Pythonを使用したWebクロール

Webクロールは、1つまたは複数のドメインのすべてのUrlを検索することにより、webからデータを収集する強力な手法です。 Pythonには、いくつかの一般的なwebクロールライブラリとフレームワークがあります。
この記事では、まず、さまざまなクロール戦略とユースケースを紹介します。 次に、requestsとBeautiful Soupという二つのライブラリを使用して、Pythonで簡単なwebクローラーをゼロから構築します。 次に、Scrapyのようなwebクローリングフレームワークを使用する方が良い理由を見ていきます。 最後に、Scrapyを使用してサンプルのクローラーを構築し、IMDbから映画のメタデータを収集し、Scrapyが数百万ページのwebサイトにどのようにスケールするかを確認します。
ウェブクローラーとは何ですか?
ウェブクロールとウェブスクレイピングは、二つの異なるが関連する概念です。 Webクロールはwebスクレイピングのコンポーネントであり、クローラーロジックはスクレーパーコードによって処理されるUrlを検索します。
webクローラーは、シードと呼ばれる訪問するUrlのリストから始まります。 各URLについて、クローラーはHTML内のリンクを検索し、いくつかの基準に基づいてそれらのリンクをフィルタリングし、新しいリンクをキューに追加します。 すべてのHTMLまたは特定の情報は、別のパイプラインによって処理されるように抽出されます。
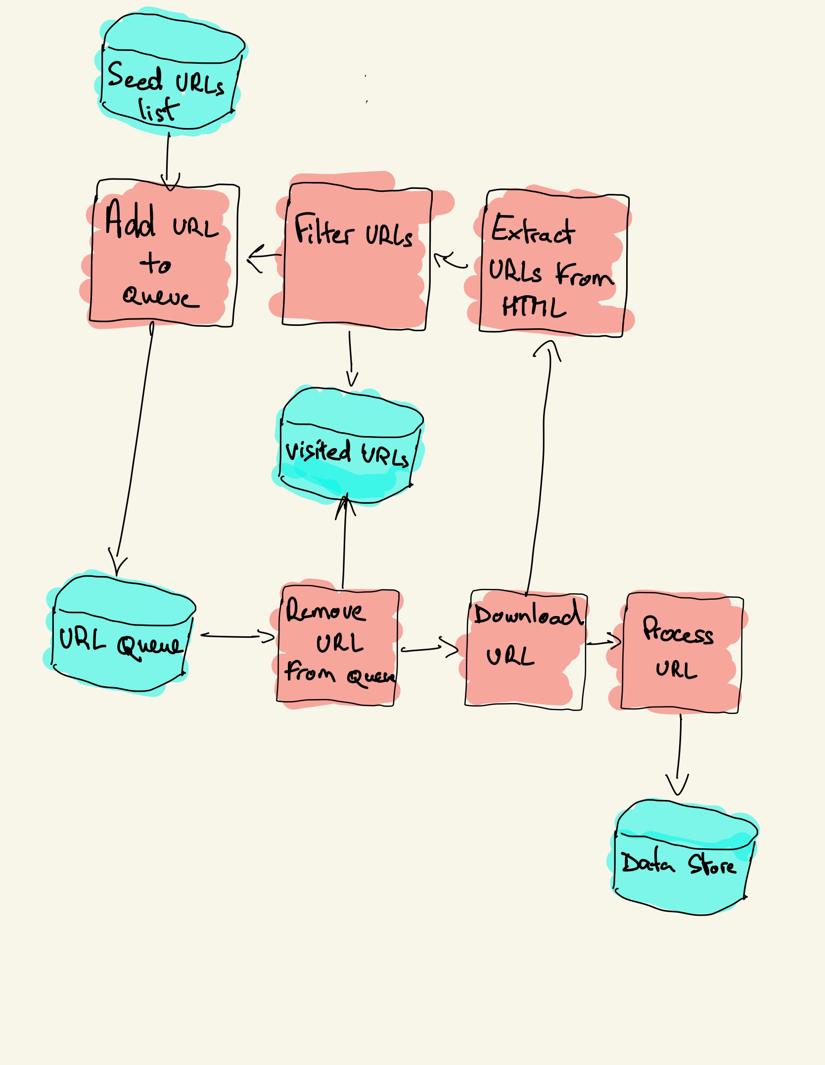
Webクロール戦略
実際には、webクローラーはクローラーの予算に応じてページのサブセットのみを訪問します。
最も人気のあるウェブサイトは、ロボットを提供しています。各ユーザーエージェントによってクロールが許可されていないwebサイトの領域を示すtxtファイル。 Robotsファイルの反対側はサイトマップです。クロール可能なページを一覧表示するxmlファイル。
人気のあるwebクローラーのユースケースは次のとおりです:
- 検索エンジン(Googlebot、Bingbot、Yandex Bot…)は、Webの重要な部分のすべてのHTMLを収集します。 このデータは、検索可能にするために索引付けされます。
- HTMLを収集する上でSEO分析ツールは、応答時間、壊れたページを検出するための応答ステータス、バックリンクを収集するための異なるドメイン間のリンクなどのメタデータを収集します。
- 価格監視ツールは、eコマースウェブサイトをクロールして商品ページを検索し、メタデータ、特に価格を抽出します。 製品ページは定期的に再訪されます。
- Common Crawlは、webクロールデータのオープンリポジトリを維持します。 たとえば、2020年10月のアーカイブには27億1000万ページのwebページが含まれています。
次に、Pythonでwebクローラーを構築するための三つの異なる戦略を比較します。 まず、標準ライブラリのみを使用し、次にHTTP要求を作成してHTMLを解析するためのサードパーティのライブラリを使用し、最後にwebクロールフレームワーク
Pythonで簡単なwebクローラーを最初から構築する
Pythonで簡単なwebクローラーを構築するには、URLからHTMLをダウンロードするためのライブラリと、リンクを抽出するためのHTML解析ライブラリが必要です。 Pythonは、HTTP要求とhtmlを作成するための標準ライブラリurllibを提供します。HTMLを解析するためのパーサー。 標準ライブラリのみで構築されたPythonクローラーの例はGithubで見つけることができます。
