Web crawling com Python

o rastreamento na Web é uma técnica poderosa para coletar dados da web, encontrando todos os URLs para um ou vários domínios. Python tem várias bibliotecas e estruturas populares de rastreamento da web.
neste artigo, primeiro introduziremos diferentes estratégias de rastreamento e casos de uso. Em seguida, construiremos um rastreador da web simples do zero em Python usando duas bibliotecas: requests e Beautiful Soup. Em seguida, veremos por que é melhor usar uma estrutura de rastreamento da web como o Scrapy. Finalmente, vamos construir um rastreador de exemplo com Scrapy para coletar metadados de filmes do IMDb e ver como o Scrapy escala para sites com vários milhões de páginas.
o que é um rastreador da web?
web crawling e web scraping são dois conceitos diferentes, mas relacionados. O rastreamento da Web é um componente da raspagem da web, a lógica do rastreador encontra URLs a serem processados pelo código do raspador.
um rastreador da web começa com uma lista de URLs a serem visitadas, chamada seed. Para cada URL, o rastreador encontra links no HTML, filtra esses links com base em alguns critérios e adiciona os novos links a uma fila. Todo o HTML ou algumas informações específicas são extraídas para serem processadas por um pipeline diferente.
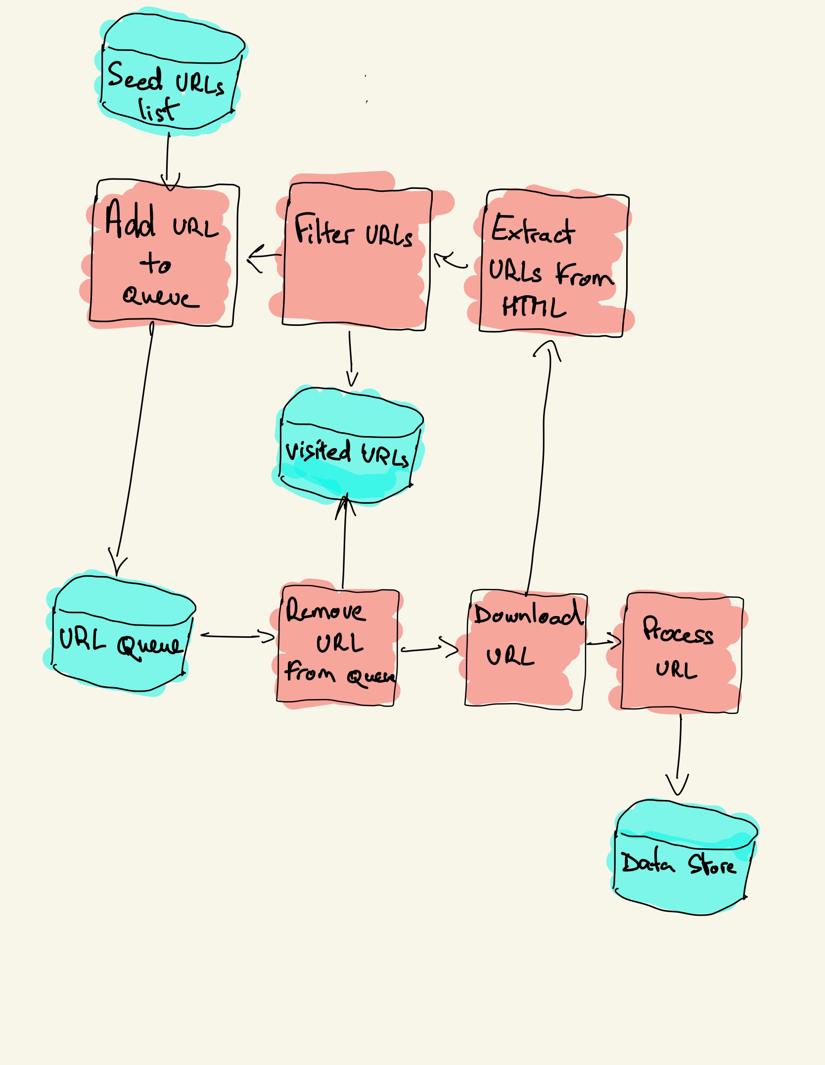
na prática, os rastreadores da web visitam apenas um subconjunto de páginas, dependendo do orçamento do rastreador, que pode ser um número máximo de páginas por domínio, profundidade ou tempo de execução.
os sites mais populares fornecem robôs.arquivo txt para indicar quais áreas do site não podem ser rastreadas por cada agente do Usuário. O oposto do arquivo robots é o mapa do site.arquivo xml, que lista as páginas que podem ser rastreadas.
os casos de uso populares do web crawler incluem:
- os mecanismos de pesquisa (Googlebot, bingbot, Yandex Bot…) coletam todo o HTML para uma parte significativa da Web. Esses dados são indexados para torná-los pesquisáveis.
