Scansione web con Python

Web crawling è una tecnica potente per raccogliere dati dal web trovando tutti gli URL per uno o più domini. Python ha diverse librerie e framework di scansione web popolari.
In questo articolo, introdurremo prima diverse strategie di scansione e casi d’uso. Quindi costruiremo un semplice web crawler da zero in Python usando due librerie: requests e Beautiful Soup. Successivamente, vedremo perché è meglio usare un framework di scansione web come Scrapy. Infine, costruiremo un crawler di esempio con Scrapy per raccogliere i metadati dei film da IMDb e vedere come Scrapy scala i siti Web con diversi milioni di pagine.
Che cos’è un web crawler?
Web crawling e web scraping sono due concetti diversi ma correlati. Web crawling è un componente di web scraping, la logica crawler trova URL da elaborare dal codice raschietto.
Un web crawler inizia con un elenco di URL da visitare, chiamato seed. Per ogni URL, il crawler trova i collegamenti nell’HTML, filtra tali collegamenti in base ad alcuni criteri e aggiunge i nuovi collegamenti a una coda. Tutto l’HTML o alcune informazioni specifiche vengono estratte per essere elaborate da una pipeline diversa.
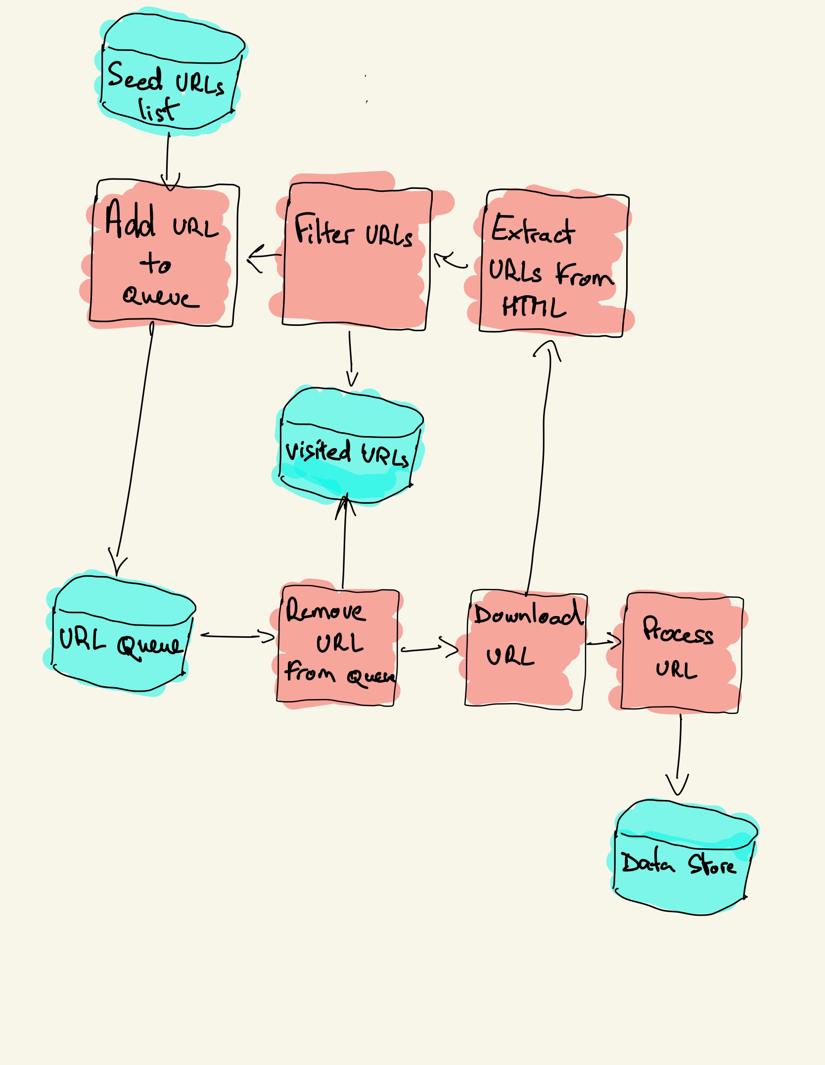
Strategie di scansione Web
In pratica, i web crawler visitano solo un sottoinsieme di pagine a seconda del budget del crawler, che può essere un numero massimo di pagine per dominio, profondità o tempo di esecuzione.
