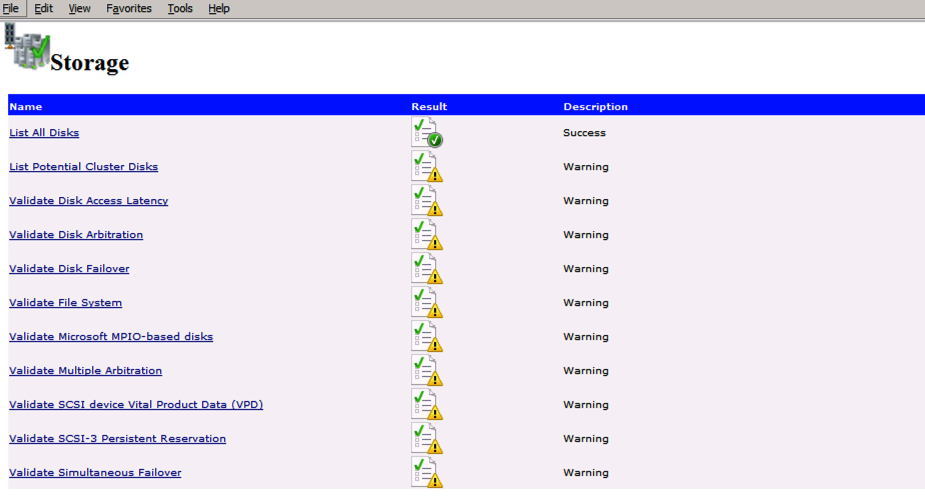
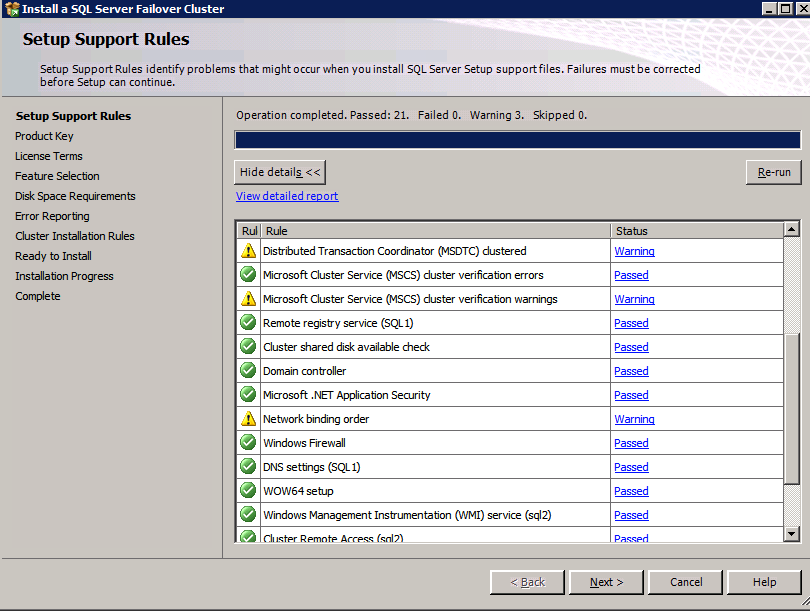
kör Klustervalidering
kör klustervalidering för att säkerställa att allt är klart att grupperas.
Import-Module FailoverClustersTest-Cluster -Node "SQL1", "SQL2"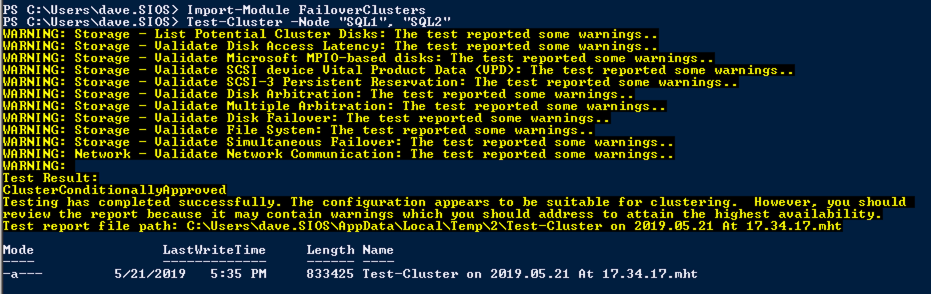
din rapport kommer att innehålla varningar om lagring och nätverk. Du kan ignorera dessa varningar eftersom vi vet att det inte finns några delade diskar och det finns bara en enda nätverksanslutning mellan servrarna. Du kan också få en varning om nätverk bindande ordning som också kan ignoreras. Om du stöter på några fel måste du ta itu med dem innan du fortsätter.
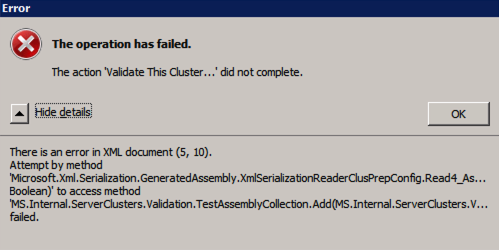
fel försöker köra Klustervalidering?
jag har stött på detta fel vid några tillfällen och jag försöker fortfarande reda ut under vilka förhållanden detta inträffar. Ibland kommer du att upptäcka att testklustret inte körs som beskrivet i foruminlägget.
Test-ClusterUnable to Validate a Cluster Configuration. The operation has failed. The action validate a configuration did not completeThere is an error in XML document (5, 73). Attempt by methodMicrosoft.Xml.Serialzation.GeneratedAssembly.XmlSerialzationReaderClusterPrep.Config.Read4_As...Bolean) to access methodMS.Internal.ServerClusters.Validation.TestAssemblyCollection.Add(MS.Internal.ServerClusters.V....Failedom detta händer dig har jag hittat följande fix som rekommenderas i foruminlägget fungerar för mig.
Inside C:\Windows\System32\WindowsPowerShell\v1.0 make a copy of powershell_ise.exe.config file (make a copy inside C:\Windows\System32\WindowsPowerShell\v1.0)- rename it to powershell.exe.configOpen it with notepad- delete current config line and paste:<?xml version="1.0" encoding="utf-8" ?><configuration> <system.xml.serialization> <xmlSerializer useLegacySerializerGeneration="true"/> </system.xml.serialization></configuration>- save and run test-clustermedan den här korrigeringen låter dig köra testkluster från Powershell, har jag funnit att körning validera via GUI fortfarande kastar ett fel, även med den här korrigeringen. Jag har en fråga till Microsoft för att se om de har en lösning, men för tillfället om du behöver köra klustervalidering kan du behöva använda Testkluster i Powershell.
skapa klustret
bästa praxis för att skapa ett kluster i Azure är att använda Powershell för att skapa ett kluster och ange en statisk IP-adress. Powershell tillåter oss att ange en statisk IP-adress, medan GUI-metoden inte gör det. Tyvärr fungerar inte Azure-implementeringen av DHCP bra med WSFC, så om du använder GUI-metoden kommer du att sluta med en dubblett IP-adress som klustrets IP-adress som måste åtgärdas innan klustret kan användas.
men vad jag har hittat är att det typiska nya Cluster powershell-kommandot med-StaticAddress-kommandot inte fungerar. För att undvika problemet med den dubbla IP-adressen måste vi tillgripa klustret.exe utility och kör följande kommando.
