Web krioelt van Python

web crawling is een krachtige techniek om gegevens te verzamelen van het web door het vinden van alle URL ‘ s voor een of meerdere domeinen. Python heeft verschillende populaire web crawling bibliotheken en frameworks.
in dit artikel zullen we eerst verschillende crawling strategieën en use cases introduceren. Dan bouwen we een eenvoudige webcrawler vanuit het niets in Python met behulp van twee bibliotheken: requests en Beautiful Soup. Vervolgens zullen we zien waarom het beter is om een web crawling framework zoals Scrapy te gebruiken. Tot slot bouwen we een voorbeeld crawler met Scrapy om film metadata van IMDb te verzamelen en te zien hoe Scrapy schaalt naar websites met enkele miljoenen pagina ‘ s.
Wat is een webcrawler?
webcrawling en web scraping zijn twee verschillende, maar verwante concepten. Web crawling is een onderdeel van web scraping, de crawler logica vindt URL ‘ s worden verwerkt door de scraper code.
een webcrawler begint met een lijst met URL ‘ s die u wilt bezoeken, genaamd de seed. Voor elke URL vindt de crawler links in de HTML, filtert die links op basis van enkele criteria en voegt de nieuwe links toe aan een wachtrij. Alle HTML of bepaalde specifieke informatie wordt geëxtraheerd om te worden verwerkt door een andere pijplijn.
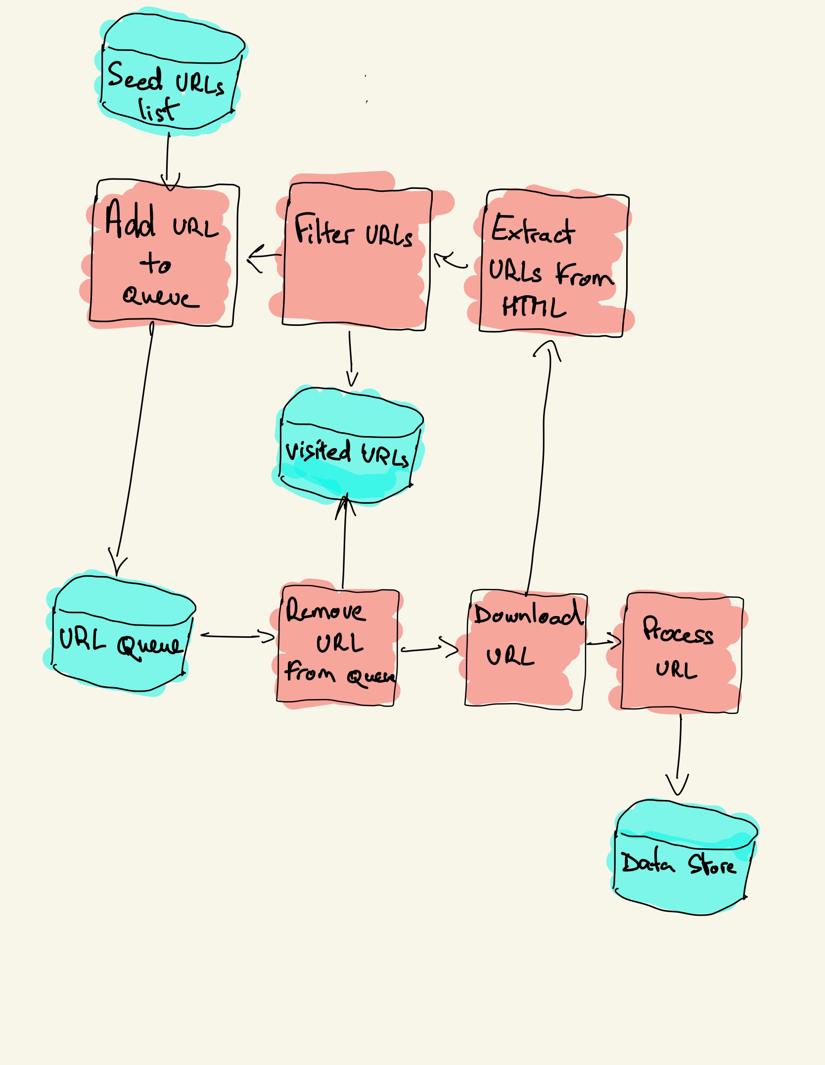
web crawling strategieën
in de praktijk bezoeken web crawlers slechts een deel van de pagina ‘s, afhankelijk van het crawler budget, wat een maximum aantal pagina’ s per domein, diepte of uitvoertijd kan zijn.
