krok po kroku: jak skonfigurować wystąpienie klastra pracy awaryjnej SQL SERVER 2008 R2 w systemie WINDOWS SERVER 2008 R2 na platformie AZURE lub AZURE STACK
9 lipca 2019 r.skończy się. Oznacza to koniec regularnych aktualizacji zabezpieczeń. Jeśli jednak przeniesiesz te wystąpienia serwera SQL do platformy Azure lub Azure Stack (w dalszej części przewodnika będę po prostu określać oba te wystąpienia jako Azure), firma Microsoft zapewni Ci trzy lata rozszerzonych aktualizacji zabezpieczeń bez dodatkowych opłat. Jeśli aktualnie korzystasz z SQL Server 2008/2008 R2 i nie jesteś w stanie zaktualizować SQL Server do późniejszej wersji przed terminem 9 lipca, będziesz chciał skorzystać z tej oferty, zamiast narażać się na przyszłe luki w zabezpieczeniach. Niezrównana instancja SQL Server może prowadzić do utraty danych, przestojów lub druzgocącego naruszenia danych.
jednym z wyzwań, z którymi musisz się zmierzyć podczas uruchamiania serwera SQL Server 2008/2008 R2 na platformie Azure, jest zapewnienie wysokiej dostępności. Lokalnie możesz uruchamiać instancję klastra pracy awaryjnej SQL Server (FCI) w celu zapewnienia wysokiej dostępności lub być może używasz SQL Server na maszynie wirtualnej i polegasz na VMware HA lub klastrze Hyper-V w celu zapewnienia dostępności. Podczas przenoszenia na platformę Azure żadna z tych opcji nie jest dostępna. Przestoje na platformie Azure to bardzo realna możliwość, że musisz podjąć kroki w celu ich złagodzenia.
aby zminimalizować możliwość przestoju i zakwalifikować się do Azure ’ s 99.95% lub 99.99% SLA, musisz wykorzystać DataKeeper SIOS. DataKeeper eliminuje brak współdzielonej pamięci masowej platformy Azure i pozwala na zbudowanie serwera SQL FCI na platformie Azure, który wykorzystuje lokalnie dołączoną pamięć masową w każdym wystąpieniu. SIOS DataKeeper obsługuje nie tylko SQL Server 2008 R2 i Windows Server 2008 R2, jak udokumentowano w tym przewodniku, obsługuje dowolną wersję systemu Windows Server, od 2008 R2 do Windows Server 2019 i dowolną wersję SQL Server od SQL Server 2008 do SQL Server 2019.
ten przewodnik przeprowadzi proces tworzenia wystąpienia klastra pracy awaryjnej (FCI) z dwoma węzłami SQL Server 2008 R2 na platformie Azure, działającego w systemie Windows Server 2008 R2. Chociaż DataKeeper SIOS obsługuje również klastry obejmujące strefy lub regiony dostępności, w tym przewodniku zakłada się, że każdy węzeł znajduje się w tym samym regionie platformy Azure, ale w różnych domenach błędów. SIOS DataKeeper zostanie użyty zamiast współdzielonej pamięci masowej Zwykle wymaganej do utworzenia SQL Server 2008 R2 FCI.
wymagania wstępne
Active Directory
ten przewodnik zakłada, że posiadasz istniejącą domenę Active Directory. Możesz zarządzać własnymi kontrolerami domen lub korzystać z usług domen Azure Active Directory. W tym tutorialu połączymy się z domeną o nazwie contoso.lokalne. Oczywiście połączysz się z własną domeną, postępując zgodnie z tym samouczkiem.
Otwórz porty zapory
– SQL Server:1433 dla wystąpienia domyślnego
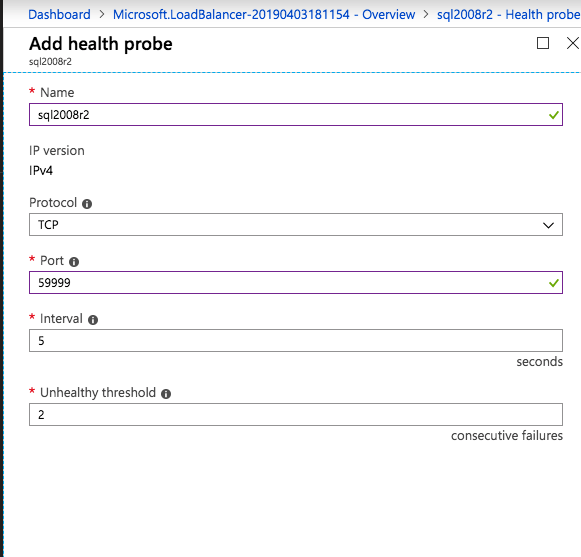
– Load Balancer Health Probe: 59999
– DataKeeper: te reguły zapory są automatycznie dodawane do zapory opartej na hoście systemu Windows podczas instalacji. Szczegółowe informacje na temat otwieranych portów można znaleźć w dokumentacji SIOS.
– pamiętaj, że jeśli masz jakieś zabezpieczenia sieciowe, które blokują porty między węzłami klastra, będziesz musiał również uwzględnić te porty.
konto usługi DataKeeper
Utwórz konto domeny. Określimy To konto podczas instalacji Datakeepera. To konto będzie musiało zostać dodane do lokalnej grupy Administratorzy na każdym węźle klastra.
Utwórz pierwsze wystąpienie SQL Server na platformie Azure
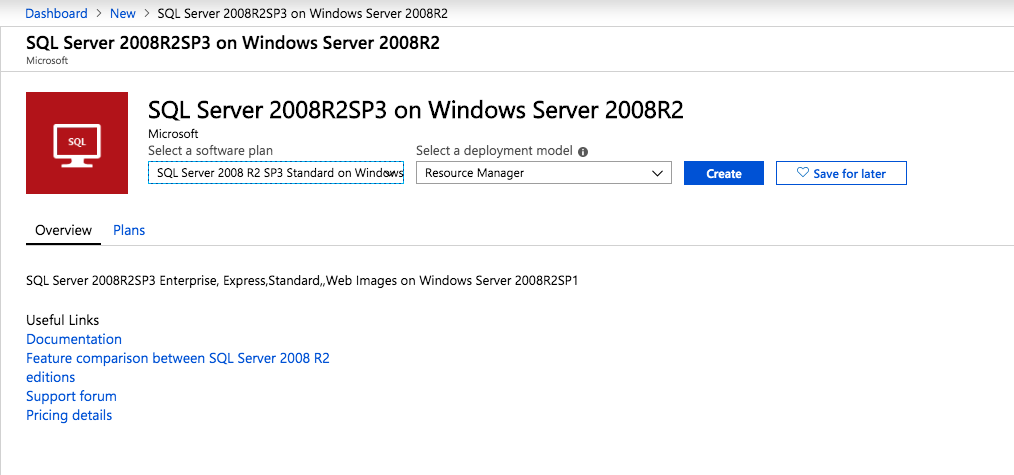
ten przewodnik wykorzysta obraz SQL Server 2008r2sp3 w systemie Windows Server 2008R2 opublikowany w Azure Marketplace.
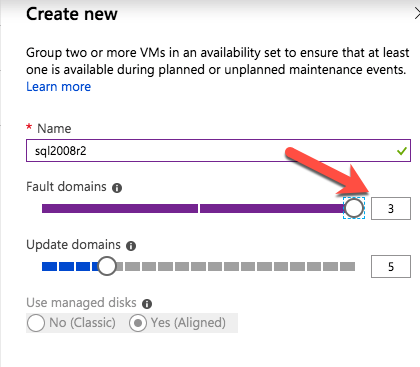
po podaniu pierwszej instancji należy utworzyć nowy zestaw dostępności. Podczas tego procesu należy zwiększyć liczbę domen błędów do 3. Pozwala to dwóm węzłom klastra i udziałowi plików witness znajdować się w ich własnej domenie błędu.
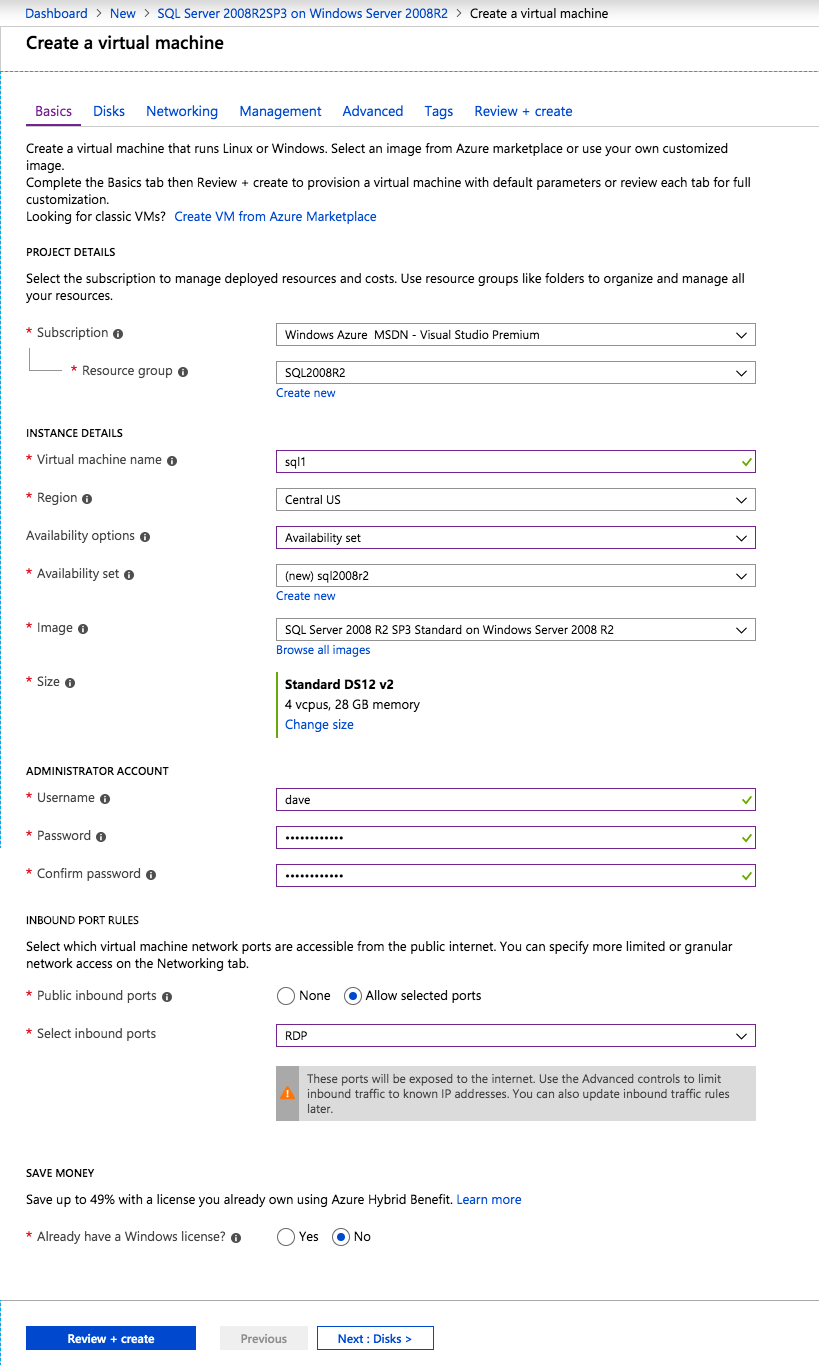
jeśli nie masz jeszcze skonfigurowanej sieci wirtualnej, Zezwól kreatorowi tworzenia na utworzenie nowej.