Siti web più popolari forniscono un robot.file txt per indicare quali aree del sito Web non sono autorizzate a eseguire la scansione da ciascun agente utente. L’opposto del file robots è la mappa del sito.file xml, che elenca le pagine che possono essere scansionate.
I casi d’uso più diffusi del web crawler includono:
- I motori di ricerca (Googlebot, Bingbot, Yandex Bot Bot) raccolgono tutto l’HTML per una parte significativa del Web. Questi dati sono indicizzati per renderli ricercabili.
- Gli strumenti di analisi SEO oltre a raccogliere l’HTML raccolgono anche metadati come il tempo di risposta, lo stato della risposta per rilevare le pagine interrotte e i collegamenti tra diversi domini per raccogliere i backlink.
- Strumenti di monitoraggio dei prezzi scansiona i siti di e-commerce per trovare le pagine dei prodotti ed estrarre i metadati, in particolare il prezzo. Le pagine dei prodotti vengono poi periodicamente rivisitate.
- Common Crawl mantiene un repository aperto di dati web crawl. Ad esempio, l’archivio di ottobre 2020 contiene 2,71 miliardi di pagine web.
Successivamente, confronteremo tre diverse strategie per la costruzione di un crawler web in Python. Innanzitutto, utilizzando solo librerie standard, quindi librerie di terze parti per effettuare richieste HTTP e analizzare HTML e, infine, un framework di scansione Web.
Costruire un semplice web crawler in Python da zero
Per costruire un semplice web crawler in Python abbiamo bisogno di almeno una libreria per scaricare l’HTML da un URL e una libreria di analisi HTML per estrarre i collegamenti. Python fornisce librerie standard urllib per fare richieste HTTP e html.parser per l’analisi di HTML. Un esempio di crawler Python costruito solo con librerie standard può essere trovato su Github.
Le librerie Python standard per le richieste e l’analisi HTML non sono molto adatte agli sviluppatori. Altre librerie popolari come requests, bollate come HTTP for humans e Beautiful Soup offrono un’esperienza di sviluppo migliore.
Se vuoi saperne di più, puoi controllare questa guida sul miglior client HTTP Python.
È possibile installare le due librerie localmente.
pip install requests bs4Un crawler di base può essere costruito seguendo il diagramma di architettura precedente.
import loggingfrom urllib.parse import urljoinimport requestsfrom bs4 import BeautifulSouplogging.basicConfig( format='%(asctime)s %(levelname)s:%(message)s', level=logging.INFO)class Crawler: def __init__(self, urls=): self.visited_urls = self.urls_to_visit = urls def download_url(self, url): return requests.get(url).text def get_linked_urls(self, url, html): soup = BeautifulSoup(html, 'html.parser') for link in soup.find_all('a'): path = link.get('href') if path and path.startswith('/'): path = urljoin(url, path) yield path def add_url_to_visit(self, url): if url not in self.visited_urls and url not in self.urls_to_visit: self.urls_to_visit.append(url) def crawl(self, url): html = self.download_url(url) for url in self.get_linked_urls(url, html): self.add_url_to_visit(url) def run(self): while self.urls_to_visit: url = self.urls_to_visit.pop(0) logging.info(f'Crawling: {url}') try: self.crawl(url) except Exception: logging.exception(f'Failed to crawl: {url}') finally: self.visited_urls.append(url)if __name__ == '__main__': Crawler(urls=).run()Il codice sopra definisce una classe Crawler con metodi helper per download_url usando la libreria requests, get_linked_urls usando la bella libreria Soup e add_url_to_visit per filtrare gli URL. Gli URL da visitare e gli URL visitati sono memorizzati in due elenchi separati. È possibile eseguire il crawler sul terminale.
python crawler.pyIl crawler registra una riga per ogni URL visitato.