リクエストやHTML解析のための標準的なPythonライブラリは、あまり開発者に優しいものではありません。 Requestsのような他の人気のあるライブラリは、人間のためのHTTPとしてブランド化されており、Beautiful Soupはより良い開発者体験を提供します。
詳細を知りたい場合は、このガイドで最適なPython HTTPクライアントについて確認できます。
二つのライブラリをローカルにインストールできます。
pip install requests bs4基本的なクローラーは、前のアーキテクチャ図に従って構築できます。
import loggingfrom urllib.parse import urljoinimport requestsfrom bs4 import BeautifulSouplogging.basicConfig( format='%(asctime)s %(levelname)s:%(message)s', level=logging.INFO)class Crawler: def __init__(self, urls=): self.visited_urls = self.urls_to_visit = urls def download_url(self, url): return requests.get(url).text def get_linked_urls(self, url, html): soup = BeautifulSoup(html, 'html.parser') for link in soup.find_all('a'): path = link.get('href') if path and path.startswith('/'): path = urljoin(url, path) yield path def add_url_to_visit(self, url): if url not in self.visited_urls and url not in self.urls_to_visit: self.urls_to_visit.append(url) def crawl(self, url): html = self.download_url(url) for url in self.get_linked_urls(url, html): self.add_url_to_visit(url) def run(self): while self.urls_to_visit: url = self.urls_to_visit.pop(0) logging.info(f'Crawling: {url}') try: self.crawl(url) except Exception: logging.exception(f'Failed to crawl: {url}') finally: self.visited_urls.append(url)if __name__ == '__main__': Crawler(urls=).run()上記のコードでは、requestsライブラリを使用してdownload_urlにヘルパーメソッドを持つクローラークラスを定義し、Beautiful Soupライブラリを使用してget_linked_urlを定義し、Urlをフィル 訪問するUrlと訪問したUrlは、二つの別々のリストに格納されています。 あなたはあなたの端末上でクローラを実行することができます。
python crawler.pyクローラーは、訪問したURLごとに1行をログに記録します。
