Log4j Tutorial: Jak skonfigurować rejestrator do efektywnego logowania aplikacji Java
uzyskanie wglądu w aplikację jest kluczowe podczas uruchamiania kodu w produkcji. Co rozumiemy przez widoczność? Przede wszystkim takie rzeczy, jak wydajność aplikacji za pomocą wskaźników, kondycja aplikacji i dostępność, jej dzienniki powinny być rozwiązywane, lub jej ślady, jeśli chcesz dowiedzieć się, co sprawia, że jest powolny i jak go przyspieszyć.
metryki dostarczają informacji o wydajności każdego z elementów infrastruktury. Śledzenie pokaże szerszy widok wykonania i przepływu kodu wraz z metrykami wykonania kodu. Wreszcie, dobrze wykonane dzienniki zapewnią nieoceniony wgląd w wykonanie logiki kodu i to, co działo się w kodzie. Każdy z wymienionych elementów ma kluczowe znaczenie dla Twojej aplikacji, a nawet ogólnej widoczności systemu. Dziś skupimy się tylko na jednym kawałku – logach. Dokładniej – na logach aplikacji Java. Jeśli interesuje Cię metryka, zapoznaj się z naszym artykułem na temat kluczowych metryk JVM, które powinieneś monitorować.
jednak zanim przejdziemy do tego, zajmijmy się problemem, który wpłynął na społeczność używającą tego frameworka. 9 grudnia 2021 r. zgłoszono krytyczną lukę o nazwie Log4Shell. Zidentyfikowany jako CVE-2021-44228, pozwala atakującemu przejąć pełną kontrolę nad maszyną z Apache Log4j 2 w wersji 2.14.1 lub niższej, umożliwiając im wykonanie dowolnego kodu na podatnym serwerze. W naszym ostatnim poście na blogu dotyczącym luki w zabezpieczeniach Log4jShell opisaliśmy, jak określić, czy problem dotyczy Użytkownika, jak rozwiązać ten problem i co w Sematext zrobiliśmy, aby chronić nasz system i użytkowników.
Log4j 1.x koniec życia
należy pamiętać, że 5 sierpnia 2015 roku komitet zarządzający projektem Logging Services ogłosił, że Log4j 1.x osiągnął swój koniec życia. Wszystkim użytkownikom zaleca się migrację do Log4j 2.x. w tym poście na blogu pomożemy Ci zrozumieć aktualną konfigurację Log4j-w szczególności log4j 2.wersja x-a potem pomogę ci w migracji do najnowszej i najlepszej wersji Log4j.
” używam Log4j 1.x, co mam zrobić?”. Nie panikuj, nie ma w tym nic złego. Stwórz plan przejścia na Log4j 2.x. pokażę Ci jak po prostu czytaj dalej:). Twoja aplikacja będzie Ci za to wdzięczna. Otrzymasz poprawki zabezpieczeń, ulepszenia wydajności i znacznie więcej funkcji po migracji.
” zaczynam nowy projekt, co powinienem zrobić?”. Wystarczy użyć Log4j 2.x od razu, nawet nie myśl o Log4j 1.x. Jeśli potrzebujesz pomocy, sprawdź ten poradnik logowania Java, w którym wyjaśnię wszystko, czego potrzebujesz.
Logowanie do Javy
logowanie do Javy nie jest magiczne. Wszystko sprowadza się do użycia odpowiedniej klasy Java i jej metod do generowania zdarzeń dziennika. Jak omówiliśmy w Java logging guide istnieje wiele sposobów, aby rozpocząć
oczywiście, najbardziej naiwny i nie najlepsza ścieżka do naśladowania jest po prostu za pomocą systemu.out and System.klasy err. Tak, możesz to zrobić, a Twoje wiadomości po prostu trafią do standardowego wyjścia i standardowego błędu. Zazwyczaj oznacza to, że zostanie wydrukowany na konsoli lub zapisany do jakiegoś pliku lub nawet wysłany do /dev/null i na zawsze zostanie zapomniany. Przykład takiego kodu może wyglądać następująco:
public class SystemExample { public static void main(String args) { System.out.println("Starting my awesome application"); // some work to be done System.out.println( String.format("My application %s started successfully", SystemExample.class) ); }}
wynik powyższego wykonania kodu będzie następujący:
Starting my awesome applicationMy application class com.sematext.logging.log4jsystem.SystemExample started successfully
to nie jest idealne, prawda? Nie mam żadnych informacji o tym, która klasa wygenerowała wiadomość i wiele, wiele więcej „małych” rzeczy, które są kluczowe i ważne podczas debugowania.