- ferramentas de análise de SEO além de coletar o HTML também coletam metadados como o tempo de resposta, o status de resposta para detectar páginas quebradas e os links entre diferentes domínios para coletar backlinks.
- Ferramentas de monitoramento de preços rastreiam sites de comércio eletrônico para encontrar páginas de produtos e extrair metadados, principalmente o preço. As páginas do produto são então revisitadas periodicamente.
- Common Crawl mantém um Repositório Aberto de dados de rastreamento da web. Por exemplo, o arquivo de outubro de 2020 contém 2,71 bilhões de páginas da web.
em seguida, compararemos três estratégias diferentes para construir um rastreador da web em Python. Primeiro, usando apenas bibliotecas padrão, depois bibliotecas de terceiros para fazer solicitações HTTP e analisar HTML e, finalmente, uma estrutura de rastreamento da web.
construindo um rastreador da web simples em Python do zero
para construir um rastreador da web simples em Python, precisamos de pelo menos uma biblioteca para baixar o HTML de um URL e uma biblioteca de análise de HTML para extrair links. Python fornece bibliotecas padrão urllib para fazer solicitações HTTP e html.analisador para analisar HTML. Um exemplo de rastreador Python construído apenas com bibliotecas padrão pode ser encontrado no Github.
as bibliotecas Python padrão para solicitações e análise de HTML não são muito amigáveis ao Desenvolvedor. Outras bibliotecas populares, como solicitações, marcadas como HTTP para humanos e Beautiful Soup, oferecem uma melhor experiência de desenvolvedor.
se você quiser saber mais, você pode verificar este guia sobre o melhor cliente HTTP Python.
você pode instalar as duas bibliotecas localmente.
pip install requests bs4um rastreador básico pode ser construído seguindo o diagrama de arquitetura anterior.
import loggingfrom urllib.parse import urljoinimport requestsfrom bs4 import BeautifulSouplogging.basicConfig( format='%(asctime)s %(levelname)s:%(message)s', level=logging.INFO)class Crawler: def __init__(self, urls=): self.visited_urls = self.urls_to_visit = urls def download_url(self, url): return requests.get(url).text def get_linked_urls(self, url, html): soup = BeautifulSoup(html, 'html.parser') for link in soup.find_all('a'): path = link.get('href') if path and path.startswith('/'): path = urljoin(url, path) yield path def add_url_to_visit(self, url): if url not in self.visited_urls and url not in self.urls_to_visit: self.urls_to_visit.append(url) def crawl(self, url): html = self.download_url(url) for url in self.get_linked_urls(url, html): self.add_url_to_visit(url) def run(self): while self.urls_to_visit: url = self.urls_to_visit.pop(0) logging.info(f'Crawling: {url}') try: self.crawl(url) except Exception: logging.exception(f'Failed to crawl: {url}') finally: self.visited_urls.append(url)if __name__ == '__main__': Crawler(urls=).run()o código acima define uma classe de rastreador com métodos auxiliares para download_url usando a biblioteca de solicitações, get_linked_urls usando a bela biblioteca Soup e add_url_to_visit para filtrar URLs. Os URLs a visitar e os URLs visitados são armazenados em duas listas separadas. Você pode executar o rastreador em seu terminal.
python crawler.pyo rastreador registra uma linha para cada URL visitado.
2020-12-04 18:10:10,737 INFO:Crawling: https://www.imdb.com/2020-12-04 18:10:11,599 INFO:Crawling: https://www.imdb.com/?ref_=nv_home2020-12-04 18:10:12,868 INFO:Crawling: https://www.imdb.com/calendar/?ref_=nv_mv_cal2020-12-04 18:10:13,526 INFO:Crawling: https://www.imdb.com/list/ls016522954/?ref_=nv_tvv_dvd2020-12-04 18:10:19,174 INFO:Crawling: https://www.imdb.com/chart/top/?ref_=nv_mv_2502020-12-04 18:10:20,624 INFO:Crawling: https://www.imdb.com/chart/moviemeter/?ref_=nv_mv_mpm2020-12-04 18:10:21,556 INFO:Crawling: https://www.imdb.com/feature/genre/?ref_=nv_ch_gro código é muito simples, mas há muitos problemas de desempenho e usabilidade para resolver antes de rastrear com sucesso um site completo.
