Web crawling with Python

web crawling to potężna technika zbierania danych z sieci poprzez znajdowanie wszystkich adresów URL dla jednej lub wielu domen. Python ma kilka popularnych bibliotek i frameworków do indeksowania stron internetowych.
w tym artykule przedstawimy najpierw różne strategie indeksowania i przypadki użycia. Następnie zbudujemy prosty Web crawler od podstaw w Pythonie przy użyciu dwóch bibliotek: requests i Beautiful Soup. Następnie przekonamy się, dlaczego lepiej jest używać frameworka Web crawlingowego, takiego jak Scrapy. Na koniec zbudujemy przykładowy robot ze Scrapym, aby zebrać metadane filmowe z IMDb i zobaczyć, jak Scrapy skaluje się do witryn z kilkoma milionami stron.
co to jest Web crawler?
web crawling i Web scraping to dwa różne, ale powiązane pojęcia. Indeksowanie sieci jest składnikiem skrobania sieci, logika robota znajduje adresy URL do przetworzenia przez kod skrobaka.
Robot sieciowy zaczyna się od listy adresów URL do odwiedzenia, nazywanej seed. Dla każdego adresu URL Robot wyszukuje łącza w kodzie HTML, filtruje je na podstawie pewnych kryteriów i dodaje nowe łącza do kolejki. Wszystkie HTML lub niektóre konkretne informacje są wyodrębniane w celu przetworzenia przez inny potok.
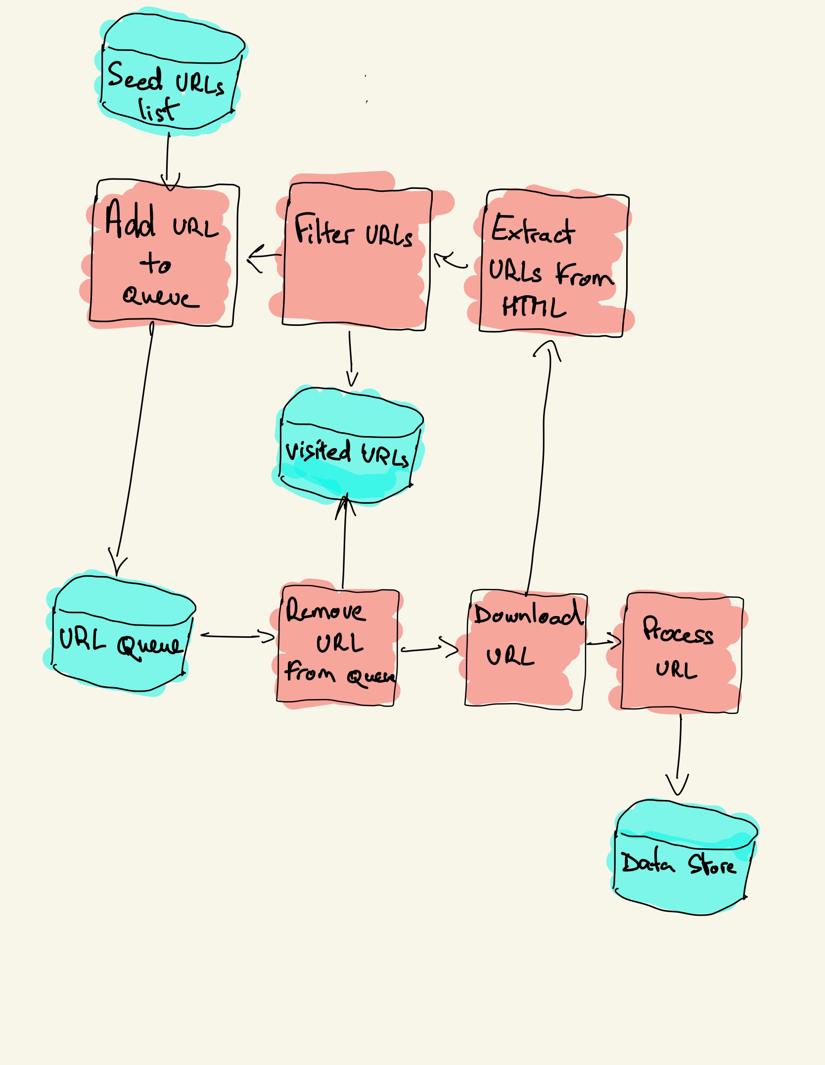
strategie indeksowania
w praktyce roboty indeksujące odwiedzają tylko podzbiór stron w zależności od budżetu robota, który może być maksymalną liczbą stron na domenę, głębokość lub czas wykonania.