2020-12-04 18:10:10,737 INFO:Crawling: https://www.imdb.com/2020-12-04 18:10:11,599 INFO:Crawling: https://www.imdb.com/?ref_=nv_home2020-12-04 18:10:12,868 INFO:Crawling: https://www.imdb.com/calendar/?ref_=nv_mv_cal2020-12-04 18:10:13,526 INFO:Crawling: https://www.imdb.com/list/ls016522954/?ref_=nv_tvv_dvd2020-12-04 18:10:19,174 INFO:Crawling: https://www.imdb.com/chart/top/?ref_=nv_mv_2502020-12-04 18:10:20,624 INFO:Crawling: https://www.imdb.com/chart/moviemeter/?ref_=nv_mv_mpm2020-12-04 18:10:21,556 INFO:Crawling: https://www.imdb.com/feature/genre/?ref_=nv_ch_grIl codice è molto semplice, ma ci sono molti problemi di prestazioni e usabilità da risolvere prima di eseguire la scansione di un sito Web completo.
- Il crawler è lento e non supporta alcun parallelismo. Come si può vedere dai timestamp, ci vuole circa un secondo per eseguire la scansione di ogni URL. Ogni volta che il crawler effettua una richiesta, attende che la richiesta venga risolta e non viene eseguito alcun lavoro in mezzo.
- La logica URL di download non ha alcun meccanismo di riprova, la coda URL non è una coda reale e non è molto efficiente con un numero elevato di URL.
- La logica di estrazione dei collegamenti non supporta la standardizzazione degli URL rimuovendo i parametri della stringa di query URL, non gestisce gli URL che iniziano con #, non supporta il filtraggio degli URL per dominio o il filtraggio delle richieste ai file statici.
- Il crawler non si identifica e ignora i robot.file txt.
Successivamente, vedremo come Scrapy fornisce tutte queste funzionalità e lo rende facile da estendere per i tuoi crawl personalizzati.
Web crawling con Scrapy
Scrapy è il framework Python di web scraping e crawling più popolare con 40k stelle su Github. Uno dei vantaggi di Scrapy è che le richieste sono pianificate e gestite in modo asincrono. Ciò significa che Scrapy può inviare un’altra richiesta prima che quella precedente sia completata o fare qualche altro lavoro in mezzo. Scrapy può gestire molte richieste simultanee ma può anche essere configurato per rispettare i siti web con impostazioni personalizzate, come vedremo più avanti.
Scrapy ha un’architettura multi-componente. Normalmente, implementerai almeno due classi diverse: Spider e Pipeline. Il Web scraping può essere pensato come un ETL in cui si estraggono dati dal Web e li si carica nel proprio spazio di archiviazione. Gli spider estraggono i dati e le pipeline li caricano nella memoria. La trasformazione può avvenire sia negli spider che nelle pipeline, ma ti consiglio di impostare una pipeline Scrapy personalizzata per trasformare ogni elemento indipendentemente l’uno dall’altro. In questo modo, la mancata elaborazione di un elemento non ha alcun effetto su altri elementi.
Oltre a tutto ciò, puoi aggiungere middleware spider e downloader tra i componenti come si può vedere nello schema seguente.
