파이썬으로 웹 크롤링

웹 크롤링은 하나 또는 여러 도메인에 대한 모든 링크를 찾아 웹에서 데이터를 수집하는 강력한 기술입니다. 파이썬에는 몇 가지 인기있는 웹 크롤링 라이브러리와 프레임 워크가 있습니다.
이 기사에서는 먼저 다양한 크롤링 전략과 사용 사례를 소개합니다. 요청과 아름다운 수프:그럼 우리는 두 개의 라이브러리를 사용하여 파이썬에서 처음부터 간단한 웹 크롤러를 구축 할 것입니다. 이 긁힌 자국과 같은 웹 크롤링 프레임 워크를 사용하는 것이 좋습니다 왜 다음,우리는 볼 수 있습니다. 마지막으로,우리는 영화 메타 데이터를 수집하고 수백만 페이지의 웹 사이트로 어떻게 확장되는지 볼 수있는 크롤러를 구축 할 것입니다.
웹 크롤러란?
웹 크롤링 및 웹 스크래핑은 서로 다르지만 관련된 두 가지 개념입니다. 웹 크롤링은 웹 스크래핑의 구성 요소이며 크롤러 논리는 스크레이퍼 코드에 의해 처리 될 주소를 찾습니다.
웹 크롤러는 방문 할 사이트 목록으로 시작합니다. 크롤러는 특정 기준에 따라 링크를 필터링하고 큐에 새 링크를 추가합니다. 다른 파이프라인에 의해 처리되도록 추출됩니다.
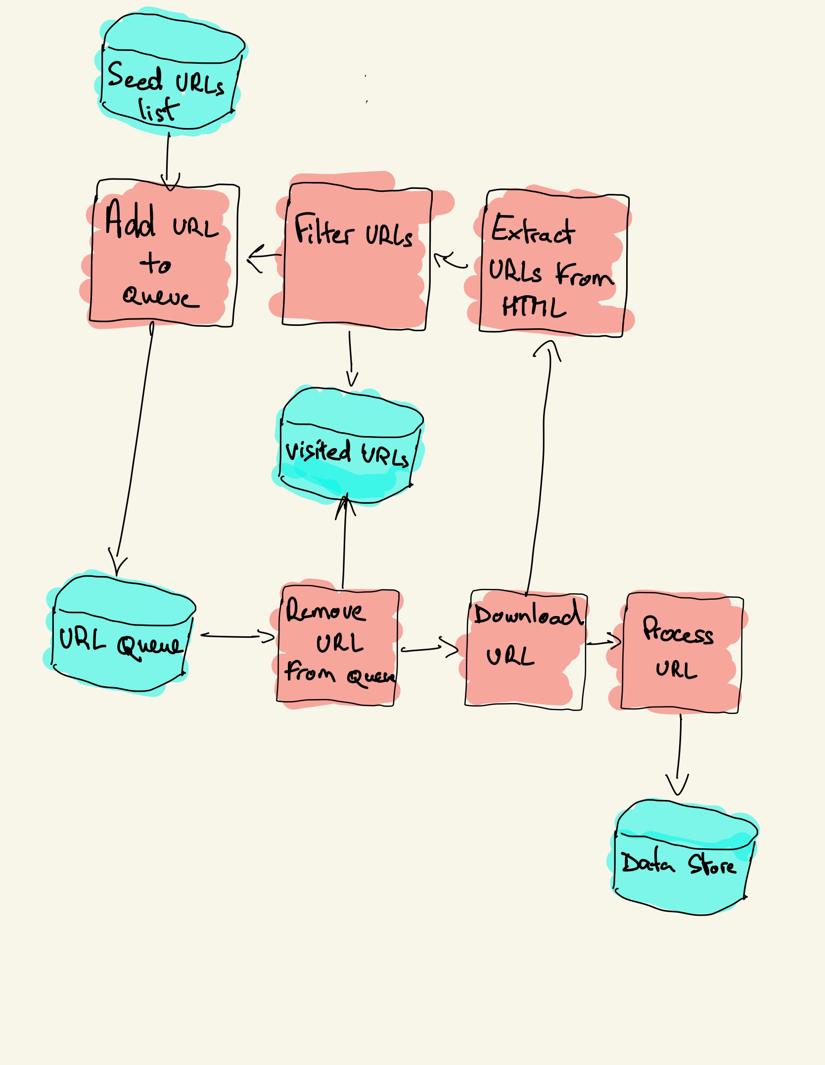
웹 크롤링 전략
실제로 웹 크롤러는 크롤러 예산에 따라 페이지의 하위 집합만 방문하며,이는 도메인당 최대 페이지 수,깊이 또는 실행 시간이 될 수 있습니다.