najpopularniejsze strony internetowe to robot.plik txt wskazujący, które obszary witryny są niedozwolone do indeksowania przez każdego agenta użytkownika. Przeciwieństwem pliku robotów jest mapa strony.plik xml, który zawiera listę stron, które można przeszukiwać.
popularne przypadki użycia robota sieciowego obejmują:
- Wyszukiwarki (Googlebot, Bingbot, Yandex Bot…) zbierają cały HTML dla znacznej części sieci. Dane te są indeksowane, aby można je było przeszukiwać.
- narzędzia analityczne SEO oprócz zbierania kodu HTML zbierają również metadane, takie jak Czas odpowiedzi, status odpowiedzi w celu wykrycia uszkodzonych stron i linki między różnymi domenami w celu zbierania linków zwrotnych.
- narzędzia do monitorowania cen indeksują witryny e-commerce, aby znaleźć strony produktów i wyodrębnić metadane, w szczególności cenę. Strony produktów są następnie okresowo odwiedzane.
- Common Crawl utrzymuje otwarte repozytorium danych indeksowania sieci. Na przykład archiwum z października 2020 zawiera 2,71 miliarda stron internetowych.
następnie porównamy trzy różne strategie budowania robota internetowego w Pythonie. Po pierwsze, używając tylko bibliotek standardowych, następnie bibliotek stron trzecich do tworzenia żądań HTTP i parsowania HTML, a na koniec, framework do indeksowania stron internetowych.
budowanie prostego robota internetowego w Pythonie od podstaw
aby zbudować prostego robota internetowego w Pythonie, potrzebujemy co najmniej jednej biblioteki do pobrania HTML z adresu URL i biblioteki do parsowania HTML do wyodrębnienia linków. Python dostarcza standardowe biblioteki urllib do tworzenia żądań HTTP i html.parser do parsowania HTML. Przykładowy crawler Pythona zbudowany tylko ze standardowych bibliotek można znaleźć na Githubie.
standardowe biblioteki Pythona dla zapytań i parsowania HTML nie są zbyt przyjazne dla programistów. Inne popularne biblioteki, takie jak requests, oznaczone jako HTTP for humans i Beautiful Soup, zapewniają lepsze wrażenia programistów.
jeśli chcesz dowiedzieć się więcej, możesz sprawdzić ten przewodnik o najlepszym kliencie http Pythona.
możesz zainstalować dwie biblioteki lokalnie.
pip install requests bs4podstawowy Robot gąsienicowy może być zbudowany zgodnie z poprzednim diagramem architektury.
import loggingfrom urllib.parse import urljoinimport requestsfrom bs4 import BeautifulSouplogging.basicConfig( format='%(asctime)s %(levelname)s:%(message)s', level=logging.INFO)class Crawler: def __init__(self, urls=): self.visited_urls = self.urls_to_visit = urls def download_url(self, url): return requests.get(url).text def get_linked_urls(self, url, html): soup = BeautifulSoup(html, 'html.parser') for link in soup.find_all('a'): path = link.get('href') if path and path.startswith('/'): path = urljoin(url, path) yield path def add_url_to_visit(self, url): if url not in self.visited_urls and url not in self.urls_to_visit: self.urls_to_visit.append(url) def crawl(self, url): html = self.download_url(url) for url in self.get_linked_urls(url, html): self.add_url_to_visit(url) def run(self): while self.urls_to_visit: url = self.urls_to_visit.pop(0) logging.info(f'Crawling: {url}') try: self.crawl(url) except Exception: logging.exception(f'Failed to crawl: {url}') finally: self.visited_urls.append(url)if __name__ == '__main__': Crawler(urls=).run()powyższy kod definiuje klasę crawlera z pomocniczymi metodami download_url za pomocą biblioteki zapytań, get_linked_urls za pomocą pięknej Biblioteki zupy i add_url_to_visit do filtrowania adresów URL. Adresy URL do odwiedzenia i odwiedzone adresy URL są przechowywane na dwóch oddzielnych listach. Możesz uruchomić robota na swoim terminalu.
python crawler.pyRobot rejestruje jedną linię dla każdego odwiedzanego adresu URL.