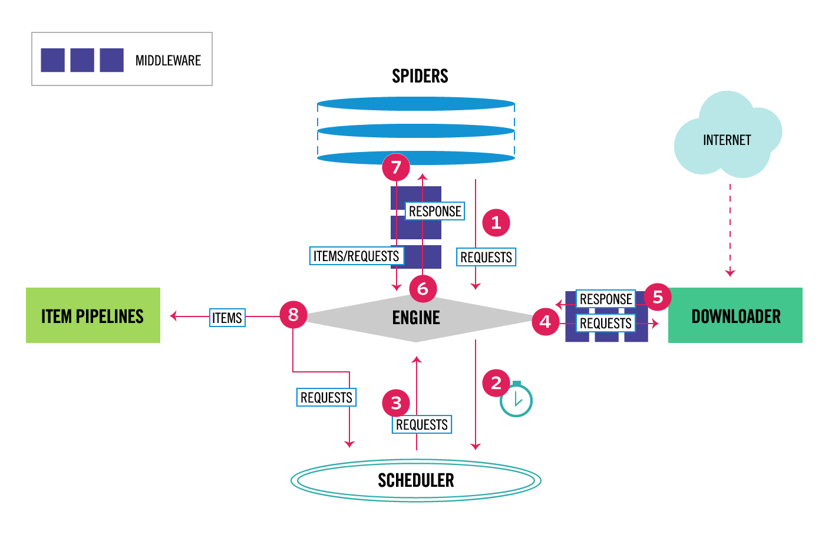
Panoramica dell’architettura Scrapy
Se hai usato Scrapy in precedenza, sai che un raschietto web è definito come una classe che eredita dalla classe Spider base e implementa un metodo di analisi per gestire ogni risposta. Se siete nuovi a Scrapy, è possibile leggere questo articolo per una facile raschiatura con Scrapy.
from scrapy.spiders import Spiderclass ImdbSpider(Spider): name = 'imdb' allowed_domains = start_urls = def parse(self, response): passScrapy fornisce anche diverse classi di spider generiche: CrawlSpider, XMLFeedSpider, CSVFeedSpider e SitemapSpider. La classe CrawlSpider eredita dalla classe Spider base e fornisce un attributo regole extra per definire come eseguire la scansione di un sito web. Ogni regola utilizza un LinkExtractor per specificare quali collegamenti vengono estratti da ogni pagina. Successivamente, vedremo come utilizzare ciascuno di essi costruendo un crawler per IMDb, l’Internet Movie Database.
Creazione di un crawler Scrapy di esempio per IMDb
Prima di provare a eseguire la scansione di IMDb, ho controllato i robot IMDb.file txt per vedere quali percorsi URL sono consentiti. Il file robots non consente solo 26 percorsi per tutti gli user-agent. Scrapy legge i robot.file txt in anticipo e lo rispetta quando l’impostazione ROBOTSTXT_OBEY è impostata su true. Questo è il caso di tutti i progetti generati con il comando Scrapy startproject.
scrapy startproject scrapy_crawlerQuesto comando crea un nuovo progetto con la struttura predefinita delle cartelle del progetto Scrapy.
scrapy_crawler/├── scrapy.cfg└── scrapy_crawler ├── __init__.py ├── items.py ├── middlewares.py ├── pipelines.py ├── settings.py └── spiders ├── __init__.pyQuindi puoi creare un ragno in scrapy_crawler/spiders/imdb.py con una regola per estrarre tutti i collegamenti.
from scrapy.spiders import CrawlSpider, Rulefrom scrapy.linkextractors import LinkExtractorclass ImdbCrawler(CrawlSpider): name = 'imdb' allowed_domains = start_urls = rules = (Rule(LinkExtractor()),)È possibile avviare il crawler nel terminale.
scrapy crawl imdb --logfile imdb.logOtterrete un sacco di registri, tra cui un registro per ogni richiesta. Esplorando i registri ho notato che anche se impostiamo allowed_domains per eseguire la scansione solo delle pagine Web sotto https://www.imdb.com, c’erano richieste a domini esterni, come ad esempio amazon.com.