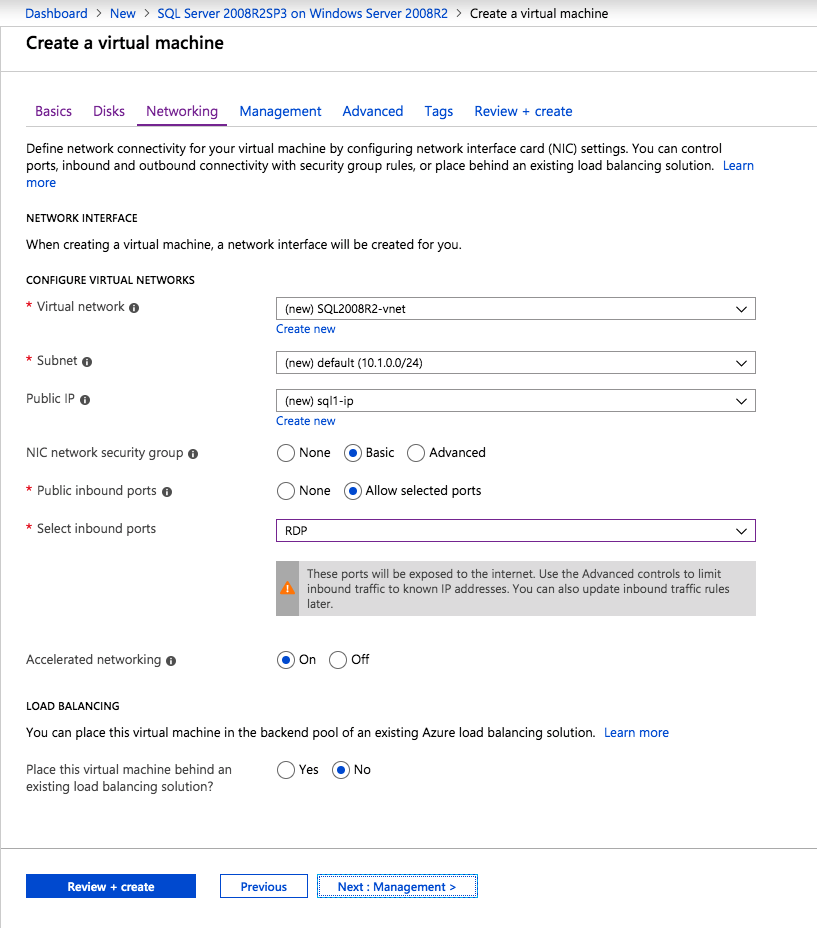
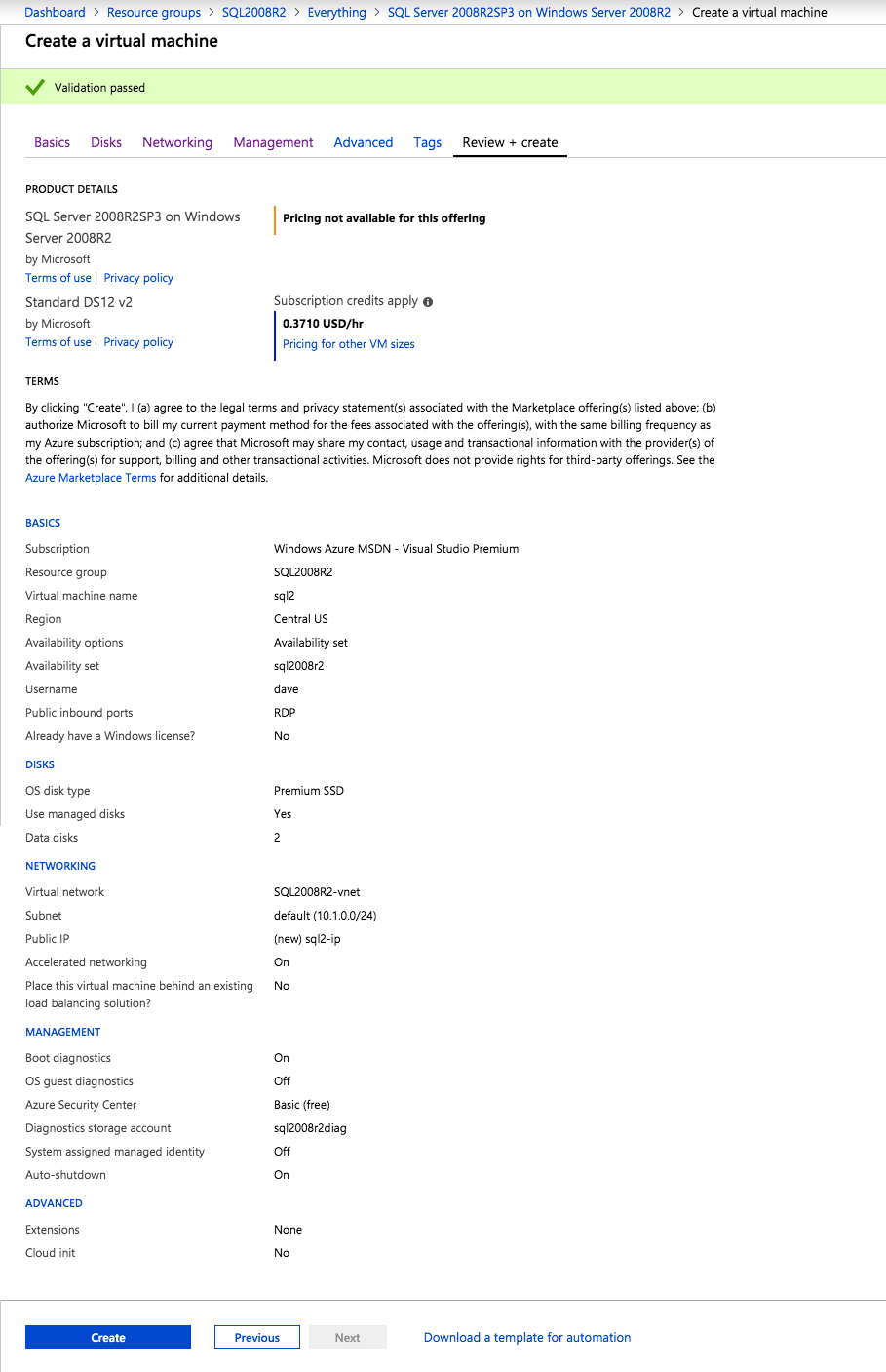
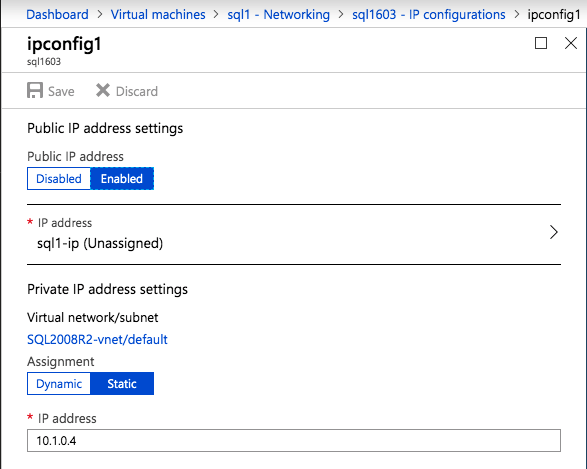
po utworzeniu instancji przejdź do konfiguracji IP i ustaw prywatny adres IP jako statyczny. Jest to wymagane dla SIOS DataKeeper i jest to najlepsza praktyka dla instancji klastrowych.
upewnij się, że sieć wirtualna jest skonfigurowana tak, aby serwer DNS był lokalnym kontrolerem Windows AD, aby w późniejszym etapie móc dołączyć do domeny.
po aprowizacji maszyn wirtualnych dodaj co najmniej dwa dodatkowe dyski do każdego wystąpienia. Zalecane są dyski SSD Premium lub Ultra. Wyłącz buforowanie na dyskach używanych do plików dziennika SQL. Włącz buforowanie tylko do odczytu na dysku używanym do plików danych SQL. Więcej informacji na temat najlepszych praktyk w zakresie pamięci masowej można znaleźć w przewodnikach dotyczących wydajności dla serwera SQL Server w usłudze Azure Virtual Machines.
Utwórz drugie wystąpienie SQL Server na platformie Azure
wykonaj te same czynności, co powyżej, z tym wyjątkiem, że pamiętaj o umieszczeniu tego wystąpienia w tym samym zestawie sieci wirtualnej i dostępności utworzonym w pierwszym wystąpieniu.
Utwórz instancję programu File Share Witness (FSW)
aby klaster pracy awaryjnej systemu Windows Server działał optymalnie, musisz utworzyć inną instancję systemu Windows Server i umieścić ją w tym samym zestawie dostępności co instancje serwera SQL. Umieszczając go w tym samym zestawie dostępności, upewniasz się, że każdy węzeł klastra i FSW znajdują się w różnych domenach błędów, zapewniając, że klaster pozostaje włączony w przypadku wyłączenia całej domeny błędu. Ta instancja nie wymaga serwera SQL, może to być prosty serwer Windows, ponieważ wszystko, co musisz zrobić, to hostować prosty udział plików.
ta instancja będzie hostować świadka udostępniania plików wymaganego przez WSFC. Ta instancja nie musi być tego samego rozmiaru, ani nie wymaga dołączania żadnych dodatkowych dysków. Jego jedynym celem jest hostowanie prostego udostępniania plików. W rzeczywistości może być używany do innych celów. W moim środowisku laboratoryjnym mój FSW jest również moim kontrolerem domeny.
Odinstaluj SQL Server 2008 R2
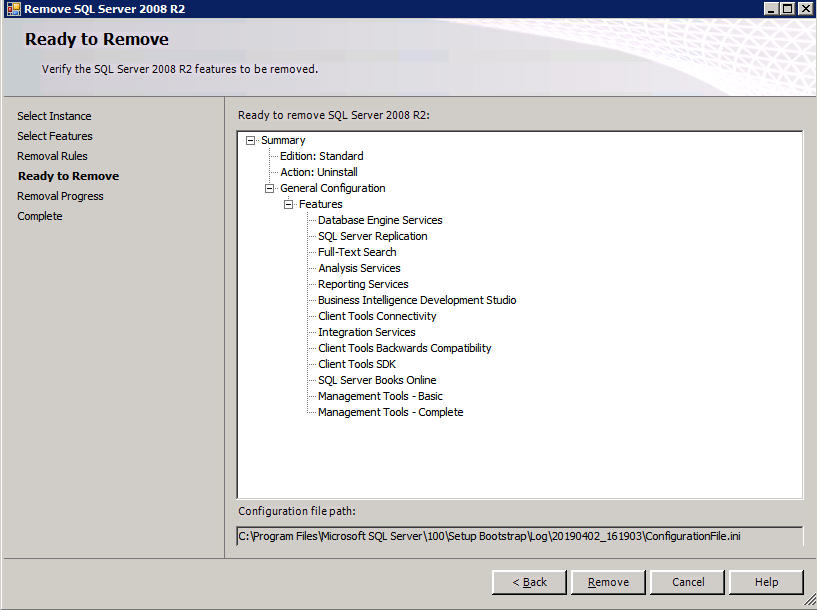
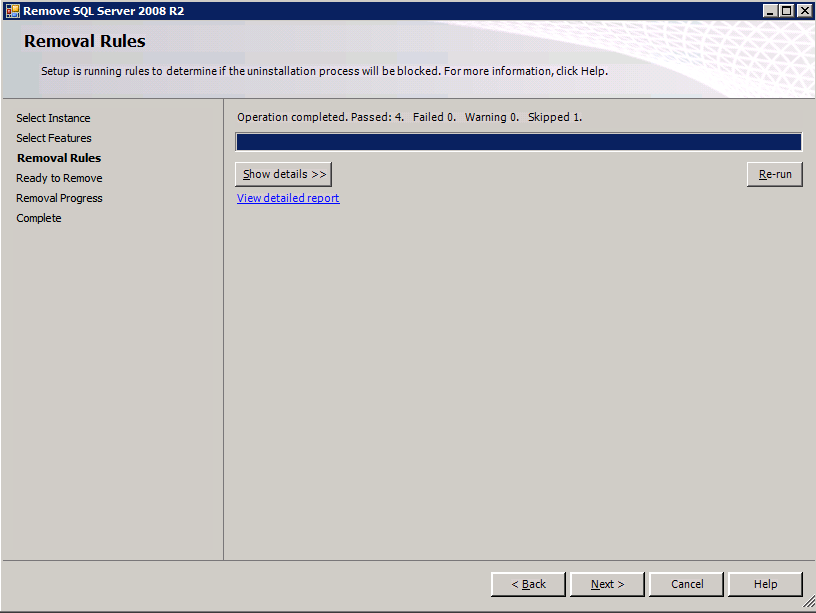
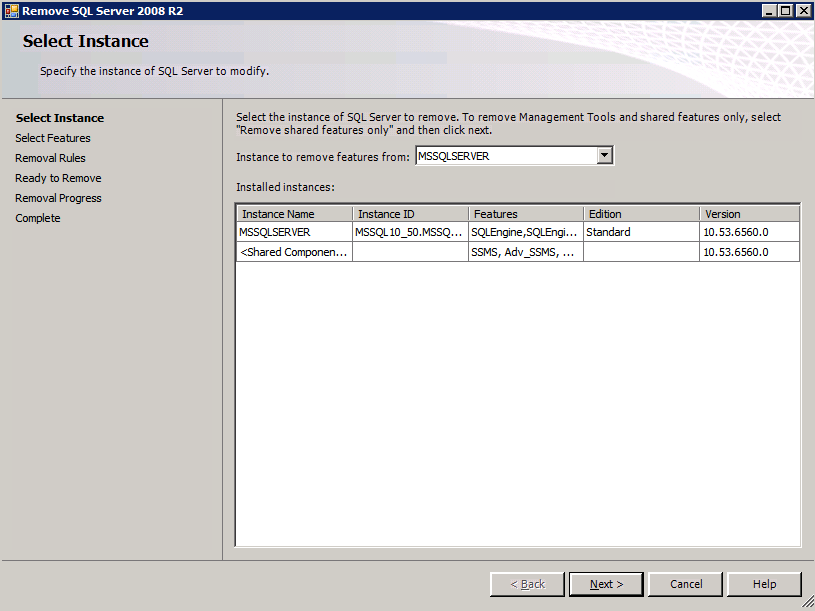
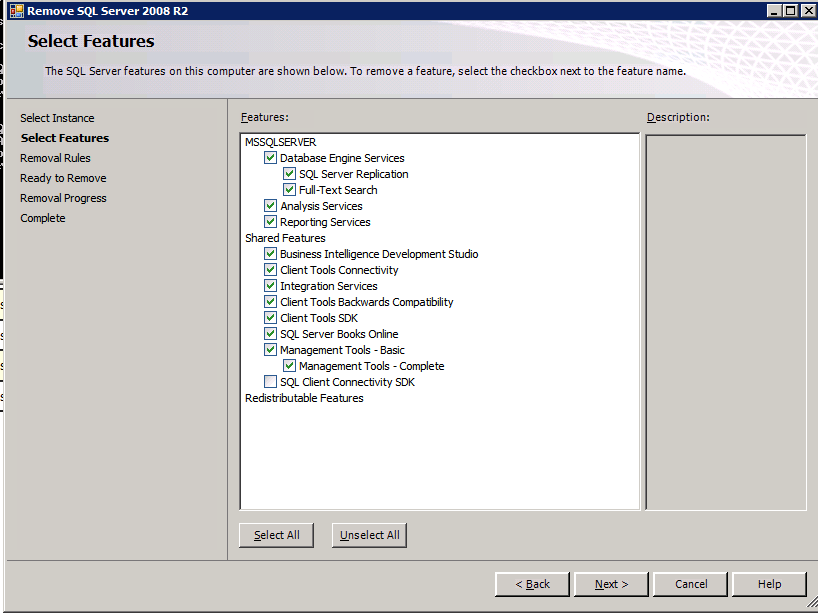
każda z dwóch obsługiwanych instancji SQL Server ma już zainstalowane SQL Server 2008 R2. Są one jednak instalowane jako samodzielne instancje serwera SQL, a nie jako instancje klastrowe. SQL Server musi zostać odinstalowany z każdej z tych instancji, zanim będziemy mogli zainstalować instancję klastra. Najprostszym sposobem na to jest uruchomienie konfiguracji SQL, jak pokazano poniżej.