de meest populaire websites bieden een robot.txt-bestand om aan te geven welke delen van de website niet mogen worden doorzocht door elke user agent. Het tegenovergestelde van het robots-bestand is de sitemap.xml-bestand, dat een lijst van de pagina ‘ s die kunnen worden gekropen.
populaire gebruikssituaties voor webcrawlers zijn::
- zoekmachines (Googlebot, Bingbot, Yandex Bot…) verzamelen alle HTML voor een aanzienlijk deel van het Web. Deze gegevens worden geïndexeerd om ze doorzoekbaar te maken.
- SEO analytics tools verzamelen naast het verzamelen van de HTML ook metadata zoals de responstijd, responsstatus om gebroken pagina ‘ s te detecteren en de koppelingen tussen verschillende domeinen om backlinks te verzamelen.
- tools voor Prijsbewaking doorzoek websites voor e-commerce om productpagina ‘ s te vinden en metagegevens te extraheren, met name de prijs. Productpagina ‘ s worden dan periodiek opnieuw bekeken.
- Common Crawl onderhoudt een open repository van web crawl data. Zo bevat het archief van oktober 2020 2,71 miljard webpagina ‘ s.
vervolgens zullen we drie verschillende strategieën vergelijken voor het bouwen van een webcrawler in Python. Eerst alleen standaardbibliotheken gebruiken, dan bibliotheken van derden voor het maken van HTTP-verzoeken en het ontleden van HTML en tenslotte een web crawling framework.
een eenvoudige webcrawler vanuit het niets bouwen
om een eenvoudige webcrawler in Python te bouwen hebben we minstens één bibliotheek nodig om de HTML van een URL te downloaden en een HTML-parsingbibliotheek om links te extraheren. Python biedt standaard bibliotheken urllib voor het maken van HTTP-verzoeken en html.parser voor het ontleden van HTML. Een voorbeeld Python crawler alleen gebouwd met standaard bibliotheken kan worden gevonden op Github.
de standaard Python-bibliotheken voor verzoeken en HTML-parsing zijn niet erg ontwikkelaarvriendelijk. Andere populaire bibliotheken zoals requests, gebrandmerkt als HTTP voor mensen, en Beautiful Soup bieden een betere ontwikkelaar ervaring.
als u meer wilt weten, kunt u deze handleiding raadplegen over de beste Python HTTP client.
u kunt de twee bibliotheken lokaal installeren.
pip install requests bs4een basis crawler kan worden gebouwd volgens het vorige architectuurdiagram.
import loggingfrom urllib.parse import urljoinimport requestsfrom bs4 import BeautifulSouplogging.basicConfig( format='%(asctime)s %(levelname)s:%(message)s', level=logging.INFO)class Crawler: def __init__(self, urls=): self.visited_urls = self.urls_to_visit = urls def download_url(self, url): return requests.get(url).text def get_linked_urls(self, url, html): soup = BeautifulSoup(html, 'html.parser') for link in soup.find_all('a'): path = link.get('href') if path and path.startswith('/'): path = urljoin(url, path) yield path def add_url_to_visit(self, url): if url not in self.visited_urls and url not in self.urls_to_visit: self.urls_to_visit.append(url) def crawl(self, url): html = self.download_url(url) for url in self.get_linked_urls(url, html): self.add_url_to_visit(url) def run(self): while self.urls_to_visit: url = self.urls_to_visit.pop(0) logging.info(f'Crawling: {url}') try: self.crawl(url) except Exception: logging.exception(f'Failed to crawl: {url}') finally: self.visited_urls.append(url)if __name__ == '__main__': Crawler(urls=).run()de code hierboven definieert een Crawler class met helper methoden om te download_url met behulp van de requests library, get_linked_urls met behulp van de Beautiful Soup library en add_url_to_visit om URL ‘ s te filteren. De te bezoeken URL ’s en de bezochte URL’ s worden opgeslagen in twee aparte lijsten. Je kunt de crawler op je terminal draaien.
python crawler.pyde crawler registreert een regel voor elke bezochte URL.