2020-12-04 18:10:10,737 INFO:Crawling: https://www.imdb.com/2020-12-04 18:10:11,599 INFO:Crawling: https://www.imdb.com/?ref_=nv_home2020-12-04 18:10:12,868 INFO:Crawling: https://www.imdb.com/calendar/?ref_=nv_mv_cal2020-12-04 18:10:13,526 INFO:Crawling: https://www.imdb.com/list/ls016522954/?ref_=nv_tvv_dvd2020-12-04 18:10:19,174 INFO:Crawling: https://www.imdb.com/chart/top/?ref_=nv_mv_2502020-12-04 18:10:20,624 INFO:Crawling: https://www.imdb.com/chart/moviemeter/?ref_=nv_mv_mpm2020-12-04 18:10:21,556 INFO:Crawling: https://www.imdb.com/feature/genre/?ref_=nv_ch_grコードは非常に単純ですが、完全なwebサイトを正常にクロールする前に解決すべき多くのパフォーマンスと使いやすさの問題があります。
- クローラーが遅く、並列処理をサポートしていません。 タイムスタンプからわかるように、各URLをクロールするのに約一秒かかります。 クローラーが要求を行うたびに、要求が解決されるのを待機し、その間に作業は行われません。
- ダウンロードURLロジックには再試行メカニズムがなく、URLキューは実際のキューではなく、Urlの数が多い場合はあまり効率的ではありません。
- リンク抽出ロジックは、URLクエリ文字列パラメータを削除してUrlを標準化することをサポートしておらず、#で始まるUrlを処理していない、ドメインによるUrlのフィルタリングアウトや静的ファイルへの要求のフィルタリングアウトをサポートしていない。
- クローラーは自分自身を識別せず、ロボットを無視します。txtファイル。
次に、Scrapyがこれらすべての機能を提供し、カスタムクロールの拡張を容易にする方法について説明します。
ScrapyによるWebクロール
ScrapyはGithub上で40kの星を持つ最も人気のあるweb scrapingとcrawling Pythonフレームワークです。 Scrapyの利点の1つは、要求がスケジュールされ、非同期に処理されることです。 これは、Scrapyが前の要求が完了する前に別の要求を送信したり、その間に他の作業を行うことができることを意味します。 Scrapyは多くの同時リクエストを処理できますが、後で説明するように、カスタム設定でwebサイトを尊重するように構成することもできます。
Scrapyはマルチコンポーネントアーキテクチャを持っています。 通常は、少なくとも2つの異なるクラス、SpiderとPipelineを実装します。 Web scrapingは、webからデータを抽出して独自のストレージにロードするETLと考えることができます。 スパイダーはデータを抽出し、パイプラインはそれをストレージにロードします。 変換はスパイダーとパイプラインの両方で実行できますが、各項目を互いに独立して変換するようにカスタムScrapyパイプラインを設定することをお勧 このようにして、アイテムの処理に失敗しても、他のアイテムには影響しません。
それに加えて、下の図に示すように、コンポーネントの間にspiderとdownloaderミドルウェアを追加することができます。