po uruchomieniu setup.exe / Action-RunDiscovery zobaczysz wszystko, co jest preinstalowane
setup.exe /Action=RunDiscovery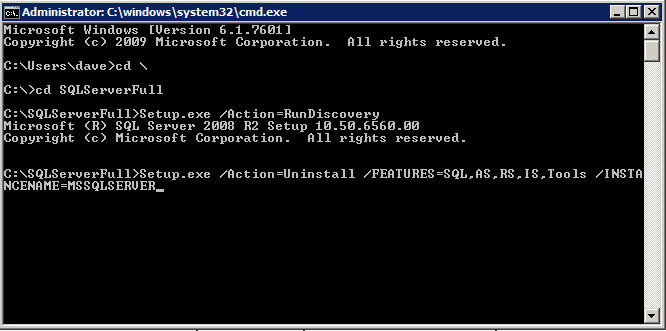

uruchamiam konfigurację.exe / Action=Uninstall / FEATURES=SQL, AS, RS, IS, Tools / INSTANCENAME=MSSQLSERVER rozpoczyna proces deinstalacji
setup.exe /Action=Uninstall /FEATURES=SQL,AS,RS,IS,Tools /INSTANCENAME=MSSQLSERVER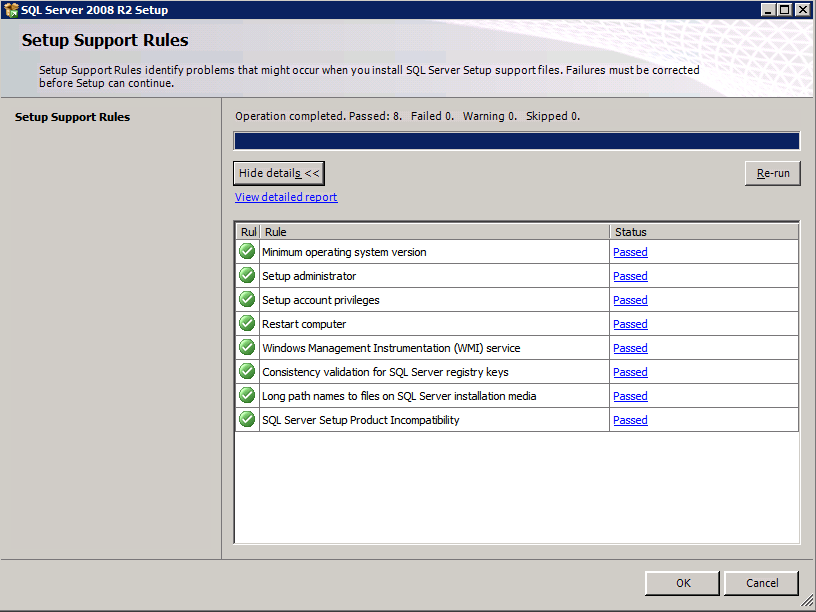
uruchamiam konfigurację.exe / Action-RunDiscovery potwierdza zakończenie deinstalacji
setup.exe /Action-RunDiscovery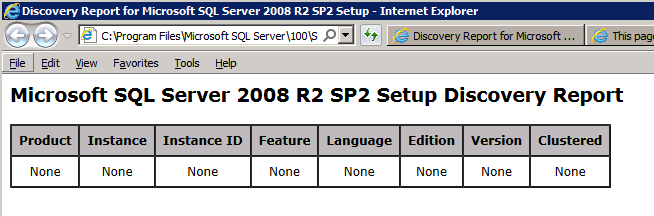
Uruchom ten proces deinstalacji ponownie w drugiej instancji.
Dodaj wystąpienia do domeny
wszystkie trzy z tych wystąpień będą musiały zostać dodane do domeny systemu Windows. Jak wspomniano w sekcji Wymagania wstępne, musisz mieć dostęp do istniejącej usługi Windows Active Directory. W naszym przypadku dołączamy do domeny o nazwie contoso.lokalne.
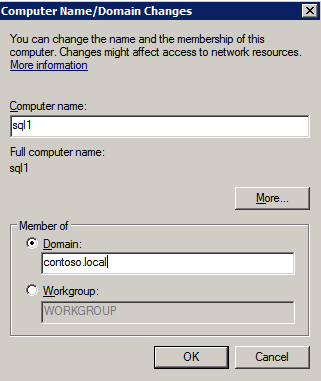
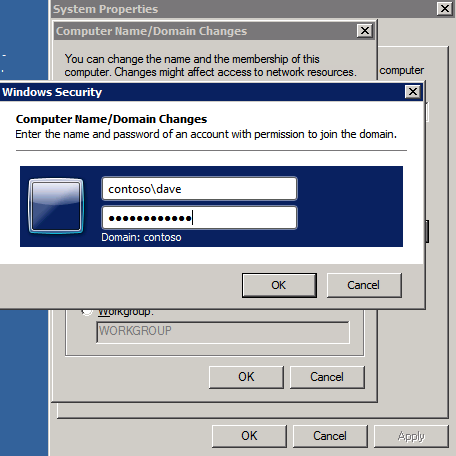
Dodaj funkcję klastrowania pracy awaryjnej systemu Windows
funkcja klastrowania pracy awaryjnej musi zostać dodana do dwóch wystąpień serwera SQL
Add-WindowsFeature Failover-Clustering
zainstaluj wygodną aktualizację Rollup dla systemu Windows Server 2008 R2 SP1
do skonfigurowania wystąpienia systemu Windows Server 2008 R2 na platformie Azure wymagana jest aktualizacja krytyczna ( kb2854082). Ta aktualizacja i wiele innych są zawarte w wygodnej aktualizacji Rollup dla systemu Windows Server 2008 R2 SP1. Zainstaluj tę aktualizację w każdej z dwóch instancji serwera SQL.
sformatuj pamięć
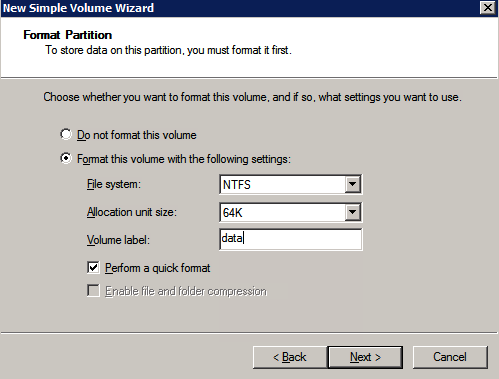
dodatkowe dyski, które zostały dołączone podczas aprowizacji dwóch instancji serwera SQL, muszą zostać sformatowane. Wykonaj następujące czynności dla każdego woluminu w każdej instancji.
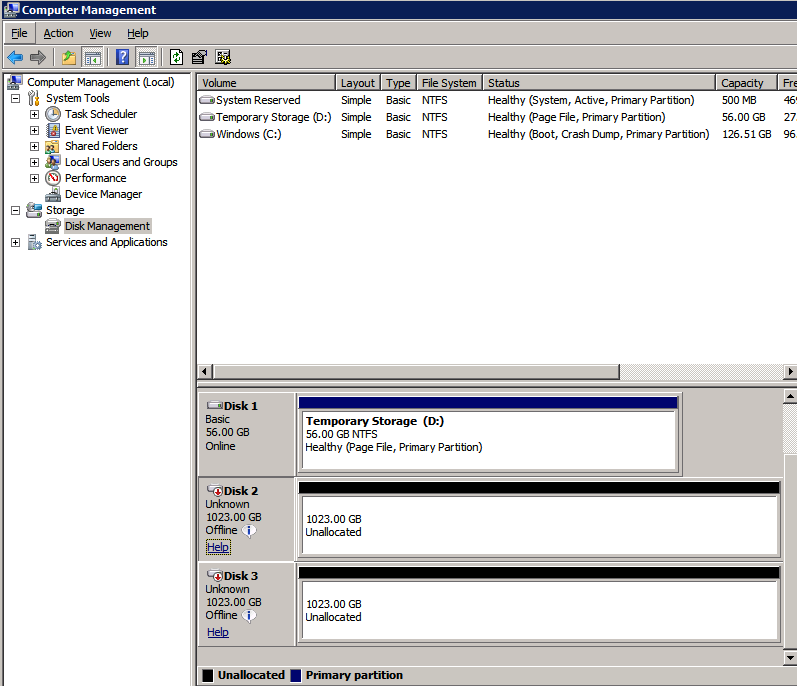
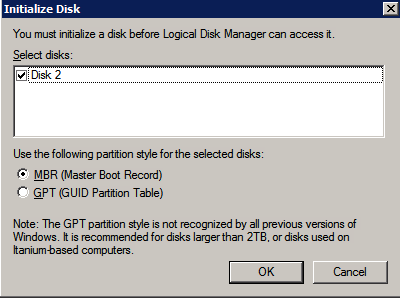
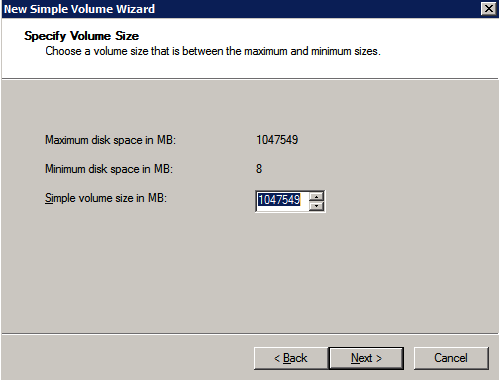
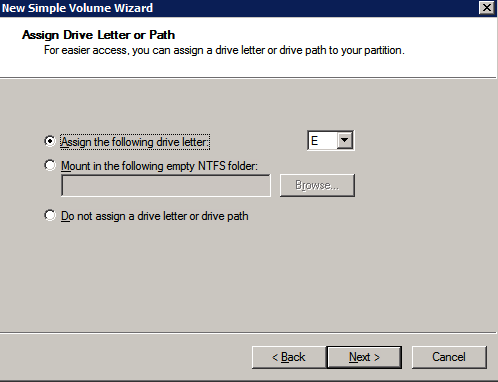
Microsoft best practices mówi następujące …
” rozmiar jednostki alokacji NTFS: Podczas formatowania dysku danych zaleca się użycie jednostki alokacji o rozmiarze 64 KB dla plików danych i dzienników oraz TempDB.”
