PASSO DOPO PASSO: COME CONFIGURARE UN’ISTANZA DEL CLUSTER DI FAILOVER DI SQL SERVER 2008 R2 SU WINDOWS SERVER 2008 R2 IN AZURE O AZURE STACK
Il 9 luglio 2019, il supporto per SQL Server 2008 e 2008 R2 terminerà. Ciò significa la fine degli aggiornamenti di sicurezza regolari. Tuttavia, se si spostano le istanze di SQL Server in Azure o Azure Stack (mi riferirò semplicemente a entrambi come Azure per il resto della guida), Microsoft ti fornirà tre anni di aggiornamenti di sicurezza estesi senza costi aggiuntivi. Se si sta attualmente eseguendo SQL Server 2008/2008 R2 e non è possibile eseguire l’aggiornamento a una versione successiva di SQL Server prima della scadenza del 9 luglio, si desidera usufruire di questa offerta piuttosto che correre il rischio di affrontare una futura vulnerabilità di sicurezza. Un’istanza senza patch di SQL Server potrebbe portare a perdita di dati, tempi di inattività o una violazione dei dati devastante.
Una delle sfide che dovrai affrontare quando esegui SQL Server 2008/2008 R2 in Azure è garantire un’elevata disponibilità. On premise è possibile che si stia eseguendo un’istanza FCI (Failover Cluster) di SQL Server per l’alta disponibilità o che si stia eseguendo SQL Server in una macchina virtuale e si faccia affidamento su VMware HA o su un cluster Hyper-V per la disponibilità. Quando si passa ad Azure, nessuna di queste opzioni è disponibile. I tempi di inattività in Azure sono una possibilità molto reale che è necessario adottare misure per mitigare.
Al fine di mitigare la possibilità di downtime e qualificarsi per Azure 99.95% o 99.99% SLA, è necessario sfruttare SIOS DataKeeper. DataKeeper supera la mancanza di archiviazione condivisa di Azure e consente di creare un FCI SQL Server in Azure che sfrutta lo storage collegato localmente su ogni istanza. SIOS DataKeeper non solo supporta SQL Server 2008 R2 e Windows Server 2008 R2 come documentato in questa guida, supporta qualsiasi versione di Windows Server, dal 2008 R2 attraverso Windows Server 2019 e qualsiasi versione di SQL Server da da SQL Server 2008 attraverso SQL Server 2019.
Questa guida illustrerà il processo di creazione di un’istanza cluster di failover (FCI) SQL Server 2008 R2 a due nodi in Azure, in esecuzione su Windows Server 2008 R2. Sebbene SIOS DataKeeper supporti anche cluster che si estendono su zone o regioni di disponibilità, questa guida presuppone che ciascun nodo risieda nella stessa regione di Azure, ma in domini di errore diversi. SIOS DataKeeper verrà utilizzato al posto dello storage condiviso normalmente richiesto per creare un FCI SQL Server 2008 R2.
Pre-requisiti
Active Directory
Questa guida presuppone che si disponga di un dominio Active Directory esistente. È possibile gestire i propri controller di dominio o utilizzare Azure Active Directory Domain Services. Per questo tutorial ci collegheremo a un dominio chiamato contoso.locale. Naturalmente ti connetterai al tuo dominio quando segui questo tutorial.
Aprire le porte del firewall
– SQL Server: 1433 per l’istanza predefinita
– Load Balancer Health Probe: 59999
– DataKeeper: queste regole del firewall vengono aggiunte automaticamente al firewall basato su host di Windows durante l’installazione. Per i dettagli su quali porte sono aperte consultare la documentazione SIOS.
– Tieni presente che se hai una sicurezza basata sulla rete che blocca le porte tra i nodi del cluster, dovrai tenere conto anche di queste porte.
Account del servizio DataKeeper
Crea un account di dominio. Specificheremo questo account quando installiamo DataKeeper. Questo account dovrà essere aggiunto al gruppo Amministratori locali su ciascun nodo del cluster.
Crea la prima istanza di SQL Server in Azure
Questa guida sfrutterà l’immagine SQL Server 2008R2SP3 su Windows Server 2008R2 pubblicata in Azure Marketplace.
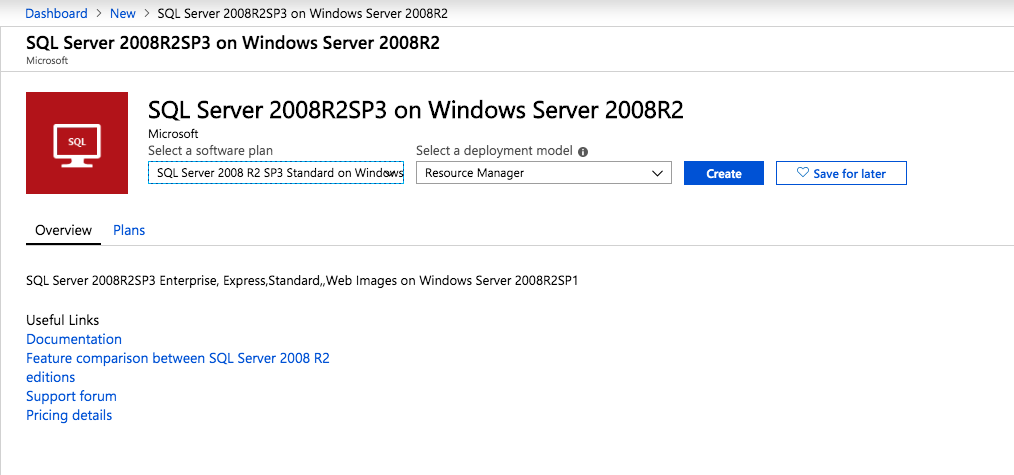
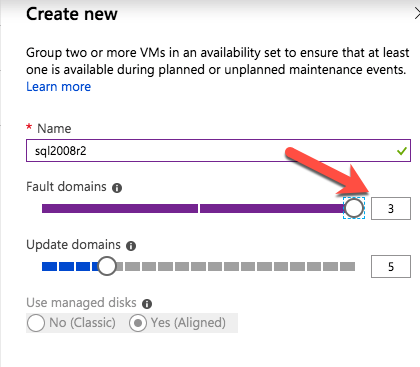
Quando si esegue il provisioning della prima istanza, sarà necessario creare un nuovo set di disponibilità. Durante questo processo assicurarsi di aumentare il numero di domini di errore a 3. Ciò consente ai due nodi cluster e al file share witness di risiedere ciascuno nel proprio dominio di errore.
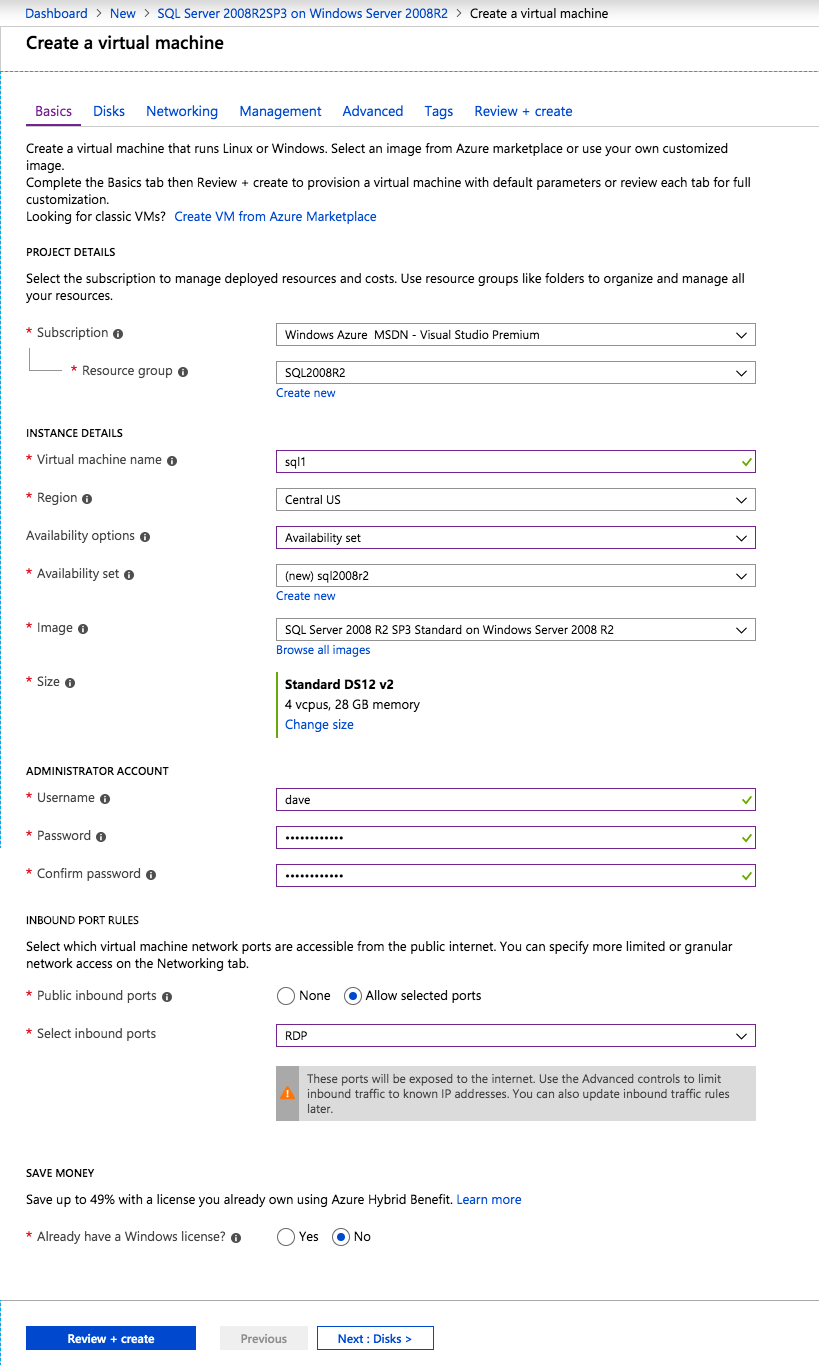
Se non hai già configurato una rete virtuale, consenti alla creazione guidata di crearne una nuova per te.