가장 인기있는 웹 사이트는 로봇을 제공합니다.각 사용자 에이전트에서 크롤링할 수 없는 웹 사이트의 영역을 나타내는 파일입니다. 로봇 파일의 반대는 사이트 맵입니다.크롤링할 수 있는 페이지를 나열합니다.
인기있는 웹 크롤러 사용 사례는 다음과 같습니다:
- 검색 엔진(구글 봇,빙봇,얀 덱스 봇…)은 웹의 상당 부분을 위해 모든 웹 페이지를 수집합니다. 이 데이터는 검색 할 수 있도록 인덱싱됩니다.
- 검색 엔진 최적화 분석 도구는 또한 응답 시간,깨진 페이지를 감지하는 응답 상태 및 뒤로 링크를 수집하는 다른 도메인 간의 링크와 같은 메타 데이터를 수집합니다.
- 가격 모니터링 도구는 전자 상거래 웹 사이트를 크롤링하여 제품 페이지를 찾고 메타 데이터,특히 가격을 추출합니다. 그런 다음 제품 페이지를 정기적으로 다시 방문합니다.
- 공통 크롤링은 웹 크롤링 데이터의 열린 저장소를 유지 관리합니다. 예를 들어,2020 년 10 월의 아카이브에는 27 억 1 천만 개의 웹 페이지가 포함되어 있습니다.
다음으로,우리는 파이썬에서 웹 크롤러를 구축하기 위한 세 가지 전략을 비교할 것이다. 먼저 표준 라이브러리 만 사용한 다음 타사 라이브러리를 사용하여 웹 크롤링 프레임 워크를 구문 분석합니다.
처음부터 파이썬에서 간단한 웹 크롤러 구축
파이썬에서 간단한 웹 크롤러를 구축하려면 적어도 하나의 라이브러리가 필요합니다. 이 라이브러리는 그러한 문제를 표준화된 프로그래밍 인터페이스를 제공함으로써 해결합니다.구문 분석을위한 파서. 표준 라이브러리로 만 구축 된 예제 파이썬 크롤러는 깃허브에서 찾을 수 있습니다.이 라이브러리는 특정 실행 프로세스에서 불러오거나 실행될 수 있습니다 요청과 같은 다른 인기있는 라이브러리,인간을위한 웹 사이트로 브랜드,아름다운 수프는 더 나은 개발자 경험을 제공합니다.
당신이 더 많은 것을 배우고 싶은 경우에,당신은 제일 파이썬
두 라이브러리를 로컬에 설치할 수 있습니다.
pip install requests bs4기본 크롤러는 이전 아키텍처 다이어그램에 따라 작성할 수 있습니다.
import loggingfrom urllib.parse import urljoinimport requestsfrom bs4 import BeautifulSouplogging.basicConfig( format='%(asctime)s %(levelname)s:%(message)s', level=logging.INFO)class Crawler: def __init__(self, urls=): self.visited_urls = self.urls_to_visit = urls def download_url(self, url): return requests.get(url).text def get_linked_urls(self, url, html): soup = BeautifulSoup(html, 'html.parser') for link in soup.find_all('a'): path = link.get('href') if path and path.startswith('/'): path = urljoin(url, path) yield path def add_url_to_visit(self, url): if url not in self.visited_urls and url not in self.urls_to_visit: self.urls_to_visit.append(url) def crawl(self, url): html = self.download_url(url) for url in self.get_linked_urls(url, html): self.add_url_to_visit(url) def run(self): while self.urls_to_visit: url = self.urls_to_visit.pop(0) logging.info(f'Crawling: {url}') try: self.crawl(url) except Exception: logging.exception(f'Failed to crawl: {url}') finally: self.visited_urls.append(url)if __name__ == '__main__': Crawler(urls=).run()위의 코드는 요청 라이브러리를 사용하여 다운로드할 도우미 메서드와 함께 크롤러 클래스를 정의합니다. 방문 할 링크와 방문한 링크는 두 개의 개별 목록에 저장됩니다. 당신은 당신의 터미널에서 크롤러를 실행할 수 있습니다.