2020-12-04 18:10:10,737 INFO:Crawling: https://www.imdb.com/2020-12-04 18:10:11,599 INFO:Crawling: https://www.imdb.com/?ref_=nv_home2020-12-04 18:10:12,868 INFO:Crawling: https://www.imdb.com/calendar/?ref_=nv_mv_cal2020-12-04 18:10:13,526 INFO:Crawling: https://www.imdb.com/list/ls016522954/?ref_=nv_tvv_dvd2020-12-04 18:10:19,174 INFO:Crawling: https://www.imdb.com/chart/top/?ref_=nv_mv_2502020-12-04 18:10:20,624 INFO:Crawling: https://www.imdb.com/chart/moviemeter/?ref_=nv_mv_mpm2020-12-04 18:10:21,556 INFO:Crawling: https://www.imdb.com/feature/genre/?ref_=nv_ch_grde code is zeer eenvoudig, maar er zijn veel prestaties en usability problemen op te lossen voordat met succes kruipen een complete website.
- de crawler is traag en ondersteunt geen parallellisme. Zoals te zien is aan de tijdstempels, duurt het ongeveer een seconde om elke URL te doorzoeken. Elke keer dat de crawler een verzoek doet, wacht het tot het verzoek is opgelost en er wordt geen werk gedaan tussendoor.
- de download URL logica heeft geen retry mechanisme, de URL wachtrij is geen echte wachtrij en niet erg efficiënt met een groot aantal URL ‘ s.
- de koppeling extractie logica ondersteunt niet het standaardiseren van URL ’s door het verwijderen van URL query string parameters, verwerkt geen URL’ s beginnend met #, ondersteunt niet het filteren van URL ‘ s per domein of het filteren van verzoeken naar statische bestanden.
- de crawler identificeert zichzelf niet en negeert de robots.txt-bestand.
hierna zullen we zien hoe Scrapy al deze functionaliteiten biedt en het gemakkelijk maakt om uit te breiden voor uw custom crawls.
web kruipen met Scrapy
Scrapy is het meest populaire web schrapen en kruipen Python framework met 40k sterren op Github. Een van de voordelen van Scrapy is dat aanvragen asynchroon worden gepland en behandeld. Dit betekent dat Scrapy nog een aanvraag kan sturen voordat de vorige is voltooid of er tussendoor nog wat werk kan doen. Scrapy kan veel gelijktijdige verzoeken verwerken, maar kan ook worden geconfigureerd om de websites met aangepaste instellingen te respecteren, zoals we later zullen zien.Scrapy heeft een architectuur met meerdere componenten. Normaal gesproken zul je ten minste twee verschillende klassen implementeren: Spider en Pipeline. Web scraping kan worden gezien als een ETL waar u gegevens uit het web te halen en te laden in uw eigen opslag. Spiders extraheren de gegevens en pijpleidingen laden het in de opslag. Transformatie kan zowel in spiders als pijpleidingen gebeuren, maar ik raad je aan om een aangepaste Scrapy pijplijn in te stellen om elk item onafhankelijk van elkaar te transformeren. Op deze manier heeft het niet verwerken van een item geen effect op andere items.
daar bovenop kunt u spider en downloader middlewares tussen de componenten toevoegen, zoals te zien is in het onderstaande diagram.