- o rastreador é lento e não suporta paralelismo. Como pode ser visto nos carimbos de data / hora, leva cerca de um segundo para rastrear cada URL. Cada vez que o rastreador faz uma solicitação, ele espera que a solicitação seja resolvida e nenhum trabalho é feito no meio.
- a lógica de URL de download não tem mecanismo de repetição, a fila de URL não é uma fila real e não é muito eficiente com um grande número de URLs.
- a lógica de extração de link não suporta a padronização de URLs removendo parâmetros de string de consulta de URL, não lida com URLs começando com#, não suporta filtragem de URLs por domínio ou filtragem de solicitações para arquivos estáticos.
- o rastreador não se identifica e ignora os robôs.arquivo txt.
em seguida, veremos como o Scrapy fornece todas essas funcionalidades e facilita a extensão de seus rastreamentos personalizados.
web rastejando com Scrapy
Scrapy é a estrutura Python de raspagem e rastreamento da web mais popular com 40k estrelas no Github. Uma das vantagens do Scrapy é que as solicitações são agendadas e tratadas de forma assíncrona. Isso significa que o Scrapy pode enviar outra solicitação antes que a anterior seja concluída ou faça algum outro trabalho intermediário. O Scrapy pode lidar com muitas solicitações simultâneas, mas também pode ser configurado para respeitar os sites com configurações personalizadas, como veremos mais adiante.
Scrapy tem uma arquitetura multi-componente. Normalmente, você implementará pelo menos duas classes diferentes: Spider e Pipeline. A raspagem da Web pode ser considerada como um ETL onde você extrai dados da web e os carrega em seu próprio armazenamento. Spiders extrair os dados e pipelines carregá-lo para o armazenamento. A transformação pode acontecer tanto em spiders quanto em pipelines, mas recomendo que você defina um pipeline Scrapy personalizado para transformar cada item independentemente um do outro. Dessa forma, não processar um item não tem efeito sobre outros itens.
além de tudo isso, você pode adicionar middlewares spider e downloader entre os componentes, como pode ser visto no diagrama abaixo.
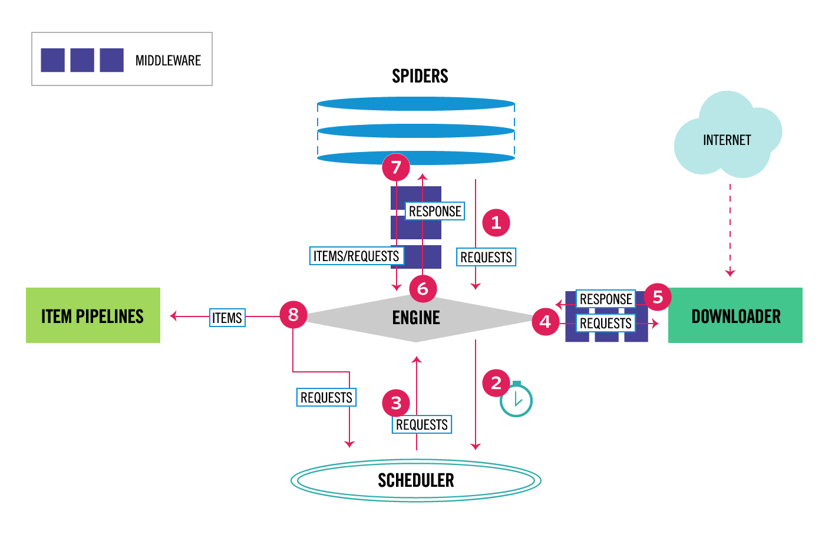
Visão Geral da arquitetura Scrapy
se você já usou o Scrapy antes, sabe que um raspador de web é definido como uma classe que herda da classe base Spider e implementa um método de análise para lidar com cada resposta. Se você é novo no Scrapy, pode ler este artigo para facilitar a raspagem com o Scrapy.
from scrapy.spiders import Spiderclass ImdbSpider(Spider): name = 'imdb' allowed_domains = start_urls = def parse(self, response): passScrapy também fornece vários genérico aranha classes: CrawlSpider, XMLFeedSpider, CSVFeedSpider e SitemapSpider. A classe CrawlSpider herda da classe base Spider e fornece um atributo de regras extra para definir como rastrear um site. Cada regra usa um LinkExtractor para especificar quais links são extraídos de cada página. Em seguida, veremos como usar cada um deles construindo um rastreador para IMDb, o banco de dados de filmes da Internet.