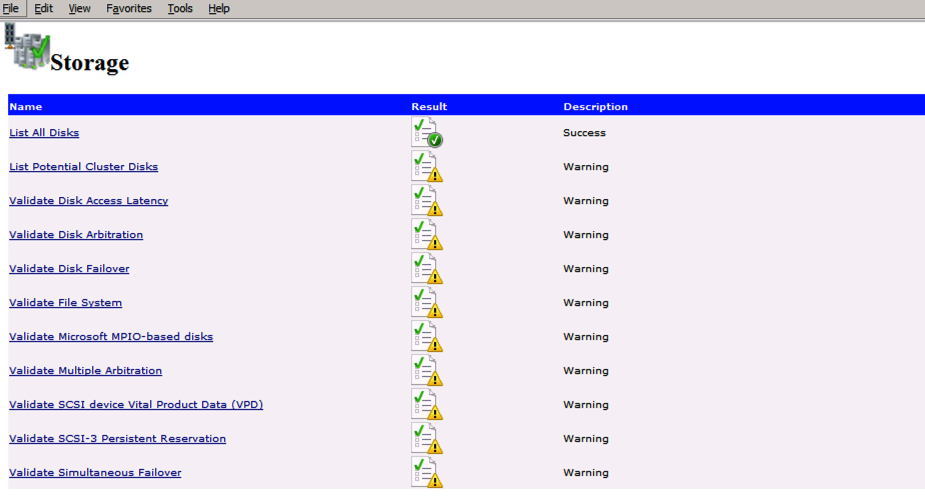
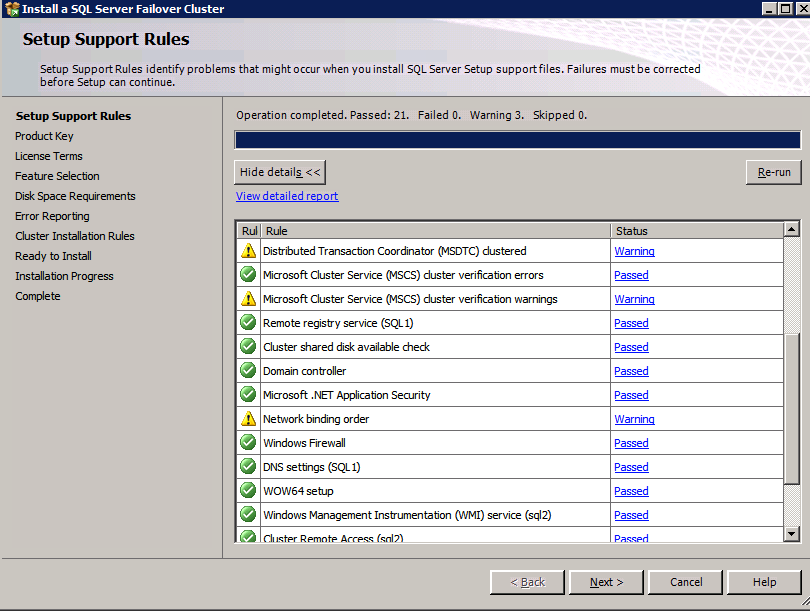
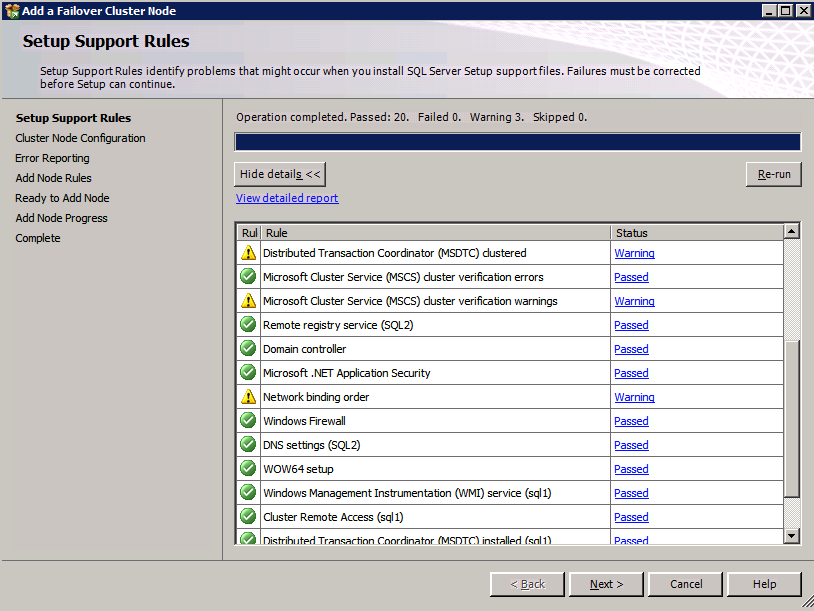
Uruchom walidację klastra
Uruchom walidację klastra, aby upewnić się, że wszystko jest gotowe do klastrowania.
Import-Module FailoverClustersTest-Cluster -Node "SQL1", "SQL2"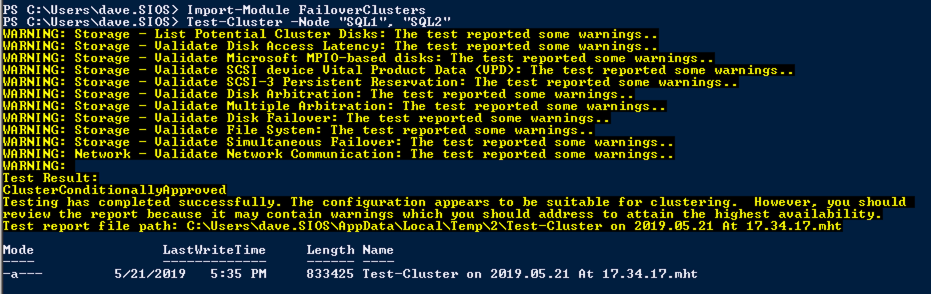
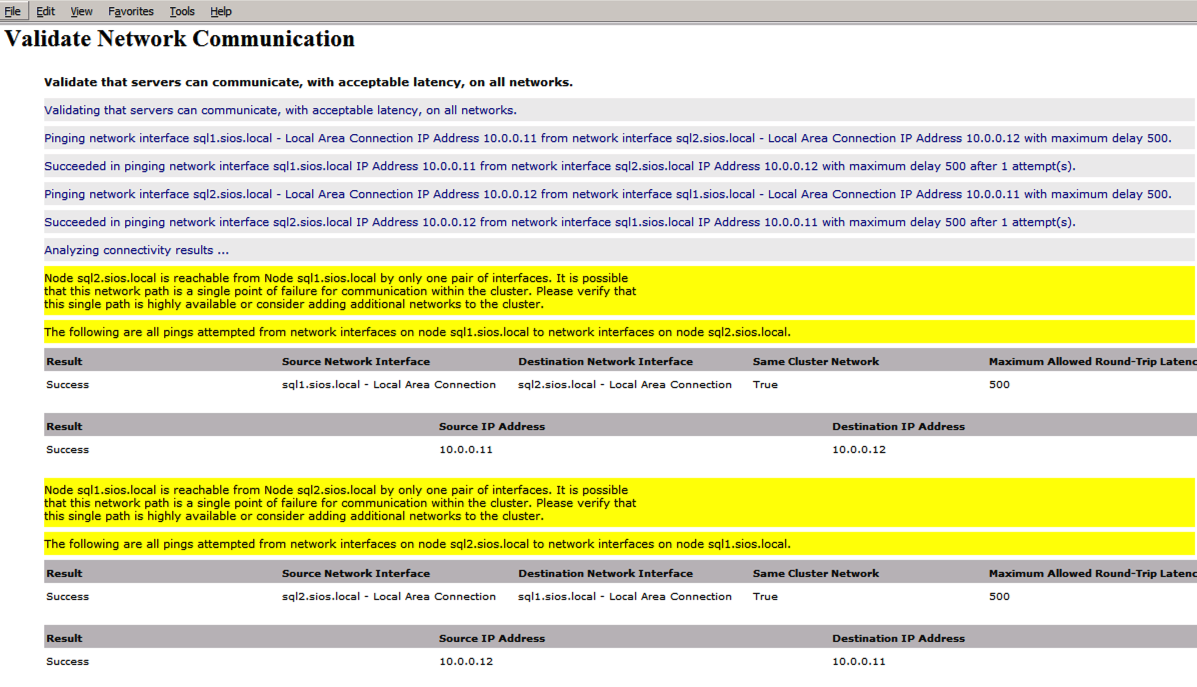
raport będzie zawierał Ostrzeżenia dotyczące pamięci masowej i sieci. Możesz zignorować te ostrzeżenia, ponieważ wiemy, że nie ma współdzielonych dysków i istnieje tylko jedno połączenie sieciowe między serwerami. Możesz również otrzymać ostrzeżenie o kolejności wiązania sieci, które również można zignorować. Jeśli napotkasz jakiekolwiek błędy, musisz je rozwiązać przed kontynuowaniem.
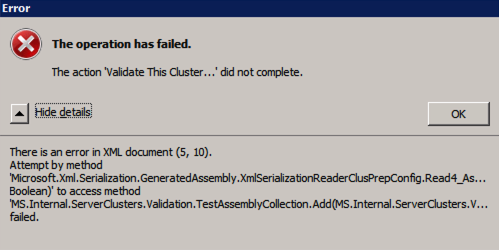
błąd próbuje uruchomić walidację klastra?
napotkałem ten błąd kilka razy i nadal próbuję ustalić, w jakich warunkach to występuje. Czasami okaże się, że klaster testowy nie działa zgodnie z opisem w poście na forum.
Test-ClusterUnable to Validate a Cluster Configuration. The operation has failed. The action validate a configuration did not completeThere is an error in XML document (5, 73). Attempt by methodMicrosoft.Xml.Serialzation.GeneratedAssembly.XmlSerialzationReaderClusterPrep.Config.Read4_As...Bolean) to access methodMS.Internal.ServerClusters.Validation.TestAssemblyCollection.Add(MS.Internal.ServerClusters.V....Failedjeśli tak się stanie, znalazłem następującą poprawkę zalecaną w poście na forum działa dla mnie.
Inside C:\Windows\System32\WindowsPowerShell\v1.0 make a copy of powershell_ise.exe.config file (make a copy inside C:\Windows\System32\WindowsPowerShell\v1.0)- rename it to powershell.exe.configOpen it with notepad- delete current config line and paste:<?xml version="1.0" encoding="utf-8" ?><configuration> <system.xml.serialization> <xmlSerializer useLegacySerializerGeneration="true"/> </system.xml.serialization></configuration>- save and run test-clusterchociaż ta poprawka pozwoli Ci uruchomić test-cluster z Powershell, odkryłem, że uruchamianie walidacji przez GUI nadal powoduje błąd, nawet przy tej poprawce. Mam zapytanie do Microsoftu, aby sprawdzić, czy mają rozwiązanie, ale na razie, jeśli chcesz uruchomić sprawdzanie poprawności klastra, być może będziesz musiał użyć Test-Cluster w Powershell.
Utwórz Klaster
najlepsze praktyki tworzenia klastra na platformie Azure polegają na użyciu Powershell do utworzenia klastra, określając statyczny adres IP. Powershell pozwala nam określić Statyczny adres IP, podczas gdy metoda GUI nie. Niestety implementacja DHCP platformy Azure nie działa dobrze z WSFC, więc jeśli użyjesz metody GUI, jako adres IP klastra pojawi się zduplikowany adres IP, który musi zostać naprawiony, zanim klaster zacznie działać.
jednak odkryłem, że typowe polecenie New-Cluster powershell z poleceniem-StaticAddress nie działa. Aby uniknąć problemu zduplikowanego adresu IP, musimy uciekać się do klastra.narzędzie exe i uruchom następujące polecenie.
cluster /cluster:cluster1 /create /nodes:"sql1 sql2" /ipaddress:10.0.0.100/255.255.255.0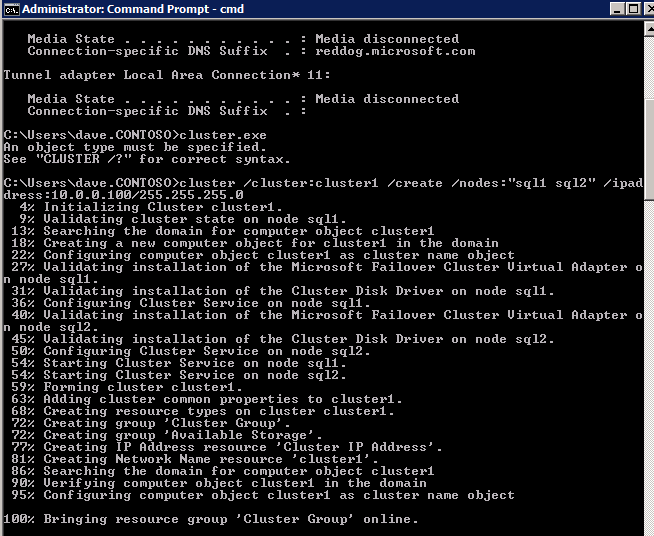
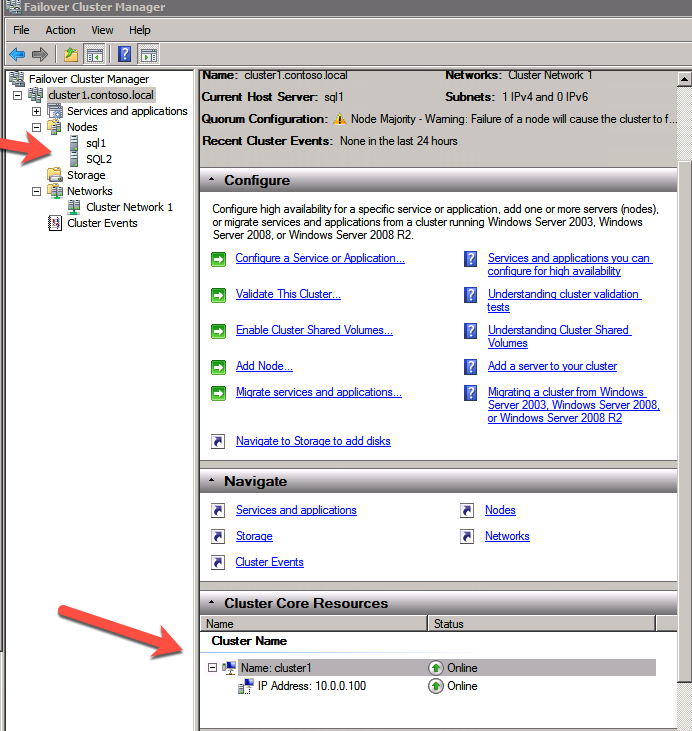
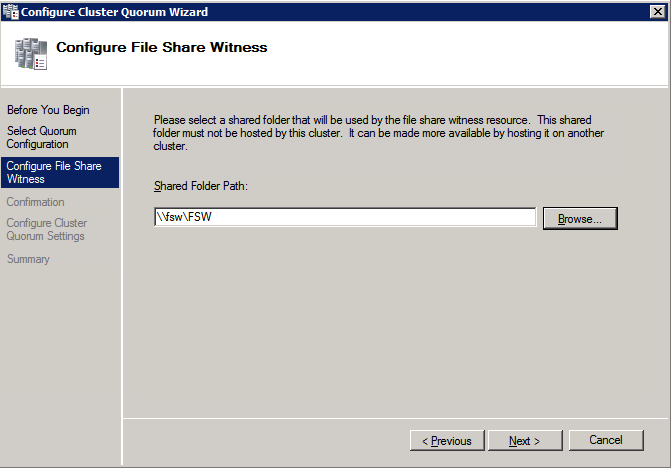
Add the File Share Witness
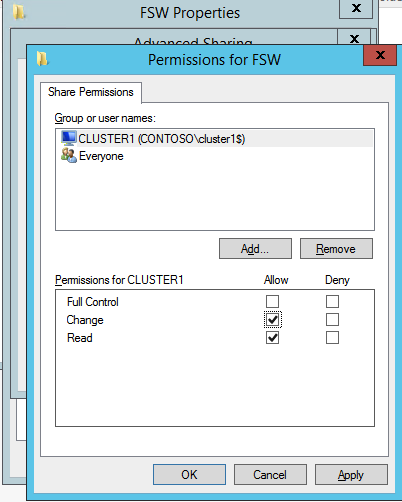
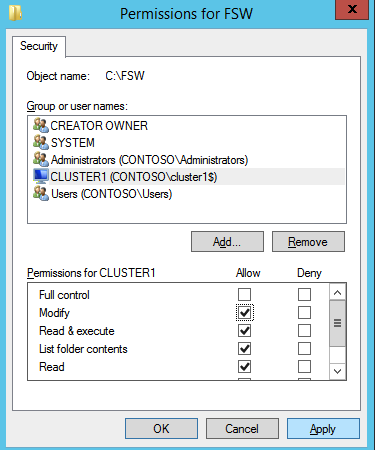
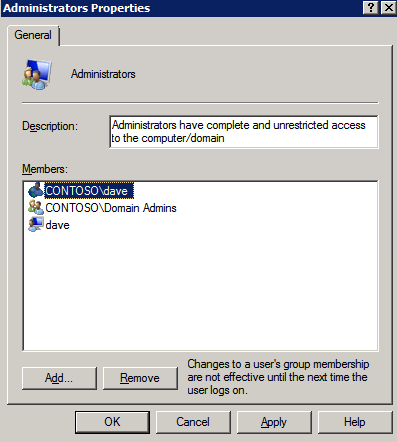
następnie musimy dodać File Share Witness. Na serwerze 3rd zapewniliśmy jako FSW, utwórz folder i udostępnij go, jak pokazano poniżej. Musisz przyznać uprawnienia do odczytu/zapisu obiektu Cluster Name Object (CNO) zarówno na poziomie udostępniania, jak i zabezpieczeń, jak pokazano poniżej.