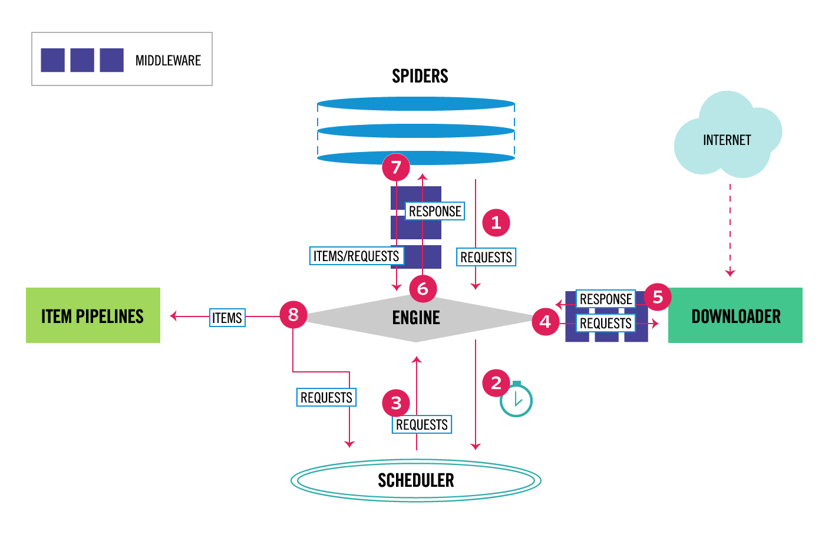
Scrapy Architecture Overview
Als u Scrapy eerder hebt gebruikt, weet u dat een web scraper is gedefinieerd als een klasse die erft van de basisspin-klasse en een parse-methode implementeert om elke reactie af te handelen. Als u nieuw bent bij Scrapy, kunt u dit artikel lezen voor eenvoudig schrapen met Scrapy.
from scrapy.spiders import Spiderclass ImdbSpider(Spider): name = 'imdb' allowed_domains = start_urls = def parse(self, response): passScrapy biedt ook verschillende generieke spider klassen: CrawlSpider, XMLFeedSpider, CSVFeedSpider en SitemapSpider. De CrawlSpider klasse erft van de base Spider klasse en biedt een extra regels attribuut om te bepalen hoe je een website te crawlen. Elke regel gebruikt een LinkExtractor om aan te geven welke links uit elke pagina worden geëxtraheerd. Vervolgens zullen we zien hoe elk van hen te gebruiken door het bouwen van een crawler voor IMDb, de Internet Movie Database.
bouwen van een voorbeeld Scrapy crawler voor IMDb
voordat ik IMDb probeerde te crawlen, controleerde ik IMDb robots.txt-bestand om te zien welke URL-paden zijn toegestaan. Het robots-bestand verbiedt slechts 26 paden voor alle user-agents. Scrapy leest de robots.txt-bestand vooraf en respecteert het wanneer de robotstxt_obey instelling is ingesteld op true. Dit is het geval voor alle projecten die gegenereerd worden met het Scrapy Commando startproject.
scrapy startproject scrapy_crawlerdit commando maakt een nieuw project met de standaard Scrapy project mappenstructuur.
scrapy_crawler/├── scrapy.cfg└── scrapy_crawler ├── __init__.py ├── items.py ├── middlewares.py ├── pipelines.py ├── settings.py └── spiders ├── __init__.pydan kun je een spin maken in scrapy_crawler/spiders/imdb.py met een regel om alle links te extraheren.
from scrapy.spiders import CrawlSpider, Rulefrom scrapy.linkextractors import LinkExtractorclass ImdbCrawler(CrawlSpider): name = 'imdb' allowed_domains = start_urls = rules = (Rule(LinkExtractor()),)je kunt de crawler in de terminal lanceren.
scrapy crawl imdb --logfile imdb.logu krijgt veel logs, waaronder een log voor elk verzoek. Ik merkte dat zelfs als we allowed_domains Instellen om alleen webpagina ’s te doorzoeken onder https://www.imdb.com, er Verzoeken waren naar externe domeinen, zoals amazon.com.