2020-12-04 18:10:10,737 INFO:Crawling: https://www.imdb.com/2020-12-04 18:10:11,599 INFO:Crawling: https://www.imdb.com/?ref_=nv_home2020-12-04 18:10:12,868 INFO:Crawling: https://www.imdb.com/calendar/?ref_=nv_mv_cal2020-12-04 18:10:13,526 INFO:Crawling: https://www.imdb.com/list/ls016522954/?ref_=nv_tvv_dvd2020-12-04 18:10:19,174 INFO:Crawling: https://www.imdb.com/chart/top/?ref_=nv_mv_2502020-12-04 18:10:20,624 INFO:Crawling: https://www.imdb.com/chart/moviemeter/?ref_=nv_mv_mpm2020-12-04 18:10:21,556 INFO:Crawling: https://www.imdb.com/feature/genre/?ref_=nv_ch_grkod jest bardzo prosty, ale istnieje wiele problemów z wydajnością i użytecznością do rozwiązania przed pomyślnym indeksowaniem kompletnej strony internetowej.
- robot jest powolny i nie obsługuje równoległości. Jak widać ze znaczników czasu, przeszukiwanie każdego adresu URL zajmuje około jednej sekundy. Za każdym razem, gdy robot gąsienicowy wyśle żądanie, czeka na jego rozwiązanie i nie wykonuje żadnej pracy pomiędzy nimi.
- logika URL pobierania nie ma mechanizmu ponownej próby, Kolejka URL nie jest prawdziwą kolejką i niezbyt wydajna przy dużej liczbie adresów URL.
- logika ekstrakcji linków nie obsługuje standaryzacji adresów URL poprzez usunięcie parametrów ciągu zapytań URL, nie obsługuje adresów URL zaczynających się od #, nie obsługuje filtrowania adresów URL według domeny ani filtrowania żądań do plików statycznych.
- Robot się nie identyfikuje i ignoruje roboty.plik txt.
następnie zobaczymy, jak Scrapy zapewnia wszystkie te funkcje i ułatwia rozszerzenie niestandardowych indeksów.
web crawling with Scrapy
Scrapy to najpopularniejszy Framework Pythona do scrapowania i indeksowania stron internetowych z gwiazdkami 40K na Githubie. Jedną z zalet Scrapy jest to, że żądania są zaplanowane i obsługiwane asynchronicznie. Oznacza to, że Scrapy może wysłać kolejne żądanie przed zakończeniem poprzedniego lub wykonać inną pracę pomiędzy nimi. Scrapy może obsługiwać wiele jednoczesnych żądań, ale może być również skonfigurowany tak, aby respektować strony internetowe z niestandardowymi ustawieniami, jak zobaczymy później.
Scrapy ma architekturę wieloskładnikową. Zwykle zaimplementujesz co najmniej dwie różne klasy: Spider i Pipeline. Skrobanie sieci można traktować jako ETL, w którym wyodrębnia się dane z sieci i ładuje je do własnej pamięci masowej. Pająki wyodrębniają dane, a rurociągi ładują je do magazynu. Transformacja może się zdarzyć zarówno w pająkach, jak i rurociągach, ale zalecam ustawienie niestandardowego potoku Scrapy, aby przekształcić każdy element niezależnie od siebie. W ten sposób brak przetworzenia elementu nie ma wpływu na inne elementy.
poza tym możesz dodać programy pośredniczące spider i downloader pomiędzy komponentami, jak widać na poniższym diagramie.