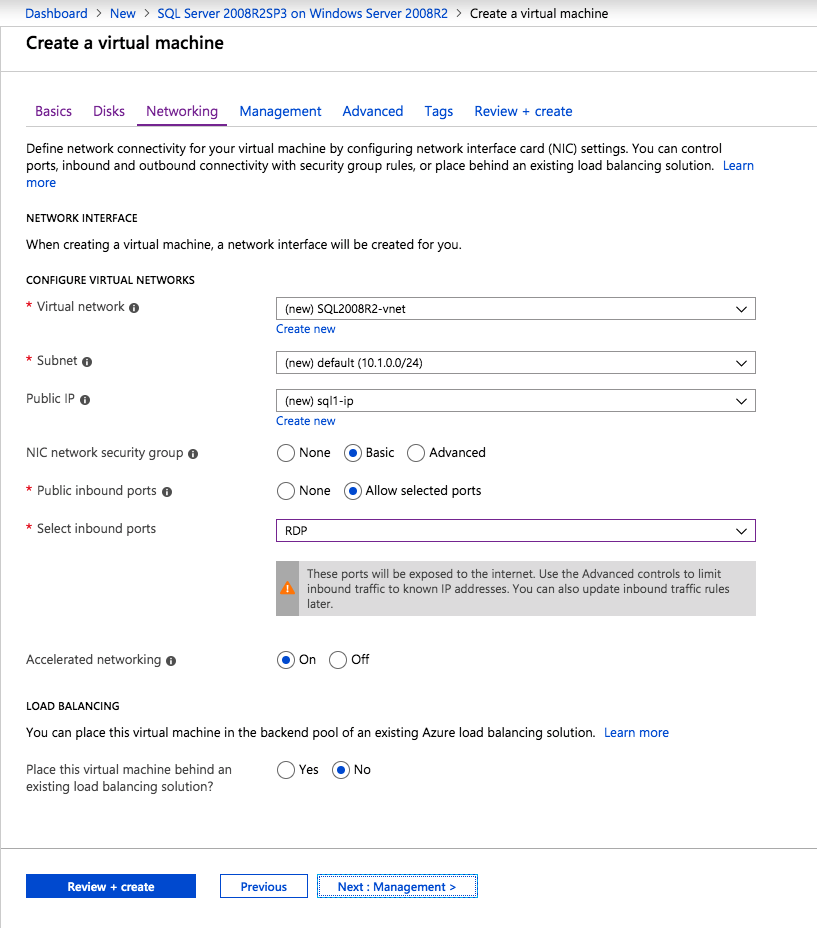
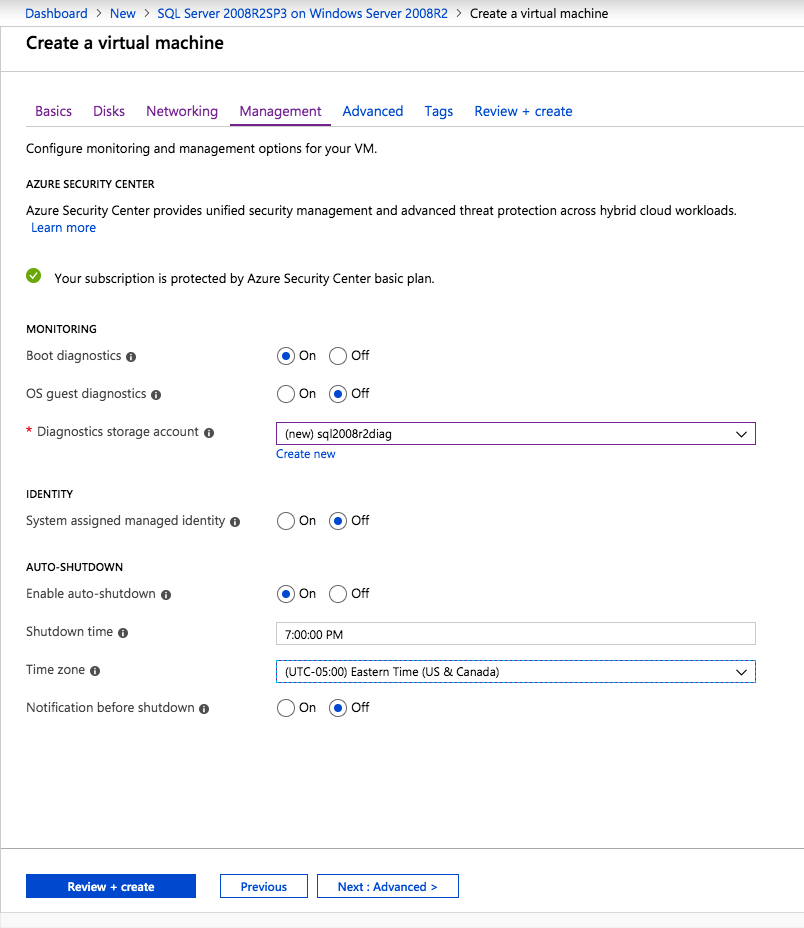
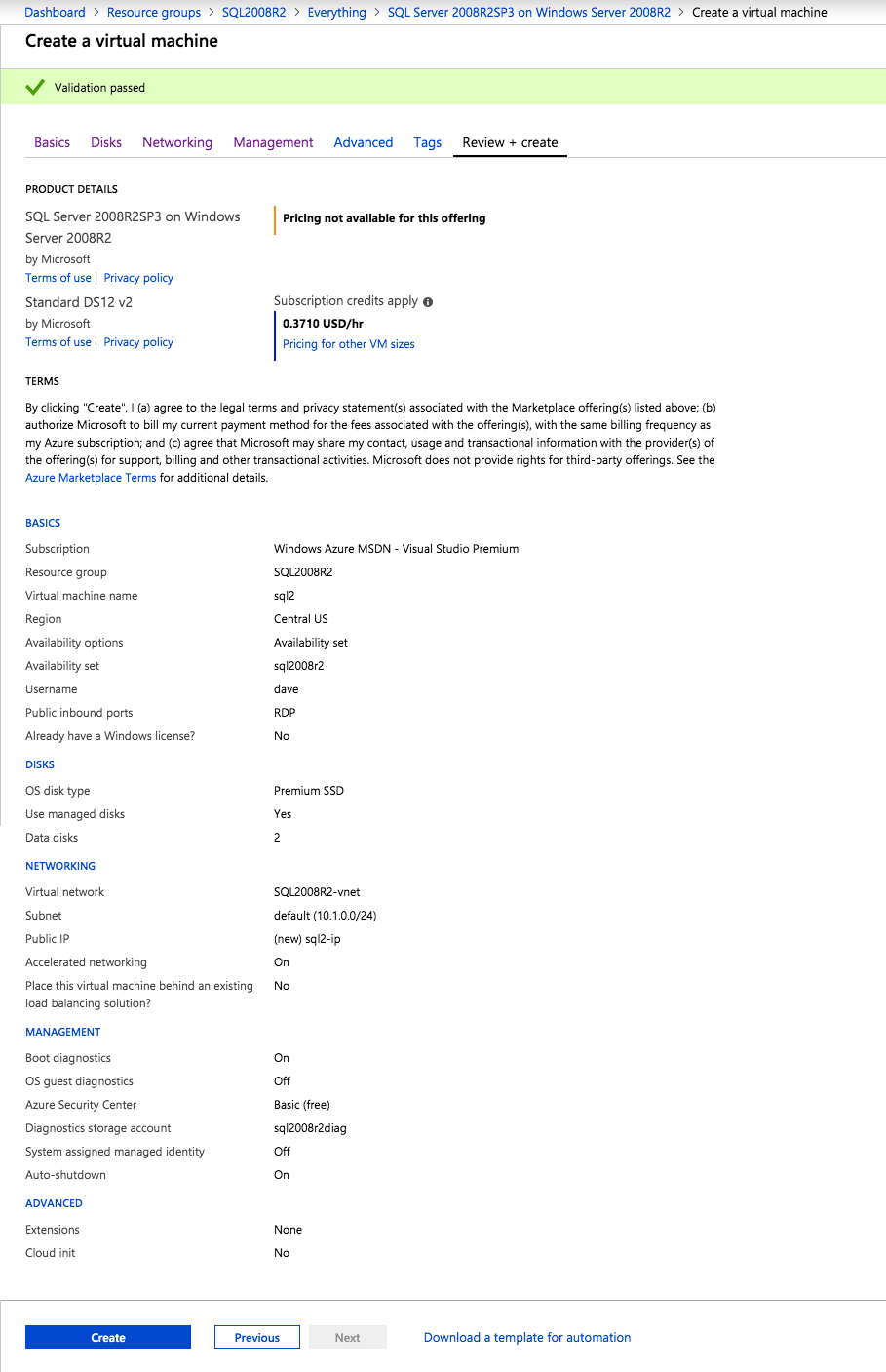
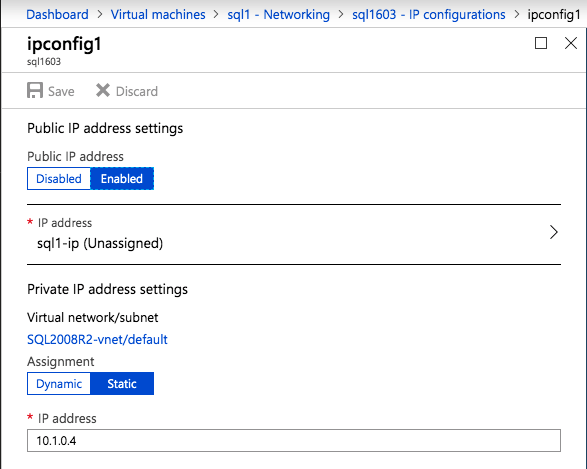
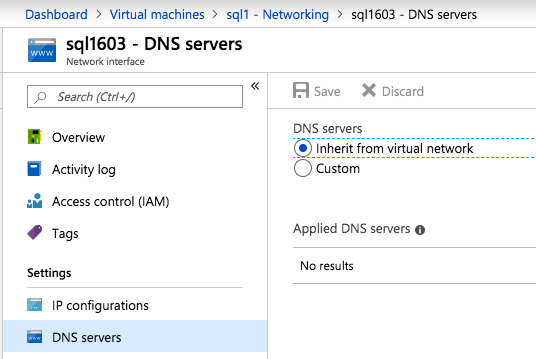
Una volta creata l’istanza, accedere alle configurazioni IP e rendere statico l’indirizzo IP privato. Questo è necessario per SIOS DataKeeper ed è la migliore pratica per le istanze in cluster.
Assicurati che la tua rete virtuale sia configurata per impostare il server DNS come controller Windows AD locale per assicurarti di poter unire il dominio in un passaggio successivo.
Dopo il provisioning delle macchine virtuali, aggiungere almeno due dischi aggiuntivi a ciascuna istanza. Premium o Ultra SSD sono raccomandati. Disabilitare la memorizzazione nella cache sui dischi utilizzati per i file di registro SQL. Abilitare la memorizzazione nella cache di sola lettura sul disco utilizzato per i file di dati SQL. Per ulteriori informazioni sulle best practice di archiviazione, consultare le Linee guida sulle prestazioni di SQL Server nelle macchine virtuali Azure.
Crea la 2a istanza di SQL Server in Azure
Segui gli stessi passaggi di cui sopra, ad eccezione di assicurarsi di posizionare questa istanza nello stesso set di rete virtuale e disponibilità creato con la 1a istanza.
Creare un’istanza FSW (File Share Witness)
Affinché il cluster di failover di Windows Server (WSFC) funzioni in modo ottimale, è necessario creare un’altra istanza di Windows Server e posizionarla nello stesso set di disponibilità delle istanze di SQL Server. Posizionandolo nello stesso set di disponibilità, assicurarsi che ciascun nodo cluster e l’FSW risiedano in domini di errore diversi, assicurando che il cluster rimanga attivo se un intero dominio di errore non è attivo. Questa istanza non richiede SQL Server, può essere un semplice server Windows in quanto tutto ciò che deve fare è ospitare una semplice condivisione di file.
Questa istanza ospiterà il file share witness richiesto da WSFC. Questa istanza non ha bisogno di avere le stesse dimensioni, né richiede alcun disco aggiuntivo da collegare. Il suo unico scopo è quello di ospitare una semplice condivisione di file. Può infatti essere utilizzato per altri scopi. Nel mio ambiente di laboratorio il mio FSW è anche il mio controller di dominio.
Disinstalla SQL Server 2008 R2
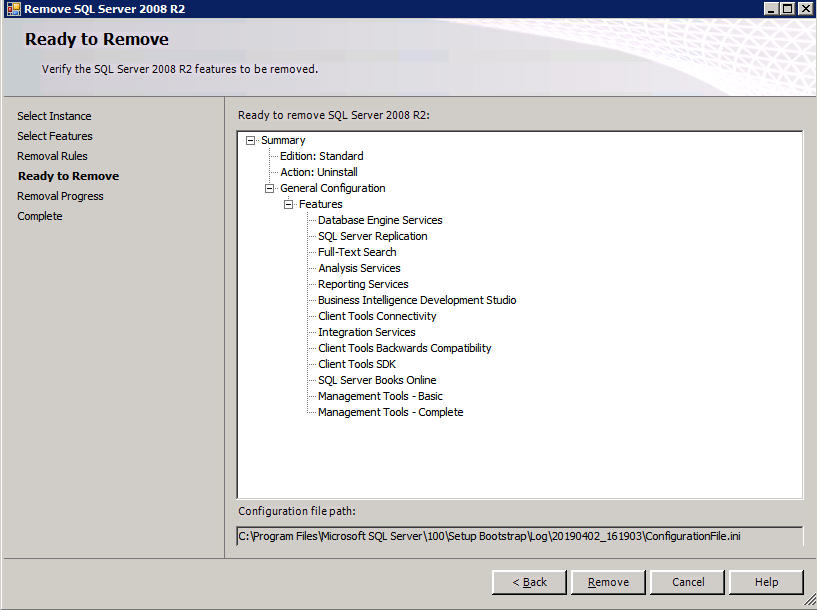
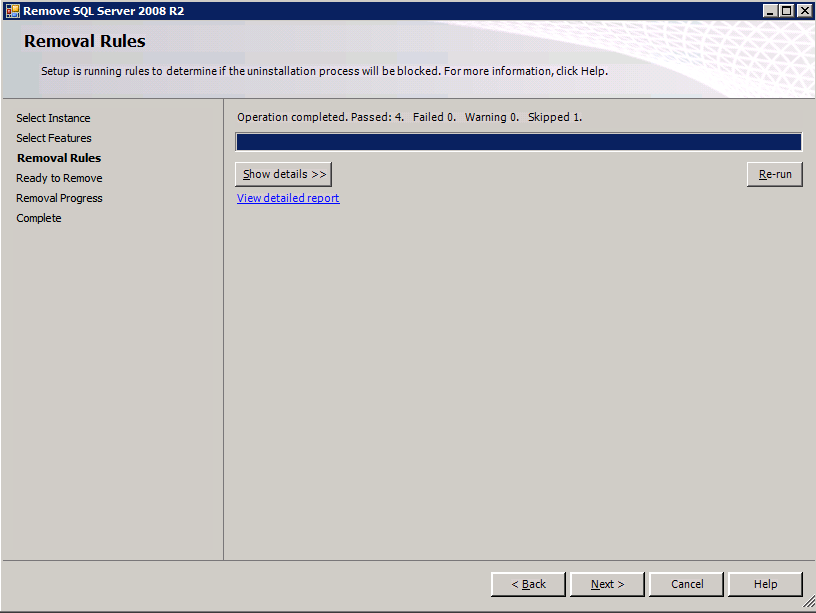
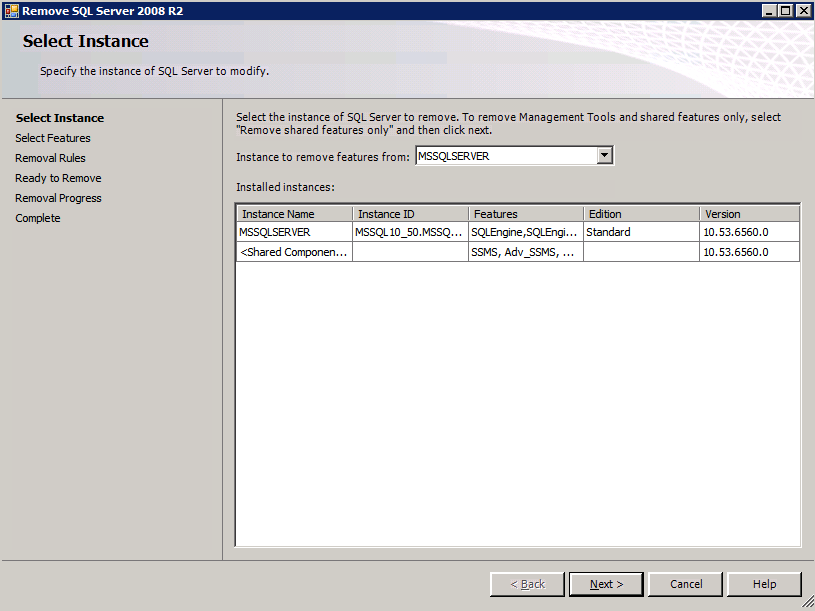
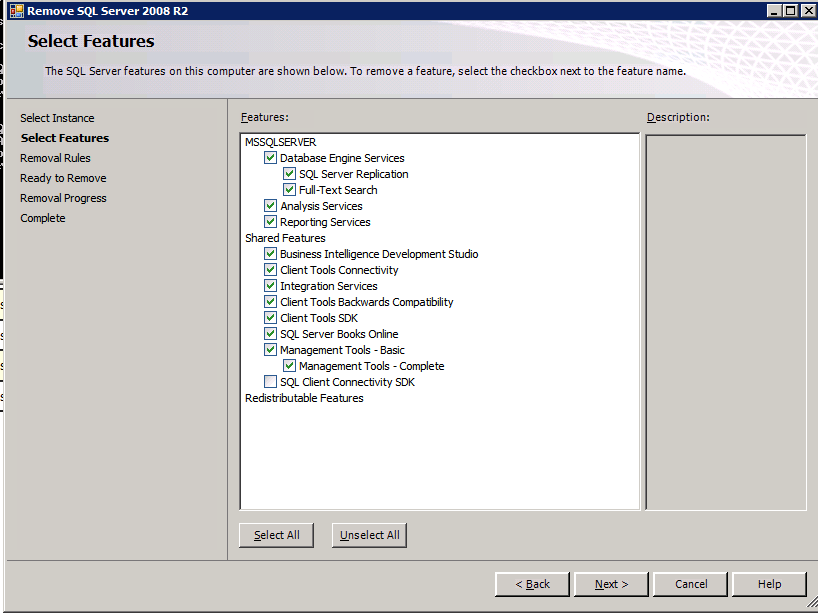
In ciascuna delle due istanze di SQL Server fornite è già installato SQL Server 2008 R2. Tuttavia, vengono installati come istanze SQL Server standalone, non in cluster. SQL Server deve essere disinstallato da ciascuna di queste istanze prima di poter installare l’istanza del cluster. Il modo più semplice per farlo è eseguire l’installazione SQL come mostrato di seguito.