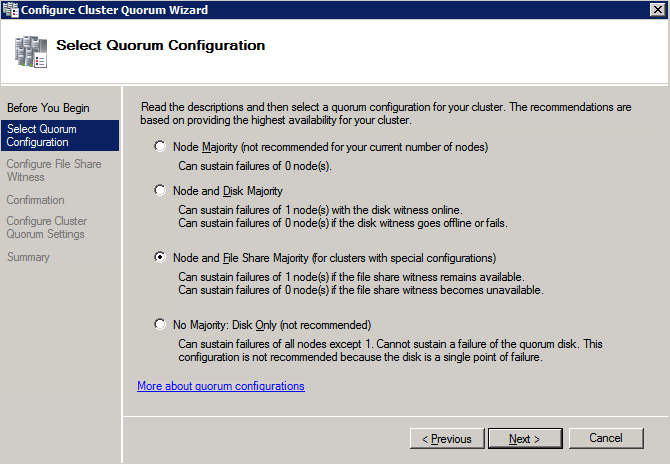
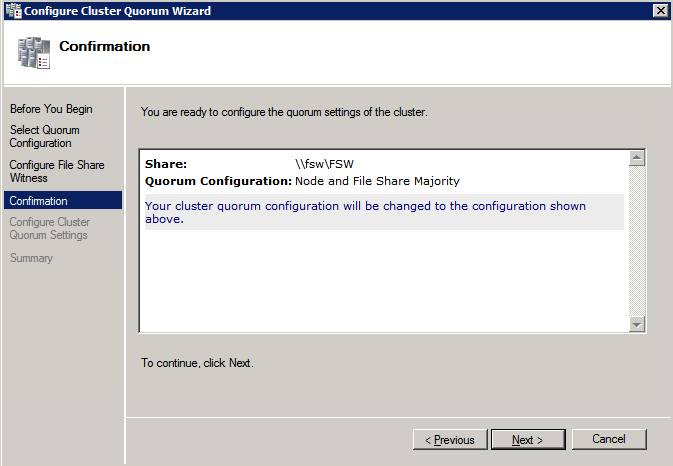
po utworzeniu udziału Uruchom Kreator konfiguracji kworum klastra na jednym z węzłów klastra i wykonaj kroki opisane poniżej.
zainstaluj DataKeeper
zainstaluj DataKeeper na każdym z dwóch węzłów klastra SQL Server, jak pokazano poniżej.
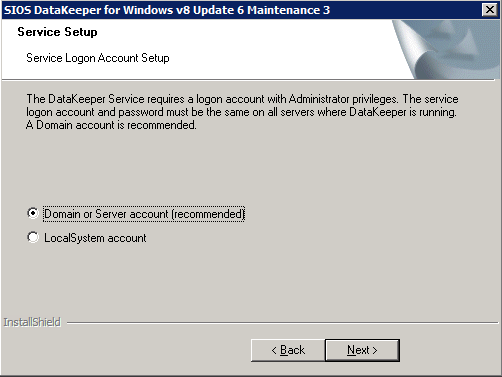
w tym miejscu określimy konto domeny, które dodaliśmy do każdej z lokalnych grup administratorów domen.
Skonfiguruj DataKeeper
po zainstalowaniu Datakeepera na każdym z dwóch węzłów klastra możesz skonfigurować DataKeeper.
Uwaga – najczęstszym błędem napotkanym w poniższych krokach jest związane z bezpieczeństwem, najczęściej przez istniejące wcześniej grupy zabezpieczeń platformy Azure blokujące wymagane porty. Zapoznaj się z dokumentacją SIOS, aby upewnić się, że serwery mogą komunikować się przez wymagane porty.
najpierw musisz połączyć się z każdym z dwóch węzłów.
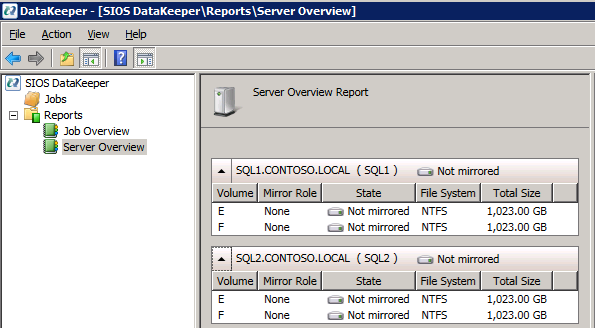
jeśli wszystko jest poprawnie skonfigurowane, powinieneś zobaczyć następujące informacje w raporcie przegląd serwera.
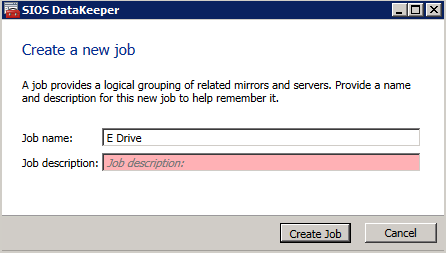
następnie utwórz nowe zadanie i wykonaj kroki opisane poniżej
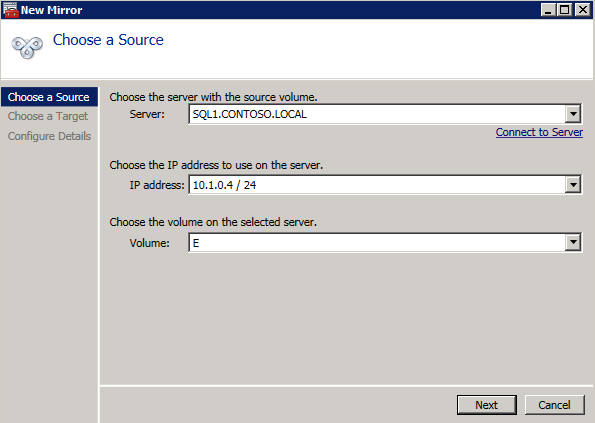
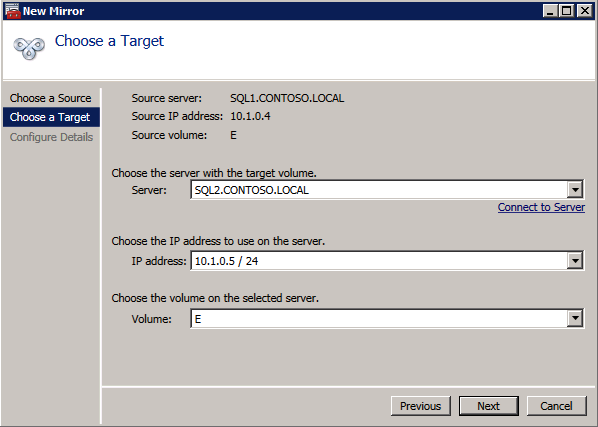
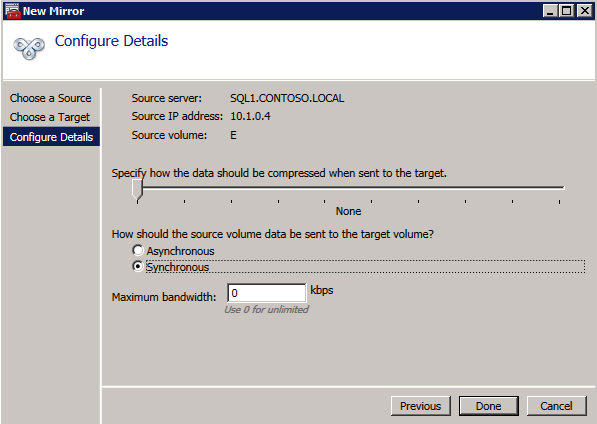
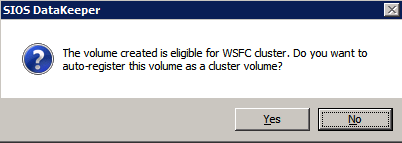
wybierz Tak tutaj, aby zarejestrować zasób woluminu DataKeeper w dostępnej pamięci masowej
wykonaj powyższe kroki dla każdego z tomów. Po zakończeniu powinieneś zobaczyć następujące elementy w interfejsie WSFC.
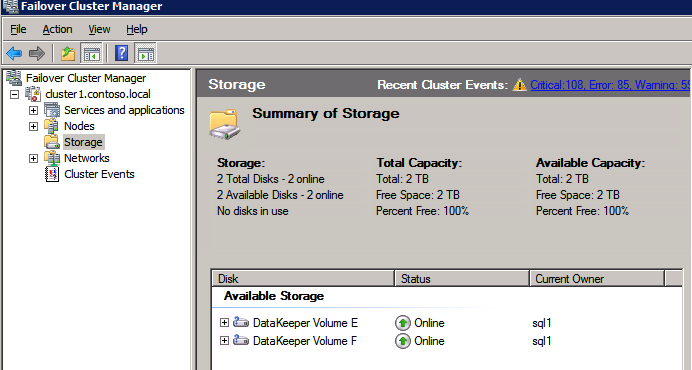
teraz możesz zainstalować SQL Server w klastrze.
uwaga – w tym momencie replikowany wolumin jest dostępny tylko w węźle, który obecnie obsługuje dostępną pamięć masową. Tego się spodziewamy, więc nie martw się!
zainstaluj SQL Server na pierwszym węźle
jeśli chcesz skryptować instalację, załączam poniższy przykład skryptowej instalacji klastra SQL Server 2008 R2 do pierwszego węzła klastra. Skrypt dodawania węzła do istniejącego klastra znajduje się w dalszej części przewodnika.
oczywiście dostosuj się do swojego otoczenia.