cluster /cluster:cluster1 /create /nodes:"sql1 sql2" /ipaddress:10.0.0.100/255.255.255.0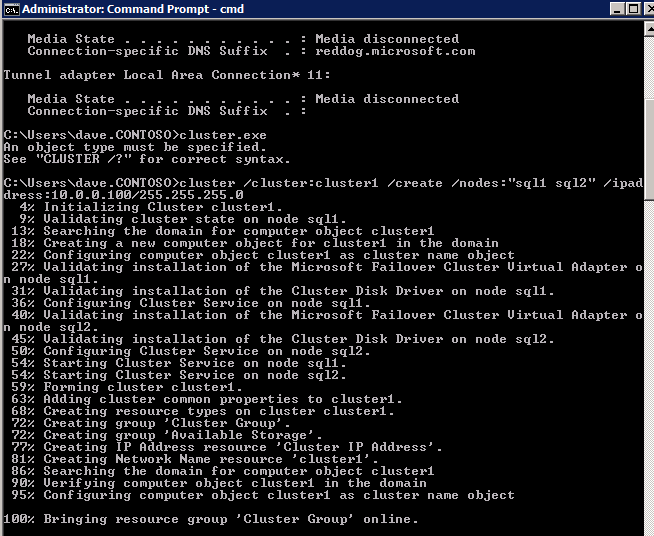
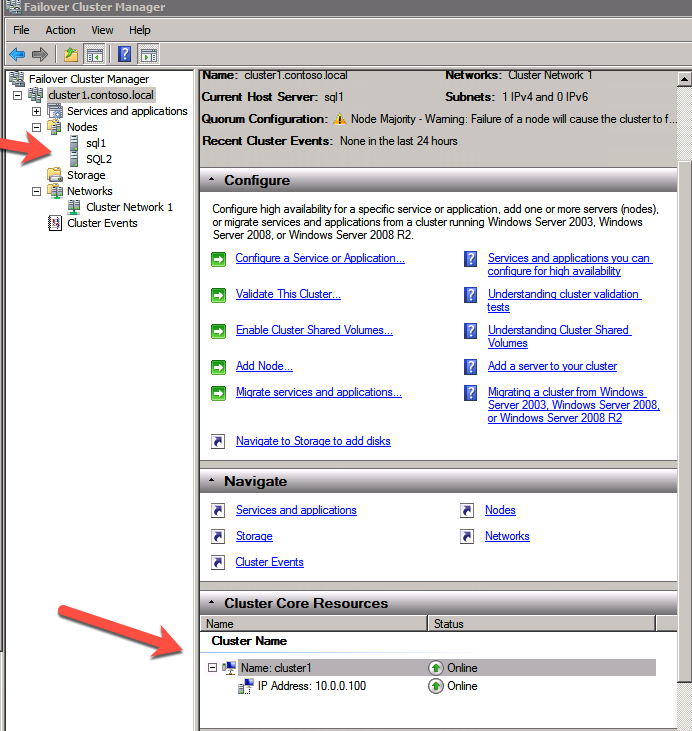
Lägg till File Share Witness
nästa måste vi lägga till File Share Witness. På den 3: e servern vi tillhandahöll som FSW, skapa en mapp och dela den enligt nedan. Du måste ge CNO (Cluster Name Object) läs – /skrivbehörigheter på både delnings-och säkerhetsnivåer som visas nedan.
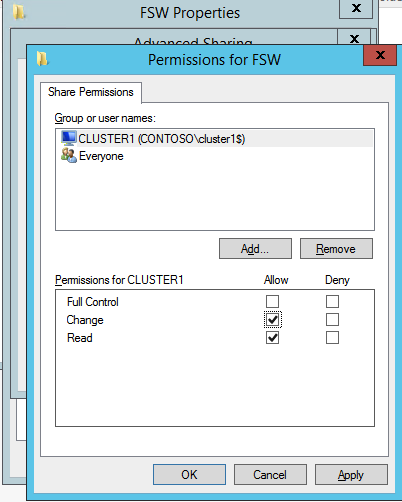
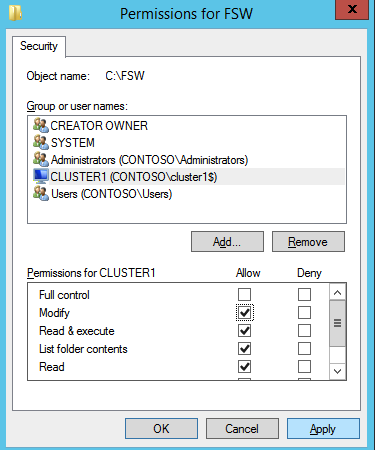
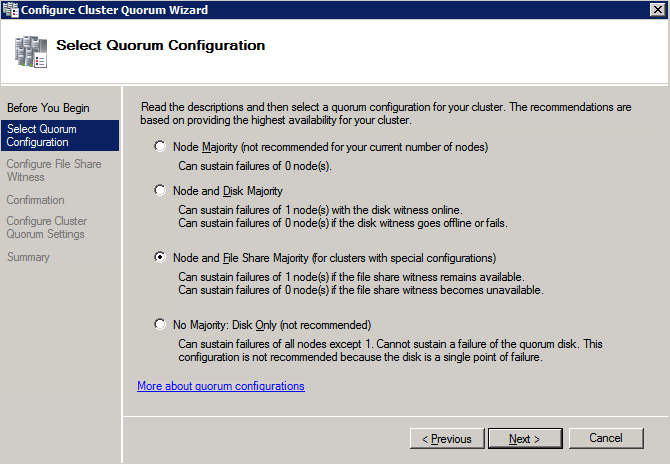
när delningen har skapats kör du guiden Konfigurera Klusterkvorum på en av klusternoderna och följ stegen nedan.
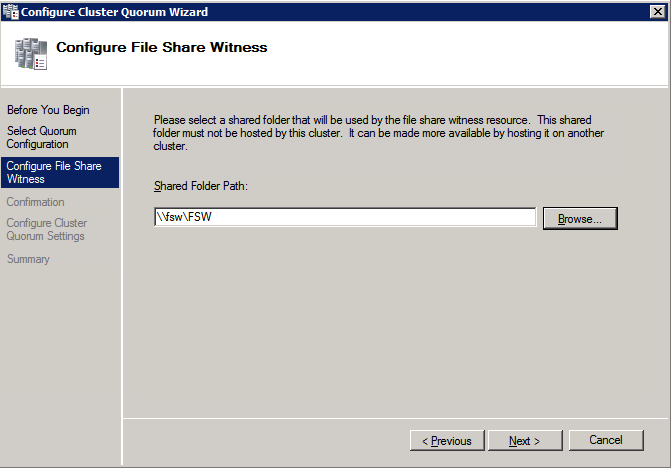
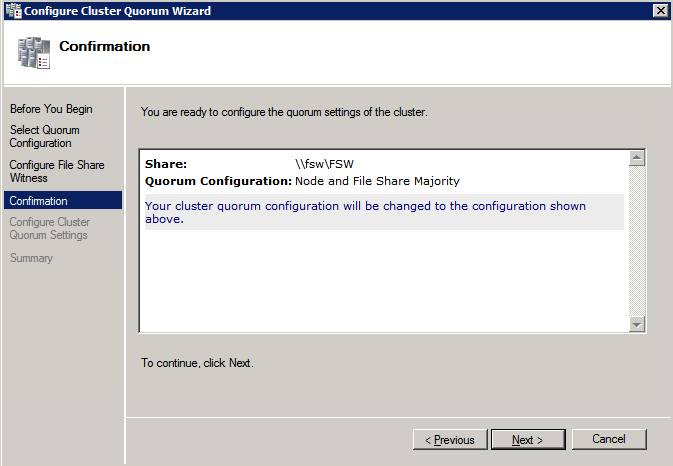
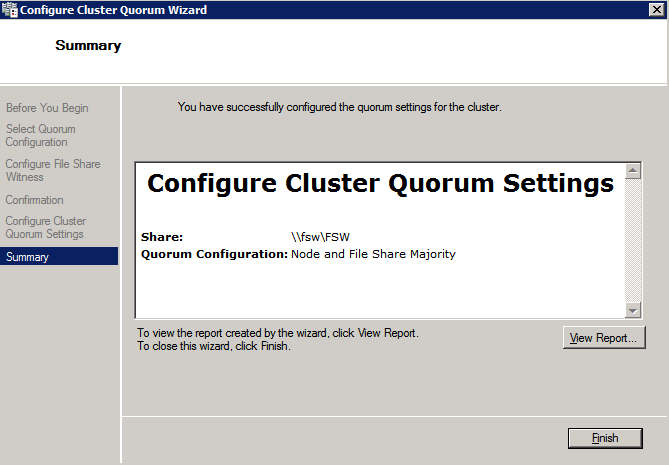
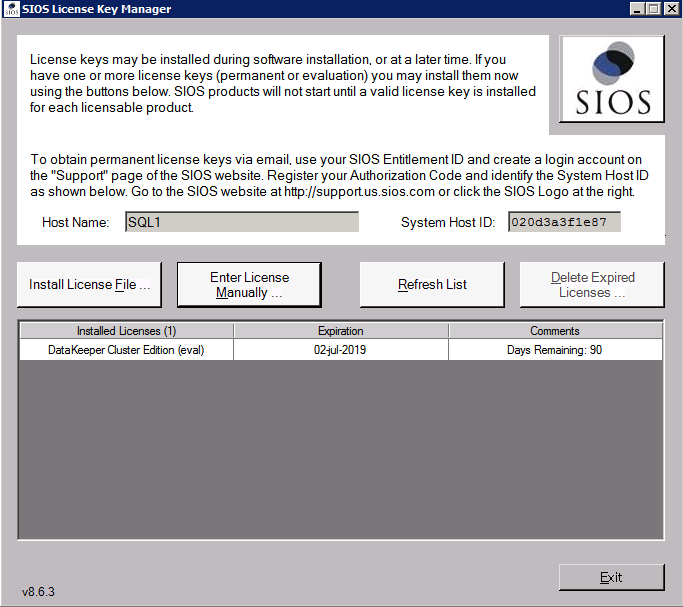
installera DataKeeper
installera DataKeeper på var och en av de två SQL Server-klusternoder som visas nedan.