Quando si esegue l’installazione.exe / Action-RunDiscovery vedrai tutto ciò che è preinstallato
setup.exe /Action=RunDiscovery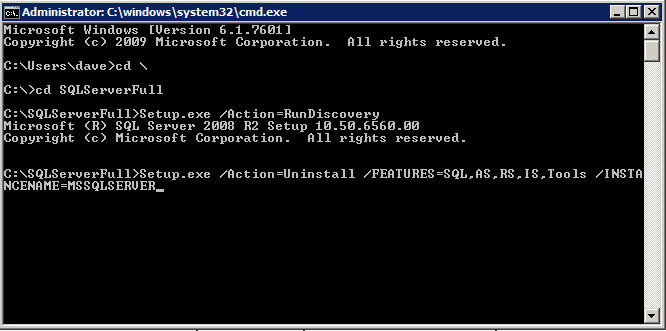

Configurazione in esecuzione.exe / Action = Uninstall / FEATURES = SQL, AS, RS,IS, Tools / INSTANCENAME=MSSQLSERVER avvia il processo di disinstallazione
setup.exe /Action=Uninstall /FEATURES=SQL,AS,RS,IS,Tools /INSTANCENAME=MSSQLSERVER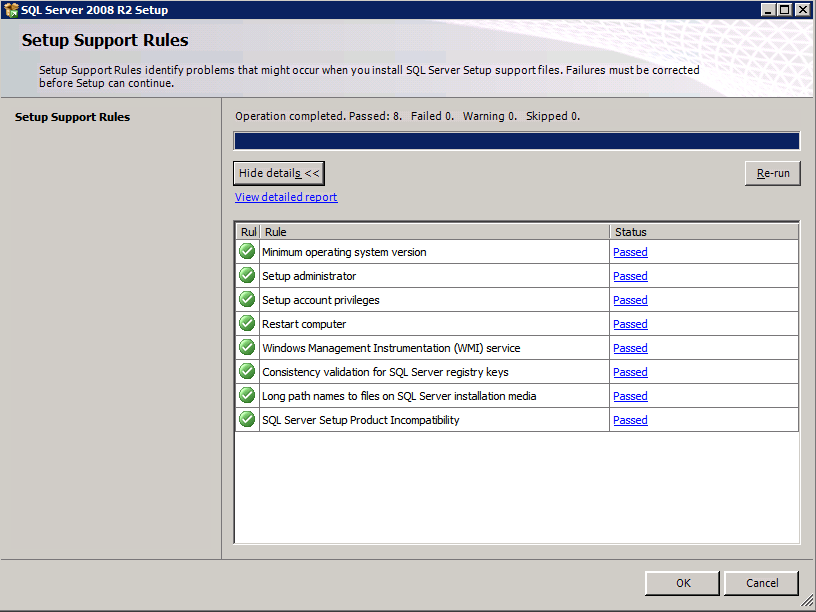
Configurazione in esecuzione.exe / Action-RunDiscovery conferma il completamento della disinstallazione
setup.exe /Action-RunDiscovery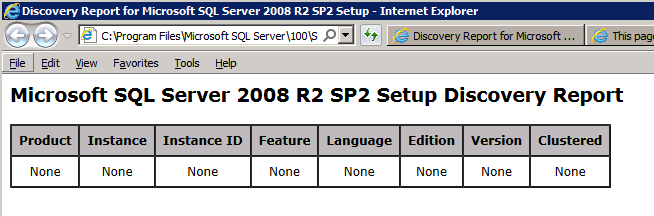
Eseguire nuovamente questo processo di disinstallazione sulla 2a istanza.
Aggiungi istanze al dominio
Tutte e tre queste istanze dovranno essere aggiunte a un dominio Windows. Come menzionato nella sezione Prerequisiti, è necessario avere accesso a partecipare a una directory attiva di Windows esistente. Nel nostro caso, stiamo unendo un dominio chiamato contoso.locale.
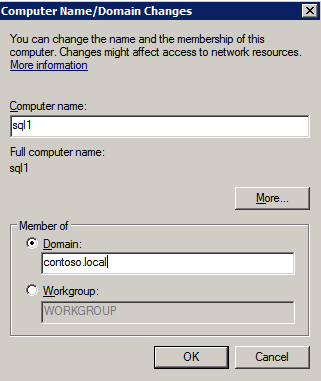
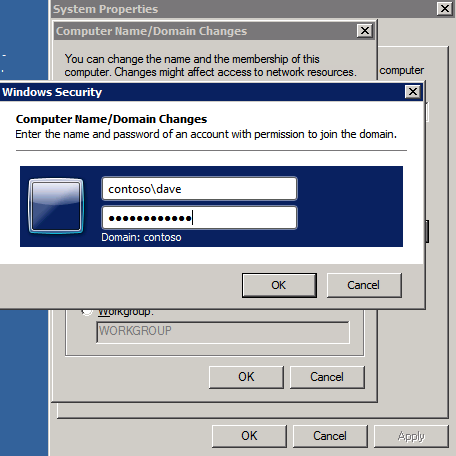
Aggiungere Funzionalità di Clustering di Failover di Windows
La Funzionalità di Clustering di Failover deve essere aggiunto a due istanze di SQL Server
Add-WindowsFeature Failover-Clustering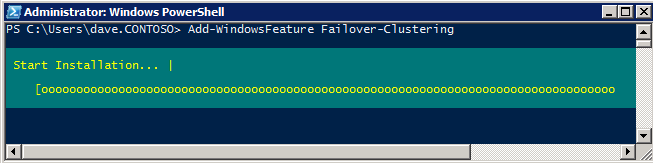
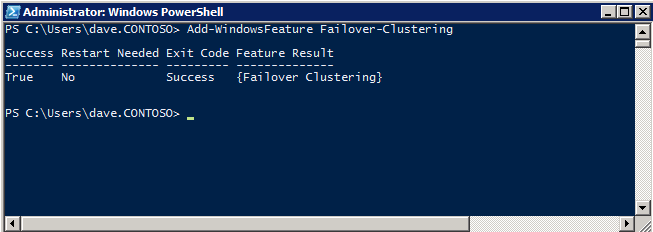
Installare la Convenienza di Rollup di Aggiornamento per Windows Server 2008 R2 SP1
C’è un aggiornamento critico ( kb2854082) che è necessario al fine di configurare un Server Windows 2008 R2 istanza in Azure. Tale aggiornamento e molti altri sono inclusi nell’aggiornamento Rollup convenienza per Windows Server 2008 R2 SP1. Installare questo aggiornamento su ciascuna delle due istanze di SQL Server.
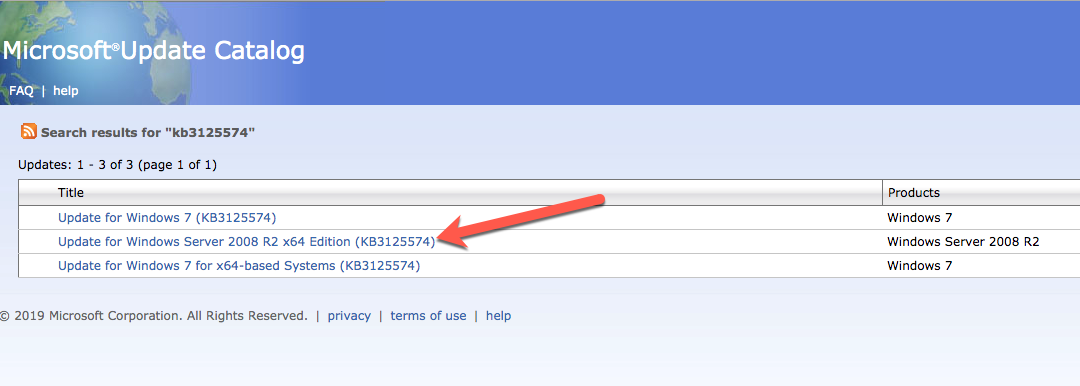
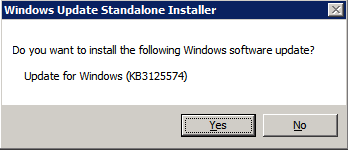
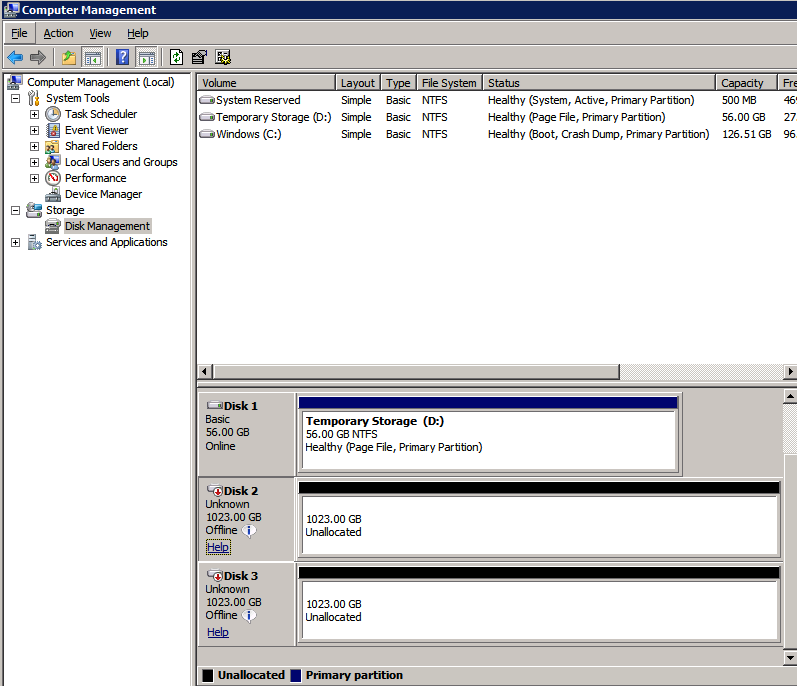
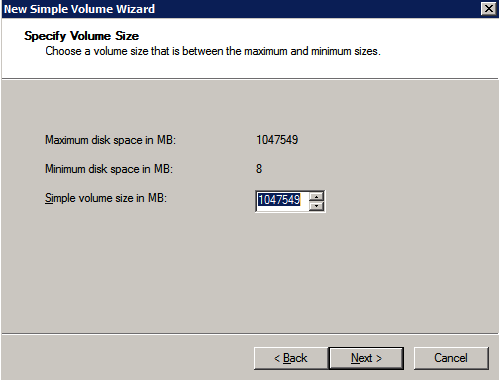
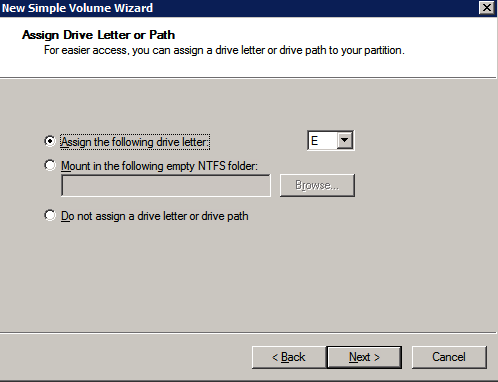
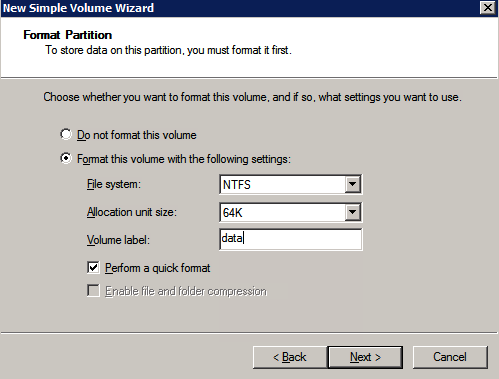
Formattare lo storage
È necessario formattare i dischi aggiuntivi collegati al provisioning delle due istanze di SQL Server. Effettuare le seguenti operazioni per ogni volume su ogni istanza.
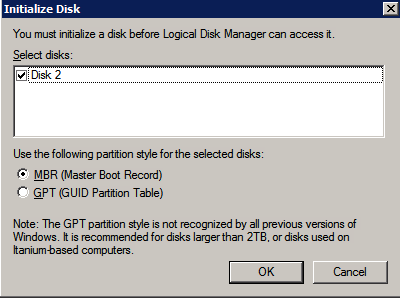
Microsoft best practice dice quanto segue
” Dimensione unità di allocazione NTFS: Quando si formatta il disco dati, si consiglia di utilizzare una dimensione dell’unità di allocazione di 64 KB per i file di dati e log e TempDB.”