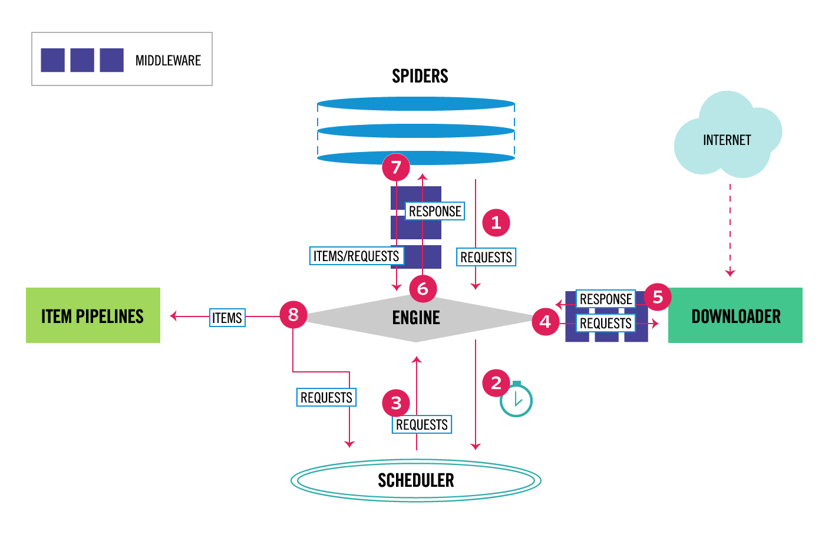
Scrapy Architecture Overview
以前にScrapyを使用したことがある場合、webスクレーパーは基本Spiderクラスを継承し、各応答を処理するparseメソッドを実装するクラスとして定義されています。 あなたがScrapyに慣れていない場合は、Scrapyで簡単に掻き取るためにこの記事を読むことができます。
from scrapy.spiders import Spiderclass ImdbSpider(Spider): name = 'imdb' allowed_domains = start_urls = def parse(self, response): passScrapyには、crawlspider、XMLFeedSpider、CSVFeedSpider、SitemapSpiderといういくつかの一般的なspiderクラスも用意されています。 CrawlSpiderクラスは、基本Spiderクラスを継承し、webサイトをクロールする方法を定義するための追加のrules属性を提供します。 各ルールでは、LinkExtractorを使用して、各ページから抽出するリンクを指定します。 次に、インターネット映画データベースであるIMDb用のクローラーを構築することによって、それぞれを使用する方法を見ていきます。
IMDbのScrapyクローラーの例を構築する
IMDbをクロールしようとする前に、IMDb robotsをチェックしました。どのURLパスが許可されているかを確認するためのtxtファイル。 Robotsファイルは、すべてのユーザーエージェントに対して26個のパスのみを許可します。 Scrapyはロボットを読む。txtファイルを事前に保存し、ROBOTSTXT_OBEY設定がtrueに設定されている場合はそれを尊重します。 これは、Scrapyコマンドstartprojectで生成されたすべてのプロジェクトに当てはまります。
scrapy startproject scrapy_crawlerこのコマンドは、デフォルトのScrapyプロジェクトフォルダ構造を持つ新しいプロジェクトを作成します。
scrapy_crawler/├── scrapy.cfg└── scrapy_crawler ├── __init__.py ├── items.py ├── middlewares.py ├── pipelines.py ├── settings.py └── spiders ├── __init__.pyその後、クモを作成することができますscrapy_crawler/spiders/imdb.py すべてのリンクを抽出するルール付き。
from scrapy.spiders import CrawlSpider, Rulefrom scrapy.linkextractors import LinkExtractorclass ImdbCrawler(CrawlSpider): name = 'imdb' allowed_domains = start_urls = rules = (Rule(LinkExtractor()),)ターミナルでクローラを起動できます。
scrapy crawl imdb --logfile imdb.logリクエストごとに1つのログを含む、多くのログが取得されます。 ログを調べると、allowed_domainsをhttps://www.imdb.comの下のwebページのみをクロールするように設定しても、次のような外部ドメインへの要求があることに気付きましたamazon.com.