2020-12-06 12:25:18 DEBUG: Redirecting (302) to <GET https://www.amazon.com/b/?&node=5160028011&ref_=ft_iba> from <GET (https://www.imdb.com/whitelist-offsite?url=https%3A%2F%2Fwww.amazon.com%2Fb%2F%3F%26node%3D5160028011%26ref_%3Dft_iba&page-action=ft-iba&ref=ft_iba)>IMDb omleidt van URL’ s paden onder whitelist-offsite en whitelist naar externe domeinen. Er is een open Scrapy GitHub probleem dat laat zien dat externe URL ‘ s niet worden uitgefilterd wanneer de OffsiteMiddleware wordt toegepast voordat de RedirectMiddleware. Om dit probleem op te lossen, kunnen we de Link extractor configureren om URL ‘ s te weigeren die beginnen met twee reguliere expressies.
class ImdbCrawler(CrawlSpider): name = 'imdb' allowed_domains = start_urls = rules = ( Rule(LinkExtractor( deny=, )), )regel-en LinkExtractor-klassen ondersteunen verschillende argumenten om URL ‘ s uit te filteren. U kunt bijvoorbeeld specifieke URL-extensies negeren en het aantal dubbele URL ‘ s verminderen door query-strings te sorteren. Als u geen specifiek argument voor uw use case vindt, kunt u een aangepaste functie doorgeven aan process_links in LinkExtractor of process_values in regel.
IMDb heeft bijvoorbeeld twee verschillende URL ‘ s met dezelfde inhoud.
https://www.imdb.com/naam / nm1156914/
https://www.imdb.com/naam / nm1156914/?mode=desktop&ref_=m_ft_dsk
om het aantal crawled URL ’s te beperken, kunnen we alle query strings uit url’ s verwijderen met de url_query_cleaner functie uit de w3lib bibliotheek en deze gebruiken in process_links.
from w3lib.url import url_query_cleanerdef process_links(links): for link in links: link.url = url_query_cleaner(link.url) yield linkclass ImdbCrawler(CrawlSpider): name = 'imdb' allowed_domains = start_urls = rules = ( Rule(LinkExtractor( deny=, ), process_links=process_links), )nu we het aantal te verwerken aanvragen hebben beperkt, kunnen we een parse_item methode toevoegen om gegevens uit elke pagina te extraheren en deze door te geven aan een pijplijn om deze op te slaan. We kunnen bijvoorbeeld de hele reactie eruit halen.tekst om het te verwerken in een andere pijplijn of selecteer de HTML metadata. Om de HTML-metadata in de header-tag te selecteren kunnen we onze eigen XPATHs coderen, maar ik vind het beter om een bibliotheek te gebruiken, extruct, die alle metadata uit een HTML-pagina haalt. U kunt het installeren met pip install extract.
import refrom scrapy.linkextractors import LinkExtractorfrom scrapy.spiders import CrawlSpider, Rulefrom w3lib.url import url_query_cleanerimport extructdef process_links(links): for link in links: link.url = url_query_cleaner(link.url) yield linkclass ImdbCrawler(CrawlSpider): name = 'imdb' allowed_domains = start_urls = rules = ( Rule( LinkExtractor( deny=, ), process_links=process_links, callback='parse_item', follow=True ), ) def parse_item(self, response): return { 'url': response.url, 'metadata': extruct.extract( response.text, response.url, syntaxes= ), }ik stel de follow attribuut True zodat Scrapy volgt nog steeds alle links van elke reactie, zelfs als we een aangepaste parse methode. Ik heb ook extruct geconfigureerd om alleen open grafiek metadata en JSON-LD extraheren, een populaire methode voor het coderen van gekoppelde gegevens met behulp van JSON in het Web, gebruikt door IMDb. U kunt de crawler uitvoeren en items opslaan in JSON lines formaat naar een bestand.
scrapy crawl imdb --logfile imdb.log -o imdb.jl -t jsonlineshet uitvoerbestand imdb.jl bevat één regel voor elk gecrawled item. Bijvoorbeeld, de geëxtraheerde Open Graph metadata voor een film genomen van de <meta> tags in de HTML ziet er als volgt uit.
{ "url": "http://www.imdb.com/title/tt2442560/", "metadata": {"opengraph": , , , , , ] }]}}de JSON-LD voor een enkel item is te lang om in het artikel te worden opgenomen, hier is een voorbeeld van wat Scrapy uittrekt uit de <script type=”application/ld+json”> tag.