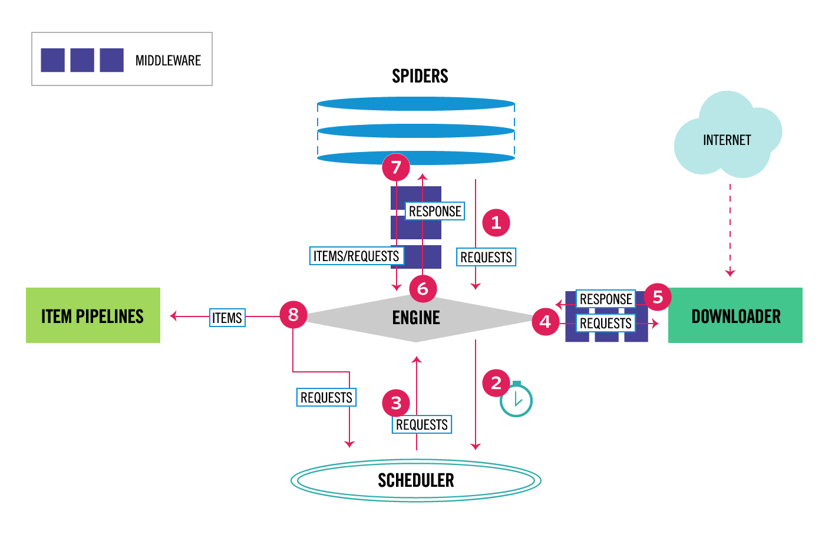
przegląd architektury Scrapy
jeśli wcześniej używałeś Scrapy ’ ego, wiesz, że skrobak sieciowy jest zdefiniowany jako klasa, która dziedziczy z podstawowej klasy pająka i implementuje metodę parse do obsługi każdej odpowiedzi. Jeśli jesteś nowy w Scrapy, możesz przeczytać ten artykuł, aby ułatwić skrobanie za pomocą Scrapy.
from scrapy.spiders import Spiderclass ImdbSpider(Spider): name = 'imdb' allowed_domains = start_urls = def parse(self, response): passScrapy udostępnia również kilka ogólnych klas pająków: CrawlSpider, XMLFeedSpider, CSVFeedSpider i SitemapSpider. Klasa CrawlSpider dziedziczy z podstawowej klasy pająka i zapewnia dodatkowy atrybut reguł określający sposób indeksowania witryny. Każda reguła używa LinkExtractor, aby określić, które linki są wyodrębniane z każdej strony. Następnie zobaczymy, jak korzystać z każdego z nich, budując crawler dla IMDb, Internet Movie Database.
budowanie przykład Scrapy crawler dla IMDb
przed próbą indeksowania IMDb, sprawdziłem roboty IMDb.plik txt, aby zobaczyć, które ścieżki URL są dozwolone. Plik robots wyłącza tylko 26 ścieżek dla wszystkich użytkowników. Scrapy czyta roboty.plik txt i respektuje go, gdy ustawienie ROBOTSTXT_OBEY jest ustawione na true. Dotyczy to wszystkich projektów generowanych za pomocą polecenia Scrapy startproject.
scrapy startproject scrapy_crawlerto polecenie tworzy nowy projekt z domyślną strukturą folderów projektu Scrapy.
scrapy_crawler/├── scrapy.cfg└── scrapy_crawler ├── __init__.py ├── items.py ├── middlewares.py ├── pipelines.py ├── settings.py └── spiders ├── __init__.pywtedy możesz stworzyć pająka w scrapy_crawler/spiders/imdb.py z regułą, aby wyodrębnić wszystkie linki.
from scrapy.spiders import CrawlSpider, Rulefrom scrapy.linkextractors import LinkExtractorclass ImdbCrawler(CrawlSpider): name = 'imdb' allowed_domains = start_urls = rules = (Rule(LinkExtractor()),)możesz uruchomić robota w terminalu.
scrapy crawl imdb --logfile imdb.logotrzymasz wiele dzienników, w tym jeden dziennik dla każdego żądania. Przeglądając logi zauważyłem, że nawet jeśli ustawimy allowed_domains tylko do indeksowania stron internetowych pod https://www.imdb.com, były żądania do zewnętrznych domen, takich jak amazon.com.