2020-12-06 12:25:18 DEBUG: Redirecting (302) to <GET https://www.amazon.com/b/?&node=5160028011&ref_=ft_iba> from <GET (https://www.imdb.com/whitelist-offsite?url=https%3A%2F%2Fwww.amazon.com%2Fb%2F%3F%26node%3D5160028011%26ref_%3Dft_iba&page-action=ft-iba&ref=ft_iba)>IMDbは、ホワイトリスト-オフサイトおよびホワイトリストの下のUrlパスから外部ドメインにリダイレク RedirectMiddlewareの前にOffsiteMiddlewareが適用されたときに外部Urlが除外されないことを示すopen Scrapy Githubの問題があります。 この問題を解決するために、2つの正規表現で始まるUrlを拒否するようにリンク抽出を構成できます。
class ImdbCrawler(CrawlSpider): name = 'imdb' allowed_domains = start_urls = rules = ( Rule(LinkExtractor( deny=, )), )RuleクラスとLinkExtractorクラスは、Urlを除外するためのいくつかの引数をサポートしています。 たとえば、特定のURL拡張子を無視して、クエリ文字列を並べ替えることで重複するUrlの数を減らすことができます。 ユースケースの特定の引数が見つからない場合は、カスタム関数をLinkExtractorのprocess_linksまたはRuleのprocess_valuesに渡すことができます。
たとえば、IMDbには同じコンテンツを持つ2つの異なるUrlがあります。
https://www.imdb.com/1156914/
https://www.imdb.com/名前/nm1156914/?mode=desktop&ref_=m_ft_dsk
クロールされたUrlの数を制限するには、w3libライブラリのurl_query_cleaner関数を使用してUrlからすべてのクエリ文字列を削除し、process_linksで使用できます。
from w3lib.url import url_query_cleanerdef process_links(links): for link in links: link.url = url_query_cleaner(link.url) yield linkclass ImdbCrawler(CrawlSpider): name = 'imdb' allowed_domains = start_urls = rules = ( Rule(LinkExtractor( deny=, ), process_links=process_links), )処理するリクエストの数が限られたので、parse_itemメソッドを追加して各ページからデータを抽出し、それを格納するパイプラインに渡すことができます。 たとえば、応答全体を抽出することもできます。別のパイプラインで処理するか、HTMLメタデータを選択するテキスト。 ヘッダータグでHTMLメタデータを選択するには、独自のXpathをコーディングできますが、HTMLページからすべてのメタデータを抽出するライブラリextructを使用する方が良 あなたはpip install extractでそれをインストールすることができます。
import refrom scrapy.linkextractors import LinkExtractorfrom scrapy.spiders import CrawlSpider, Rulefrom w3lib.url import url_query_cleanerimport extructdef process_links(links): for link in links: link.url = url_query_cleaner(link.url) yield linkclass ImdbCrawler(CrawlSpider): name = 'imdb' allowed_domains = start_urls = rules = ( Rule( LinkExtractor( deny=, ), process_links=process_links, callback='parse_item', follow=True ), ) def parse_item(self, response): return { 'url': response.url, 'metadata': extruct.extract( response.text, response.url, syntaxes= ), }follow属性をTrueに設定して、カスタム解析メソッドを提供しても、Scrapyが各応答のすべてのリンクを追跡するようにしました。 また、open Graphメタデータのみを抽出するようにextructを構成し、IMDbで使用されるWEBでJSONを使用してリンクされたデータをエンコードする一般的な方法であるJSON-LD クローラーを実行して、JSON行形式のアイテムをファイルに保存できます。