brakuje innych rzeczy, które nie są tak naprawdę związane z debugowaniem. Pomyśl o środowisku wykonywania, wielu aplikacjach lub mikroserwisach oraz o potrzebie ujednolicenia rejestrowania, aby uprościć konfigurację potoku centralizacji logów. Korzystanie z systemu.out, or / And System.błąd w naszym kodzie do celów logowania zmusiłby nas do powtórzenia wszystkich miejsc, w których go używamy, gdy potrzebujemy dostosować format logowania. Wiem, że to ekstremalne, ale uwierz mi, widzieliśmy użycie systemu.w kodzie produkcyjnym w” tradycyjnych ” modelach wdrażania aplikacji! Oczywiście logowanie do systemu.out jest odpowiednim rozwiązaniem dla aplikacji kontenerowych i powinieneś użyć wyjścia, które pasuje do Twojego środowiska. Pamiętaj o tym!
ze względu na wszystkie wymienione powody i wiele innych, o których nawet nie myślimy, powinieneś zajrzeć do jednej z możliwych bibliotek logowania, takich jak Log4 j, Log4j 2, Logback, a nawet java.util.logowanie, które jest częścią Java Development Kit. W tym wpisie na blogu użyjemy Log4j.
warstwa abstrakcji – SLF4J
temat wyboru odpowiedniego rozwiązania do logowania dla Twojej aplikacji Java jest czymś, co już omówiliśmy w naszym tutorialu na temat logowania w Javie. Gorąco polecamy lekturę przynajmniej wspomnianej sekcji.
będziemy używać SLF4J, warstwy abstrakcji pomiędzy naszym kodem Java i Log4j-wybranej przez nas biblioteki logowania. Prosta Fasada logowania zapewnia powiązania dla popularnych frameworków logowania, takich jak Log4j, Logback i java.util.logowanie. Wyobraź sobie proces pisania wiadomości dziennika w następujący, uproszczony sposób:
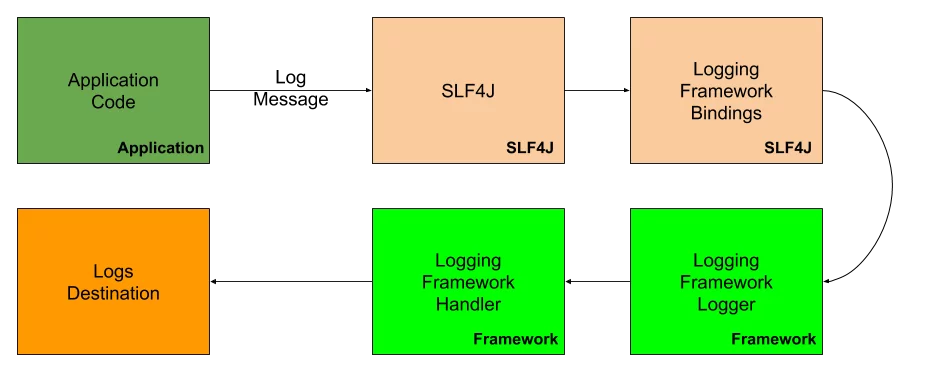
możesz zapytać po co w ogóle używać warstwy abstrakcji? Cóż, odpowiedź jest dość prosta-w końcu możesz zmienić framework rejestrowania, uaktualnić go, ujednolicić z resztą stosu technologii. Przy użyciu warstwy abstrakcji taka operacja jest dość prosta – wystarczy wymienić zależności frameworka logowania i dostarczyć nowy pakiet. Gdybyśmy nie używali warstwy abstrakcji-musielibyśmy zmienić kod, potencjalnie dużo kodu. Każda klasa, która coś rejestruje. Niezbyt miłe doświadczenie w rozwoju.