det är här vi kommer att ange Domänkontot som vi har lagt till i var och en av gruppen lokala domänadministratörer.
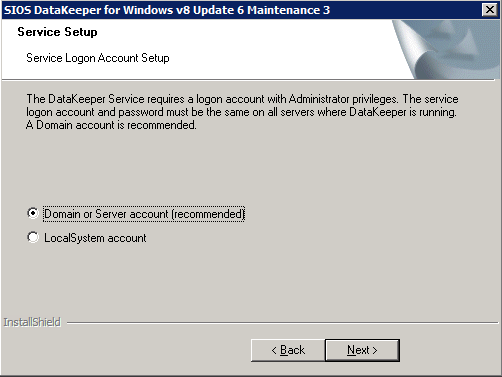
konfigurera DataKeeper
när DataKeeper har installerats på var och en av de två klusternoderna är du redo att konfigurera DataKeeper.
OBS-Det vanligaste felet i följande steg är säkerhetsrelaterat, oftast av befintliga Azure-säkerhetsgrupper som blockerar nödvändiga portar. Se Sios-dokumentationen för att säkerställa att servrarna kan kommunicera över de nödvändiga portarna.
först måste du ansluta till var och en av de två noderna.
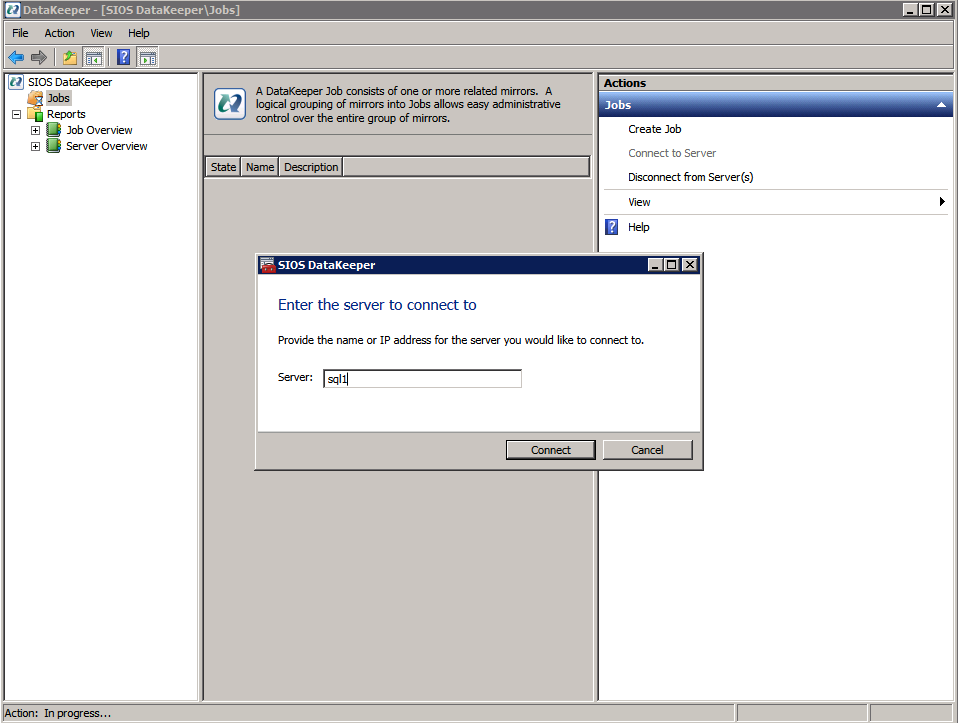
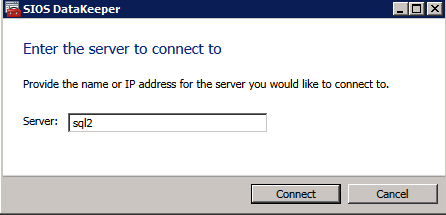
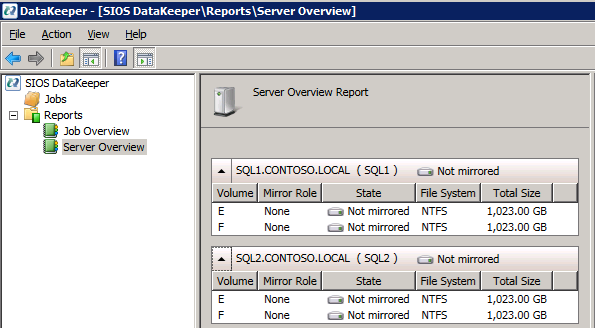
om allt är korrekt konfigurerat bör du se följande i Serveröversiktsrapporten.