scrapy crawl imdb --logfile imdb.log -o imdb.jl -t jsonlines出力ファイルimdb。jlには、クロールされた項目ごとに1行が含まれます。 たとえば、HTMLの<meta>タグから取得したムービーの抽出されたOpen Graphメタデータは次のようになります。
{ "url": "http://www.imdb.com/title/tt2442560/", "metadata": {"opengraph": , , , , , ] }]}}ここでは、Scrapyが<script type=”application/ld+json”>タグから抽出したサンプルを示します。
"json-ld": , "contentRating": "TV-MA", "actor": ... }]ログを調べて、私はクローラと別の一般的な問題に気づきました。 フィルターを順番にクリックすると、クローラーは同じコンテンツを持つUrlを生成し、フィルターが異なる順序で適用されたUrlのみを生成します。
https://www.imdb.com/名前/nm2900465/videogallery/content_type-trailer/related_title-tt0479468
https://www.imdb.com/name/nm2900465/videogallery/related_title-tt0479468/content_type-trailer
長いフィルタと検索Urlは、Urllength_LIMITというScrapy設定でUrlの長さを制限することで部分的に解決できる困難な問題です。IMDbを例として使用して、Pythonでwebクローラーを構築するための基本を示しました。 私はデータの特定のユースケースを持っていなかったので、クローラーを長く走らせませんでした。 IMDbの特定のデータが必要な場合は、IMDbデータの毎日のエクスポートを提供するIMDb Datasetsプロジェクトと、データの取得と管理のためのPythonパッケージであるIMDbPYをチェ
規模でのwebクロール
IMDbのような大きなウェブサイトをクロールしようとすると、Googleに基づいて45M以上のページがありますが、次の設定を行って責任を持ってクロールすることが重要です。 クローラーを識別し、BOT_NAME設定で連絡先の詳細を提供することができます。 ウェブサイトのサーバーにかける圧力を制限するには、DOWNLOAD_DELAYを増やし、CONCURRENT_REQUESTS_PER_DOMAINを制限するか、サーバーからの応答時間に基づいてこれらの設定を動的に適応させるAUTOTHROTTLE_ENABLEDを設定することができます。
デフォルトでは、Scrapyクロールは単一ドメイン用に最適化されていることに注意してください。 複数のドメインをクロールする場合は、これらの設定をチェックして、既定のクロール順序を深さ優先から息優先に変更するなど、幅広いクロールに最適化 クロール予算を制限するには、close spider拡張機能のCLOSESPIDER_PAGECOUNT設定を使用して要求の数を制限できます。
デフォルト設定では、ScrapyはIMDbのようなウェブサイトのために毎分約600ページをクロールします。 45Mのページをクロールするには、単一のロボットのために50日以上かかります。 複数のwebサイトをクロールする必要がある場合は、大きなwebサイトまたはwebサイトのグループごとに別々のクローラーを起動する方が良い 分散webクロールに興味がある場合は、20台のAmazon EC2マシンインスタンスを使用して、開発者がPythonで250Mページを40時間でクロールした方法を読むことがで
場合によっては、すべてのHTMLをレンダリングするためにJavaScriptコードを実行する必要があるwebサイトに遭遇することがあります。 これを行うに失敗し、ウェブサイト上のすべてのリンクを収集することはできません。 今日では、ウェブサイトがブラウザで動的にコンテンツをレンダリングすることは非常に一般的なので、私はScrapingBeeのAPIを使用してJavaScriptページをレンダリングす
結論
UrlのダウンロードやHTMLの解析にサードパーティのライブラリを使用したPythonクローラーのコードを、一般的なwebクローリングフレームワークを使用して構築されたクローラーと比較しました。 Scrapyは非常にパフォーマンスの高いwebクローリングフレームワークであり、カスタムコードで簡単に拡張できます。 しかし、あなたはあなた自身のコードと各コンポーネントの設定をフックできるすべての場所を知る必要があります。
何百万ものページを持つウェブサイトをクロールするとき、Scrapyを適切に設定することはさらに重要になります。 Webクロールの詳細を知りたい場合は、人気のあるwebサイトを選択し、それをクロールしようとすることをお勧めします。 あなたは間違いなくトピックが魅力的になり、新しい問題に実行されます!