Rejestrator
kod aplikacji Java będzie współdziałał ze standardowym zestawem kluczowych elementów, które umożliwiają tworzenie i manipulowanie zdarzeniami dziennika. Omówiliśmy najważniejsze z nich w naszym tutorialu logowania Java, ale pozwól, że przypomnę ci o jednej z klas, z których będziemy stale korzystać-Loggerze.
rejestrator jest głównym elementem używanym przez aplikację do wykonywania połączeń logowania – tworzenia zdarzeń dziennika. Obiekt Logger jest zwykle używany dla jednej klasy lub pojedynczego komponentu w celu zapewnienia kontekstu związanego z konkretnym przypadkiem użycia. Zapewnia metody do tworzenia zdarzeń dziennika z odpowiednim poziomem dziennika i przekazywania ich do dalszego przetwarzania. Zwykle tworzysz statyczny obiekt, z którym będziesz wchodzić w interakcje, na przykład w ten sposób:
... Logger LOGGER = LoggerFactory.getLogger(MyAwesomeClass.class);
i to wszystko. Teraz, gdy wiemy, czego możemy się spodziewać, spójrzmy na bibliotekę Log4j.
Log4j
najprostszym sposobem rozpoczęcia Z Log4j jest włączenie biblioteki do ścieżki klas aplikacji Java. W tym celu dołączamy do naszego pliku kompilacji najnowszą dostępną bibliotekę log4j, czyli wersję 1.2.17.
używamy Gradle i w naszej prostej aplikacji Sekcja zależności dla pliku kompilacji Gradle wygląda następująco:
dependencies { implementation 'log4j:log4j:1.2.17'}
możemy zacząć rozwijać kod i dołączyć logowanie za pomocą Log4j:
package com.sematext.blog;import org.apache.log4j.Logger;public class ExampleLog4j { private static final Logger LOGGER = Logger.getLogger(ExampleLog4j.class); public static void main(String args) { LOGGER.info("Initializing ExampleLog4j application"); }}
jak widać w powyższym kodzie zainicjowaliśmy obiekt Logger za pomocą statycznej metody getLogger i podaliśmy nazwę klasy. Po wykonaniu tej czynności możemy łatwo uzyskać dostęp do obiektu statycznego Loggera i użyć go do wygenerowania zdarzeń dziennika. Możemy to zrobić w głównej metodzie.
jedna uwaga boczna – metodę getLogger można wywołać również z łańcuchem znaków jako argumentem, na przykład:
private static final Logger LOGGER = Logger.getLogger("com.sematext.blog");
oznaczałoby to, że chcemy utworzyć logger i powiązać nazwę com.sematext.blog z nim. Jeśli użyjemy tej samej nazwy gdziekolwiek indziej w kodzie Log4j zwróci tę samą instancję Loggera. Jest to przydatne, jeśli chcemy połączyć logowanie z wielu różnych klas w jednym miejscu. Na przykład dzienniki związane z płatnością w jednym, dedykowanym pliku dziennika.
Log4j udostępnia listę metod pozwalających na tworzenie nowych zdarzeń dziennika przy użyciu odpowiedniego poziomu dziennika. Są to:
- Public void trace (komunikat obiektu)
- Public void debug (komunikat obiektu)
- Public void info (komunikat obiektu)
- Public void warn (komunikat obiektu)
- Public void error (komunikat obiektu)
- Public void fatal (komunikat obiektu)
i jedna metoda ogólna:
- public void log (level level, object message)
rozmawialiśmy o Java logging poziomów w naszym blogu Java logging tutorial. Jeśli nie jesteś ich świadomy, poświęć kilka minut, aby się do nich przyzwyczaić, ponieważ poziomy dziennika są kluczowe dla rejestrowania. Jeśli dopiero zaczynasz z poziomami logowania, zalecamy zapoznanie się z naszym przewodnikiem poziomów logowania. Wyjaśniamy wszystko, od tego, czym są, po to, jak wybrać odpowiedni i jak wykorzystać je, aby uzyskać znaczące spostrzeżenia.