construindo um exemplo de rastreador Scrapy para IMDb
Antes de tentar rastrear IMDb, verifiquei os robôs IMDb.arquivo txt para ver quais caminhos de URL são permitidos. O arquivo robots só desativa 26 caminhos para todos os user-agents. Scrapy lê os robôs.arquivo TXT de antemão e o respeita quando a configuração ROBOTSTXT_OBEY é definida como true. Este é o caso de todos os projetos gerados com o comando Scrapy startproject.
scrapy startproject scrapy_crawlereste comando cria um novo projeto com a estrutura de pastas padrão do projeto Scrapy.
scrapy_crawler/├── scrapy.cfg└── scrapy_crawler ├── __init__.py ├── items.py ├── middlewares.py ├── pipelines.py ├── settings.py └── spiders ├── __init__.pyentão você pode criar uma aranha em scrapy_crawler/spiders/imdb.py com uma regra para extrair todos os links.
from scrapy.spiders import CrawlSpider, Rulefrom scrapy.linkextractors import LinkExtractorclass ImdbCrawler(CrawlSpider): name = 'imdb' allowed_domains = start_urls = rules = (Rule(LinkExtractor()),)Você pode iniciar o rastreador no terminal.
scrapy crawl imdb --logfile imdb.logvocê receberá muitos logs, incluindo um log para cada solicitação. Explorando os logs notei que, se podemos definir allowed_domains para rastrear somente páginas da web em https://www.imdb.com, houve pedidos para domínios externos, tais como amazon.com.
2020-12-06 12:25:18 DEBUG: Redirecting (302) to <GET https://www.amazon.com/b/?&node=5160028011&ref_=ft_iba> from <GET (https://www.imdb.com/whitelist-offsite?url=https%3A%2F%2Fwww.amazon.com%2Fb%2F%3F%26node%3D5160028011%26ref_%3Dft_iba&page-action=ft-iba&ref=ft_iba)>IMDb redirecionamentos de URLs caminhos em lista branca-fora e branca para domínios externos. Há um problema do GitHub Scrapy aberto que mostra que URLs externos não são filtrados quando o OffsiteMiddleware é aplicado antes do RedirectMiddleware. Para corrigir esse problema, podemos configurar o extrator de links para negar URLs começando com duas expressões regulares.
class ImdbCrawler(CrawlSpider): name = 'imdb' allowed_domains = start_urls = rules = ( Rule(LinkExtractor( deny=, )), )as classes Rule e LinkExtractor suportam vários argumentos para filtrar URLs. Por exemplo, você pode ignorar extensões de URL específicas e reduzir o número de URLs duplicados classificando strings de consulta. Se você não encontrar um argumento específico para o seu caso de Uso, poderá passar uma função personalizada para process_links em LinkExtractor ou process_values na regra.
por exemplo, o IMDb tem dois URLs diferentes com o mesmo conteúdo.
https://www.imdb.com/nome/nm1156914/
https://www.imdb.com/nome/nm1156914/?mode = desktop& ref_=m_ft_dsk
para limitar o número de URLs rastreados, podemos remover todas as strings de consulta de URLs com a função url_query_cleaner da biblioteca w3lib e usá-la em process_links.
from w3lib.url import url_query_cleanerdef process_links(links): for link in links: link.url = url_query_cleaner(link.url) yield linkclass ImdbCrawler(CrawlSpider): name = 'imdb' allowed_domains = start_urls = rules = ( Rule(LinkExtractor( deny=, ), process_links=process_links), )Agora que temos limitado o número de solicitações ao processo, podemos adicionar um parse_item método para extrair dados a partir de cada página e passá-lo para um pipeline para armazená-lo. Por exemplo, podemos extrair toda a resposta.texto para processá-lo em um pipeline diferente ou selecione os metadados HTML. Para selecionar os metadados HTML na tag de cabeçalho, podemos codificar nossos próprios XPATHs, mas acho melhor usar uma biblioteca, extruct, que extrai todos os metadados de uma página HTML. Você pode instalá-lo com pip install extract.
import refrom scrapy.linkextractors import LinkExtractorfrom scrapy.spiders import CrawlSpider, Rulefrom w3lib.url import url_query_cleanerimport extructdef process_links(links): for link in links: link.url = url_query_cleaner(link.url) yield linkclass ImdbCrawler(CrawlSpider): name = 'imdb' allowed_domains = start_urls = rules = ( Rule( LinkExtractor( deny=, ), process_links=process_links, callback='parse_item', follow=True ), ) def parse_item(self, response): return { 'url': response.url, 'metadata': extruct.extract( response.text, response.url, syntaxes= ), }eu defino o atributo follow como True para que Scrapy ainda siga todos os links de cada resposta, mesmo que forneçamos um método de análise personalizado. Eu também configurei o extruct para extrair apenas metadados Open Graph e JSON-LD, um método popular para codificar dados vinculados usando JSON na Web, usado pelo IMDb. Você pode executar o rastreador e armazenar itens no formato JSON lines em um arquivo.
scrapy crawl imdb --logfile imdb.log -o imdb.jl -t jsonlinesO arquivo de saída imdb.jl contém uma linha para cada item rastreado. Por exemplo, os metadados de gráfico aberto extraídos para um filme retirado das tags <meta> no HTML são assim.