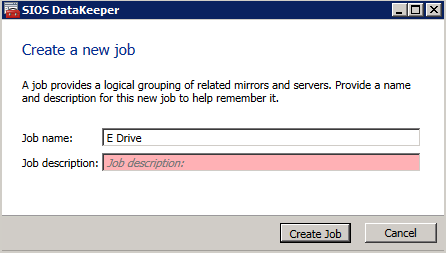
skapa sedan ett nytt jobb och följ stegen nedan
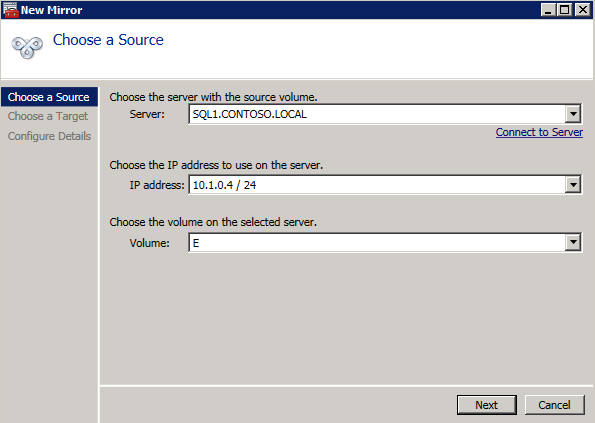
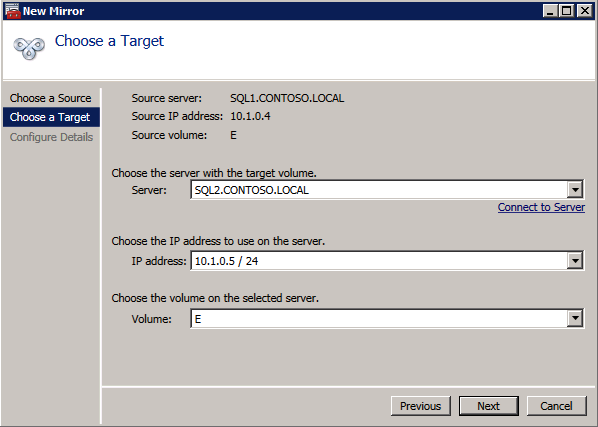
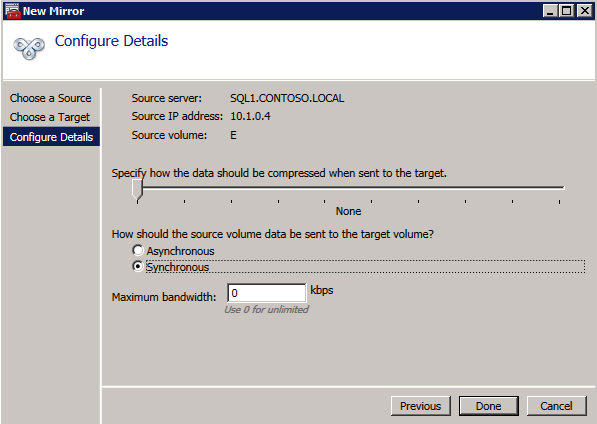
Välj Ja här för att registrera DataKeeper Volume resource I tillgängligt lagringsutrymme
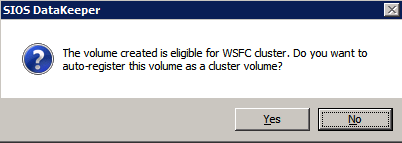
Slutför ovanstående steg för var och en av volymerna. När du är klar bör du se följande i WSFC-användargränssnittet.
du är nu redo att installera SQL Server i klustret.
OBS-vid denna tidpunkt är den replikerade volymen endast tillgänglig på den nod som för närvarande är värd för Tillgänglig Lagring. Det förväntas, så oroa dig inte!
installera SQL Server på den första noden
om du vill skriva installationen har jag inkluderat exemplet nedan för en skriptklusterinstallation av SQL Server 2008 R2 i den första noden i klustret. Skriptet för att lägga till en nod i befintligt kluster finns längre ner i guiden.
naturligtvis justera för din miljö.
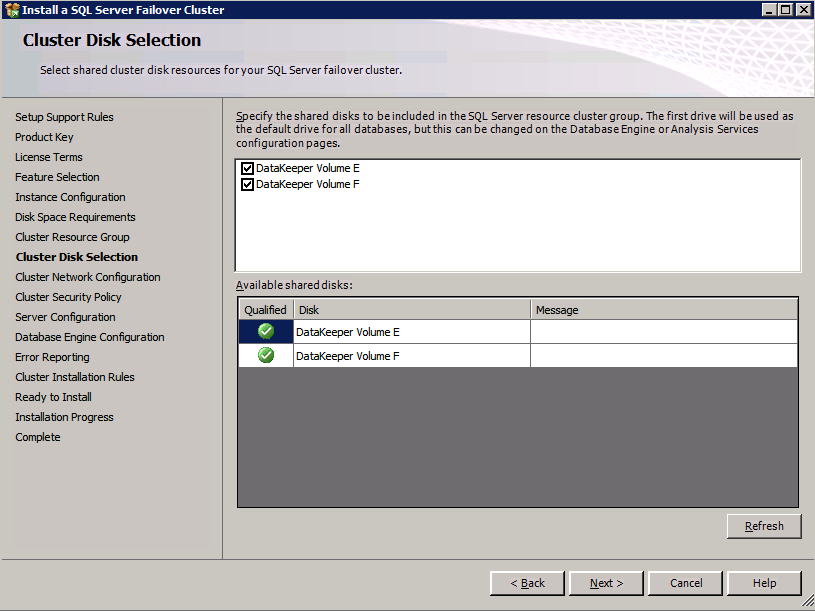
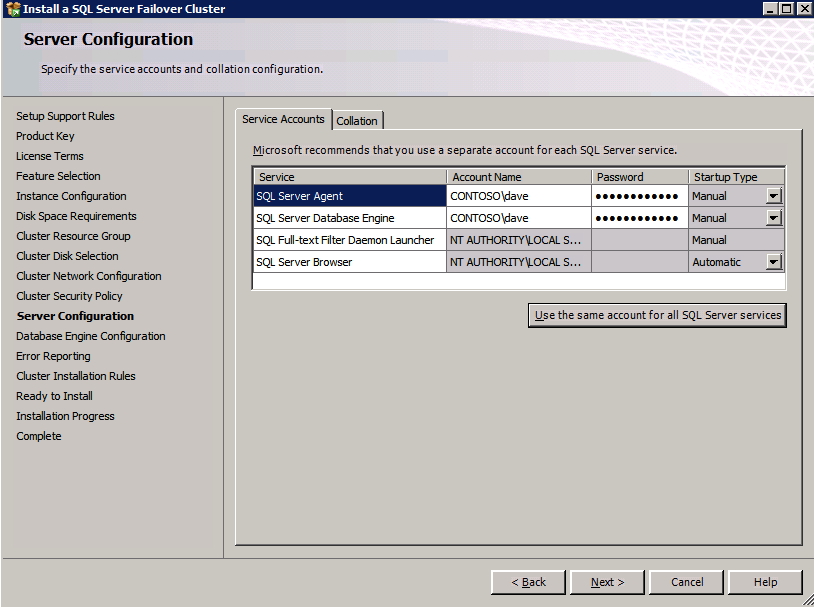
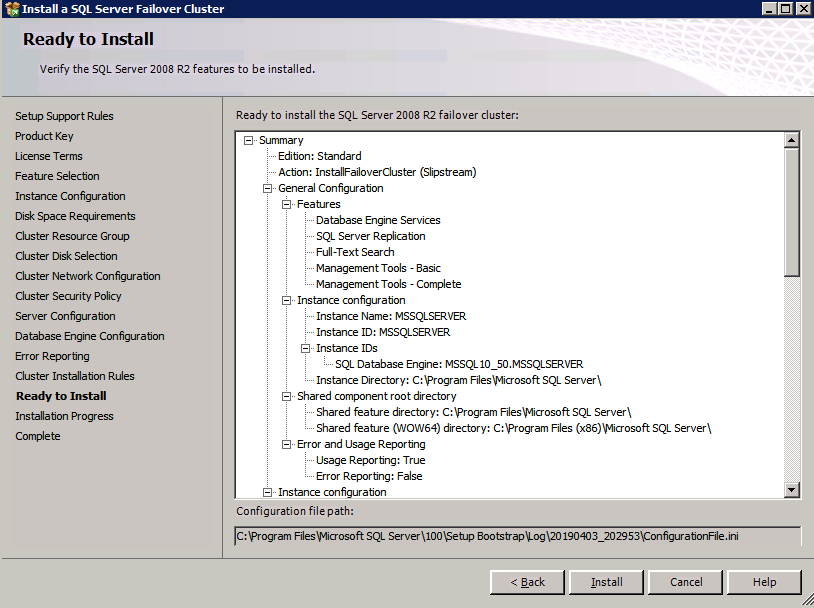
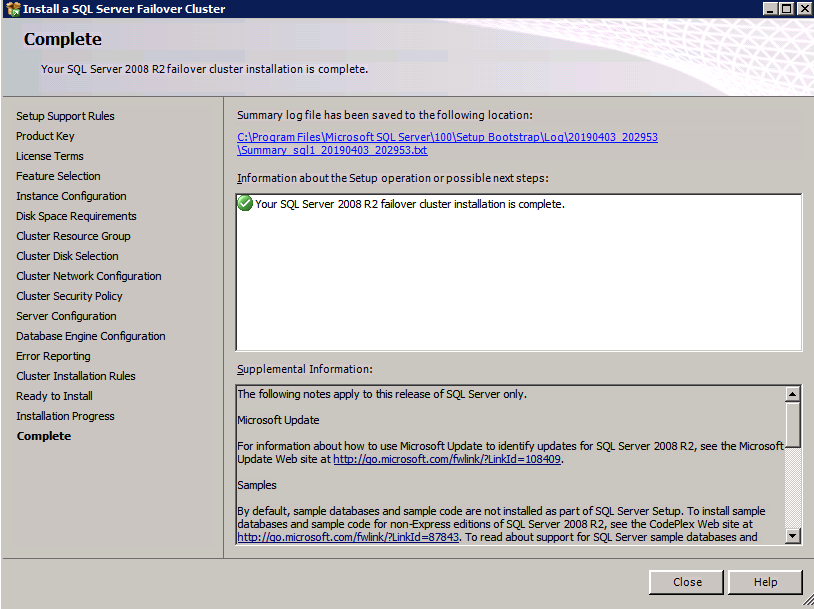
c:\SQLServerFull\setup.exe /q /ACTION=InstallFailoverCluster /FEATURES=SQL /INSTANCENAME="MSSQLSERVER" /INSTANCEDIR="C:\Program Files\Microsoft SQL Server" /INSTALLSHAREDDIR="C:\Program Files\Microsoft SQL