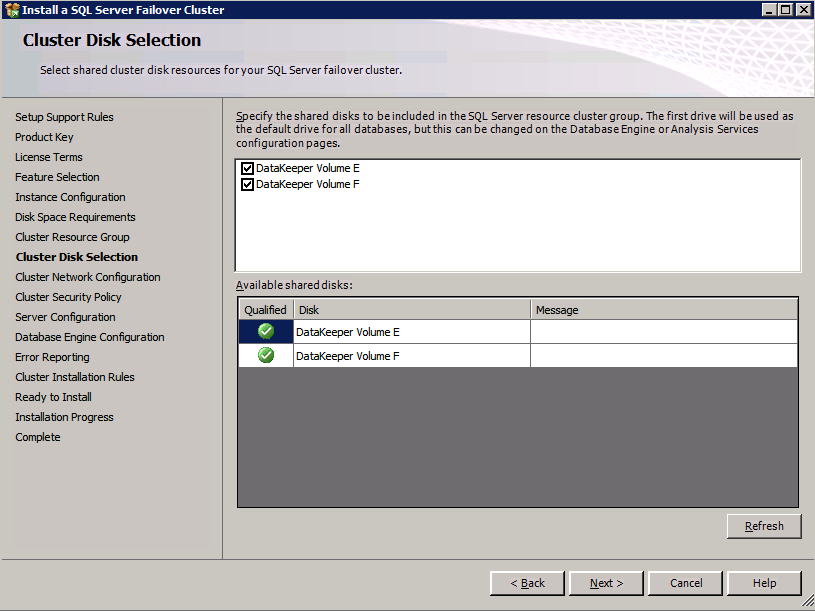
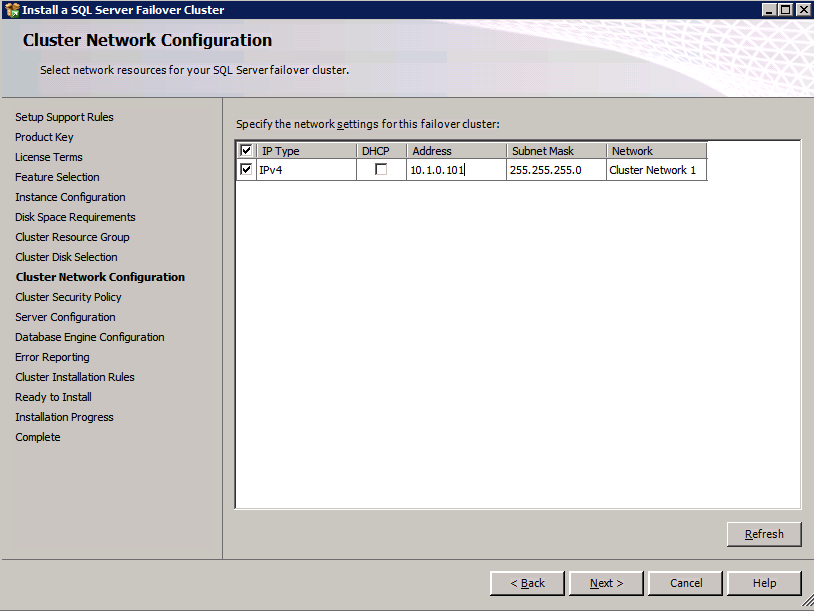
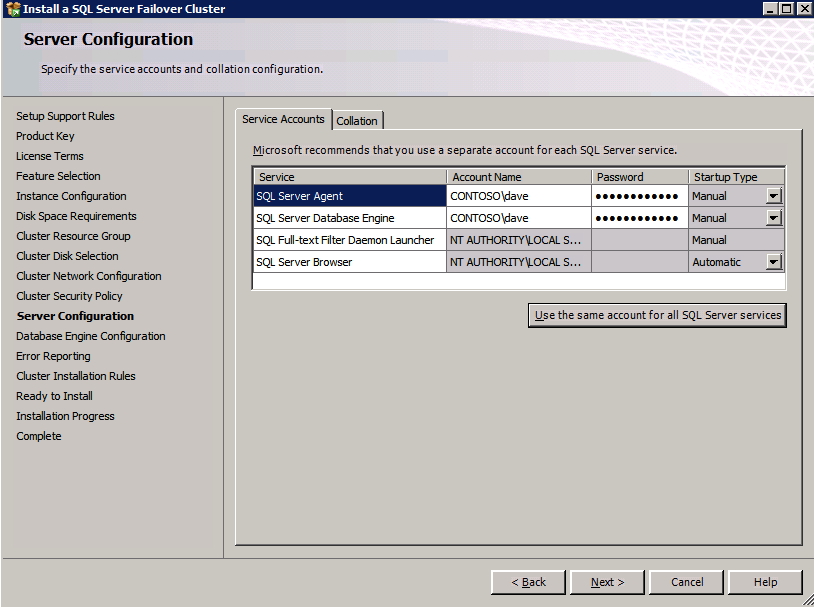
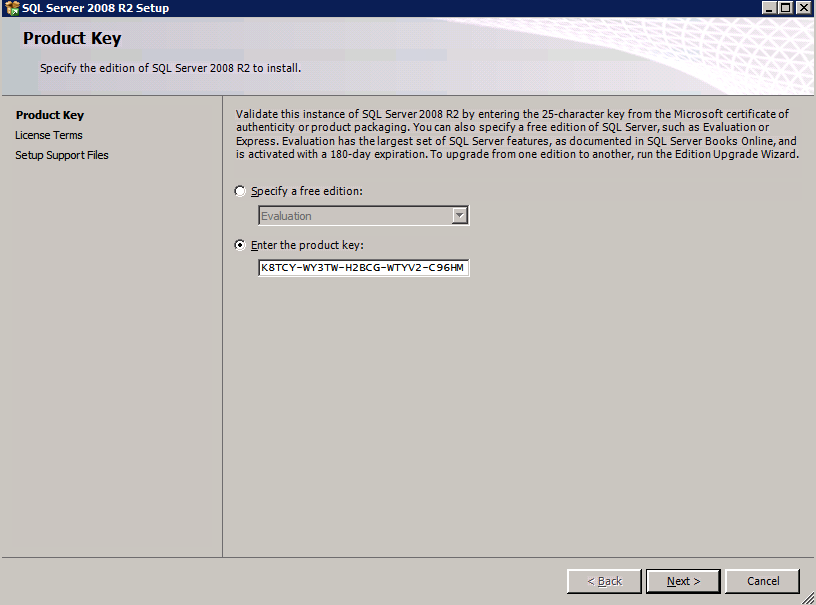
c:\SQLServerFull\setup.exe /q /ACTION=InstallFailoverCluster /FEATURES=SQL /INSTANCENAME="MSSQLSERVER" /INSTANCEDIR="C:\Program Files\Microsoft SQL Server" /INSTALLSHAREDDIR="C:\Program Files\Microsoft SQL Server" /SQLSVCACCOUNT="contoso\admin" /SQLSVCPASSWORD="xxxxxxxxx" /AGTSVCACCOUNT="contoso\admin" /AGTSVCPASSWORD="xxxxxxxxx" /SQLDOMAINGROUP="contoso\SQLAdmins" /AGTDOMAINGROUP="contoso\SQLAdmins" /SQLCOLLATION="SQL_Latin1_General_CP1_CI_AS" /FAILOVERCLUSTERGROUP="SQL Server 2008 R2 Group" /FAILOVERCLUSTERDISKS="DataKeeper Volume E" "DataKeeper Volume F" /FAILOVERCLUSTERIPADDRESSES="IPv4;10.0.0.101;Cluster Network 1;255.255.255.0" /FAILOVERCLUSTERNETWORKNAME="SQL2008Cluster" /SQLSYSADMINACCOUNTS="contoso\admin" /SQLUSERDBLOGDIR="E:\MSSQL10.MSSQLSERVER\MSSQL\Log" /SQLTEMPDBLOGDIR="F:\MSSQL10.MSSQLSERVER\MSSQL\Log" /INSTALLSQLDATADIR="F:\MSSQL10.MSSQLSERVER\MSSQLSERVER" /IAcceptSQLServerLicenseTermsjeśli wolisz używać GUI, po prostu postępuj zgodnie z poniższymi zrzutami ekranu.
na pierwszym węźle uruchom konfigurację SQL Server.
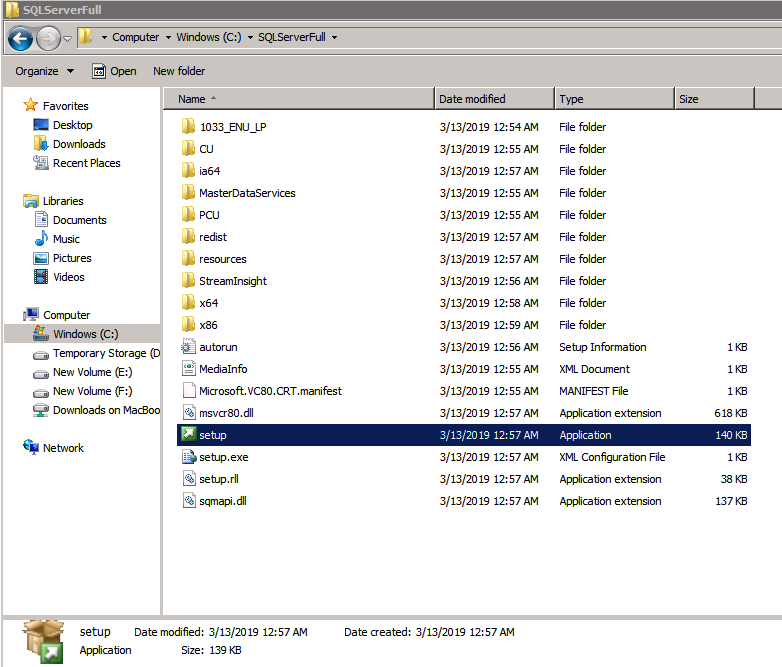
wybierz instalację nowego klastra pracy awaryjnej SQL Server i postępuj zgodnie z instrukcjami przedstawionymi na rysunku.
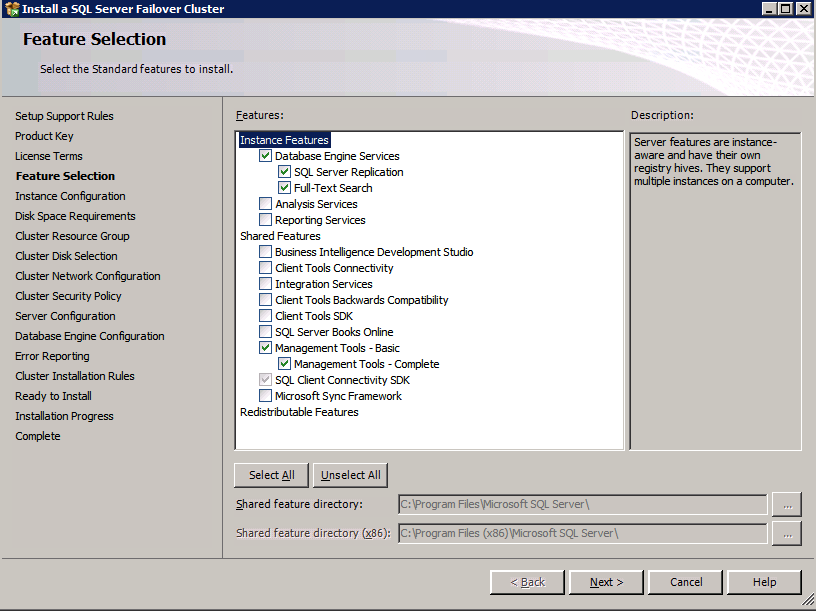
wybierz tylko opcje, których potrzebujesz.
proszę zauważyć, że ten dokument zakłada, że używasz domyślnej instancji SQL Server. Jeśli używasz instancji nazwanej, musisz zablokować port, na którym nasłuchuje, i użyć go później podczas konfigurowania Load balancera. Konieczne będzie również utworzenie reguły load balancer dla usługi przeglądarki SQL Server (UDP 1434), aby połączyć się z nazwaną instancją. Żaden z tych dwóch wymagań nie jest objęty tym przewodnikiem, ale jeśli potrzebujesz nazwanej instancji, będzie ona działać, jeśli wykonasz te dwa dodatkowe kroki.