python crawler.py크롤러는 방문한 각 링크에 대해 한 줄을 기록합니다.
2020-12-04 18:10:10,737 INFO:Crawling: https://www.imdb.com/2020-12-04 18:10:11,599 INFO:Crawling: https://www.imdb.com/?ref_=nv_home2020-12-04 18:10:12,868 INFO:Crawling: https://www.imdb.com/calendar/?ref_=nv_mv_cal2020-12-04 18:10:13,526 INFO:Crawling: https://www.imdb.com/list/ls016522954/?ref_=nv_tvv_dvd2020-12-04 18:10:19,174 INFO:Crawling: https://www.imdb.com/chart/top/?ref_=nv_mv_2502020-12-04 18:10:20,624 INFO:Crawling: https://www.imdb.com/chart/moviemeter/?ref_=nv_mv_mpm2020-12-04 18:10:21,556 INFO:Crawling: https://www.imdb.com/feature/genre/?ref_=nv_ch_gr이 코드는 매우 간단하지만 전체 웹 사이트를 성공적으로 크롤링하기 전에 해결해야 할 많은 성능 및 유용성 문제가 있습니다.
- 크롤러가 느리고 병렬 처리를 지원하지 않습니다. 타임스탬프에서 볼 수 있듯이 각 페이지를 크롤링하는 데 약 1 초가 걸립니다. 크롤러가 요청을 할 때마다 요청이 해결될 때까지 대기하며 그 사이에 작업이 수행되지 않습니다.
- 다운로드 로직에는 재시도 메커니즘이 없습니다.
- 링크 추출 논리는#로 시작하는 링크를 처리하지 않으며 도메인별로 필터링하거나 정적 파일에 대한 요청을 필터링하지 않습니다.
- 크롤러는 자신을 식별하지 않고 로봇을 무시합니다.파일.
다음으로,스크래피가 이러한 모든 기능을 제공하고 사용자 지정 크롤링을 쉽게 확장 할 수있는 방법을 살펴 보겠습니다.웹 크롤링은 가장 인기있는 웹 스크래핑 및 크롤링 파이썬 프레임 워크입니다. 스크래피의 장점 중 하나는 요청이 예약되고 비동기적으로 처리된다는 것입니다. 즉,스크래피는 이전 요청이 완료되기 전에 다른 요청을 보내거나 그 사이에 다른 작업을 수행 할 수 있습니다. 스크래피는 많은 동시 요청을 처리 할 수 있지만 나중에 볼 수 있듯이 사용자 지정 설정으로 웹 사이트를 존중하도록 구성 할 수도 있습니다.
스크래피에는 다중 구성 요소 아키텍처가 있습니다. 일반적으로 스파이더와 파이프 라인의 두 가지 클래스 이상을 구현합니다. 웹 스크래핑은 웹에서 데이터를 추출하여 자신의 저장소에 로드하는 것으로 생각할 수 있습니다. 스파이더는 데이터를 추출하고 파이프라인은 이를 스토리지에 로드합니다. 변환은 스파이더와 파이프라인 모두에서 발생할 수 있지만 각 항목을 서로 독립적으로 변환하도록 사용자 지정 스크래피 파이프라인을 설정하는 것이 좋습니다. 이렇게 하면 항목을 처리하지 못하면 다른 항목에는 영향을 주지 않습니다.
그 외에도 아래 다이어그램에서 볼 수 있듯이 구성 요소 사이에 스파이더 및 다운로더 미들웨어를 추가 할 수 있습니다.