{ "url": "http://www.imdb.com/title/tt2442560/", "metadata": {"opengraph": , , , , , ] }]}}O JSON-LD para um único item é demasiado longa para ser incluída no artigo, aqui está uma amostra do que Scrapy extratos do <script type=”application/ld+json”> tag.
"json-ld": , "contentRating": "TV-MA", "actor": ... }]explorando os logs, notei outro problema comum com rastreadores. Ao clicar sequencialmente nos filtros, o rastreador gera URLs com o mesmo conteúdo, apenas que os filtros foram aplicados em uma ordem diferente.
https://www.imdb.com/nome/nm2900465/overview/content_type-trailer/related_titles-tt0479468
https://www.imdb.com/nome/nm2900465/overview/related_titles-tt0479468/content_type-reboque
Tempo de filtro e busca de URLs é um problema difícil que pode ser parcialmente resolvido limitando a duração das URLs com um Scrapy definição, URLLENGTH_LIMIT.
usei o IMDb como exemplo para mostrar os fundamentos da construção de um rastreador da web em Python. Não deixei o rastreador funcionar desde que não tivesse um caso de uso específico para os dados. Caso você precise de dados específicos do IMDb, você pode verificar o projeto de Conjuntos de dados do IMDb que fornece uma exportação diária de dados do IMDb e do IMDbPY, um pacote Python para recuperar e gerenciar os dados.
rastreamento na web em escala
se você tentar rastrear um site grande como o IMDb, com mais de 45 milhões de páginas baseadas no Google, é importante rastrear com responsabilidade configurando as seguintes configurações. Você pode identificar seu rastreador e fornecer detalhes de contato na configuração BOT_NAME. Para limitar a pressão que você coloca nos servidores do site, você pode aumentar o DOWNLOAD_DELAY, limitar o CONCURRENT_REQUESTS_PER_DOMAIN ou definir AUTOTHROTTLE_ENABLED que irá adaptar essas configurações dinamicamente com base nos tempos de resposta do servidor.
observe que rastreamentos Scrapy são otimizados para um único domínio por padrão. Se você estiver rastreando vários domínios, verifique essas configurações para otimizar rastreamentos amplos, incluindo a alteração da ordem de rastreamento padrão de profundidade-primeiro a respiração-primeiro. Para limitar seu orçamento de rastreamento, você pode limitar o número de solicitações com a configuração CLOSESPIDER_PAGECOUNT da extensão close spider.
com as configurações padrão, o Scrapy rastreia cerca de 600 páginas por minuto para um site como o IMDb. Para rastrear 45 milhões de páginas, levará mais de 50 dias para um único robô. Se você precisar rastrear vários sites, pode ser melhor lançar rastreadores separados para cada grande site ou grupo de sites. Se você estiver interessado em rastreamentos distribuídos da web, poderá ler como um desenvolvedor rastreou 250 milhões de páginas com Python em 40 horas usando 20 instâncias do Amazon EC2 machine.
em alguns casos, você pode encontrar sites que exigem que você execute o código JavaScript para renderizar todo o HTML. Deixar de fazê-lo, e você não pode coletar todos os links no site. Porque hoje em dia é muito comum que os sites renderizem conteúdo dinamicamente no navegador, escrevi um middleware Scrapy para renderizar páginas JavaScript usando a API do ScrapingBee.
conclusão
comparamos o código de um rastreador Python usando bibliotecas de terceiros para baixar URLs e analisar HTML com um rastreador construído usando uma estrutura popular de rastreamento da web. Scrapy é uma estrutura de rastreamento da web muito eficiente e é fácil de estender com seu código personalizado. Mas você precisa conhecer todos os lugares onde você pode conectar seu próprio código e as configurações para cada componente.
configurar o Scrapy corretamente se torna ainda mais importante ao rastrear sites com milhões de páginas. Se você quiser saber mais sobre o rastreamento na web, sugiro que você escolha um site popular e tente rastreá-lo. Você definitivamente encontrará novos problemas, o que torna o tópico fascinante!