Server" /SQLSVCACCOUNT="contoso\admin" /SQLSVCPASSWORD="xxxxxxxxx" /AGTSVCACCOUNT="contoso\admin" /AGTSVCPASSWORD="xxxxxxxxx" /SQLDOMAINGROUP="contoso\SQLAdmins" /AGTDOMAINGROUP="contoso\SQLAdmins" /SQLCOLLATION="SQL_Latin1_General_CP1_CI_AS" /FAILOVERCLUSTERGROUP="SQL Server 2008 R2 Group" /FAILOVERCLUSTERDISKS="DataKeeper Volume E" "DataKeeper Volume F" /FAILOVERCLUSTERIPADDRESSES="IPv4;10.0.0.101;Cluster Network 1;255.255.255.0" /FAILOVERCLUSTERNETWORKNAME="SQL2008Cluster" /SQLSYSADMINACCOUNTS="contoso\admin" /SQLUSERDBLOGDIR="E:\MSSQL10.MSSQLSERVER\MSSQL\Log" /SQLTEMPDBLOGDIR="F:\MSSQL10.MSSQLSERVER\MSSQL\Log" /INSTALLSQLDATADIR="F:\MSSQL10.MSSQLSERVER\MSSQLSERVER" /IAcceptSQLServerLicenseTermsom du föredrar att använda GUI, följ bara med skärmdumparna nedan.
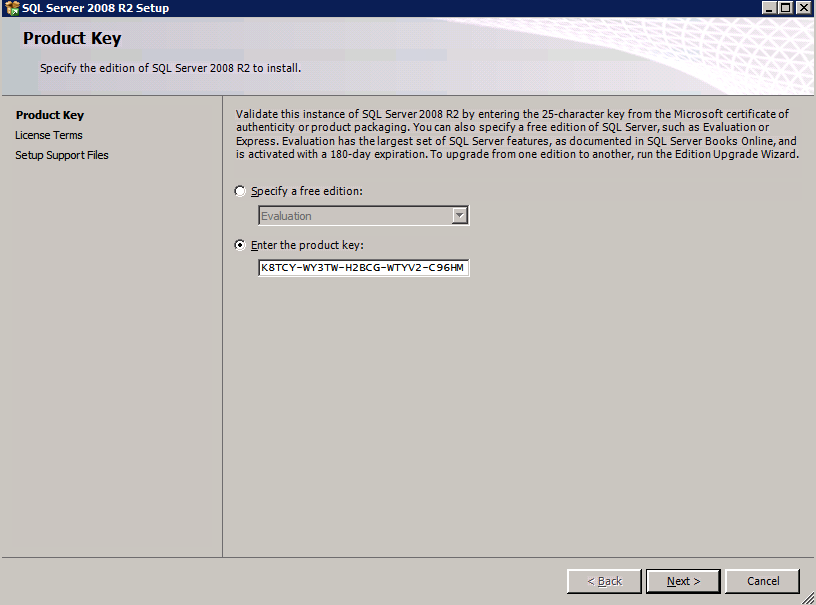
kör SQL Server-inställningen på den första noden.
Välj Ny SQL Server Failover Cluster Installation och följ stegen som illustreras.
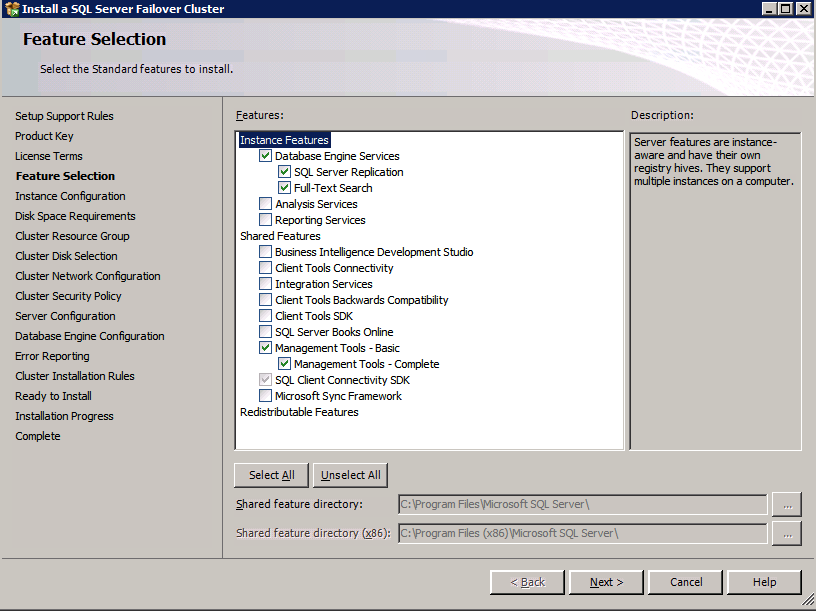
välj bara de alternativ du behöver.
Observera att det här dokumentet förutsätter att du använder STANDARDINSTANSEN för SQL Server. Om du använder en namngiven instans måste du se till att du låser porten som den lyssnar på och använder den porten senare när du konfigurerar lastbalanseraren. Du måste också skapa en lastbalanserregel för SQL Server Browser Service (UDP 1434) för att ansluta till en namngiven instans. Inget av dessa två krav omfattas av den här guiden, men om du behöver en namngiven instans fungerar det om du gör de två ytterligare stegen.