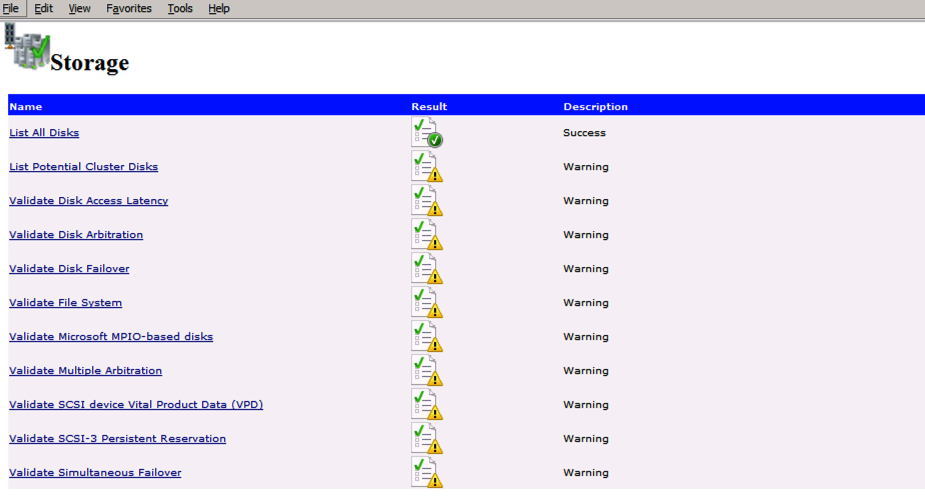
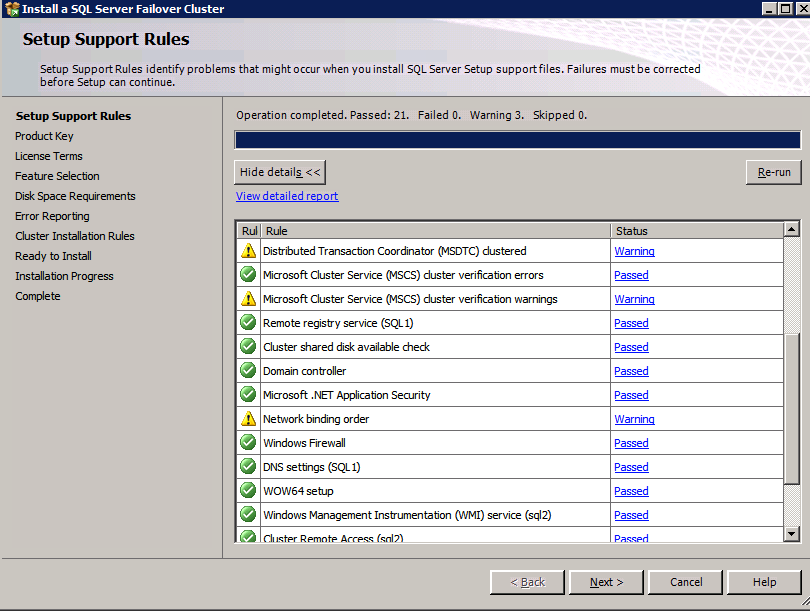
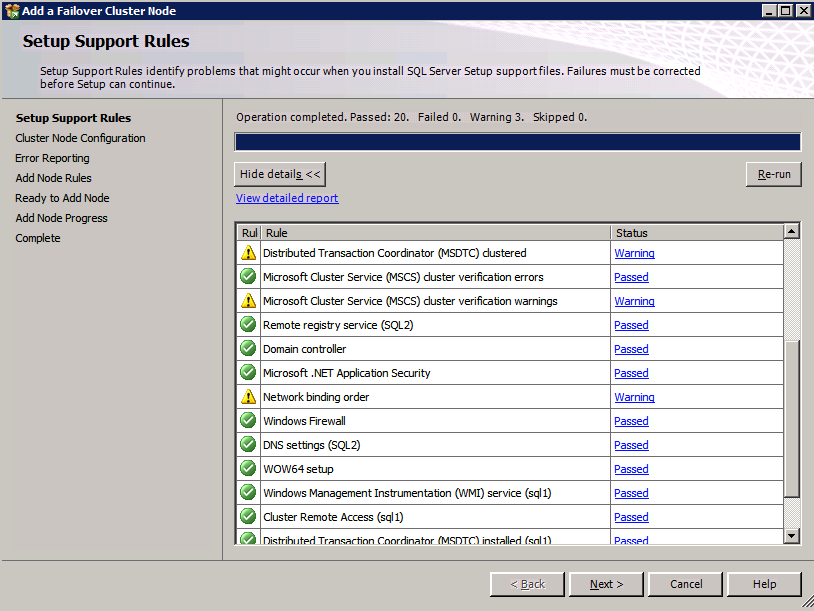
Esegui la convalida del cluster
Esegui la convalida del cluster per garantire che tutto sia pronto per essere cluster.
Import-Module FailoverClustersTest-Cluster -Node "SQL1", "SQL2"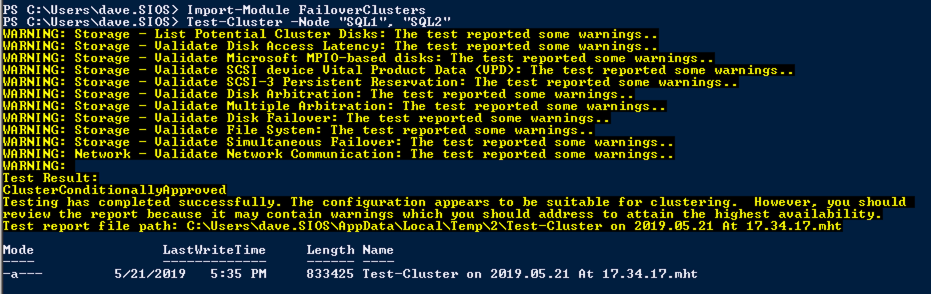
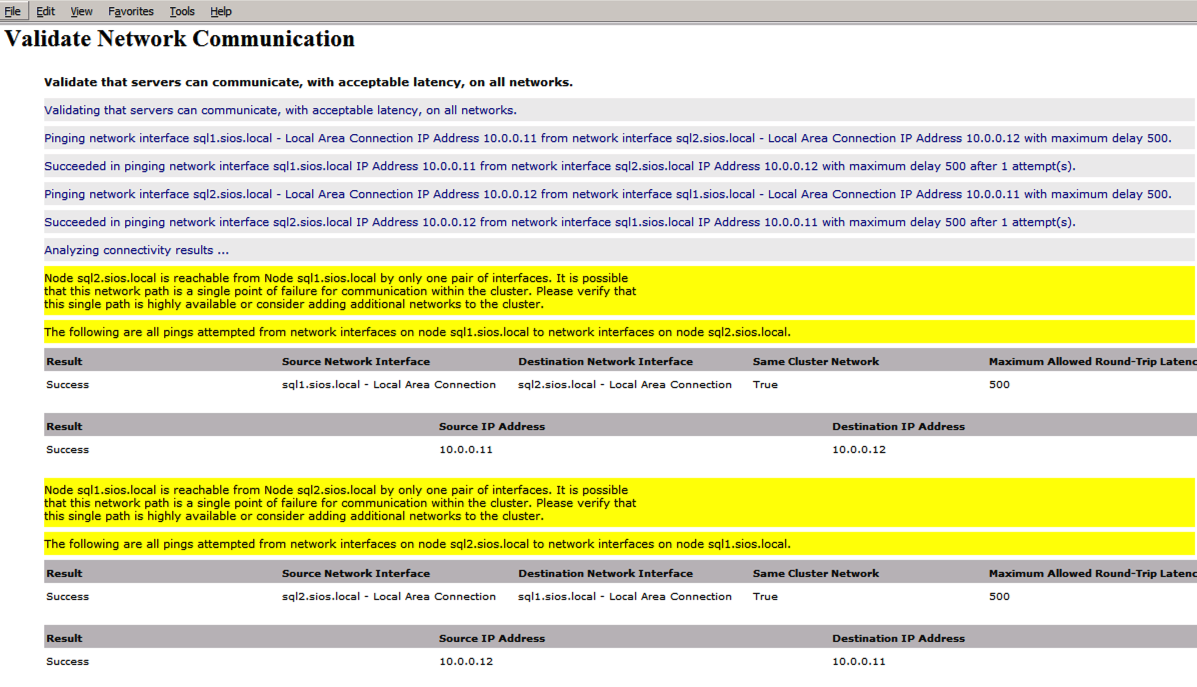
Il report conterrà AVVISI su archiviazione e rete. È possibile ignorare tali avvisi come sappiamo non ci sono dischi condivisi e solo una singola connessione di rete esiste tra i server. È inoltre possibile ricevere un avviso sull’ordine di associazione della rete che può anche essere ignorato. Se si verificano errori è necessario affrontare quelli prima di continuare.
Errore nel tentativo di eseguire la convalida del cluster?
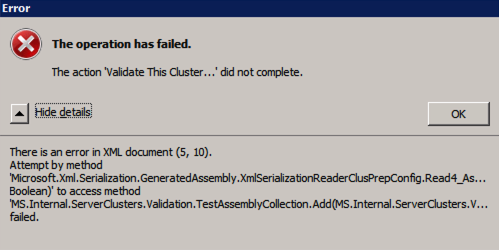
Ho riscontrato questo errore in alcune occasioni e sto ancora cercando di capire in quali condizioni si verifica. Di tanto in tanto troverete che test-cluster non riesce a funzionare come descritto nel post del forum.
Test-ClusterUnable to Validate a Cluster Configuration. The operation has failed. The action validate a configuration did not completeThere is an error in XML document (5, 73). Attempt by methodMicrosoft.Xml.Serialzation.GeneratedAssembly.XmlSerialzationReaderClusterPrep.Config.Read4_As...Bolean) to access methodMS.Internal.ServerClusters.Validation.TestAssemblyCollection.Add(MS.Internal.ServerClusters.V....FailedSe questo accade a voi, ho trovato la seguente correzione consigliata nel post del forum funziona per me.
Inside C:\Windows\System32\WindowsPowerShell\v1.0 make a copy of powershell_ise.exe.config file (make a copy inside C:\Windows\System32\WindowsPowerShell\v1.0)- rename it to powershell.exe.configOpen it with notepad- delete current config line and paste:<?xml version="1.0" encoding="utf-8" ?><configuration> <system.xml.serialization> <xmlSerializer useLegacySerializerGeneration="true"/> </system.xml.serialization></configuration>- save and run test-clusterMentre questa correzione ti consentirà di eseguire test-cluster da Powershell, ho scoperto che l’esecuzione di Validate attraverso la GUI genera ancora un errore, anche con questa correzione. Ho una query in Microsoft per vedere se hanno una soluzione, ma per ora se è necessario eseguire la convalida del cluster potrebbe essere necessario utilizzare Test-Cluster in Powershell.
Creare il cluster
Le best practice per la creazione di un cluster in Azure consistono nell’utilizzare Powershell per creare un cluster, specificando un indirizzo IP statico. Powershell ci consente di specificare un indirizzo IP statico, mentre il metodo GUI no. Sfortunatamente, l’implementazione di DHCP di Azure non funziona bene con WSFC, quindi se si utilizza il metodo GUI si finirà con un indirizzo IP duplicato come indirizzo IP del cluster che dovrà essere corretto prima che il cluster sia utilizzabile.
Tuttavia, quello che ho trovato è che il tipico comando powershell New-Cluster con il comando-StaticAddress non funziona. Per evitare il problema dell’indirizzo IP duplicato, dobbiamo ricorrere al cluster.utility exe ed eseguire il seguente comando.
cluster /cluster:cluster1 /create /nodes:"sql1 sql2" /ipaddress:10.0.0.100/255.255.255.0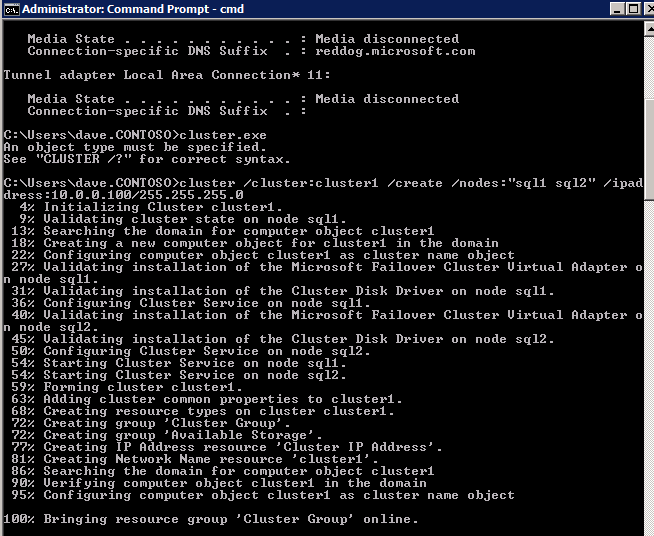
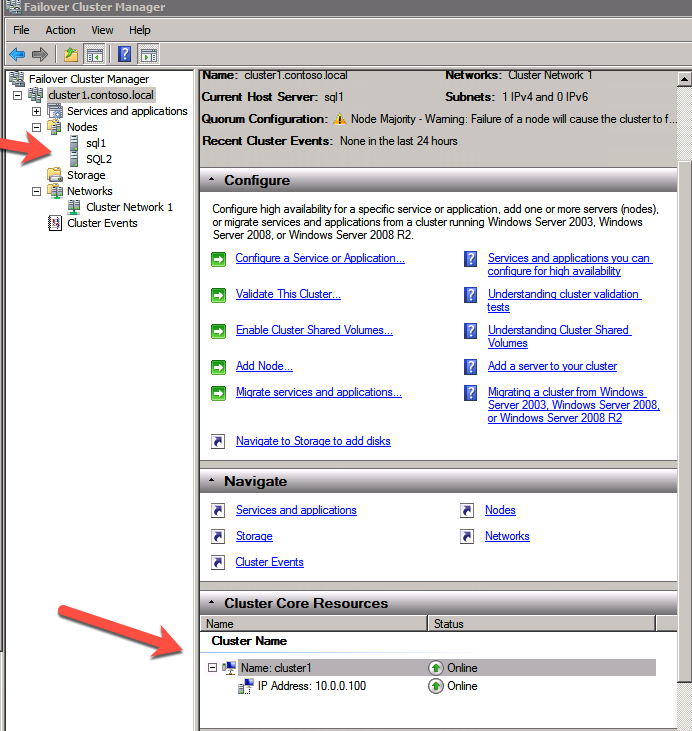
Aggiungi il File Share Witness
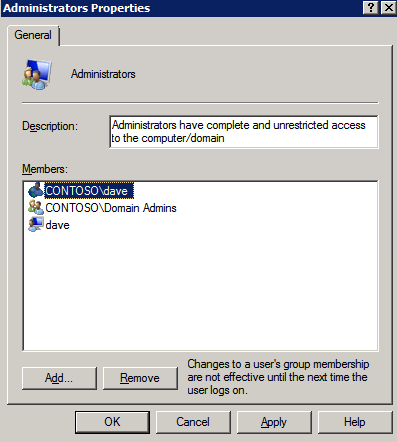
Quindi dobbiamo aggiungere il File Share Witness. Sul server 3rd abbiamo eseguito il provisioning come FSW, creare una cartella e condividerla come mostrato di seguito. Sarà necessario concedere al Cluster Name Object (CNO) le autorizzazioni di lettura/scrittura sia a livello di condivisione che di sicurezza come mostrato di seguito.
