Webes feltérképezés Pythonnal

a webes feltérképezés hatékony módszer az adatok gyűjtésére az internetről egy vagy több domain összes URL-jének megtalálásával. A Python számos népszerű webes feltérképező könyvtárral és keretrendszerrel rendelkezik.
ebben a cikkben először különböző feltérképezési stratégiákat és használati eseteket mutatunk be. Ezután egy egyszerű webbejárót építünk a semmiből a Pythonban két könyvtár segítségével: kérések és gyönyörű leves. Ezután meglátjuk, miért jobb olyan webes feltérképezési keretet használni, mint a Scrapy. Végül létrehozunk egy Scrapy-vel ellátott robotot, hogy összegyűjtsük a film metaadatait az IMDb-ről, és megnézzük, hogyan skálázódik a Scrapy a több millió oldalas webhelyekre.
mi az a webrobot?
a webes feltérképezés és a webkaparás két különböző, de kapcsolódó fogalom. A webes feltérképezés a webkaparás egyik eleme, a bejáró logika megtalálja a kaparókód által feldolgozandó URL-eket.
a webrobot a meglátogatandó URL-ek listájával kezdődik, amelyet magnak hívnak. A bejáró minden URL-hez megtalálja a hivatkozásokat a HTML-ben, szűri azokat bizonyos feltételek alapján, és hozzáadja az új hivatkozásokat egy sorhoz. Az összes HTML-t vagy valamilyen konkrét információt kinyerjük, hogy egy másik csővezeték feldolgozza.
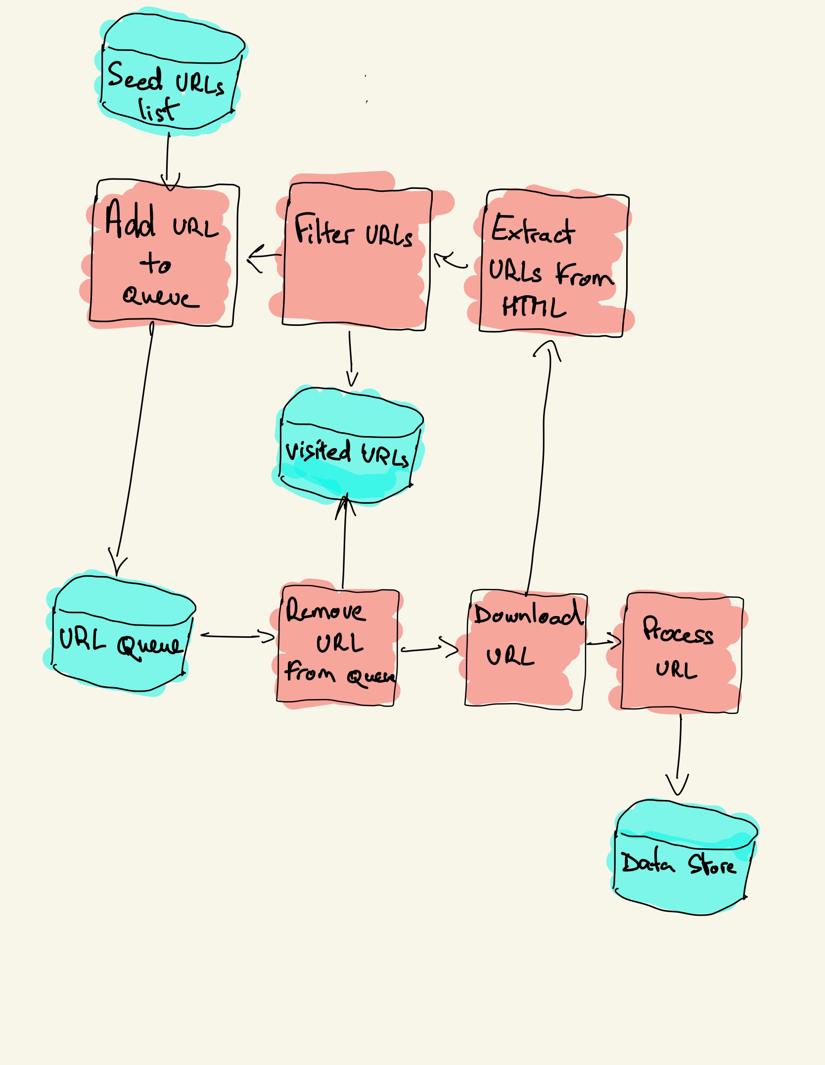
webes feltérképezési stratégiák
a gyakorlatban a webbejárók csak az oldalak egy részhalmazát látogatják meg a bejáró költségkeretétől függően, amely lehet tartományonként, mélységenként vagy végrehajtási időnként az oldalak maximális száma.