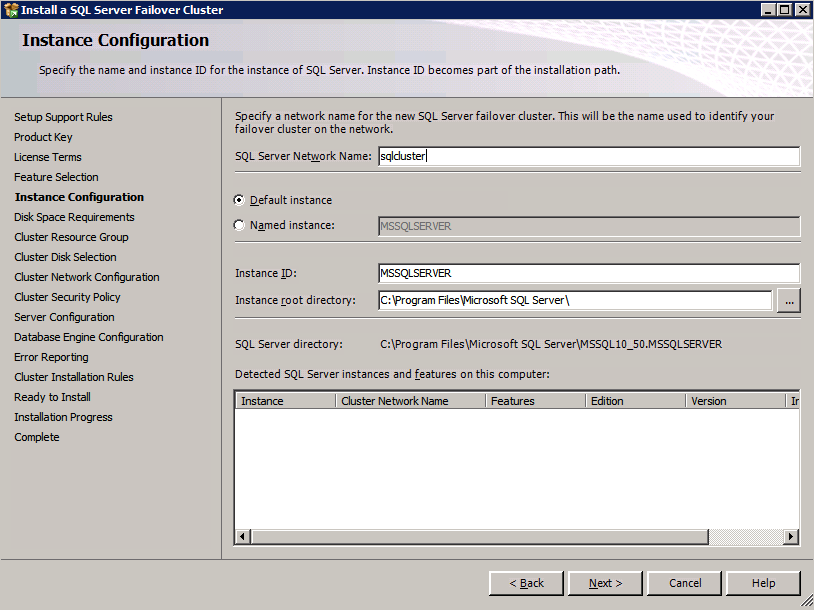
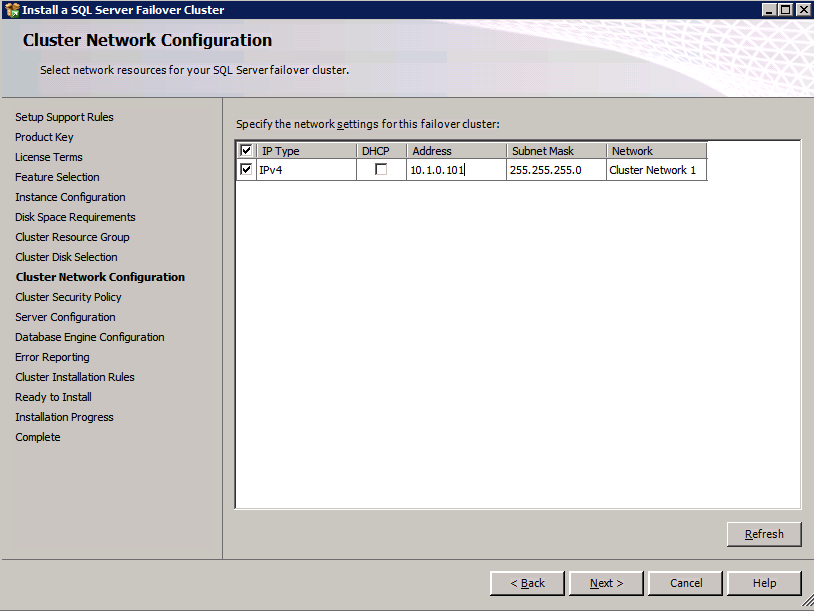
här måste du ange en oanvänd IP-adress
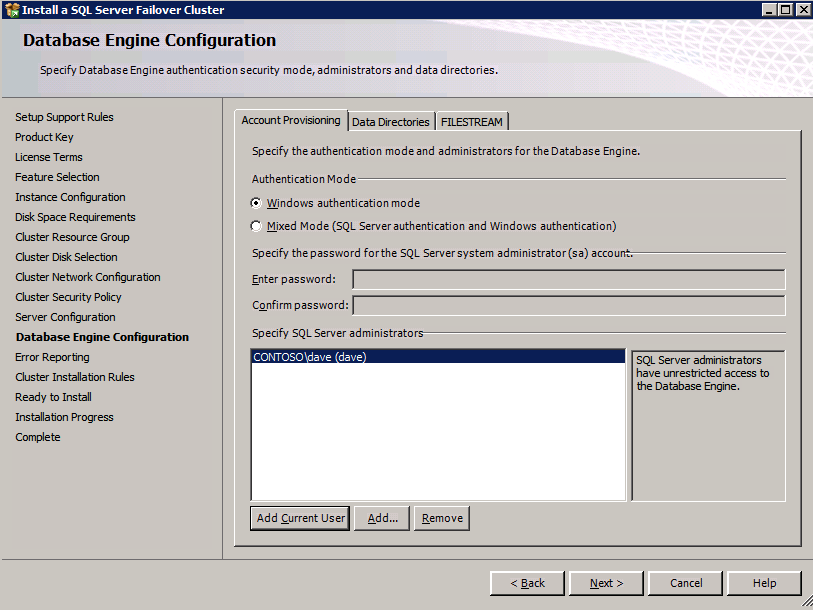
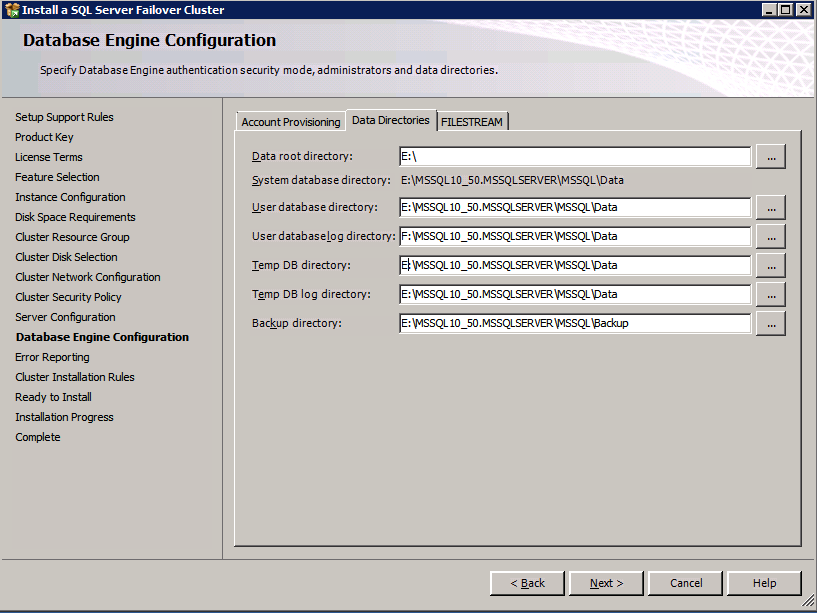
gå till fliken datakataloger och flytta data och loggfiler. I slutet av den här guiden pratar vi om att flytta tempdb till en icke-speglad DataKeeper-volym för optimal prestanda. För nu, håll det bara på en av de klustrade skivorna.
installera SQL Server på den andra noden
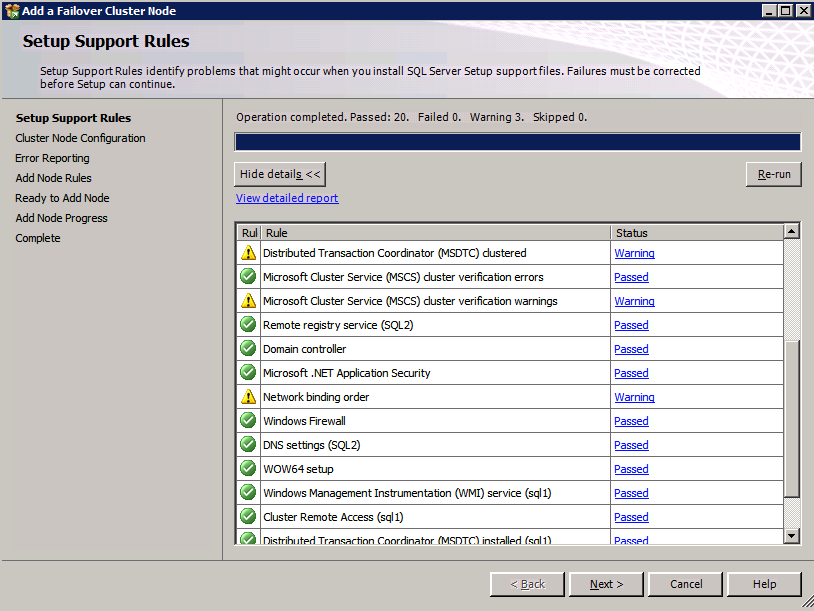
nedan är ett exempel på kommandot du kan köra för att lägga till en ytterligare SQL Server 2008 R2-nod i ett befintligt kluster.
c:\SQLServerFull\setup.exe /q /ACTION=AddNode /INSTANCENAME="MSSQLSERVER" /SQLSVCACCOUNT="contoso\admin" /SQLSVCPASSWORD="xxxxxxxxx" /AGTSVCACCOUNT="contoso\admin" /AGTSVCPASSWORD="xxxxxxxx" /IAcceptSQLServerLicenseTermsom du föredrar att använda GUI, följ med följande skärmdumpar.