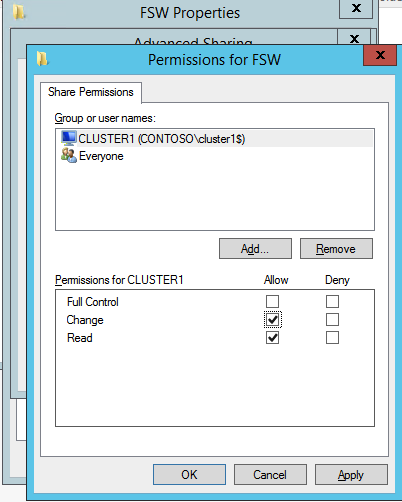
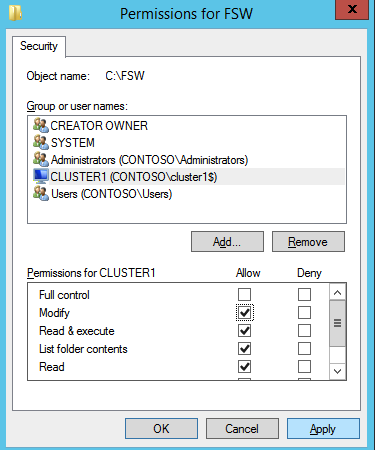
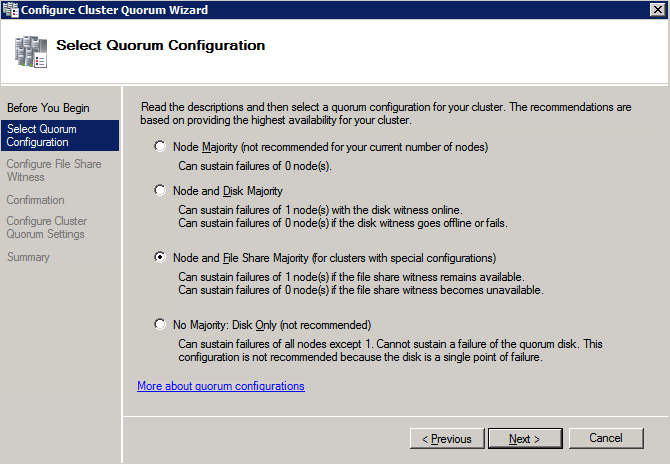
Una volta creata la condivisione, eseguire la configurazione guidata Quorum cluster su uno dei nodi cluster e seguire i passaggi illustrati di seguito.
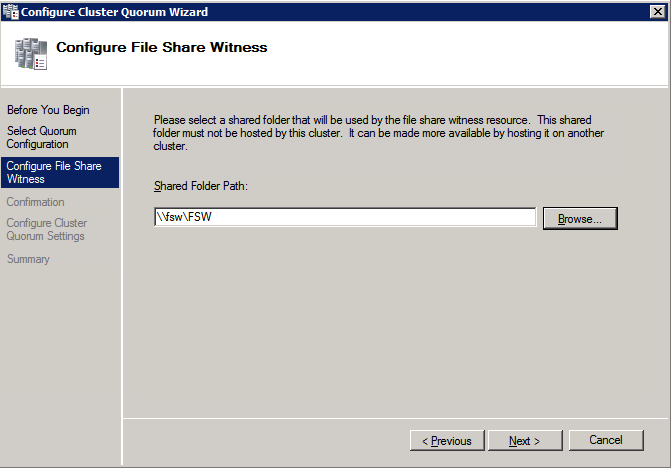
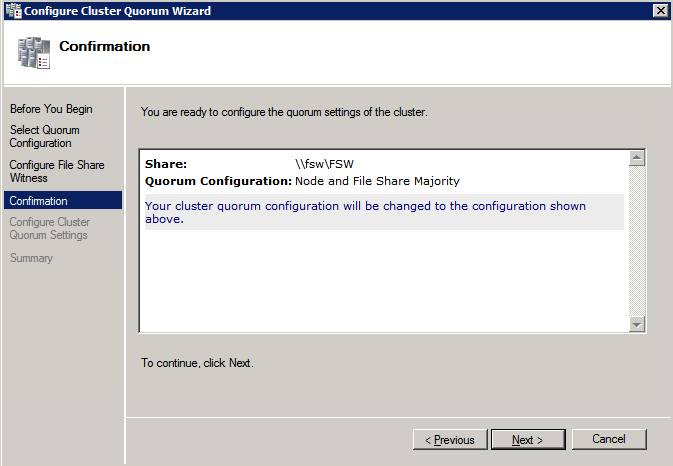
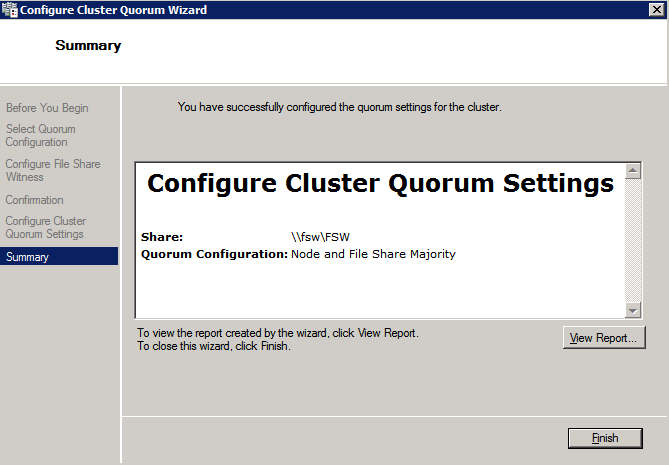
Installa DataKeeper
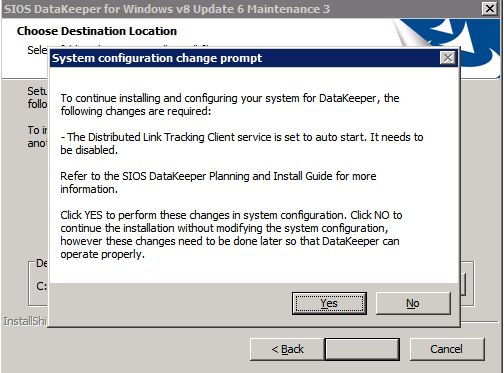
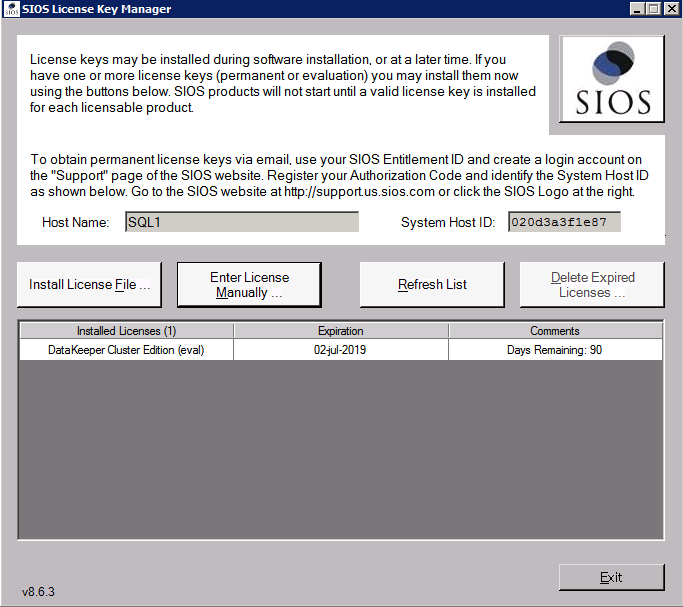
Installa DataKeeper su ciascuno dei due nodi cluster di SQL Server come mostrato di seguito.
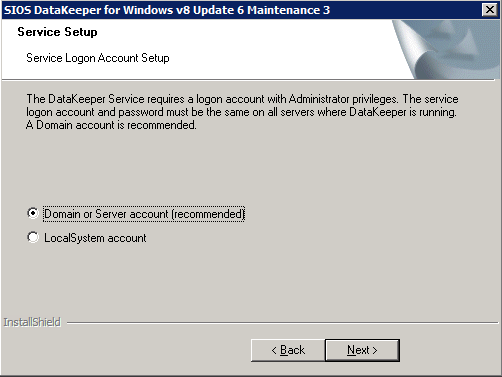
È qui che specificheremo l’account di dominio che abbiamo aggiunto a ciascuno del gruppo Local Domain Administrators.
Configurare DataKeeper
Una volta installato DataKeeper su ciascuno dei due nodi del cluster, si è pronti per configurare DataKeeper.
NOTA: l’errore più comune riscontrato nei passaggi seguenti è relativo alla sicurezza, il più delle volte da gruppi di sicurezza di Azure preesistenti che bloccano le porte richieste. Fare riferimento alla documentazione SIOS per garantire che i server possano comunicare attraverso le porte richieste.
Per prima cosa è necessario connettersi a ciascuno dei due nodi.
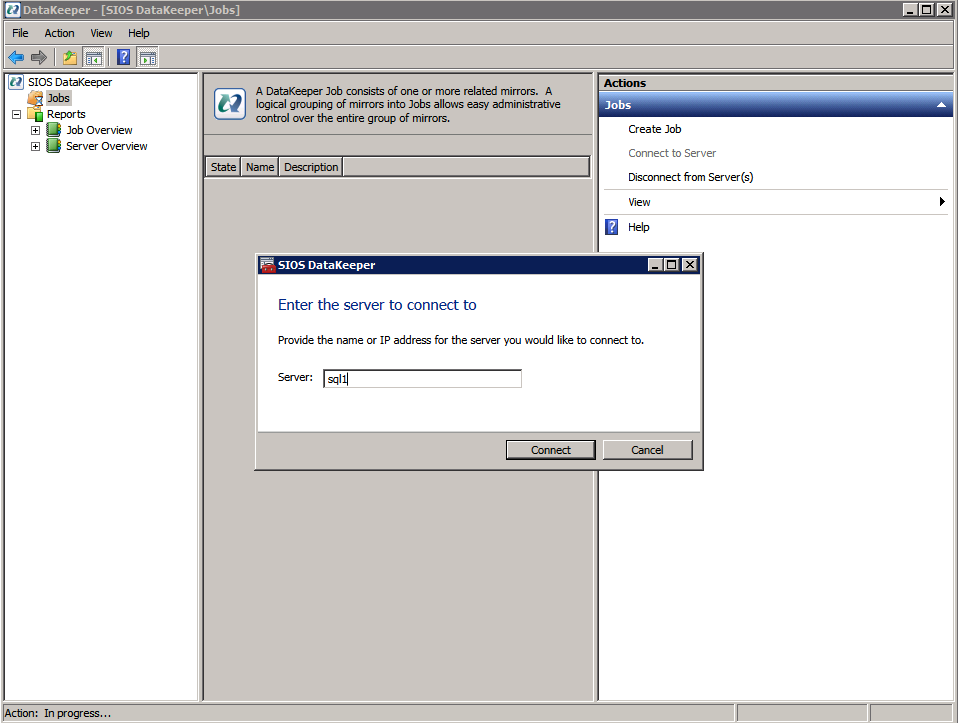
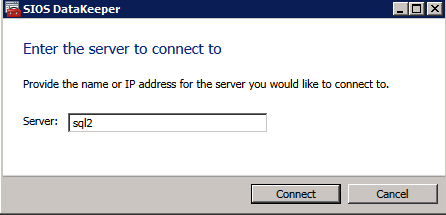
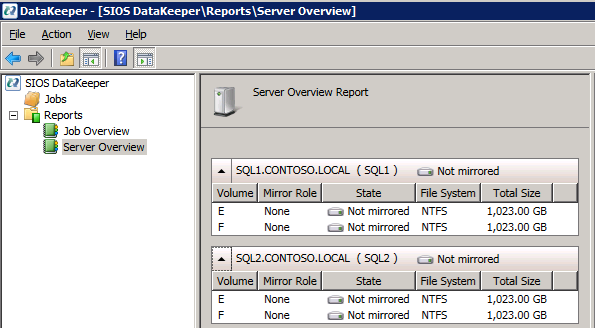
Se tutto è configurato correttamente, è necessario visualizzare quanto segue nel report Panoramica del server.