gdybyśmy mieli uruchomić powyższy kod, wynik na standardowej konsoli byłby następujący:
log4j:WARN No appenders could be found for logger (com.sematext.blog.ExampleLog4j).log4j:WARN Please initialize the log4j system properly.log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
nie widzieliśmy oczekiwanego komunikatu dziennika. Log4j poinformował nas, że nie ma konfiguracji. Oooops, porozmawiajmy o tym, jak skonfigurować Log4j …
Konfiguracja Log4j
istnieje wiele sposobów konfigurowania naszego logowania Log4j. Możemy to zrobić programowo-na przykład poprzez dołączenie statycznego bloku inicjalizacji:
static { BasicConfigurator.configure();}
powyższy kod konfiguruje Log4j do wysyłania dzienników do konsoli w domyślnym formacie. Wynik uruchomienia naszej przykładowej aplikacji wyglądałby następująco:
0 INFO com.sematext.blog.ExampleLog4jProgrammaticConfig - Initializing ExampleLog4j application
jednak programowanie Log4j nie jest zbyt częste. Najczęstszym sposobem byłoby użycie pliku Właściwości lub pliku XML. Możemy zmienić nasz kod i dołączyć plik log4j. properties o następującej treści:
log4j.rootLogger=DEBUG, MAINlog4j.appender.MAIN=org.apache.log4j.ConsoleAppenderlog4j.appender.MAIN.layout=org.apache.log4j.PatternLayoutlog4j.appender.MAIN.layout.ConversionPattern=%r %-5p %c %x - %m%n
w ten sposób powiedzieliśmy Log4j, że tworzymy główny logger, który będzie używany domyślnie. Jego domyślny poziom logowania jest ustawiony na DEBUG, co oznacza, że zdarzenia logowania o ważności debug lub wyższej będą uwzględniane. Więc DEBUG, INFO, WARN, błąd, i FATAL. Daliśmy też naszemu loggerowi nazwę-MAIN. Następnie konfigurujemy logger, ustawiając jego wyjście na konsolę i używając układu wzorca. Porozmawiamy o tym później w poście na blogu. Wynik uruchomienia powyższego kodu będzie następujący:
0 INFO com.sematext.blog.ExampleLog4jProperties - Initializing ExampleLog4j application
jeśli chcemy, możemy również zmienić plik log4j. properties i użyć takiego o nazwie log4j.xml. Ta sama konfiguracja przy użyciu formatu XML wyglądałaby następująco:
<!DOCTYPE log4j:configuration SYSTEM "log4j.dtd"><log4j:configuration> <appender name="MAIN" class="org.apache.log4j.ConsoleAppender"> <param name="Target" value="System.out"/> <layout class="org.apache.log4j.PatternLayout"> <param name="ConversionPattern" value="%r %-5p %c %x - %m%n" /> </layout> </appender> <root> <priority value ="debug"></priority> <appender-ref ref="MAIN" /> </root></log4j:configuration>
gdybyśmy teraz zmienili log4j. properties dla log4j.xml jeden i zachować go w classpath wykonanie naszej przykładowej aplikacji będzie wyglądać następująco:
0 INFO com.sematext.blog.ExampleLog4jXML - Initializing ExampleLog4j application
skąd więc Log4j wie, którego pliku użyć? Przyjrzyjmy się temu.
proces inicjalizacji
ważne jest, aby wiedzieć, że Log4j nie przyjmuje żadnych założeń dotyczących środowiska, w którym działa. Log4j nie przyjmuje żadnych domyślnych miejsc docelowych zdarzeń dziennika. Po uruchomieniu szuka właściwości log4j. configuration i próbuje załadować podany PLIK JAKO jego konfigurację. Jeśli lokalizacja pliku nie może zostać przekonwertowana na adres URL lub plik nie jest obecny, próbuje załadować plik ze ścieżki klasy.