2020-12-06 12:25:18 DEBUG: Redirecting (302) to <GET https://www.amazon.com/b/?&node=5160028011&ref_=ft_iba> from <GET (https://www.imdb.com/whitelist-offsite?url=https%3A%2F%2Fwww.amazon.com%2Fb%2F%3F%26node%3D5160028011%26ref_%3Dft_iba&page-action=ft-iba&ref=ft_iba)>IMDb przekierowuje ze ścieżek URL pod whitelist-offsite i whitelist do domen zewnętrznych. Istnieje otwarty problem Scrapy Github, który pokazuje, że zewnętrzne adresy URL nie są filtrowane, gdy OffsiteMiddleware jest stosowane przed RedirectMiddleware. Aby rozwiązać ten problem, możemy skonfigurować ekstraktor linków tak, aby odmawiał adresów URL zaczynających się od dwóch wyrażeń regularnych.
class ImdbCrawler(CrawlSpider): name = 'imdb' allowed_domains = start_urls = rules = ( Rule(LinkExtractor( deny=, )), )klasy Rule i LinkExtractor obsługują kilka argumentów do filtrowania adresów URL. Na przykład można ignorować określone rozszerzenia adresów URL i zmniejszać liczbę zduplikowanych adresów URL, sortując ciągi zapytań. Jeśli nie znajdziesz konkretnego argumentu dla swojego przypadku użycia, możesz przekazać niestandardową funkcję do process_links w LinkExtractor lub process_values w Rule.
na przykład IMDb ma dwa różne adresy URL o tej samej treści.
https://www.imdb.com/nazwa / nm1156914/
https://www.imdb.com/nazwa / nm1156914/?mode=desktop&ref_ = m_ft_dsk
aby ograniczyć liczbę przeszukiwanych adresów URL, możemy usunąć wszystkie ciągi zapytań z adresów URL za pomocą funkcji url_query_cleaner z biblioteki w3lib i użyć jej w linkach process_links.
from w3lib.url import url_query_cleanerdef process_links(links): for link in links: link.url = url_query_cleaner(link.url) yield linkclass ImdbCrawler(CrawlSpider): name = 'imdb' allowed_domains = start_urls = rules = ( Rule(LinkExtractor( deny=, ), process_links=process_links), )teraz, gdy ograniczyliśmy liczbę żądań do przetworzenia, możemy dodać metodę parse_item, aby wyodrębnić dane z każdej strony i przekazać je do potoku, aby je przechowywać. Na przykład, możemy wyodrębnić całą odpowiedź.tekst, aby przetworzyć go w innym potoku lub wybrać metadane HTML. Aby wybrać metadane HTML w znaczniku nagłówka, możemy kodować własne ścieżki XPATHs, ale uważam, że lepiej jest użyć biblioteki exruct, która wyodrębnia wszystkie metadane ze strony HTML. Możesz go zainstalować za pomocą pip install extract.
import refrom scrapy.linkextractors import LinkExtractorfrom scrapy.spiders import CrawlSpider, Rulefrom w3lib.url import url_query_cleanerimport extructdef process_links(links): for link in links: link.url = url_query_cleaner(link.url) yield linkclass ImdbCrawler(CrawlSpider): name = 'imdb' allowed_domains = start_urls = rules = ( Rule( LinkExtractor( deny=, ), process_links=process_links, callback='parse_item', follow=True ), ) def parse_item(self, response): return { 'url': response.url, 'metadata': extruct.extract( response.text, response.url, syntaxes= ), }ustawiłem atrybut follow Na True, aby Scrapy nadal podążał za wszystkimi linkami z każdej odpowiedzi, nawet jeśli podaliśmy niestandardową metodę parse. Skonfigurowałem również exstruct, aby wyodrębnić tylko otwarte metadane grafu i JSON-LD, popularną metodę kodowania połączonych danych za pomocą JSON w Internecie, używaną przez IMDb. Możesz uruchomić robot i przechowywać elementy w formacie linii JSON do pliku.
scrapy crawl imdb --logfile imdb.log -o imdb.jl -t jsonlinesplik wyjściowy imdb.jl zawiera jedną linię dla każdego zindeksowanego elementu. Na przykład wyodrębnione metadane otwartego wykresu dla filmu pobranego ze znaczników <meta> w HTML wyglądają następująco.
{ "url": "http://www.imdb.com/title/tt2442560/", "metadata": {"opengraph": , , , , , ] }]}}JSON-LD dla pojedynczego elementu jest zbyt długi, aby mógł zostać uwzględniony w artykule, oto próbka tego, co Scrapy wyciąga ze znacznika <script type=”application/LD+json”>.