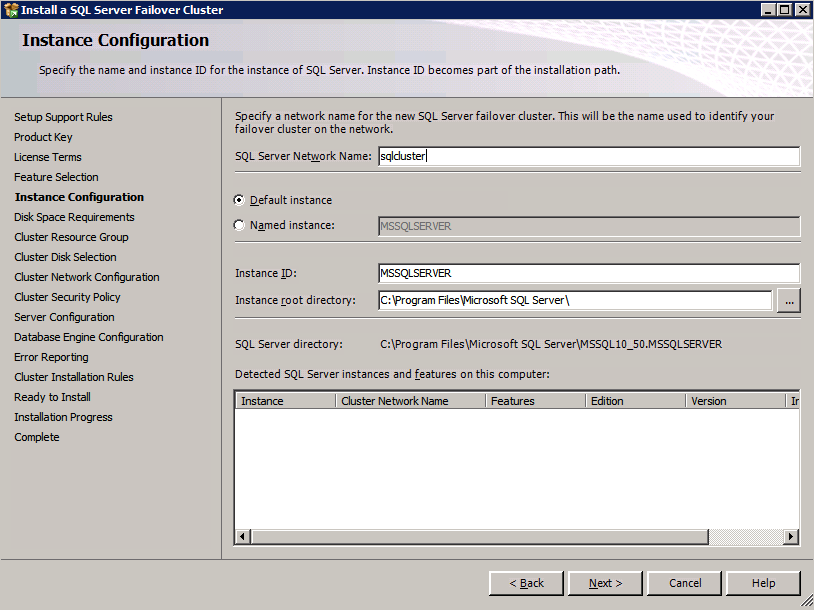
tutaj musisz podać nieużywany adres IP
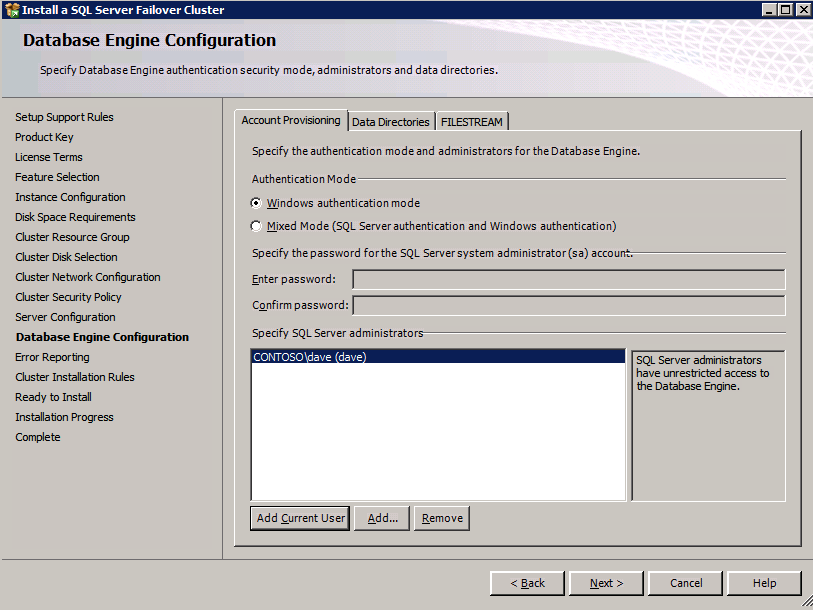
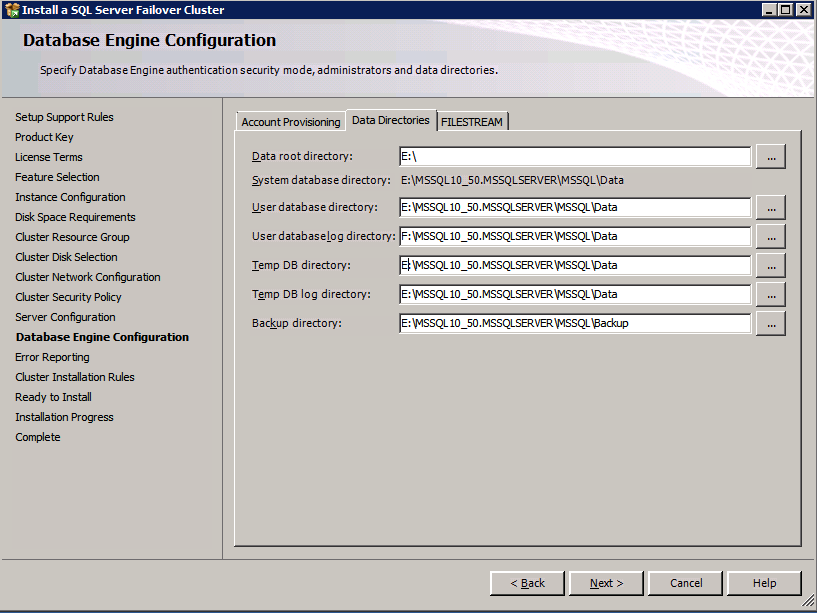
przejdź do zakładki katalogi danych i przenieś pliki danych i dzienników. Na końcu tego przewodnika mówimy o przeniesieniu tempdb do woluminu bez lustrzanego DataKeeper w celu uzyskania optymalnej wydajności. Na razie trzymaj to na jednym z dysków.
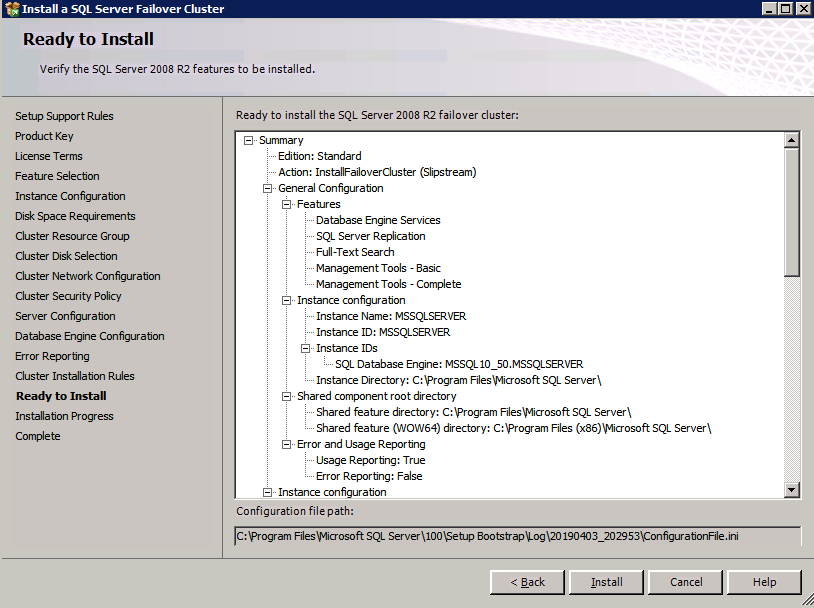
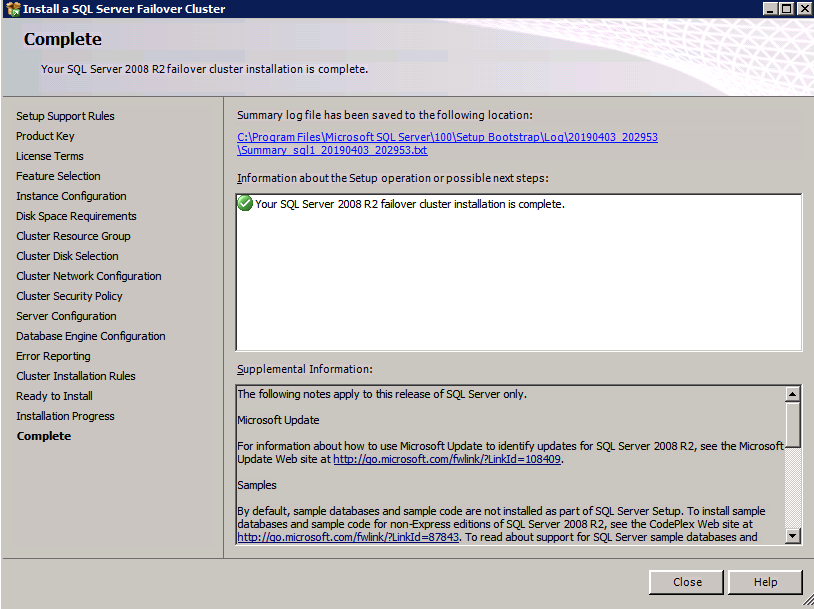
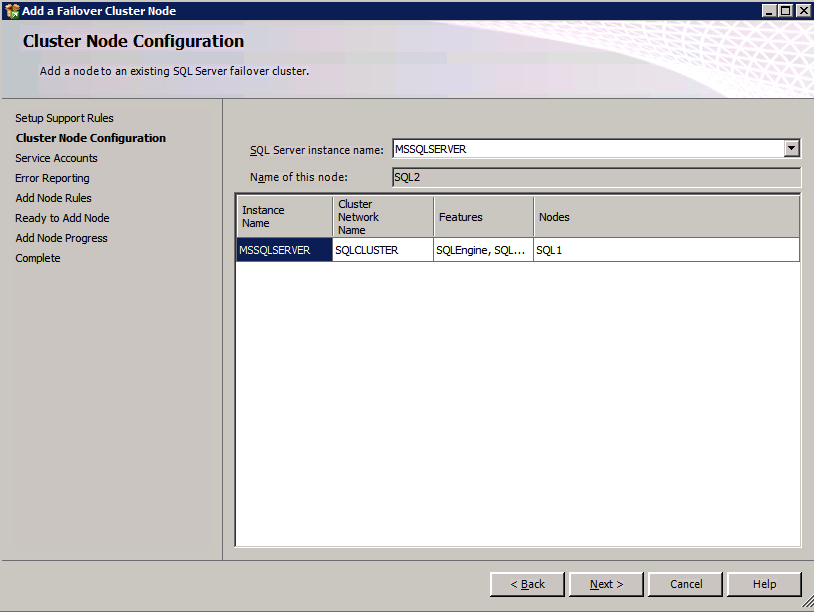
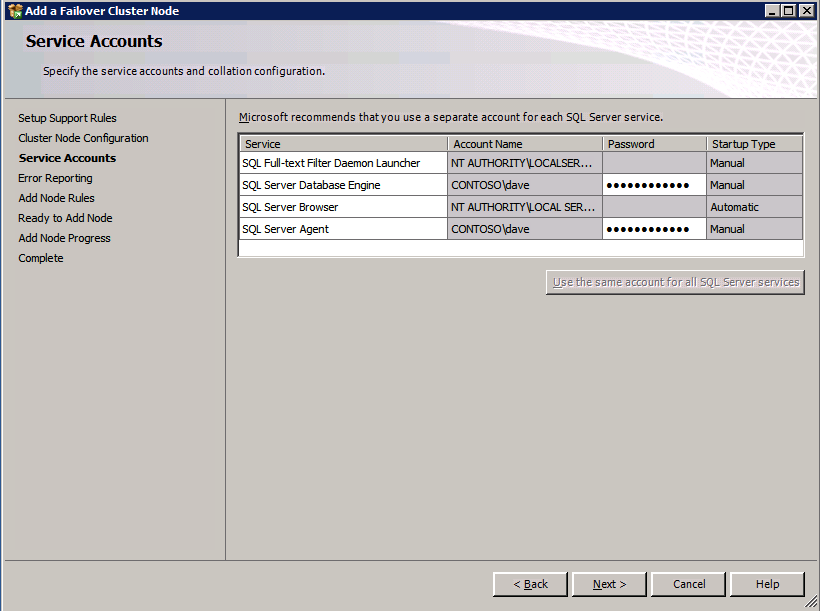
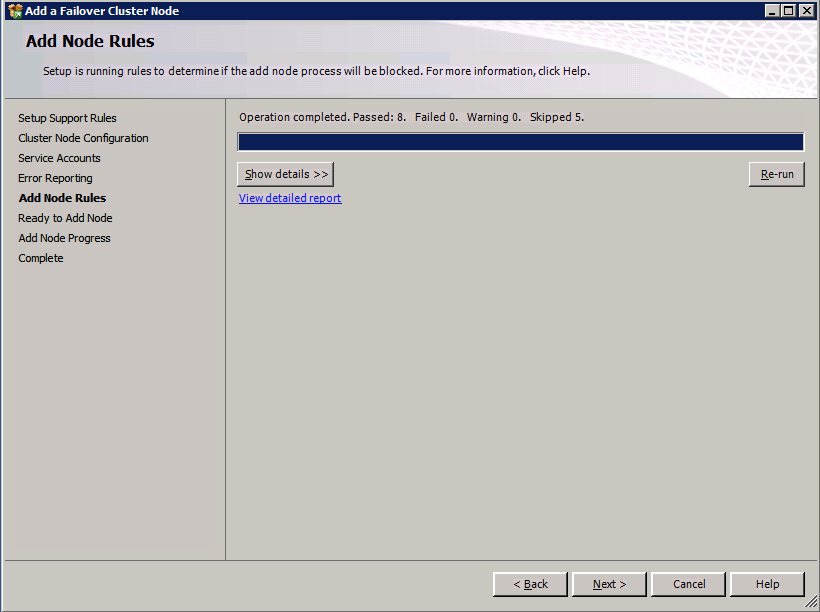
zainstaluj SQL Server na drugim węźle
Poniżej znajduje się przykład polecenia, które można uruchomić, aby dodać dodatkowy węzeł SQL Server 2008 R2 do istniejącego klastra.
c:\SQLServerFull\setup.exe /q /ACTION=AddNode /INSTANCENAME="MSSQLSERVER" /SQLSVCACCOUNT="contoso\admin" /SQLSVCPASSWORD="xxxxxxxxx" /AGTSVCACCOUNT="contoso\admin" /AGTSVCPASSWORD="xxxxxxxx" /IAcceptSQLServerLicenseTermsjeśli wolisz używać interfejsu graficznego, wykonaj poniższe zrzuty ekranu.
Uruchom ponownie konfigurację SQL Server na drugim węźle i wybierz Dodaj węzeł do klastra pracy awaryjnej SQL Server.