oznacza to, że możemy nadpisać konfigurację Log4j ze ścieżki klasy poprzez podanie opcji-Dlog4j.configuration podczas uruchamiania i skierowanie jej do właściwej lokalizacji. Na przykład, jeśli dołączymy plik o nazwie other.xml o następującej treści:
<!DOCTYPE log4j:configuration SYSTEM "log4j.dtd"><log4j:configuration> <appender name="MAIN" class="org.apache.log4j.ConsoleAppender"> <param name="Target" value="System.out"/> <layout class="org.apache.log4j.PatternLayout"> <param name="ConversionPattern" value="%r %-5p %c %x - %m%n" /> </layout> </appender> <root> <priority value ="debug"></priority> <appender-ref ref="MAIN" /> </root></log4j:configuration>
a następnie uruchom kod z -Dlog4j. configuration= / opt / sematext / other.XML wyjście z naszego kodu będzie następujące:
0 INFO com.sematext.blog.ExampleLog4jXML - Initializing ExampleLog4j application
Appenders Log4j
w naszych przykładach już użyliśmy appenderów … cóż, tak naprawdę tylko jeden-ConsoleAppender. Jego jedynym celem jest zapisywanie zdarzeń dziennika do konsoli. Oczywiście przy dużej liczbie zdarzeń dziennika i systemów działających w różnych środowiskach zapisywanie czystych danych tekstowych na standardowe wyjście może nie być najlepszym pomysłem, chyba że pracujesz w kontenerach. Dlatego Log4j obsługuje wiele typów nadawców. Oto kilka typowych przykładów aplikacji Log4j:
- ConsoleAppender-appender, który dołącza zdarzenia dziennika do systemu.out or System.błąd z domyślnym systemem.Wynocha. Podczas korzystania z tego appendera zobaczysz swoje logi w konsoli aplikacji.
- FileAppender-appender, który dołącza zdarzenia dziennika do zdefiniowanego pliku przechowującego je w systemie plików.
- RollingFileAppender – appender, który rozszerza FileAppender i obraca plik, gdy osiągnie określony rozmiar. Użycie RollingFileAppender zapobiega powstawaniu bardzo dużych i trudnych do utrzymania plików dziennika.
- syslogappender-appender wysyłający zdarzenia dziennika do zdalnego demona Syslog.
- JDBCAppender-appender, który przechowuje zdarzenia dziennika do bazy danych. Należy pamiętać, że ten appender nie będzie przechowywać błędów i generalnie nie jest najlepszym pomysłem zapisywanie zdarzeń dziennika w bazie danych.
- SocketAppender – appender, który wysyła serializowane zdarzenia dziennika do zdalnego gniazda. Należy pamiętać, że ten appender nie używa układów, ponieważ wysyła serializowane, surowe zdarzenia dziennika.
- NullAppender – appender, który po prostu odrzuca zdarzenia dziennika.
co więcej, możesz skonfigurować wiele nadawców dla jednej aplikacji. Na przykład można wysyłać logi do konsoli i do pliku. Następujący log4j.zawartość pliku właściwości zrobiłaby dokładnie to:
log4j.rootLogger=DEBUG, MAIN, ROLLINGlog4j.appender.MAIN=org.apache.log4j.ConsoleAppenderlog4j.appender.MAIN.layout=org.apache.log4j.PatternLayoutlog4j.appender.MAIN.layout.ConversionPattern=%r %-5p %c %x - %m%nlog4j.appender.ROLLING=org.apache.log4j.RollingFileAppenderlog4j.appender.ROLLING.File=/var/log/sematext/awesome.loglog4j.appender.ROLLING.MaxFileSize=1024KBlog4j.appender.ROLLING.MaxBackupIndex=10log4j.appender.ROLLING.layout=org.apache.log4j.PatternLayoutlog4j.appender.ROLLING.layout.ConversionPattern=%r %-5p %c %x - %m%n
nasz główny rejestrator jest skonfigurowany tak, aby rejestrować wszystko, począwszy od stopnia debugowania i wysyłać dzienniki do dwóch nadawców-głównego i ROLLING. Głównym rejestratorem jest ten, który już widzieliśmy-ten, który wysyła dane do konsoli.
drugi logger, ten zwany ROLLING, jest bardziej interesujący w tym przykładzie. Używa RollingFileAppender, który zapisuje dane do pliku i zdefiniujmy, jak duży może być plik i ile plików ma być przechowywanych. W naszym przypadku pliki dziennika powinny być nazywane awesome.Zaloguj i zapisz dane do katalogu/var/log/ sematext/. Każdy plik powinien mieć maksymalnie 1024KB i nie powinno być więcej niż 10 plików. Jeśli jest więcej plików, zostaną one usunięte z systemu plików, gdy tylko log4j je zobaczy.