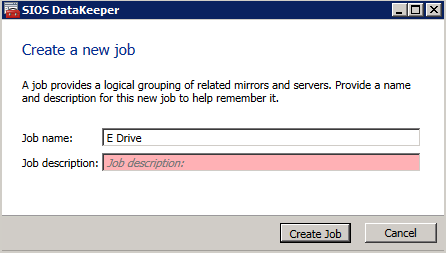
successivamente, creare un Nuovo Lavoro e seguire la procedura illustrata di seguito
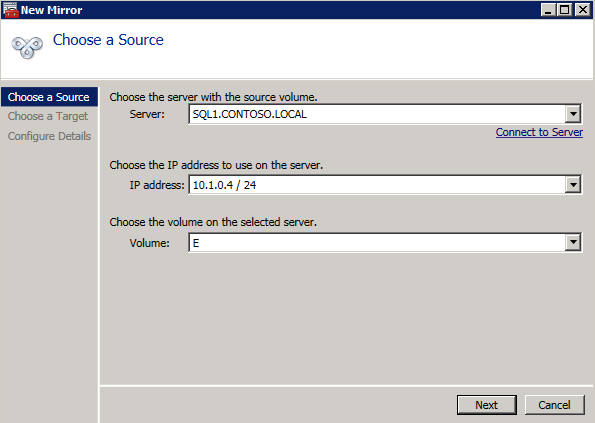
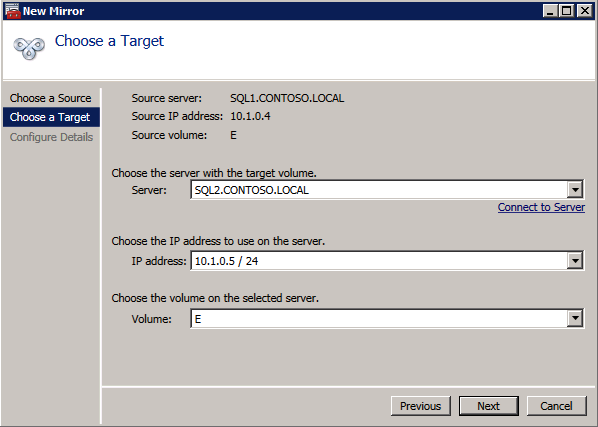
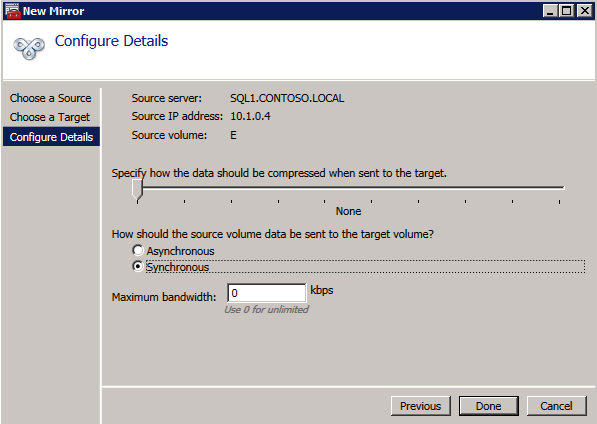
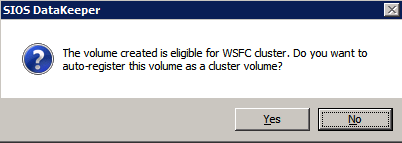
Scegliere Sì qui per registrare i DataKeeper Volume di risorsa di Archiviazione Disponibile
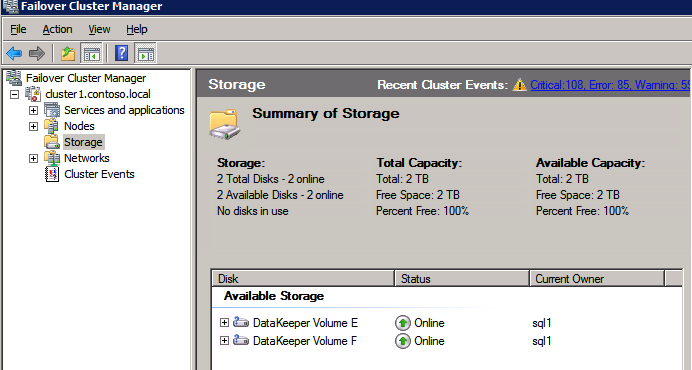
Completare la procedura sopra descritta per ogni volume. Una volta che hai finito, dovresti vedere quanto segue nell’interfaccia utente WSFC.
Ora sei pronto per installare SQL Server nel cluster.
NOTA: a questo punto il volume replicato è accessibile solo sul nodo che attualmente ospita lo storage disponibile. Questo è previsto, quindi non preoccuparti!
Installa SQL Server sul primo nodo
Se si desidera eseguire lo script dell’installazione, ho incluso l’esempio seguente di un’installazione del cluster con script di SQL Server 2008 R2 nel primo nodo del cluster. Lo script per aggiungere un nodo al cluster esistente si trova più in basso nella guida.
Naturalmente regolare per il vostro ambiente.
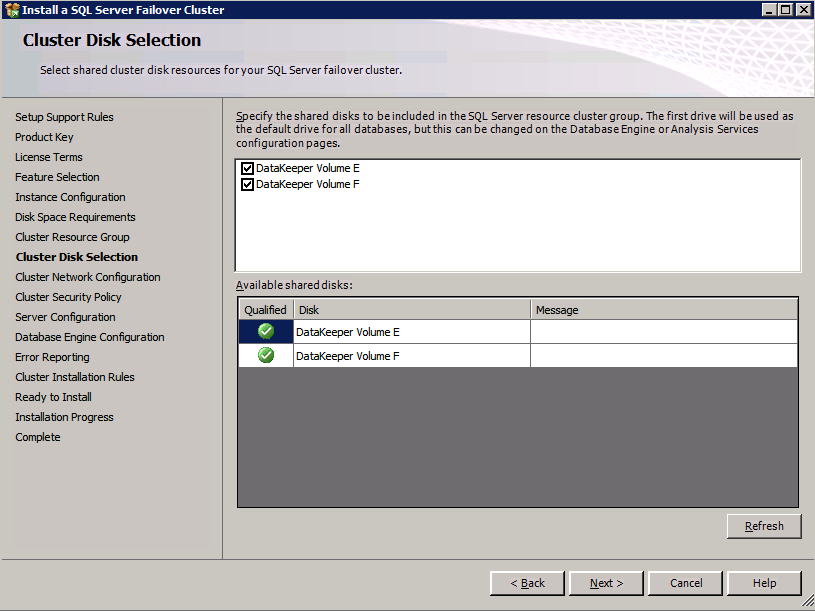
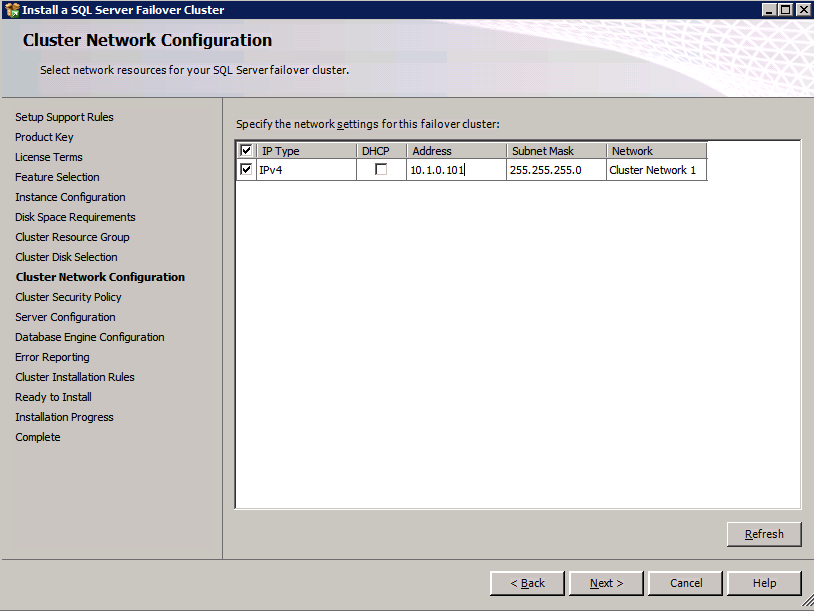
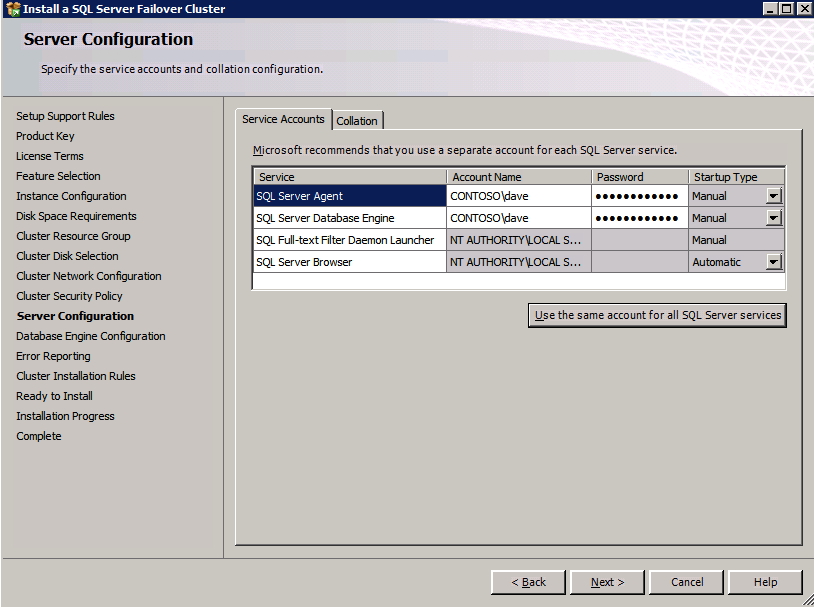
c:\SQLServerFull\setup.exe /q /ACTION=InstallFailoverCluster /FEATURES=SQL /INSTANCENAME="MSSQLSERVER" /INSTANCEDIR="C:\Program Files\Microsoft SQL Server" /INSTALLSHAREDDIR="C:\Program Files\Microsoft SQL Server" /SQLSVCACCOUNT="contoso\admin" /SQLSVCPASSWORD="xxxxxxxxx" /AGTSVCACCOUNT="contoso\admin" /AGTSVCPASSWORD="xxxxxxxxx" /SQLDOMAINGROUP="contoso\SQLAdmins" /AGTDOMAINGROUP="contoso\SQLAdmins" /SQLCOLLATION="SQL_Latin1_General_CP1_CI_AS" /FAILOVERCLUSTERGROUP="SQL Server 2008 R2 Group" /FAILOVERCLUSTERDISKS="DataKeeper Volume E" "DataKeeper Volume F" /FAILOVERCLUSTERIPADDRESSES="IPv4;10.0.0.101;Cluster Network 1;255.255.255.0" /FAILOVERCLUSTERNETWORKNAME="SQL2008Cluster" /SQLSYSADMINACCOUNTS="contoso\admin" /SQLUSERDBLOGDIR="E:\MSSQL10.MSSQLSERVER\MSSQL\Log" /SQLTEMPDBLOGDIR="F:\MSSQL10.MSSQLSERVER\MSSQL\Log" /INSTALLSQLDATADIR="F:\MSSQL10.MSSQLSERVER\MSSQLSERVER" /IAcceptSQLServerLicenseTermsSe si preferisce utilizzare la GUI, basta seguire con gli screenshot qui sotto.
Sul primo nodo, eseguire la configurazione di SQL Server.
Scegliere Nuova installazione del cluster di failover di SQL Server e seguire i passaggi illustrati.
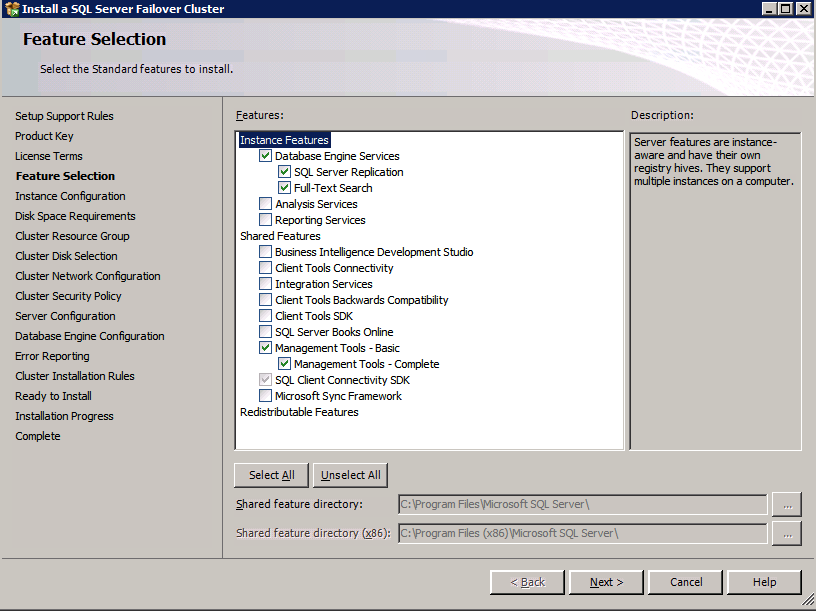
Scegli solo le opzioni che ti servono.
Si noti che questo documento presuppone che si stia utilizzando l’istanza predefinita di SQL Server. Se si utilizza un’istanza con nome, è necessario assicurarsi di bloccare la porta su cui è in ascolto e utilizzare quella porta in seguito quando si configura il bilanciamento del carico. È inoltre necessario creare una regola di bilanciamento del carico per il servizio Browser SQL Server (UDP 1434) per connettersi a un’istanza denominata. Nessuno di questi due requisiti è coperto in questa guida, ma se si richiede un’istanza con nome funzionerà se si eseguono questi due passaggi aggiuntivi.