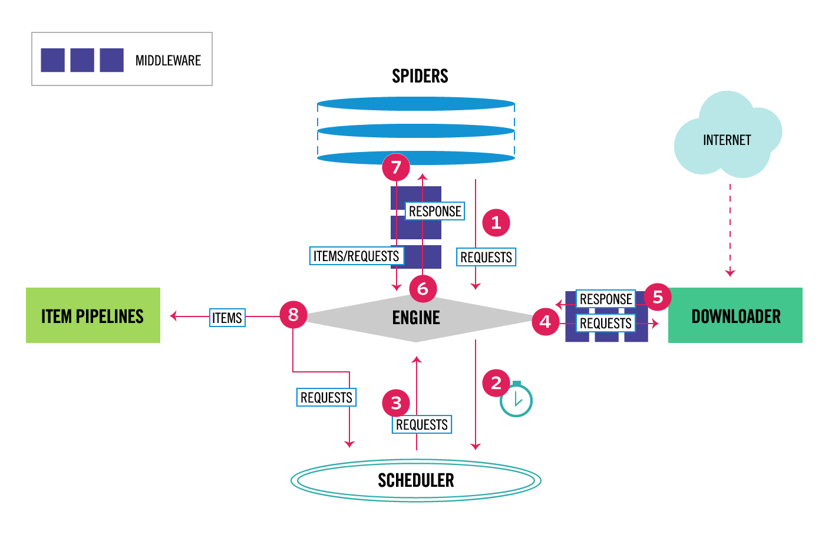
스크래피 아키텍처 개요
전에 스크래피를 사용한 경우 웹 스크레이퍼는 기본 스파이더 클래스에서 상속되고 각 응답을 처리하는 구문 분석 메서드를 구현하는 클래스로 정의된다는 것을 알고 있습니다. 당신이 긁힌 자국을 처음 사용하는 경우,당신은 긁힌 자국으로 쉽게 긁기 위해이 기사를 읽을 수 있습니다.
from scrapy.spiders import Spiderclass ImdbSpider(Spider): name = 'imdb' allowed_domains = start_urls = def parse(self, response): pass또한 이 클래스에는 여러 가지 일반적인 스파이더 클래스가 포함되어 있습니다. 크롤 스파이더클래스는 기본 스파이더 클래스에서 상속되며 웹 사이트를 크롤링하는 방법을 정의하는 추가 규칙 속성을 제공합니다. 각 규칙은 링크 추출을 사용하여 각 페이지에서 추출되는 링크를 지정합니다. 다음,우리는 인터넷 영화 데이터베이스에 대한 크롤러를 구축하여 각각의 하나를 사용하는 방법을 볼 수 있습니다.
크롤링을 시도하기 전에,나는 로봇을 체크했다.어떤 경로를 사용할 수 있는지 확인할 수 있습니다. 로봇 파일은 모든 사용자 에이전트에 대해 26 개의 경로 만 허용하지 않습니다. 스크래피는 로봇을 읽습니다.이 응용 프로그램을 사용하는 경우,이 응용 프로그램을 사용하는 것이 좋습니다. 이 명령은 프로젝트 시작 명령으로 생성된 모든 프로젝트의 경우입니다.
scrapy startproject scrapy_crawler이 명령은 기본 프로젝트 폴더 구조로 새 프로젝트를 만듭니다.
scrapy_crawler/├── scrapy.cfg└── scrapy_crawler ├── __init__.py ├── items.py ├── middlewares.py ├── pipelines.py ├── settings.py └── spiders ├── __init__.py그럼 당신은 거미를 만들 수 있습니다 scrapy_crawler/spiders/imdb.py 모든 링크를 추출하는 규칙.
from scrapy.spiders import CrawlSpider, Rulefrom scrapy.linkextractors import LinkExtractorclass ImdbCrawler(CrawlSpider): name = 'imdb' allowed_domains = start_urls = rules = (Rule(LinkExtractor()),)당신은 터미널에서 크롤러를 시작할 수 있습니다.
scrapy crawl imdb --logfile imdb.log각 요청에 대해 하나의 로그를 포함하여 많은 로그를 얻을 수 있습니다. 로그 탐색에서는https://www.imdb.com에서 웹 페이지만 크롤링하도록 허용 _도메인을 설정한 경우에도 다음과 같은 외부 도메인에 대한 요청이 있었습니다 amazon.com.