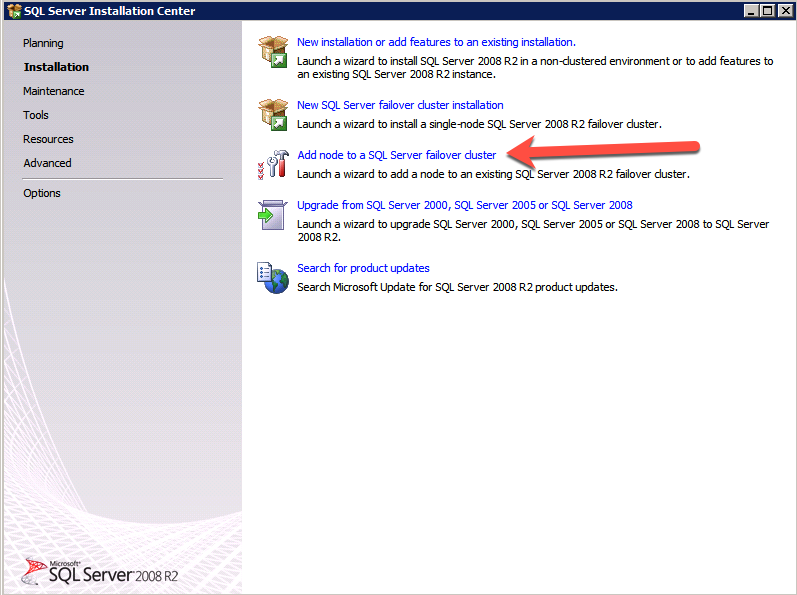
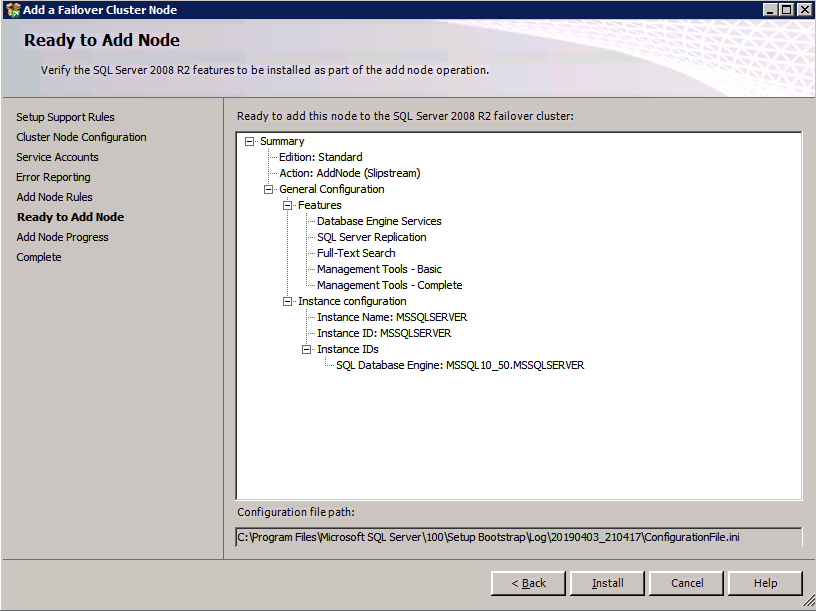
Congratulations prawie skończyłeś! Jednak ze względu na brak obsługi darmowego ARP platformy Azure, będziemy musieli skonfigurować wewnętrzny Load Balancer (ILB), aby pomóc w przekierowaniu klienta, jak pokazano w poniższych krokach.
zaktualizuj adres IP klastra SQL
aby ILB działał poprawnie, musisz uruchomić następujące polecenie z jednego z węzłów klastra. It SQL Cluster IP umożliwia adresowi IP klastra SQL reagowanie na sondę zdrowia ILB, jednocześnie ustawiając maskę podsieci na 255.255.255.255, aby uniknąć konfliktów adresu IP z sondą zdrowia.
cluster res <IPResourceName> /priv enabledhcp=0 address=<ILBIP> probeport=59999 subnetmask=255.255.255.255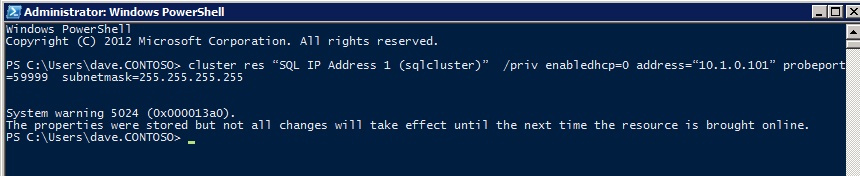
UWAGA-Nie wiem, czy to Fuks, ale czasami uruchamiałem to polecenie i wygląda na to, że działa, ale nie kończy pracy i muszę go uruchomić ponownie. Sposób, w jaki mogę stwierdzić, czy to działało, polega na spojrzeniu na maskę podsieci zasobu IP serwera SQL, jeśli nie jest to 255.255.255.255, to wiesz, że nie działa pomyślnie. Może to być prosty problem z odświeżaniem interfejsu graficznego, więc możesz również spróbować ponownie uruchomić interfejs graficzny klastra, aby sprawdzić, czy maska podsieci została zaktualizowana.
po pomyślnym uruchomieniu, zabierz zasób offline i przywróć go z powrotem do trybu online, aby zmiany weszły w życie.
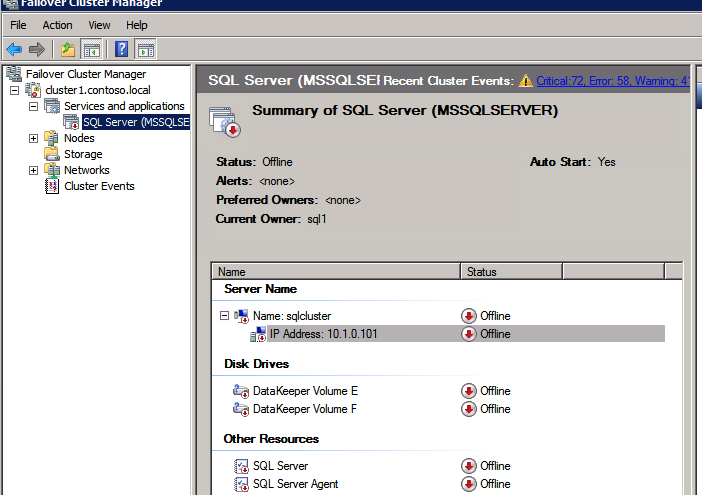
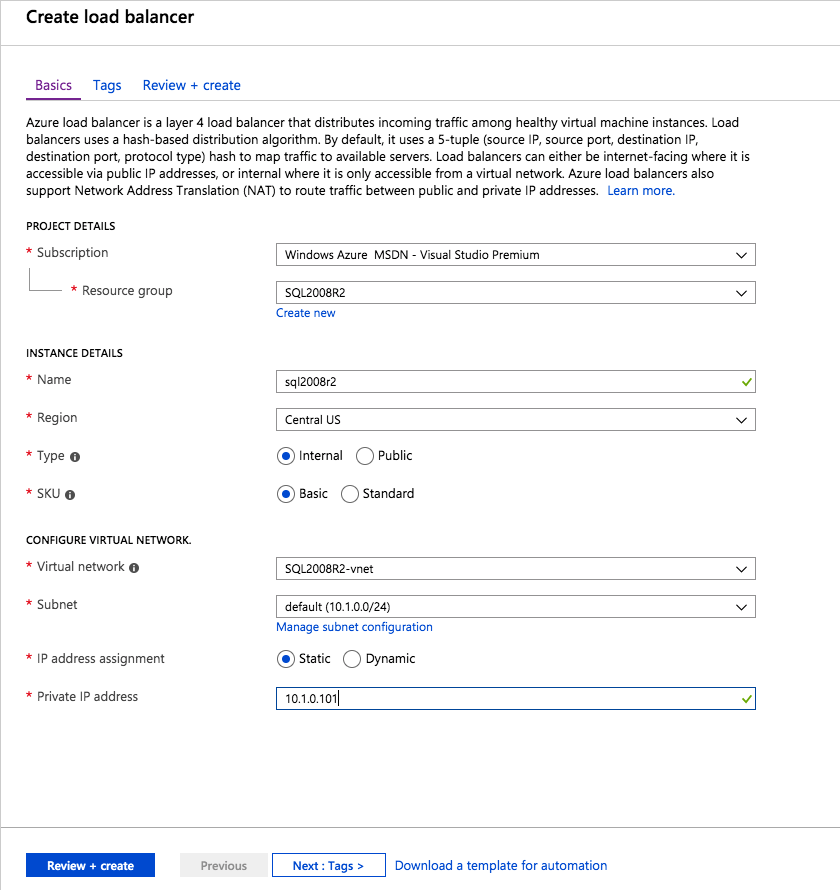
Utwórz Load balancer
ostatnim krokiem jest utworzenie Load balancera. W tym przypadku Zakładamy, że uruchamiasz domyślną instancję SQL Server, nasłuchującą na porcie 1433.
prywatny adres IP zdefiniowany podczas tworzenia Load balancera będzie dokładnie tym samym adresem, którego używa FCI serwera SQL.
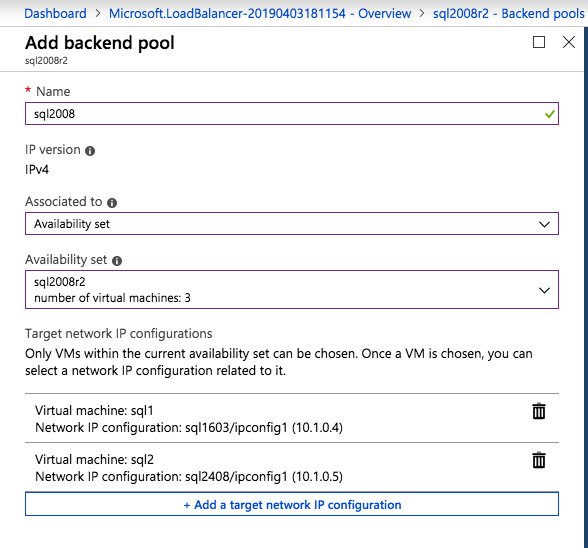
Dodaj tylko dwie instancje SQL Server do puli zaplecza. Nie dodawaj FSW do puli zaplecza.
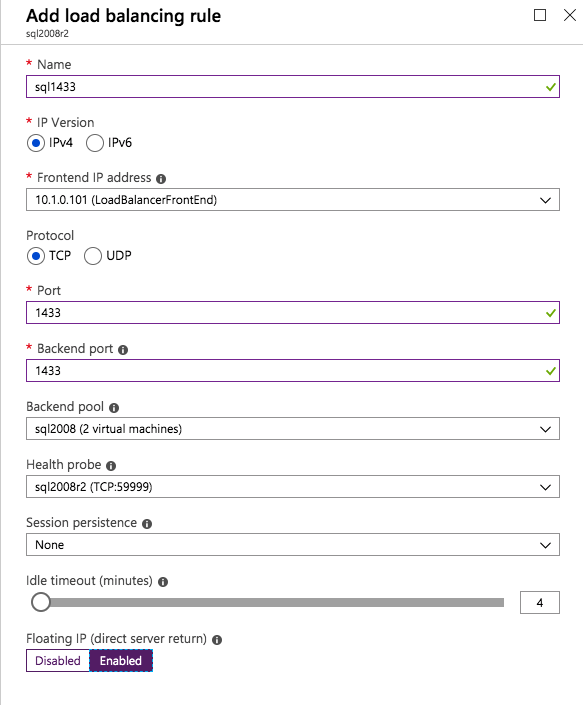
w tej regule load balancing musisz włączyć Floating IP
Sprawdź poprawność klastra
zanim przejdziesz dalej, Uruchom walidację klastra jeszcze raz. Raport walidacji klastra powinien zwracać te same ostrzeżenia dotyczące sieci i pamięci masowej, co przy pierwszym uruchomieniu. Zakładając, że nie ma nowych błędów lub ostrzeżeń, klaster jest poprawnie skonfigurowany.
Edytuj sqlserv.plik konfiguracyjny exe
w katalogu C:\Program Files (x86)\Microsoft SQL Server \ 100\Tools \ Binn stworzyliśmy sqlps.exe.plik konfiguracyjny i sqlservr.exe.konfiguracja z następującymi liniami w pliku konfiguracyjnym:
<configuration> <startup> <supportedRuntime version="v2.0.50727"/> </startup></configuration>pliki te domyślnie nie istnieją i mogą zostać utworzone. Jeśli ten plik(y) już istnieje dla Twojej instalacji, linia <supportedRuntime version=”v2.0.50727″/> po prostu musi być umieszczona w sekcji <startup>…</startup> w sekcji <konfiguracja>…</konfiguracja>. Należy to zrobić na obu serwerach.
Przetestuj Klaster
najprostszym testem jest otwarcie SQL Server Management Studio na pasywnym węźle i połączenie z klastrem. Jeśli jesteś w stanie połączyć, gratulacje, zrobiłeś wszystko poprawnie! Jeśli nie możesz się połączyć, nie bój się, nie będziesz pierwszą osobą, która popełni błąd. Napisałem artykuł na blogu, aby pomóc rozwiązać problem. Zarządzanie klastrem jest dokładnie takie samo jak zarządzanie tradycyjnym klastrem współdzielonej pamięci masowej. Wszystko jest kontrolowane przez Menedżera klastra przełączania awaryjnego.
Opcjonalnie – Przenieś Tempdb
aby uzyskać optymalną wydajność, zaleca się przeniesienie tempdb na lokalny, nie replikowany dysk SSD. Jednak SQL Server 2008 R2 wymaga, aby tempdb było na dysku klastrowym. SIOS ma rozwiązanie o nazwie Non-Mirrored Volume Resource, które rozwiązuje ten problem. Wskazane byłoby utworzenie zasobu woluminu bez lustrzanego na lokalnym dysku SSD i przeniesienie tam tempdb. Jednak lokalny dysk SSD nie jest trwały, więc należy zadbać o to, aby folder zawierający tempdb i uprawnienia do tego folderu były odtwarzane przy każdym ponownym uruchomieniu serwera.