a legnépszerűbb webhelyek robotokat biztosítanak.txt fájl annak jelzésére, hogy a webhely mely területeit nem engedélyezi az egyes felhasználói ügynökök feltérképezése. A robots fájl ellentéte a webhelytérkép.xml fájl, amely felsorolja a feltérképezhető oldalakat.
a népszerű webrobot használati esetek a következők:
- a keresőmotorok (Googlebot, Bingbot, Yandex Bot…) összegyűjtik az összes HTML-t az Internet jelentős részére. Ezeket az adatokat indexelik, hogy kereshetővé váljanak.
- a HTML gyűjtésén túl a SEO elemző eszközök metaadatokat is gyűjtenek, például a válaszidőt, a válasz állapotát a törött oldalak észlelésére, valamint a különböző domainek közötti linkeket a backlinkek gyűjtésére.
- Árfigyelő eszközök feltérképezik az e-kereskedelmi webhelyeket, hogy megtalálják a termékoldalakat és kinyerjék a metaadatokat, nevezetesen az árat. A termékoldalakat ezután rendszeresen felülvizsgálják.
- a Common Crawl a webes feltérképezési adatok nyitott tárházát tartja fenn. Például a 2020 októberi archívum 2,71 milliárd weboldalt tartalmaz.
ezután három különböző stratégiát hasonlítunk össze egy webbejáró felépítéséhez Pythonban. Először csak szabványos könyvtárakat használ, majd harmadik féltől származó könyvtárakat HTTP kérések készítéséhez és HTML elemzéséhez, végül pedig egy webes feltérképezési keretrendszert.
egyszerű webrobot létrehozása Pythonban a semmiből
egyszerű webrobot felépítéséhez Pythonban legalább egy könyvtárra van szükségünk a HTML letöltéséhez egy URL-ből, és egy HTML elemző könyvtárra a linkek kibontásához. A Python szabványos urllib könyvtárakat biztosít HTTP kérések és html készítéséhez.elemző a HTML elemzéséhez. Egy példa Python lánctalpas épített csak szabványos könyvtárak megtalálható Github.
a szabványos Python könyvtárak a kérésekhez és a HTML elemzéshez nem túl fejlesztőbarátak. Más népszerű könyvtárak, például a requests, a http for humans és a Beautiful Soup jobb fejlesztői élményt nyújtanak.
ha többet szeretne megtudni, ellenőrizze ezt az útmutatót a legjobb Python HTTP kliensről.
a két könyvtárat helyben telepítheti.
pip install requests bs4egy alapvető bejáró építhető az előző architektúra diagram alapján.
import loggingfrom urllib.parse import urljoinimport requestsfrom bs4 import BeautifulSouplogging.basicConfig( format='%(asctime)s %(levelname)s:%(message)s', level=logging.INFO)class Crawler: def __init__(self, urls=): self.visited_urls = self.urls_to_visit = urls def download_url(self, url): return requests.get(url).text def get_linked_urls(self, url, html): soup = BeautifulSoup(html, 'html.parser') for link in soup.find_all('a'): path = link.get('href') if path and path.startswith('/'): path = urljoin(url, path) yield path def add_url_to_visit(self, url): if url not in self.visited_urls and url not in self.urls_to_visit: self.urls_to_visit.append(url) def crawl(self, url): html = self.download_url(url) for url in self.get_linked_urls(url, html): self.add_url_to_visit(url) def run(self): while self.urls_to_visit: url = self.urls_to_visit.pop(0) logging.info(f'Crawling: {url}') try: self.crawl(url) except Exception: logging.exception(f'Failed to crawl: {url}') finally: self.visited_urls.append(url)if __name__ == '__main__': Crawler(urls=).run()a fenti kód meghatároz egy bejáró osztályt segítő módszerekkel a download_url-hoz a kérések könyvtár segítségével, a Get_linked_urls-hoz a gyönyörű leves könyvtár segítségével, az add_url_to_visit pedig az URL-ek szűréséhez. A meglátogatandó URL-ek és a meglátogatott URL-ek két külön listában vannak tárolva. Futtathatja a bejárót a terminálon.
python crawler.pya bejáró minden meglátogatott URL-hez egy sort naplóz.