"json-ld": , "contentRating": "TV-MA", "actor": ... }]badając dzienniki, zauważyłem inny wspólny problem z gąsienicami. Klikając kolejno filtry, Robot generuje adresy URL o tej samej zawartości, tyle że filtry zostały zastosowane w innej kolejności.
https://www.imdb.com/nazwa / nm2900465 / videogaleria / content_type-trailer / related_titles-tt0479468
https://www.imdb.com/name/nm2900465/videogallery/related_titles-tt0479468 / content_type-trailer
długi filtr i wyszukiwane adresy URL to trudny problem, który można częściowo rozwiązać, ograniczając długość adresów URL za pomocą Ustawienia Scrapy, URLLENGTH_LIMIT.
użyłem IMDb jako przykład, aby pokazać podstawy budowania robota internetowego w Pythonie. Nie pozwoliłem, aby robot działał długo, ponieważ nie miałem konkretnego przypadku użycia danych. Jeśli potrzebujesz konkretnych danych z IMDb, możesz sprawdzić projekt IMDb Datasets, który zapewnia codzienny eksport danych IMDb i imdbpy, pakiet Pythona do pobierania i zarządzania danymi.
indeksowanie stron w skali
jeśli próbujesz indeksować dużą stronę internetową, taką jak IMDb, z ponad 45 milionami stron opartych na Google, ważne jest, aby indeksować odpowiedzialnie, konfigurując następujące ustawienia. Możesz zidentyfikować swojego robota i podać dane kontaktowe w ustawieniu BOT_NAME. Aby ograniczyć presję, jaką wywierasz na serwery witryny, możesz zwiększyć DOWNLOAD_DELAY, ograniczyć CONCURRENT_REQUESTS_PER_DOMAIN lub ustawić AUTOTHROTTLE_ENABLED, który dostosuje te ustawienia dynamicznie w oparciu o czasy odpowiedzi z serwera.
zauważ, że Scrapy crawle są domyślnie zoptymalizowane dla pojedynczej domeny. Jeśli indeksujesz wiele domen, sprawdź te ustawienia, aby zoptymalizować pod kątem szerokich indeksów, w tym zmienić domyślną kolejność indeksowania z głębi na oddech. Aby ograniczyć budżet indeksowania, możesz ograniczyć liczbę żądań za pomocą ustawienia CLOSESPIDER_PAGECOUNT rozszerzenia close spider.
dzięki domyślnym ustawieniom Scrapy indeksuje około 600 stron na minutę dla witryny takiej jak IMDb. Przeszukiwanie 45M stron zajmie więcej niż 50 dni dla pojedynczego robota. Jeśli potrzebujesz przeszukiwać wiele stron internetowych, lepiej uruchomić oddzielne roboty dla każdej dużej witryny lub grupy stron internetowych. Jeśli jesteś zainteresowany rozproszonymi indeksami sieciowymi, możesz przeczytać, jak programista przeszukiwał 250 mln stron za pomocą Pythona w 40 godzin przy użyciu 20 instancji Maszyny Amazon EC2.
w niektórych przypadkach możesz uruchomić strony internetowe, które wymagają wykonania kodu JavaScript, aby renderować cały kod HTML. Nie uda się tego zrobić, a użytkownik nie może zbierać wszystkich linków na stronie internetowej. Ponieważ w dzisiejszych czasach bardzo często strony internetowe renderują zawartość dynamicznie w przeglądarce, napisałem Scrapowe oprogramowanie pośredniczące do renderowania stron JavaScript za pomocą API ScrapingBee.
podsumowanie
porównaliśmy kod robota w Pythonie przy użyciu bibliotek innych firm do pobierania adresów URL i parsowania HTML z robotem gąsienicowym zbudowanym przy użyciu popularnego frameworka do indeksowania stron internetowych. Scrapy jest bardzo wydajnym frameworkiem do indeksowania stron internetowych i można go łatwo rozszerzyć za pomocą niestandardowego kodu. Ale musisz znać wszystkie miejsca, w których możesz zaczepić swój własny kod i ustawienia dla każdego komponentu.
prawidłowe Konfigurowanie Scrapy staje się jeszcze ważniejsze podczas indeksowania stron z milionami stron. Jeśli chcesz dowiedzieć się więcej o indeksowaniu stron internetowych, sugeruję, abyś wybrał popularną stronę i spróbował ją indeksować. Na pewno napotkasz nowe problemy, co sprawia, że temat jest fascynujący!