po uruchomieniu kodu z powyższą konfiguracją konsola wyświetli następującą zawartość:
0 INFO com.sematext.blog.ExampleAppenders - Starting ExampleAppenders application1 WARN com.sematext.blog.ExampleAppenders - Ending ExampleAppenders application
w / var / log / sematext / awesome.plik dziennika, który zobaczylibyśmy:
0 INFO com.sematext.blog.ExampleAppenders - Starting ExampleAppenders application1 WARN com.sematext.blog.ExampleAppenders - Ending ExampleAppenders application
Appender Log Level
zaletą Appenderów jest to, że mogą mieć swój poziom, który należy wziąć pod uwagę podczas logowania. Wszystkie przykłady, które widzieliśmy do tej pory, rejestrowały każdą wiadomość, która miała wagę debugowania lub wyższą. A gdybyśmy chcieli to zmienić dla wszystkich klas w Kom.sematext.pakiet blogowy? Musielibyśmy tylko zmodyfikować nasz plik log4j. properties:
log4j.rootLogger=DEBUG, MAINlog4j.appender.MAIN=org.apache.log4j.ConsoleAppenderlog4j.appender.MAIN.layout=org.apache.log4j.PatternLayoutlog4j.appender.MAIN.layout.ConversionPattern=%r %-5p %c %x - %m%nlog4j.logger.com.sematext.blog=WARN
spójrz na ostatnią linię w powyższym pliku konfiguracyjnym. Użyliśmy przedrostka log4j. logger i stwierdziliśmy, że logger nazywa się com.sematext.blog powinien być używany tylko dla poziomów ważności ostrzegać i powyżej, więc błąd i śmiertelne.
nasz przykładowy kod aplikacji wygląda następująco:
public static void main(String args) { LOGGER.info("Starting ExampleAppenderLevel application"); LOGGER.warn("Ending ExampleAppenderLevel application");}
przy powyższej konfiguracji Log4j wynik logowania wygląda następująco:
0 WARN com.sematext.blog.ExampleAppenderLevel - Ending ExampleAppenderLevel application
jak widać, uwzględniono tylko dziennik poziomu WARN. Dokładnie tego chcieliśmy.
Układy Log4j
wreszcie, część logowania log4j Framework, który kontroluje sposób, w jaki nasze dane są zorganizowane w naszym pliku dziennika – układ. Log4j udostępnia kilka domyślnych implementacji, takich jak PatternLayout, SimpleLayout, XMLLayout, HTMLLayout, EnchancedPatternLayout i DateLayout.
w większości przypadków napotkasz PatternLayout. Ideą tego układu jest to, że można zapewnić różne opcje formatowania, aby zdefiniować strukturę dzienników. Niektóre przykłady to:
- d-Data i czas zdarzenia log,
- m – wiadomość powiązana ze zdarzeniem log,
- t – nazwa wątku,
- N – separator linii zależny od platformy,
- P – poziom dziennika.
aby uzyskać więcej informacji na temat dostępnych opcji, Przejdź do oficjalnego Log4j Javadocs, aby uzyskać PatternLayout.