2020-12-06 12:25:18 DEBUG: Redirecting (302) to <GET https://www.amazon.com/b/?&node=5160028011&ref_=ft_iba> from <GET (https://www.imdb.com/whitelist-offsite?url=https%3A%2F%2Fwww.amazon.com%2Fb%2F%3F%26node%3D5160028011%26ref_%3Dft_iba&page-action=ft-iba&ref=ft_iba)>IMDb reindirizza dai percorsi URL sotto whitelist-offsite e whitelist a domini esterni. C’è un problema Github Scrapy aperto che mostra che gli URL esterni non vengono filtrati quando OffsiteMiddleware viene applicato prima di RedirectMiddleware. Per risolvere questo problema, possiamo configurare link extractor per negare gli URL che iniziano con due espressioni regolari.
class ImdbCrawler(CrawlSpider): name = 'imdb' allowed_domains = start_urls = rules = ( Rule(LinkExtractor( deny=, )), )Le classi Rule e LinkExtractor supportano diversi argomenti per filtrare gli URL. Ad esempio, è possibile ignorare le estensioni URL specifiche e ridurre il numero di URL duplicati ordinando le stringhe di query. Se non trovi un argomento specifico per il tuo caso d’uso, puoi passare una funzione personalizzata a process_links in LinkExtractor o process_values in Rule.
Ad esempio, IMDb ha due URL diversi con lo stesso contenuto.
https://www.imdb.com/nome / nm1156914/
https://www.imdb.com/nome / nm1156914/?mode=desktop&ref_ = m_ft_dsk
Per limitare il numero di URL sottoposti a scansione, possiamo rimuovere tutte le stringhe di query dagli URL con la funzione url_query_cleaner dalla libreria w3lib e usarla in process_links.
from w3lib.url import url_query_cleanerdef process_links(links): for link in links: link.url = url_query_cleaner(link.url) yield linkclass ImdbCrawler(CrawlSpider): name = 'imdb' allowed_domains = start_urls = rules = ( Rule(LinkExtractor( deny=, ), process_links=process_links), )Ora che abbiamo limitato il numero di richieste da elaborare, possiamo aggiungere un metodo parse_item per estrarre i dati da ogni pagina e passarli a una pipeline per memorizzarli. Ad esempio, possiamo estrarre l’intera risposta.testo per elaborarlo in una pipeline diversa o selezionare i metadati HTML. Per selezionare i metadati HTML nel tag header possiamo codificare i nostri XPATHs ma trovo meglio usare una libreria, extruct, che estrae tutti i metadati da una pagina HTML. Puoi installarlo con pip install extract.
import refrom scrapy.linkextractors import LinkExtractorfrom scrapy.spiders import CrawlSpider, Rulefrom w3lib.url import url_query_cleanerimport extructdef process_links(links): for link in links: link.url = url_query_cleaner(link.url) yield linkclass ImdbCrawler(CrawlSpider): name = 'imdb' allowed_domains = start_urls = rules = ( Rule( LinkExtractor( deny=, ), process_links=process_links, callback='parse_item', follow=True ), ) def parse_item(self, response): return { 'url': response.url, 'metadata': extruct.extract( response.text, response.url, syntaxes= ), }Ho impostato l’attributo follow su True in modo che Scrapy segua ancora tutti i collegamenti da ogni risposta anche se abbiamo fornito un metodo di analisi personalizzato. Ho anche configurato extruct per estrarre solo metadati Open Graph e JSON-LD, un metodo popolare per la codifica dei dati collegati utilizzando JSON nel Web, utilizzato da IMDb. È possibile eseguire il crawler e memorizzare gli elementi in formato linee JSON in un file.
scrapy crawl imdb --logfile imdb.log -o imdb.jl -t jsonlinesIl file di output imdb.jl contiene una riga per ogni elemento sottoposto a scansione. Ad esempio, i metadati Open Graph estratti per un film tratto dai tag <meta> nell’HTML hanno il seguente aspetto.
{ "url": "http://www.imdb.com/title/tt2442560/", "metadata": {"opengraph": , , , , , ] }]}}Il JSON-LD per un singolo elemento è troppo lungo per essere incluso nell’articolo, ecco un esempio di ciò che Scrapy estrae dal tag <script type=”application/ld+json”>.