2020-12-04 18:10:10,737 INFO:Crawling: https://www.imdb.com/2020-12-04 18:10:11,599 INFO:Crawling: https://www.imdb.com/?ref_=nv_home2020-12-04 18:10:12,868 INFO:Crawling: https://www.imdb.com/calendar/?ref_=nv_mv_cal2020-12-04 18:10:13,526 INFO:Crawling: https://www.imdb.com/list/ls016522954/?ref_=nv_tvv_dvd2020-12-04 18:10:19,174 INFO:Crawling: https://www.imdb.com/chart/top/?ref_=nv_mv_2502020-12-04 18:10:20,624 INFO:Crawling: https://www.imdb.com/chart/moviemeter/?ref_=nv_mv_mpm2020-12-04 18:10:21,556 INFO:Crawling: https://www.imdb.com/feature/genre/?ref_=nv_ch_gra kód nagyon egyszerű, de számos teljesítmény-és használhatósági problémát kell megoldani, mielőtt sikeresen feltérképeznénk egy teljes weboldalt.
- a lánctalpas lassú és nem támogatja a párhuzamosságot. Amint az időbélyegekből látható, az egyes URL-ek feltérképezése körülbelül egy másodpercet vesz igénybe. Minden alkalommal, amikor a bejáró kérést tesz, megvárja a kérés megoldását, és közben nem történik munka.
- a letöltési URL logikának nincs újrapróbálkozási mechanizmusa, az URL-várólista nem valós sor, és nem túl hatékony nagy számú URL esetén.
- a linkkitermelési logika nem támogatja az URL-ek szabványosítását az URL-lekérdezési karakterlánc-paraméterek eltávolításával, nem kezeli a # betűvel kezdődő URL-eket, nem támogatja az URL-ek tartomány szerinti szűrését vagy a statikus fájlokra vonatkozó kérelmek kiszűrését.
- a lánctalpas nem azonosítja magát, és figyelmen kívül hagyja a robotokat.txt fájl.
ezután meglátjuk, hogy a Scrapy hogyan biztosítja ezeket a funkciókat, és megkönnyíti az egyéni feltérképezések kiterjesztését.
webes feltérképezés Scrapy-vel
a Scrapy a legnépszerűbb webes kaparó és feltérképező Python keretrendszer 40k csillaggal a Githubon. A Scrapy egyik előnye, hogy a kéréseket aszinkron módon ütemezik és kezelik. Ez azt jelenti, hogy a Scrapy újabb kérést küldhet az előző befejezése előtt, vagy más munkát végezhet a kettő között. A Scrapy sok egyidejű kérést képes kezelni, de konfigurálható úgy is, hogy az egyéni beállításokkal tiszteletben tartsa a webhelyeket, amint később látni fogjuk.
Scrapy többkomponensű architektúrával rendelkezik. Általában legalább két különböző osztályt hajt végre: Spider és Pipeline. A webkaparást úgy lehet elképzelni, mint egy ETL-t, ahol az adatokat kinyeri az internetről, és betölti a saját tárhelyére. A pókok kinyerik az adatokat, a csővezetékek pedig betöltik a tárolóba. Az átalakítás történhet mind a pókokban, mind a csővezetékekben, de azt javaslom, hogy állítson be egy egyedi Scrapy csővezetéket az egyes elemek egymástól független átalakításához. Ily módon az elem feldolgozásának elmulasztása nincs hatással más elemekre.
mindezek mellett hozzáadhatod a Spider és downloader köztes szoftvereket az összetevők között, amint az az alábbi ábrán látható.