korzystając z PatternLayout możemy skonfigurować, którą opcję chcemy użyć. Załóżmy, że chcielibyśmy napisać datę, wagę zdarzenia log, wątek otoczony nawiasami kwadratowymi i wiadomość zdarzenia log. Przydałby się taki wzór:
%d %-5p - %m%n
pełny plik log4j. properties w tym przypadku może wyglądać następująco:
log4j.rootLogger=DEBUG, MAINlog4j.appender.MAIN=org.apache.log4j.ConsoleAppenderlog4j.appender.MAIN.layout=org.apache.log4j.PatternLayoutlog4j.appender.MAIN.layout.ConversionPattern=%d %-5p - %m%n
używamy %d do wyświetlania daty, % – 5p do wyświetlania ważności za pomocą 5 znaków, %t Dla wątku, %m dla wiadomości i %n dla separatora linii. Wyjście, które jest zapisywane do konsoli po uruchomieniu naszego przykładowego kodu wygląda następująco:
2021-02-02 11:49:49,003 INFO - Initializing ExampleLog4jFormatter application
zagnieżdżony kontekst diagnostyczny
w większości rzeczywistych aplikacji Zdarzenie log nie istnieje samo w sobie. Jest otoczona pewnym kontekstem. Aby zapewnić taki kontekst, dla każdego wątku, Log4j dostarcza tak zwany zagnieżdżony kontekst diagnostyczny. W ten sposób możemy powiązać dany wątek dodatkowymi informacjami, na przykład identyfikatorem sesji, tak jak w naszej przykładowej aplikacji:
NDC.push(String.format("Session ID: %s", "1234-5678-1234-0987"));LOGGER.info("Initializing ExampleLog4jNDC application");
przy użyciu wzorca zawierającego zmienną x Dodatkowe informacje będą zawarte w każdej linii logowania dla danego wątku. W naszym przypadku wynik będzie wyglądał następująco:
0 INFO com.sematext.blog.ExampleLog4jNDC Session ID: 1234-5678-1234-0987 - Initializing ExampleLog4jNDC application
możesz zobaczyć, że informacje o identyfikatorze sesji znajdują się w linii logowania. Dla odniesienia plik log4j. properties, którego użyliśmy w tym przykładzie, wygląda następująco:
log4j.rootLogger=DEBUG, MAINlog4j.appender.MAIN=org.apache.log4j.ConsoleAppenderlog4j.appender.MAIN.layout=org.apache.log4j.PatternLayoutlog4j.appender.MAIN.layout.ConversionPattern=%r %-5p %c %x - %m%n
zmapowany kontekst diagnostyczny
drugim rodzajem informacji kontekstowych, które możemy uwzględnić w naszych zdarzeniach dziennika, jest zmapowany kontekst diagnostyczny. Za pomocą klasy MDC możemy dostarczyć dodatkowe informacje związane z wartością klucza. Podobnie jak zagnieżdżony kontekst diagnostyczny, zmapowany kontekst diagnostyczny jest związany z wątkiem.
spójrzmy na przykładowy kod aplikacji:
MDC.put("user", "[email protected]");MDC.put("step", "initial");LOGGER.info("Initializing ExampleLog4jNDC application");MDC.put("step", "launch");LOGGER.info("Starting ExampleLog4jNDC application");
mamy dwa pola kontekstowe-user I step. Aby wyświetlić wszystkie zmapowane informacje kontekstu diagnostycznego związane ze zdarzeniem log, po prostu używamy zmiennej X w naszej definicji wzorca. Na przykład:
log4j.rootLogger=DEBUG, MAINlog4j.appender.MAIN=org.apache.log4j.ConsoleAppenderlog4j.appender.MAIN.layout=org.apache.log4j.PatternLayoutlog4j.appender.MAIN.layout.ConversionPattern=%r %-5p %c %X - %m%n
uruchomienie powyższego kodu wraz z konfiguracją spowoduje następujące wyjście:
0 INFO com.sematext.blog.ExampleLog4jMDC {{step,initial}{user,[email protected]}} - Initializing ExampleLog4jNDC application1 INFO com.sematext.blog.ExampleLog4jMDC {{step,launch}{user,[email protected]}} - Starting ExampleLog4jNDC application
możemy również wybrać, których Informacji użyć, zmieniając wzór. Na przykład, aby uwzględnić użytkownika z zmapowanego kontekstu diagnostycznego, możemy napisać wzór podobny do tego:
%r %-5p %c %X{user} - %m%n
tym razem wynik będzie wyglądał następująco:
0 INFO com.sematext.blog.ExampleLog4jMDC [email protected] - Initializing ExampleLog4jNDC application0 INFO com.sematext.blog.ExampleLog4jMDC [email protected] - Starting ExampleLog4jNDC application
widać, że zamiast ogólnego %X użyliśmy %x{user}. Oznacza to, że jesteśmy zainteresowani zmienną użytkownika z zmapowanego kontekstu diagnostycznego związanego z danym zdarzeniem dziennika.
migracja do Log4j 2
Migracja z Log4j 1.x do Log4j 2.x nie jest trudne, a w niektórych przypadkach może być bardzo łatwe. Jeśli nie używałeś żadnego wewnętrznego Log4j 1.klasy x, używałeś plików konfiguracyjnych zamiast programowo konfigurować loggery i nie korzystałeś z klas Domconfigurator i PropertyConfigurator migracja powinna być tak prosta, jak włączenie log4j-1.2-api.plik jar jar zamiast Log4j 1.pliki x jar. To pozwoliłoby Log4j 2.X do pracy z kodem. Musisz dodać Log4j 2.pliki x jar, dostosuj konfigurację i voila-gotowe.