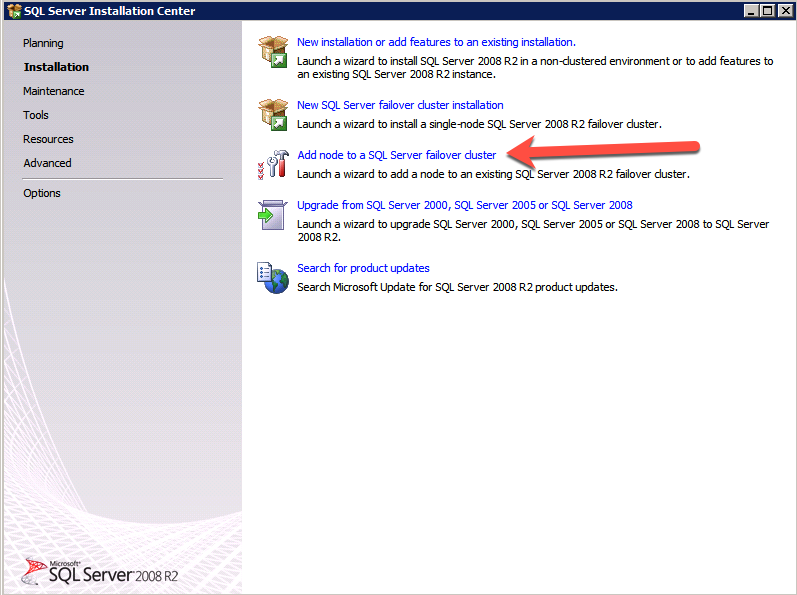
kör SQL Server-inställningen igen på den andra noden och välj Lägg till nod i ett SQL Server Failover-kluster.
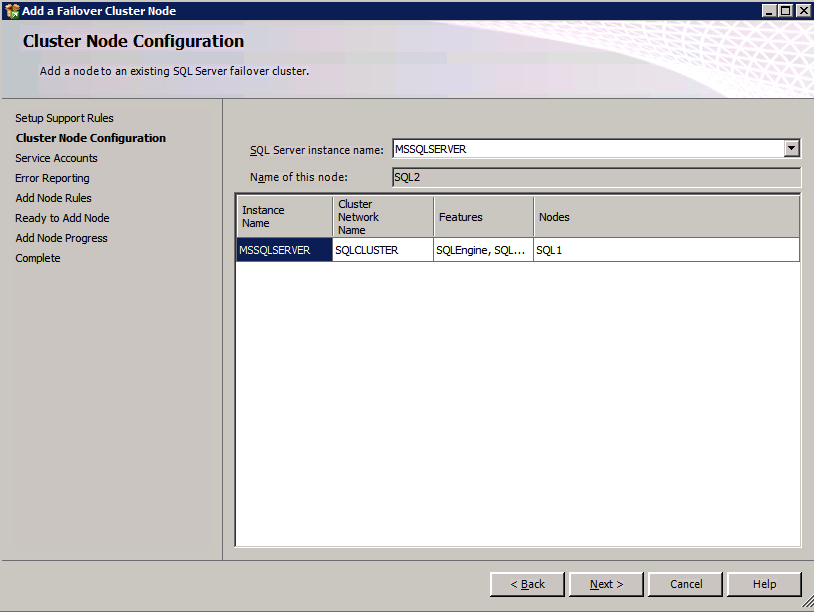
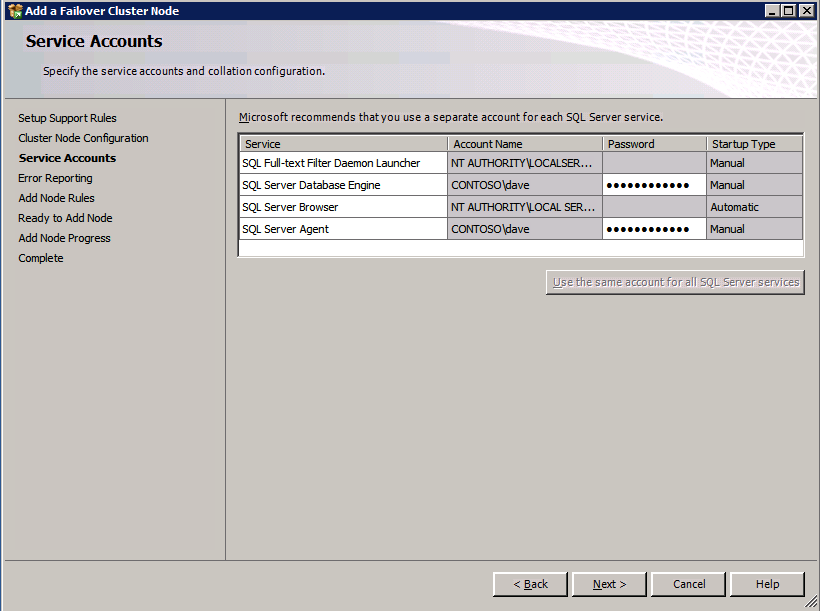
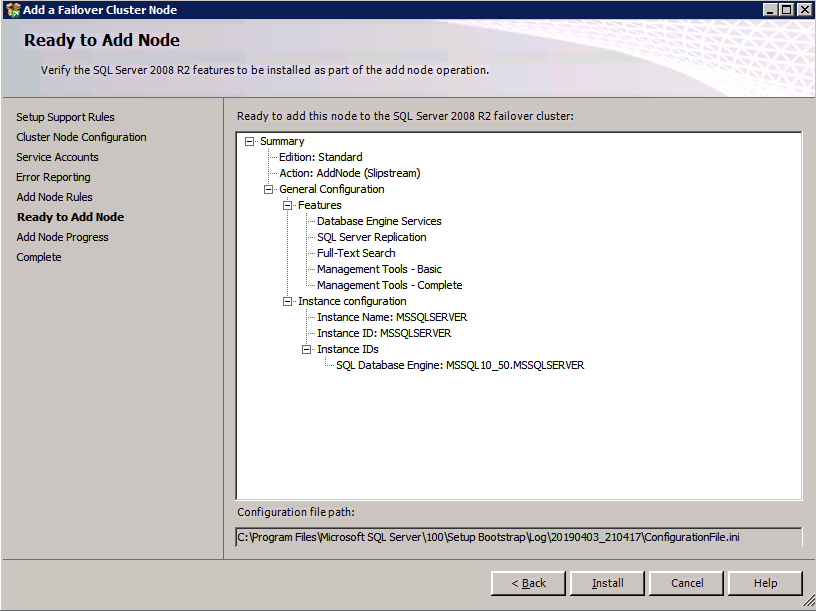
Congratulations, du är nästan klar! Men på grund av Azure brist på stöd för omotiverat ARP, vi kommer att behöva konfigurera en intern lastbalanserare (ILB) för att hjälpa till med klient omdirigering som visas i följande steg.
uppdatera SQL-klustrets IP-adress
för att ILB ska fungera korrekt måste du köra kör följande kommando från en av klusternoderna. Det SQL Cluster IP gör SQL Cluster IP-adress för att svara på ILB health probe samtidigt ställa in nätmask till 255.255.255.255 för att undvika IP-adresskonflikter med health probe.
cluster res <IPResourceName> /priv enabledhcp=0 address=<ILBIP> probeport=59999 subnetmask=255.255.255.255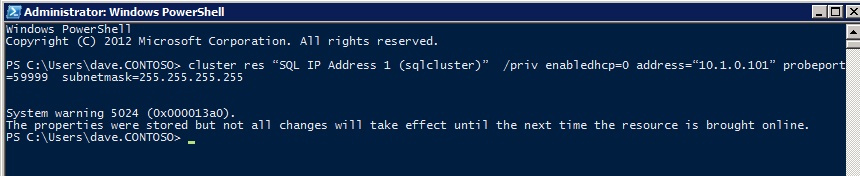
OBS – Jag vet inte om det är en fluke, men ibland har jag kört det här kommandot och det ser ut som det körs, men det Slutför inte jobbet och jag måste köra det igen. Det sätt jag kan berätta om det fungerade är genom att titta på subnätmasken i SQL Server IP-resursen, om den inte är 255.255.255.255 då vet du att den inte kördes framgångsrikt. Det kan enkelt vara ett GUI-uppdateringsproblem, så du kan också försöka starta om cluster GUI för att verifiera att subnätmasken uppdaterades.
när den körs framgångsrikt, ta resursen offline och ta tillbaka den online för att ändringarna ska träda i kraft.