2020-12-06 12:25:18 DEBUG: Redirecting (302) to <GET https://www.amazon.com/b/?&node=5160028011&ref_=ft_iba> from <GET (https://www.imdb.com/whitelist-offsite?url=https%3A%2F%2Fwww.amazon.com%2Fb%2F%3F%26node%3D5160028011%26ref_%3Dft_iba&page-action=ft-iba&ref=ft_iba)>화이트리스트-오프사이트 및 화이트리스트 아래의 경로를 외부 도메인으로 리디렉션합니다. 이 문제를 해결하려면 다음 단계를 따르세요 이 문제를 해결하기 위해 두 개의 정규 표현식으로 시작하는 링크 추출기를 구성 할 수 있습니다.
class ImdbCrawler(CrawlSpider): name = 'imdb' allowed_domains = start_urls = rules = ( Rule(LinkExtractor( deny=, )), )규칙 및 링크추출자 클래스는 여러 인수를 지원하여 필터링합니다. 예를 들어 특정 확장자를 무시하고 쿼리 문자열을 정렬하여 중복된 확장자 수를 줄일 수 있습니다. 사용 사례에 대 한 특정 인수를 찾을 수 없는 경우 사용자 지정 함수를 전달할 수 있습니다.
예를 들어,동일한 콘텐츠를 가진 두 개의 다른 페이지가 있습니다.
https://www.imdb.com/이름/1156914/
https://www.imdb.com/이름/1156914/?이 문제를 해결하려면 다음 단계를 따르세요.*************
from w3lib.url import url_query_cleanerdef process_links(links): for link in links: link.url = url_query_cleaner(link.url) yield linkclass ImdbCrawler(CrawlSpider): name = 'imdb' allowed_domains = start_urls = rules = ( Rule(LinkExtractor( deny=, ), process_links=process_links), )이제 처리할 요청 수를 제한했으므로 구문 분석 _항목 메서드를 추가하여 각 페이지에서 데이터를 추출하고 이를 파이프라인으로 전달하여 저장할 수 있습니다. 예를 들어 전체 응답을 추출 할 수 있습니다.다른 파이프라인에서 처리할 텍스트 또는 메타데이터를 선택합니다. 하지만,라이브러리에서 모든 메타데이터를 추출하는 것이 좋습니다. 당신은 핍 설치 추출을 설치할 수 있습니다.
import refrom scrapy.linkextractors import LinkExtractorfrom scrapy.spiders import CrawlSpider, Rulefrom w3lib.url import url_query_cleanerimport extructdef process_links(links): for link in links: link.url = url_query_cleaner(link.url) yield linkclass ImdbCrawler(CrawlSpider): name = 'imdb' allowed_domains = start_urls = rules = ( Rule( LinkExtractor( deny=, ), process_links=process_links, callback='parse_item', follow=True ), ) def parse_item(self, response): return { 'url': response.url, 'metadata': extruct.extract( response.text, response.url, syntaxes= ), }나는 우리가 사용자 정의 구문 분석 방법을 제공하더라도 스크래피가 여전히 각 응답의 모든 링크를 따르도록 팔로우 속성을 참 으로 설정했습니다. 나는 또한 오픈 그래프 메타 데이터 만 추출하도록 엑스트라를 구성했다. 크롤러를 실행하고 항목을 파일에 저장할 수 있습니다.
scrapy crawl imdb --logfile imdb.log -o imdb.jl -t jsonlines출력 파일.크롤링된 각 항목에 대해 한 줄을 포함합니다. 예를 들어,<메타>태그에서 가져온 동영상에 대한 추출된 오픈 그래프 메타데이터는 다음과 같습니다.
{ "url": "http://www.imdb.com/title/tt2442560/", "metadata": {"opengraph": , , , , , ] }]}}다음 예제에서는 태그에서 추출하는 스크립트의 샘플입니다.