jeśli chcesz dowiedzieć się więcej o Log4j 2.x sprawdź nasz Java logging tutorial i jego Log4j 2.x sekcja dedykowana.
jednak, jeśli użyłeś wewnętrznego Log4j 1.x classes, oficjalny przewodnik migracji, jak przejść z Log4j 1.x do Log4j 2.x będzie bardzo pomocny. Omawia on potrzebne zmiany w kodzie i konfiguracji i będzie nieoceniony w razie wątpliwości.
scentralizowane logowanie za pomocą narzędzi do zarządzania dziennikami
wysyłanie zdarzeń dziennika do konsoli lub pliku może być dobre dla jednej aplikacji, ale obsługa wielu wystąpień aplikacji i korelowanie dzienników z wielu źródeł nie jest zabawne, gdy zdarzenia dziennika są w plikach tekstowych na różnych komputerach. W takich przypadkach ilość danych szybko staje się niemożliwa do zarządzania i wymaga dedykowanych rozwiązań – hostowanych samodzielnie lub pochodzących od jednego z dostawców. A co z kontenerami, w których zazwyczaj nie zapisujesz logów do plików? Jak rozwiązać i debugować aplikację, której logi zostały wysłane na standardowe wyjście lub której kontener został zabity?
w tym miejscu pojawiają się usługi zarządzania dziennikami, narzędzia do analizy dzienników i usługi rejestrowania w chmurze. Jest to niepisane Java logging najlepszych praktyk wśród inżynierów, aby używać takich rozwiązań, gdy jesteś poważnie o zarządzaniu dzienniki i jak najlepiej z nich. Na przykład Sematext Logs, nasze oprogramowanie do monitorowania i zarządzania logami, rozwiązuje wszystkie wyżej wymienione problemy i nie tylko.
dzięki w pełni zarządzanemu rozwiązaniu, takim jak Sematext Logs, nie musisz zarządzać innym fragmentem środowiska – Twoim rozwiązaniem do rejestrowania DIY, Zwykle zbudowanym z elementów elastycznego stosu. Takie konfiguracje mogą zaczynać się od małych i tanich, jednak często rosną duże i drogie. Nie tylko pod względem kosztów infrastruktury, ale także kosztów zarządzania. Wiesz, czas i płace. Więcej o zaletach korzystania z zarządzanej usługi wyjaśniamy w naszym poście na blogu o najlepszych praktykach logowania.
alerty i agregacja logów są również kluczowe w przypadku problemów. Ostatecznie, w przypadku aplikacji Java, możesz chcieć mieć dzienniki zbierania śmieci po włączeniu rejestrowania i rozpoczęciu analizy dzienników. Takie dzienniki skorelowane z metrykami są nieocenionym źródłem informacji do rozwiązywania problemów związanych z gromadzeniem śmieci.
podsumowanie
mimo że Log4j 1.x osiągnął swój koniec dawno temu jest nadal obecny w wielu starszych aplikacjach używanych na całym świecie. Migracja do jego młodszej wersji jest dość prosta, ale może wymagać znacznych zasobów i czasu i zwykle nie jest priorytetem. Zwłaszcza w dużych przedsiębiorstwach, gdzie procedury, wymogi prawne lub oba te elementy wymagają audytów, a następnie długich i kosztownych testów, zanim cokolwiek może zostać zmienione w już działającym systemie. Ale dla tych z nas, którzy dopiero zaczynają lub myślą o migracji-pamiętajcie, Log4j 2.x jest tam, jest już dojrzały, szybki, bezpieczny i bardzo zdolny.
ale niezależnie od struktury używanej do rejestrowania aplikacji Java, zdecydowanie zalecamy połączenie wysiłków z w pełni zarządzanym rozwiązaniem do zarządzania logami, takim jak dzienniki Sematext. Spróbuj! Dostępna jest 14-dniowa BEZPŁATNA wersja próbna na jazdę próbną.
Szczęśliwego logowania!