"json-ld": , "contentRating": "TV-MA", "actor": ... }]het onderzoeken van de logs, merkte ik een ander gemeenschappelijk probleem met crawlers. Door achtereenvolgens op filters te klikken, genereert de crawler URL ‘ s met dezelfde inhoud, alleen dat de filters in een andere volgorde werden toegepast.
https://www.imdb.com/naam/nm2900465 / videogallery / content_type-trailer / related_titles-tt0479468
https://www.imdb.com/name/nm2900465/videogallery/related_titles-tt0479468 / content_type-trailer
lang filter en zoek-url ’s is een moeilijk probleem dat gedeeltelijk kan worden opgelost door de lengte van URL’ s te beperken met een Scrapy-instelling, URLLENGTH_LIMIT.
ik gebruikte IMDb als voorbeeld om de basisprincipes van het bouwen van een webcrawler in Python te laten zien. Ik liet de crawler niet lang lopen omdat ik geen specifieke use case voor de data had. In het geval u specifieke gegevens van IMDb nodig hebt, kunt u de IMDb datasets project dat een dagelijkse export van IMDb gegevens en IMDbPY, een Python pakket voor het ophalen en beheren van de gegevens te controleren.
webcrawling op schaal
als u een grote website zoals IMDb probeert te crawlen, met meer dan 45M pagina ‘ s gebaseerd op Google, is het belangrijk om verantwoord te crawlen door de volgende instellingen te configureren. U kunt uw crawler identificeren en contactgegevens opgeven in de BOT_NAME instelling. Om de druk die u op de websiteservers zet te beperken kunt u de DOWNLOAD_DELAY verhogen, de CONCURRENT_REQUESTS_PER_DOMAIN beperken of autothrottle_enabled instellen die deze instellingen dynamisch aanpast op basis van de responstijden van de server.
merk op dat Scrapy crawls standaard zijn geoptimaliseerd voor een enkel domein. Als u meerdere domeinen kruipt, controleert u deze instellingen om te optimaliseren voor brede crawls, inclusief het wijzigen van de standaard crawl order van depth-first naar breath-first. Om uw crawl budget te beperken, kunt u het aantal aanvragen beperken met de CLOSESPIDER_PAGECOUNT instelling van de close spider extensie.
met de standaardinstellingen kruipt Scrapy ongeveer 600 pagina ‘ s per minuut voor een website zoals IMDb. Om 45M pagina ‘ s te doorzoeken duurt het meer dan 50 dagen voor een enkele robot. Als u meerdere websites moet crawlen, kan het beter zijn om afzonderlijke crawlers te lanceren voor elke grote website of groep websites. Als u geïnteresseerd bent in gedistribueerde webcrawls, kunt u lezen hoe een ontwikkelaar gekropen 250M pagina ‘ s met Python in 40 uur met behulp van 20 Amazon EC2 machine instances.
in sommige gevallen kunt u websites tegenkomen die vereisen dat u JavaScript-code uitvoert om alle HTML weer te geven. Als u dit niet doet, mag u niet alle links op de website verzamelen. Omdat het tegenwoordig heel gebruikelijk is voor websites om inhoud dynamisch te maken in de browser schreef ik een Scrapy middleware voor het renderen van JavaScript pagina ‘ s met behulp van ScrapingBee API.
conclusie
we vergeleken de code van een Python crawler met behulp van bibliotheken van derden voor het downloaden van URL ‘ s en het ontleden van HTML met een crawler gebouwd met behulp van een populair web crawling framework. Scrapy is een zeer performante web crawling framework en het is gemakkelijk uit te breiden met uw aangepaste code. Maar je moet alle plaatsen weten waar je je eigen code kunt haken en de instellingen voor elk onderdeel.
Scrapy correct configureren wordt nog belangrijker wanneer websites met miljoenen pagina ‘ s worden doorzocht. Als u meer wilt leren over Web crawlen ik stel voor dat u een populaire website te kiezen en proberen om het te kruipen. U zult zeker nieuwe problemen tegenkomen, wat het onderwerp fascinerend maakt!