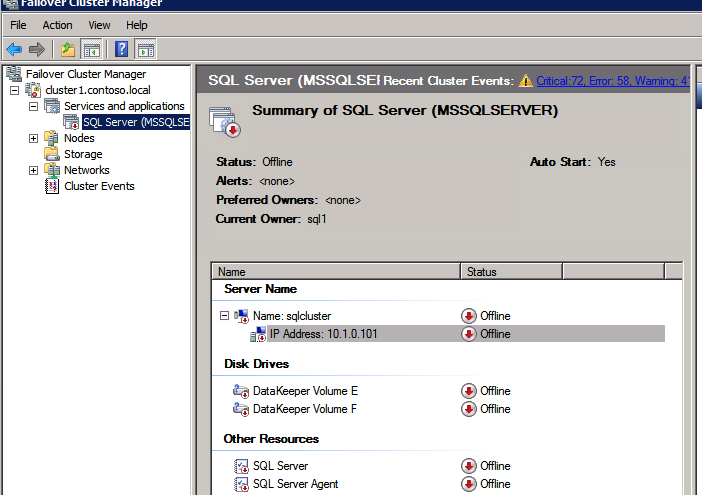
skapa Lastbalanseraren
det sista steget är att skapa lastbalanseraren. I det här fallet antar vi att du kör STANDARDINSTANSEN av SQL Server och lyssnar på port 1433.
den privata IP-adressen du definierar när du skapar lastbalansern kommer att vara exakt samma adress som din SQL Server FCI använder.
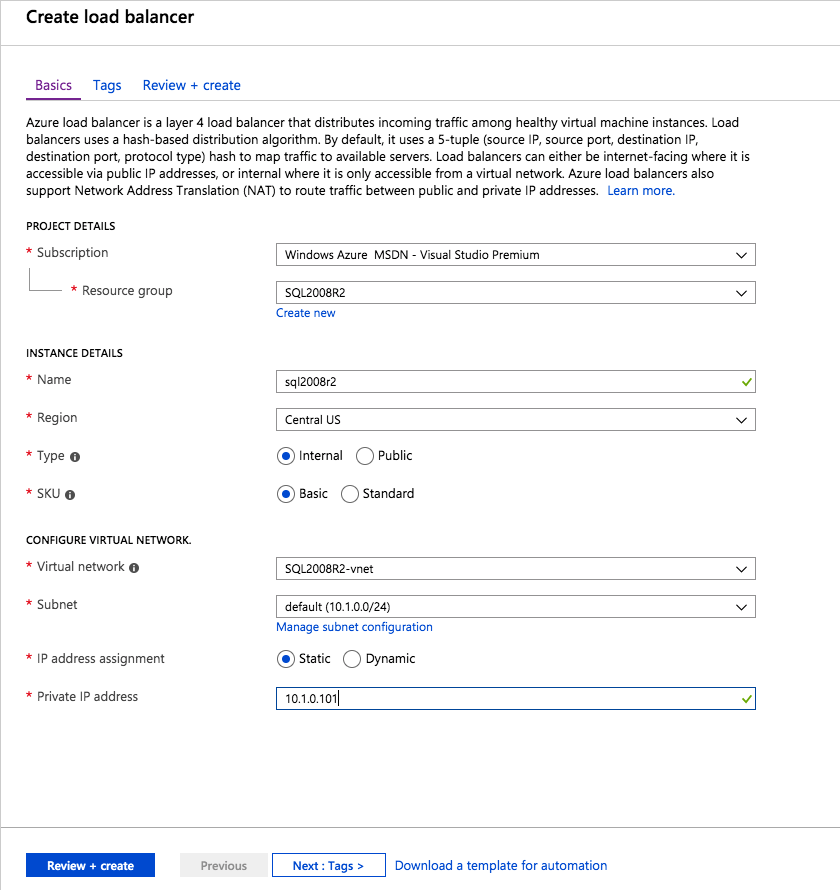
lägg bara till de två SQL Server-instanserna i backend-poolen. Lägg inte till FSW i backend-poolen.
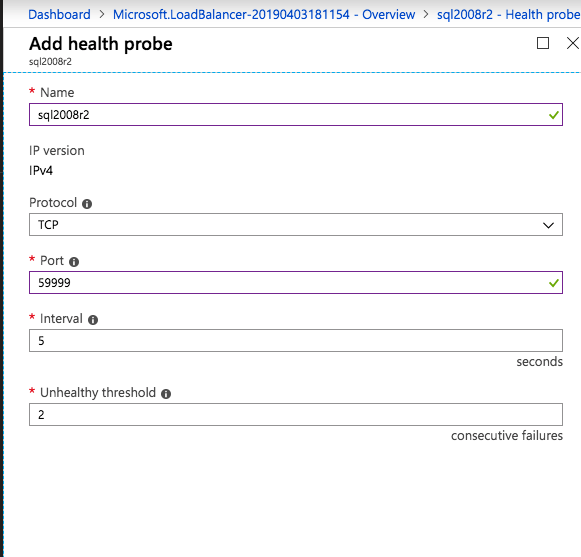
i denna lastbalanseringsregel måste du aktivera flytande IP
validera klustret
innan du fortsätter, kör klustervalidering en gång till. Klustervalideringsrapporten ska returnera samma nätverks-och lagringsvarningar som den gjorde första gången du körde den. Förutsatt att det inte finns några nya fel eller varningar är ditt kluster korrekt konfigurerat.
redigera sqlserv.Exe konfigurationsfil
i katalogen C:\Program filer (x86)\Microsoft SQL Server\100\Tools \ Binn vi skapade en sqlps.exe.konfigurationsfil och sqlservr.exe.config med följande rader i konfigurationsfilen:
<configuration> <startup> <supportedRuntime version="v2.0.50727"/> </startup></configuration>dessa filer kommer som standard inte att existera och kan skapas. Om den här filen(er) redan finns för din installation, måste< supportedRuntime version=”v2.0.50727″/>raden helt enkelt placeras med<startup>…</startup >underavsnitt i<konfiguration>…</konfiguration > avsnitt. Detta bör göras på båda servrarna.
testa klustret
det enklaste testet är att öppna SQL Server Management Studio på den passiva noden och ansluta till klustret. Om du har möjlighet att ansluta, grattis, du gjorde allt rätt! Om du inte kan ansluta var inte rädd, du skulle inte vara den första personen som gjorde ett misstag. Jag skrev en bloggartikel för att felsöka problemet. Att hantera klustret är exakt detsamma som att hantera ett traditionellt delat lagringskluster. Allt styrs genom failover Cluster Manager.
valfritt – flytta Tempdb
för optimal prestanda är det lämpligt att flytta tempdb till den lokala, icke-replikerade SSD. SQL Server 2008 R2 kräver dock att tempdb finns på en klustrad disk. SIOS har en lösning som kallas en icke-speglad Volymresurs som löser problemet. Det skulle vara tillrådligt att skapa en icke-speglad volymresurs på den lokala SSD-enheten och flytta tempdb dit. Den lokala SSD-enheten är dock inte beständig, så du måste se till att mappen som håller tempdb och behörigheterna på den mappen återskapas varje gång servern startar om.