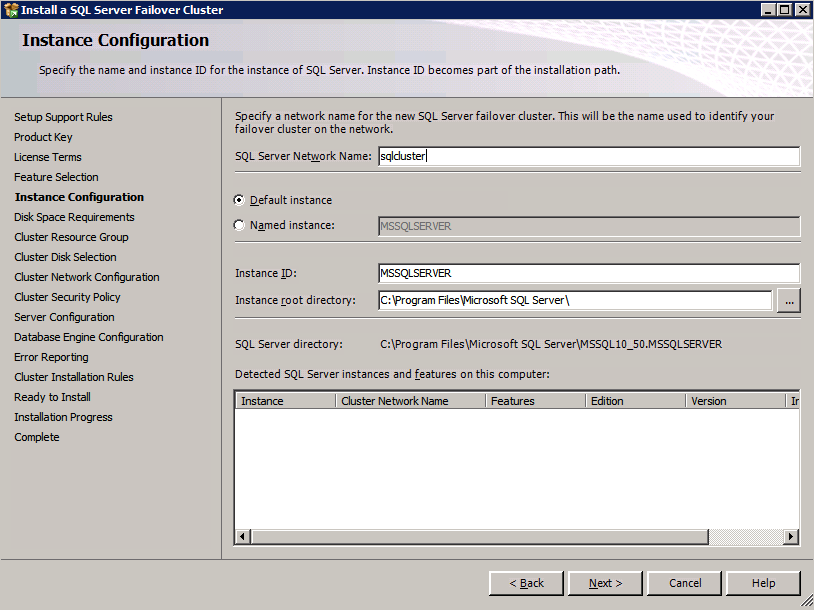
Qui è necessario specificare un indirizzo IP non utilizzato
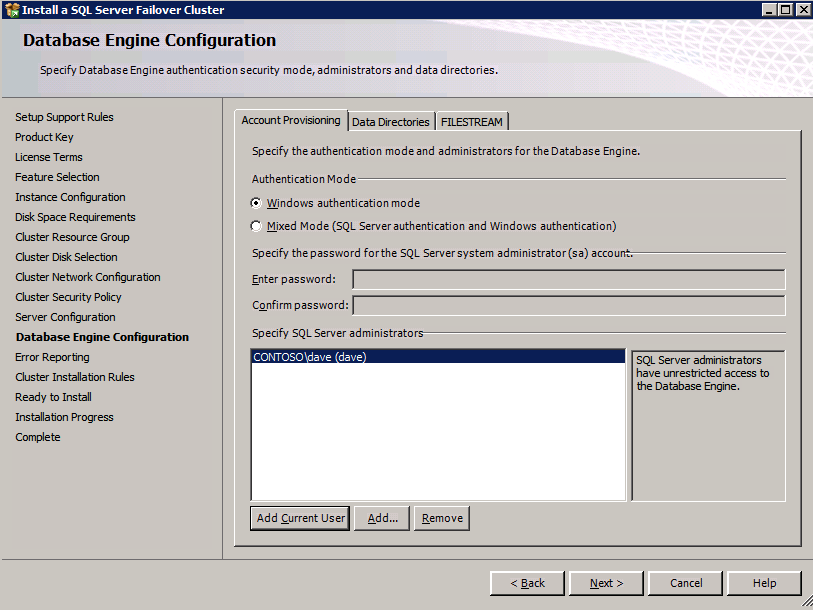
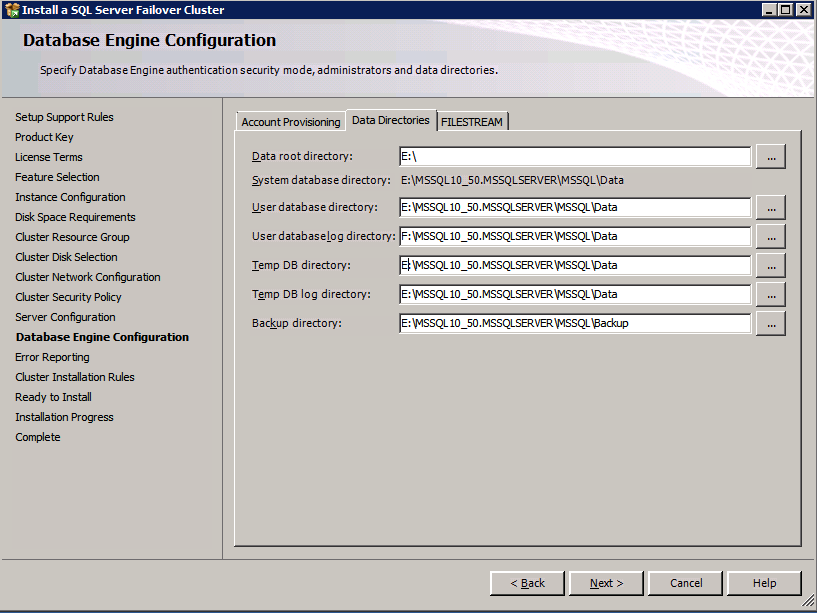
Vai alla scheda Directory Dati e trasferire dati e file di log. Alla fine di questa guida si parla di spostare tempdb a un volume DataKeeper non mirrored per prestazioni ottimali. Per ora, basta tenerlo su uno dei dischi cluster.
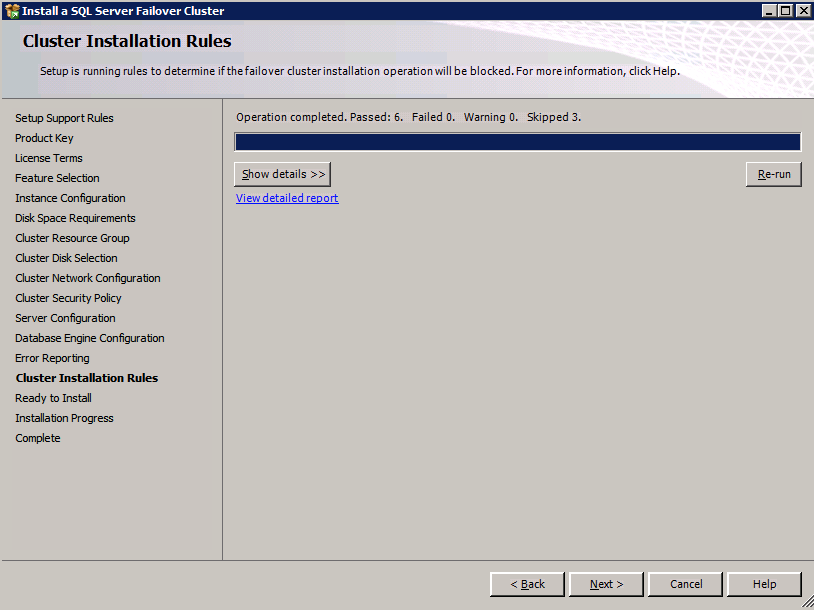
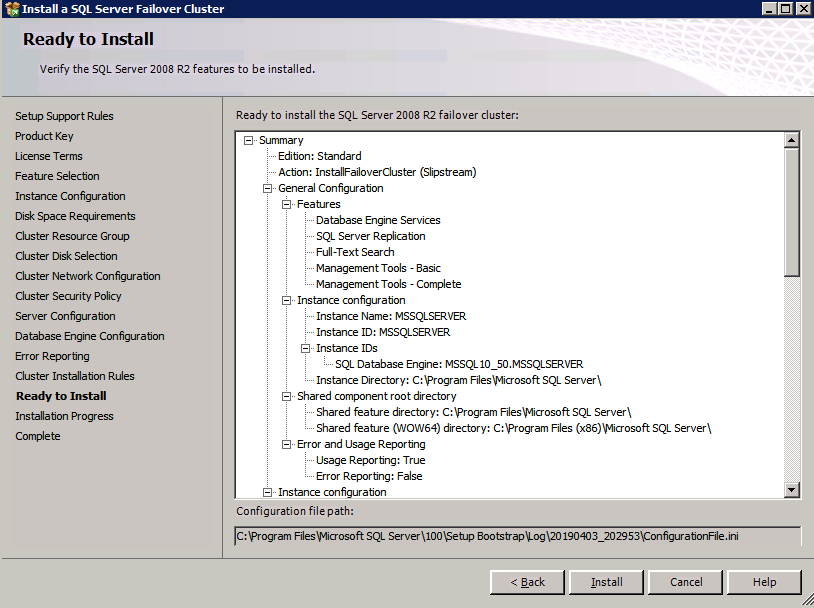
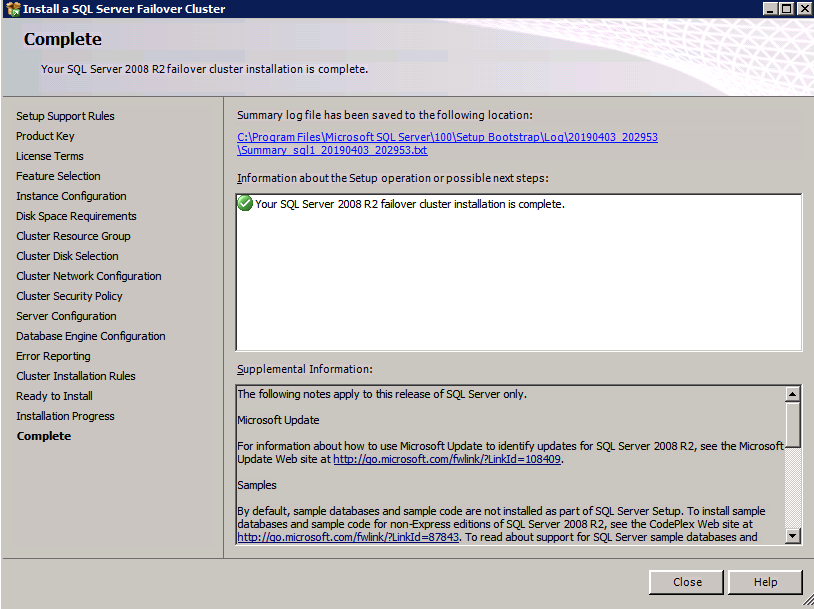
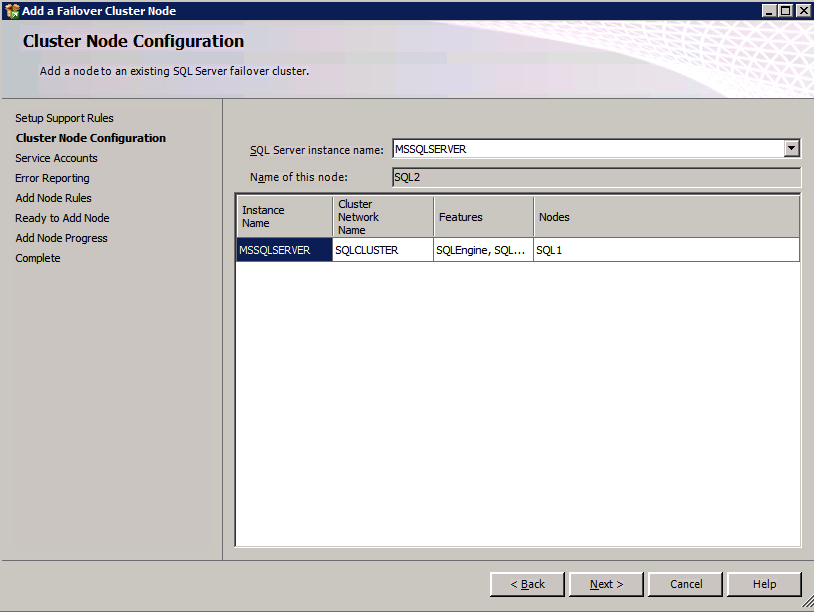
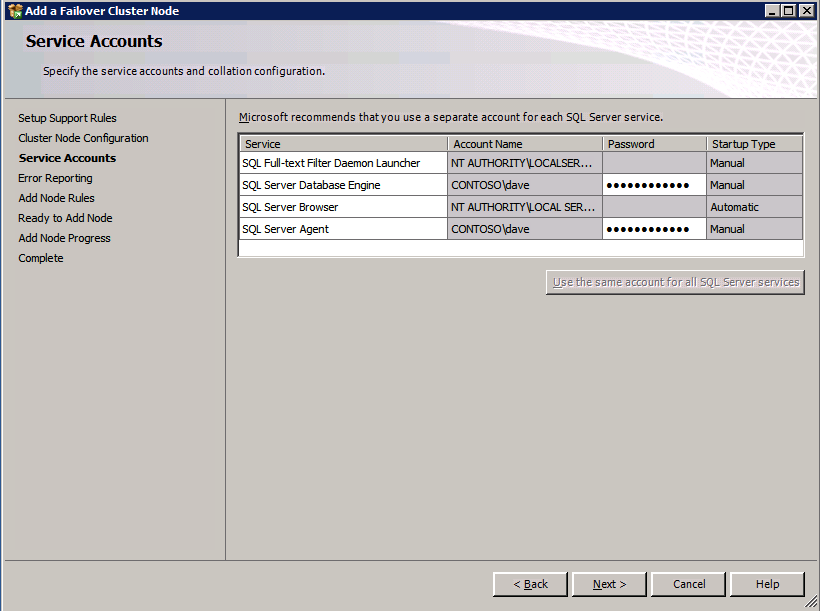
Installazione di SQL Server sul secondo nodo
di Seguito è un esempio di comando che è possibile eseguire per aggiungere un ulteriore SQL Server 2008 R2 nodo in un cluster esistente.
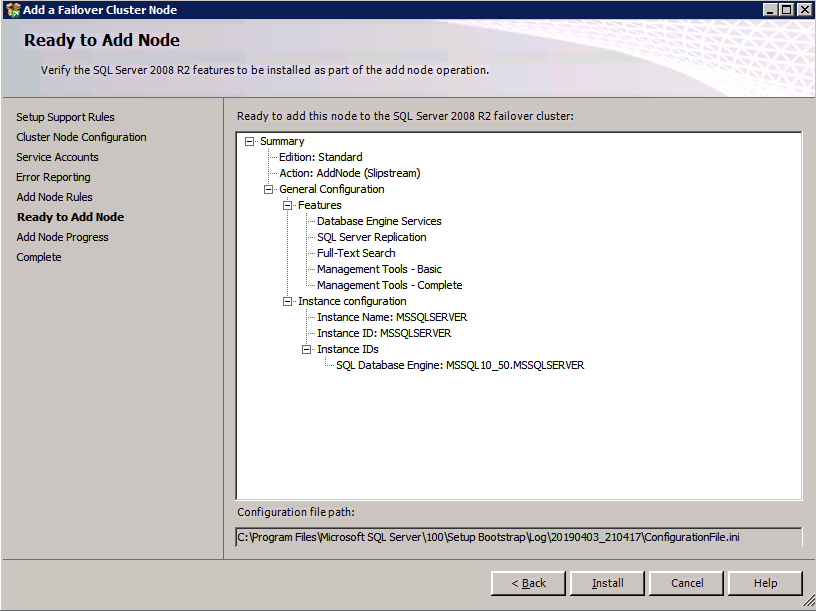
c:\SQLServerFull\setup.exe /q /ACTION=AddNode /INSTANCENAME="MSSQLSERVER" /SQLSVCACCOUNT="contoso\admin" /SQLSVCPASSWORD="xxxxxxxxx" /AGTSVCACCOUNT="contoso\admin" /AGTSVCPASSWORD="xxxxxxxx" /IAcceptSQLServerLicenseTermsSe si preferisce utilizzare la GUI, seguire con i seguenti screenshot.
Eseguire nuovamente l’impostazione di SQL Server sul secondo nodo e scegliere Aggiungi nodo a un cluster di failover di SQL Server.