"json-ld": , "contentRating": "TV-MA", "actor": ... }]Esplorando i registri, ho notato un altro problema comune con i crawler. Facendo clic in sequenza sui filtri, il crawler genera URL con lo stesso contenuto, solo che i filtri sono stati applicati in un ordine diverso.
https://www.imdb.com/nome/nm2900465/videogallery/content_type-trailer/related_titles-tt0479468
https://www.imdb.com/nome/nm2900465/videogallery/related_titles-tt0479468/content_type-trailer
filtro Lungo, e gli Url di ricerca è un problema difficile, che può essere parzialmente risolto limitando la lunghezza degli Url con una Scrapy impostazione, URLLENGTH_LIMIT.
Ho usato IMDb come esempio per mostrare le basi della costruzione di un crawler web in Python. Non ho lasciato correre il crawler a lungo perché non avevo un caso d’uso specifico per i dati. Nel caso in cui siano necessari dati specifici da IMDb, è possibile controllare il progetto Dataset IMDb che fornisce un’esportazione giornaliera di dati IMDb e IMDbPY, un pacchetto Python per il recupero e la gestione dei dati.
Web crawling in scala
Se si tenta di eseguire la scansione di un grande sito web come IMDb, con oltre 45 milioni di pagine basate su Google, è importante eseguire la scansione in modo responsabile configurando le seguenti impostazioni. È possibile identificare il crawler e fornire i dettagli di contatto nell’impostazione BOT_NAME. Per limitare la pressione esercitata sui server del sito Web è possibile aumentare DOWNLOAD_DELAY, limitare CONCURRENT_REQUESTS_PER_DOMAIN o impostare AUTOTHROTTLE_ENABLED che adatterà dinamicamente tali impostazioni in base ai tempi di risposta dal server.
Si noti che i crawl Scrapy sono ottimizzati per un singolo dominio per impostazione predefinita. Se si esegue la scansione di più domini, controllare queste impostazioni per ottimizzare le scansioni ampie, inclusa la modifica dell’ordine di scansione predefinito da depth-first a breath-first. Per limitare il budget di scansione, è possibile limitare il numero di richieste con l’impostazione CLOSESPIDER_PAGECOUNT dell’estensione chiudi spider.
Con le impostazioni predefinite, Scrapy esegue la scansione di circa 600 pagine al minuto per un sito web come IMDb. Per eseguire la scansione di pagine 45M ci vorranno più di 50 giorni per un singolo robot. Se è necessario eseguire la scansione di più siti Web può essere meglio lanciare crawler separati per ogni grande sito web o gruppo di siti web. Se sei interessato alla scansione Web distribuita, puoi leggere come uno sviluppatore ha eseguito la scansione di 250 milioni di pagine con Python in 40 ore utilizzando 20 istanze di macchine Amazon EC2.
In alcuni casi, è possibile eseguire siti Web che richiedono l’esecuzione di codice JavaScript per il rendering di tutto il codice HTML. Non riescono a farlo, e non si può raccogliere tutti i link sul sito web. Poiché al giorno d’oggi è molto comune per i siti web per il rendering di contenuti in modo dinamico nel browser ho scritto un middleware Scrapy per il rendering di pagine JavaScript utilizzando l’API di ScrapingBee.
Conclusione
Abbiamo confrontato il codice di un crawler Python utilizzando librerie di terze parti per scaricare URL e analizzare HTML con un crawler costruito utilizzando un popolare framework di scansione web. Scrapy è un framework di scansione Web molto performante ed è facile da estendere con il tuo codice personalizzato. Ma è necessario conoscere tutti i luoghi in cui è possibile collegare il proprio codice e le impostazioni per ciascun componente.
Configurare correttamente Scrapy diventa ancora più importante quando si scansionano siti web con milioni di pagine. Se vuoi saperne di più sulla scansione web, ti suggerisco di scegliere un sito Web popolare e provare a scansionarlo. Sicuramente incontrerai nuovi problemi, il che rende l’argomento affascinante!