"json-ld": , "contentRating": "TV-MA", "actor": ... }]로그를 탐색하면서 크롤러의 또 다른 일반적인 문제를 발견했습니다. 크롤러는 순차적으로 필터를 클릭하면 동일한 콘텐츠로 필터가 다른 순서로 적용된 주소만 생성합니다.
https://www.imdb.com/2018 년 11 월 15 일~2018 년 12 월 15 일
https://www.imdb.com/이 문제를 해결하는 데 도움이 되는 방법은 다음과 같습니다.***********
나는 파이썬에서 웹 크롤러를 구축하는 기초를 보여주기 위해 예를 들어,임을 사용했다. 데이터에 대한 특정 사용 사례가 없기 때문에 크롤러를 오랫동안 실행시키지 않았습니다. 이것은 수학적으로 정확한 유형 계층구조인,강력한 타입을 정의합니다.웹 크롤링의 규모
웹 크롤링의 규모
웹 크롤링의 규모
웹 크롤링의 규모
웹 크롤링의 규모
웹 크롤링의 규모
웹 크롤링의 규모
크롤러를 식별하고 봇 _이름 설정에서 연락처 정보를 제공할 수 있습니다. 웹 사이트 서버에 가해지는 압력을 제한하려면 다운로드 지연을 늘리거나,동시 요청을 제한하거나,서버의 응답 시간을 기준으로 이러한 설정을 동적으로 조정할 수 있는 자동 전송을 설정할 수 있습니다.
스크래피 크롤링은 기본적으로 단일 도메인에 최적화되어 있습니다. 여러 도메인을 크롤링하는 경우 기본 크롤링 순서를 깊이 우선에서 호흡 우선으로 변경하는 등 광범위한 크롤링을 최적화하려면 이러한 설정을 확인하십시오. 크롤링 예산을 제한하려면 닫기 스파이더 확장의 페이지 개수 설정을 사용하여 요청 수를 제한할 수 있습니다.
기본 설정을 사용하면 웹 사이트에 대해 분당 약 600 페이지를 크롤링합니다. 4,500 만 페이지를 크롤링하려면 단일 로봇에 대해 50 일 이상 소요됩니다. 여러 웹 사이트를 크롤링해야하는 경우 각 큰 웹 사이트 또는 웹 사이트 그룹에 대해 별도의 크롤러를 시작하는 것이 좋습니다. 배포된 웹 크롤링에 관심이 있다면 개발자가 20 개의 컴퓨터 인스턴스를 사용하여 40 시간 안에 파이썬으로 2 억 5000 만 페이지를 크롤링하는 방법을 읽을 수 있습니다.
어떤 경우에는 모든 웹 페이지를 렌더링하기 위해 자바 스크립트 코드를 실행해야 웹 사이트로 실행할 수 있습니다. 그렇게하지 않으면 웹 사이트의 모든 링크를 수집 할 수 없습니다. 요즘 웹 사이트가 브라우저에서 콘텐츠를 동적으로 렌더링하는 것이 매우 일반적이기 때문에 스크래핑 비를 사용하여 자바 스크립트 페이지를 렌더링하기 위해 스크래피 미들웨어를 작성했습니다.
결론
우리는 인기 있는 웹 크롤링 프레임 워크를 사용 하 여 구축 된 크롤러와 크롤러를 다운로드 및 구문 분석에 대 한 타사 라이브러리를 사용 하 여 파이썬 크롤러의 코드를 비교 했다. 스크래피는 매우 뛰어난 웹 크롤링 프레임 워크이며 사용자 지정 코드로 쉽게 확장 할 수 있습니다. 하지만 당신은 당신이 당신의 자신의 코드와 각 구성 요소에 대한 설정을 후크 할 수있는 모든 장소를 알 필요가있다.
수백만 페이지의 웹 사이트를 크롤링할 때 스크래피를 올바르게 구성하는 것이 더욱 중요해집니다. 너가 웹 포복하기에 관하여 더를 배우고 싶으면 너가 대중적인 웹사이트를 쑤시고 그것을 포복한것을 해보는 것과 나는 건의한다. 당신은 확실히 주제를 매혹적으로 만드는 새로운 문제에 부딪 칠 것입니다!