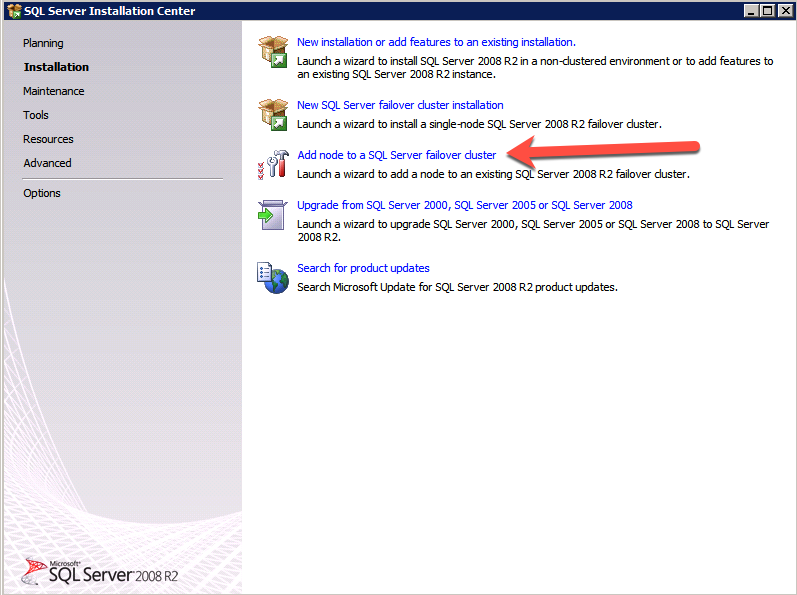
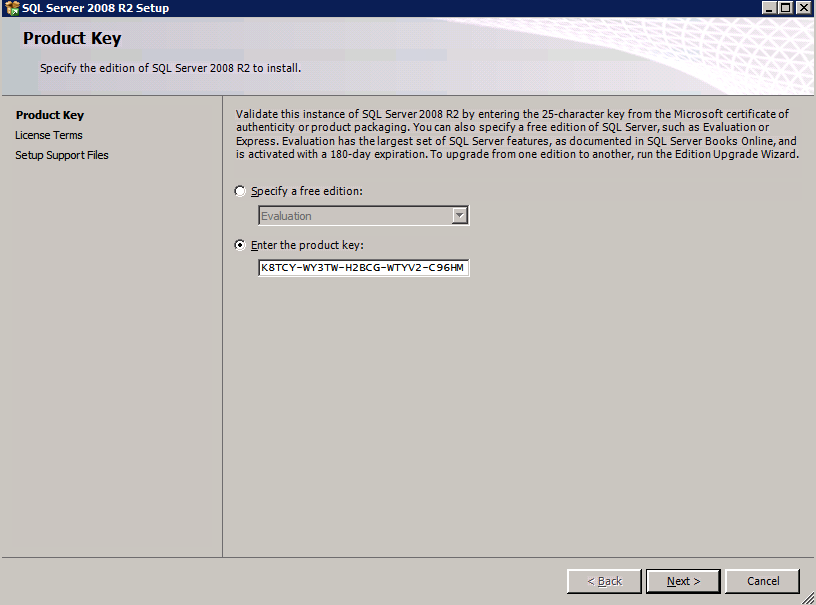
Congratulations, si è quasi fatto! Tuttavia, a causa della mancanza di supporto di Azure per ARP gratuito, sarà necessario configurare un sistema di bilanciamento del carico interno (ILB) per assistere con il reindirizzamento del client come mostrato nei passaggi seguenti.
Aggiornare l’indirizzo IP del cluster SQL
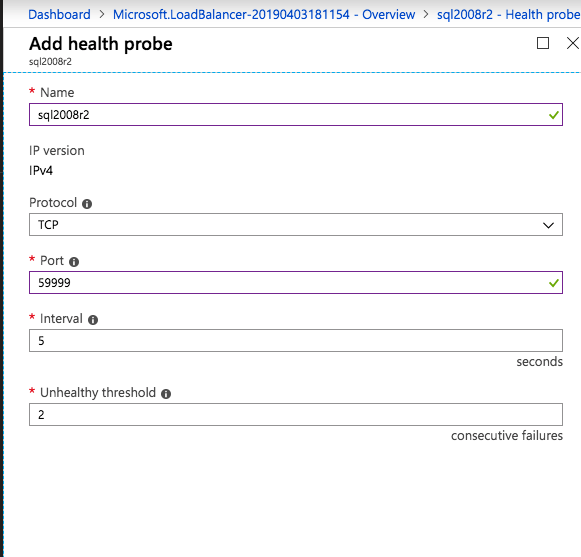
Affinché l’ILB funzioni correttamente, è necessario eseguire eseguire il seguente comando da uno dei nodi del cluster. It SQL Cluster IP consente all’indirizzo IP del cluster SQL di rispondere al probe di integrità ILB impostando anche la subnet mask su 255.255.255.255 per evitare conflitti di indirizzo IP con il probe di integrità.
cluster res <IPResourceName> /priv enabledhcp=0 address=<ILBIP> probeport=59999 subnetmask=255.255.255.255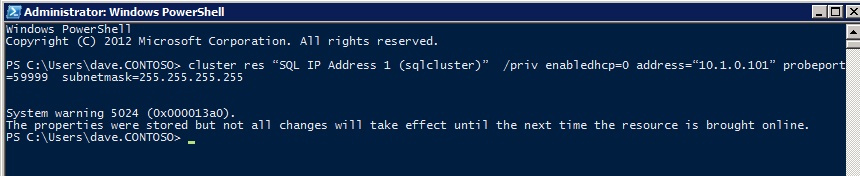
NOTA – Non lo so se si tratta di un colpo di fortuna, ma a volte ho eseguito questo comando e sembra che funzioni, ma non completa il lavoro e devo eseguirlo di nuovo. Il modo in cui posso dire se ha funzionato è guardando la Subnet Mask della risorsa IP di SQL Server, se non è 255.255.255.255, allora sai che non è stato eseguito correttamente. Può essere semplice un problema di aggiornamento della GUI, quindi puoi anche provare a riavviare la GUI del cluster per verificare che la subnet mask sia stata aggiornata.
Dopo aver eseguito correttamente, prendere la risorsa offline e riportarla online per le modifiche abbiano effetto.
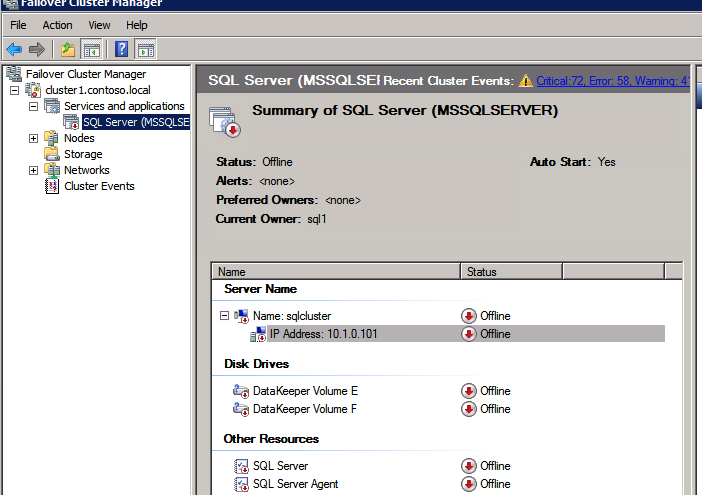
Creare il bilanciamento del carico
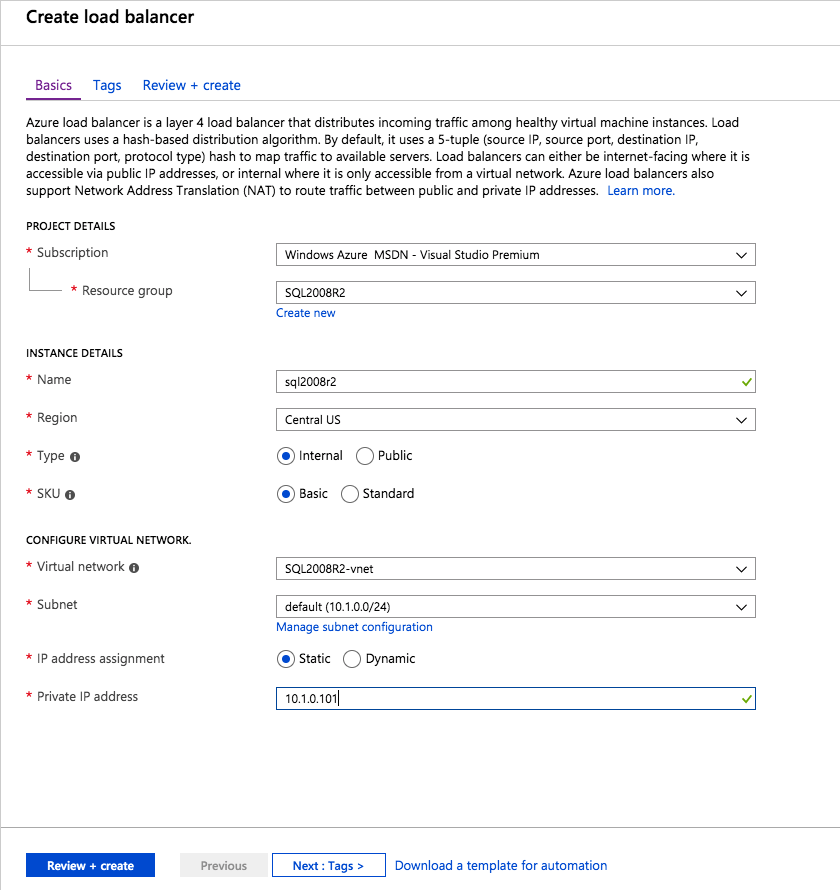
Il passaggio finale consiste nel creare il bilanciamento del carico. In questo caso supponiamo che tu stia eseguendo l’istanza predefinita di SQL Server, in ascolto sulla porta 1433.
L’indirizzo IP privato definito quando si crea il bilanciamento del carico sarà lo stesso indirizzo utilizzato da SQL Server FCI.
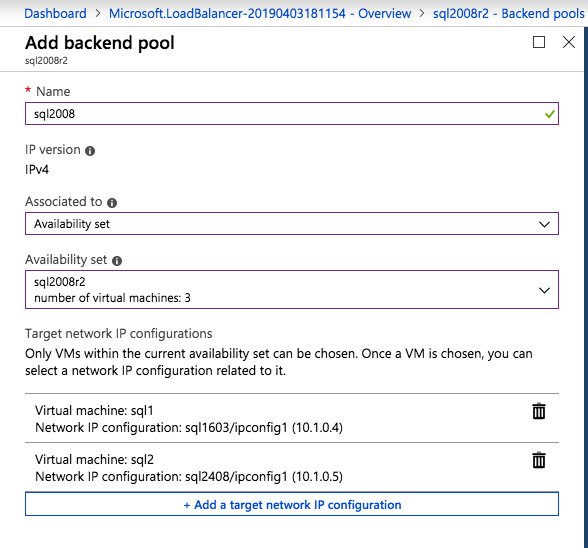
Aggiungi solo le due istanze di SQL Server al pool di backend. Non aggiungere il FSW al pool di backend.
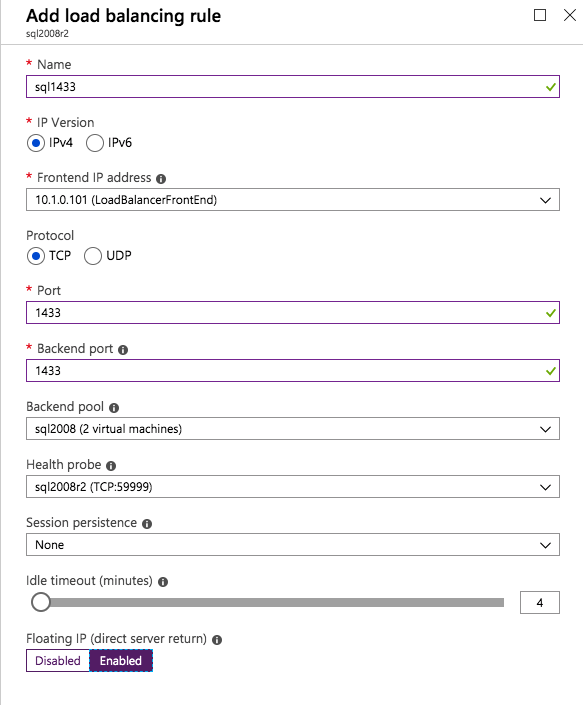
In questa regola di bilanciamento del carico è necessario abilitare l’IP mobile
Convalidare il cluster
Prima di continuare, eseguire nuovamente la convalida del cluster. Il rapporto di convalida del cluster dovrebbe restituire solo gli stessi avvisi di rete e archiviazione che ha fatto la prima volta che è stato eseguito. Supponendo che non ci siano nuovi errori o avvisi, il cluster è configurato correttamente.
Modifica sqlserv.file di configurazione exe
Nella directory C:\Program File(x86)\Microsoft SQL Server\100\Tools \ Binn abbiamo creato un sqlps.exe.file di configurazione e sqlservr.exe.config con le seguenti righe nel file di configurazione:
<configuration> <startup> <supportedRuntime version="v2.0.50727"/> </startup></configuration>Questi file, per impostazione predefinita, non esisteranno e possono essere creati. Se questo file esiste già per l’installazione ,la riga< supportedRuntime version=”v2.0.50727″/>deve semplicemente essere posizionata con la sottosezione<startup>
Testare il Cluster
Il test più semplice consiste nell’aprire SQL Server Management Studio sul nodo passivo e connettersi al cluster. Se sei in grado di connetterti, congratulazioni, hai fatto tutto correttamente! Se non riesci a connetterti non temere, non saresti la prima persona a commettere un errore. Ho scritto un articolo sul blog per aiutare a risolvere il problema. La gestione del cluster equivale esattamente alla gestione di un cluster di storage condiviso tradizionale. Tutto è controllato tramite Failover Cluster Manager.
Opzionale – Riposizionare Tempdb
Per prestazioni ottimali è consigliabile spostare tempdb sull’SSD locale, non replicato. Tuttavia, SQL Server 2008 R2 richiede che tempdb sia su un disco cluster. SIOS ha una soluzione chiamata risorsa volume non speculare che risolve questo problema. Sarebbe consigliabile creare una risorsa volume non speculare dell’unità SSD locale e spostare tempdb lì. Tuttavia, l’unità SSD locale non è persistente, quindi è necessario assicurarsi che la cartella contenente tempdb e le autorizzazioni su tale cartella vengano ricreate ogni volta che il server si riavvia.