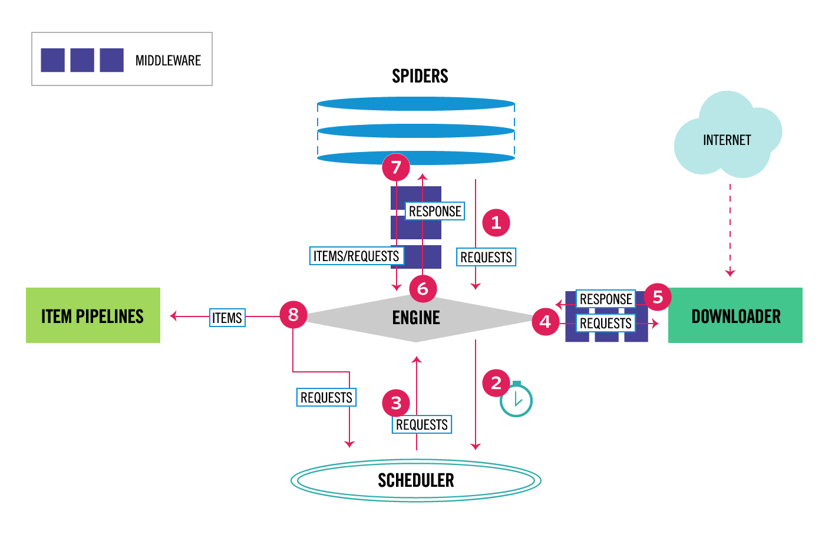
Scrapy Architecture Overview
ha korábban már használta a Scrapy-t, akkor tudja, hogy a web scraper olyan osztályként van definiálva, amely az alap Spider osztálytól örököl, és egy elemzési módszert valósít meg az egyes válaszok kezelésére. Ha még nem ismeri a Scrapy-t, olvassa el ezt a cikket a Scrapy segítségével történő egyszerű kaparáshoz.
from scrapy.spiders import Spiderclass ImdbSpider(Spider): name = 'imdb' allowed_domains = start_urls = def parse(self, response): passa Scrapy számos általános spider osztályt is kínál: CrawlSpider, XMLFeedSpider, CSVFeedSpider és SitemapSpider. A CrawlSpider osztály a base Spider osztálytól örököl, és egy extra szabály attribútumot biztosít a webhely feltérképezésének meghatározásához. Minden szabály egy LinkExtractor segítségével határozza meg, hogy mely linkek kerülnek kibontásra az egyes oldalakról. Ezután látni fogjuk, hogyan kell használni mindegyiket az IMDb-hez, az Internet Movie Database-hez.
példa létrehozása Scrapy bejáró az IMDb-hez
mielőtt megpróbáltam feltérképezni az IMDb-t, ellenőriztem az IMDb robotokat.TXT fájl, hogy mely URL-útvonalak engedélyezettek. A robots fájl csak 26 elérési utat engedélyez az összes felhasználói ügynök számára. Scrapy olvassa a robotokat.TXT fájl előre, és tiszteletben tartja, ha a ROBOTSTXT_OBEY beállítás értéke true. Ez a helyzet a Scrapy startproject paranccsal generált összes projekt esetében.
scrapy startproject scrapy_crawlerez a parancs új projektet hoz létre az alapértelmezett Scrapy projekt mappastruktúrával.
scrapy_crawler/├── scrapy.cfg└── scrapy_crawler ├── __init__.py ├── items.py ├── middlewares.py ├── pipelines.py ├── settings.py └── spiders ├── __init__.pyezután létrehozhat egy pókot scrapy_crawler/spiders/imdb.py az összes link kivonására vonatkozó szabály.
from scrapy.spiders import CrawlSpider, Rulefrom scrapy.linkextractors import LinkExtractorclass ImdbCrawler(CrawlSpider): name = 'imdb' allowed_domains = start_urls = rules = (Rule(LinkExtractor()),)elindíthatja a bejárót a terminálon.
scrapy crawl imdb --logfile imdb.logsok naplót fog kapni, beleértve egy naplót minden kéréshez. A naplók feltárása során észrevettem, hogy még akkor is, ha az allowed_domains-t csak a weboldalak feltérképezésére állítjuk be https://www.imdb.com alatt, külső tartományokra vonatkozó kérések voltak, például amazon.com.
2020-12-06 12:25:18 DEBUG: Redirecting (302) to <GET https://www.amazon.com/b/?&node=5160028011&ref_=ft_iba> from <GET (https://www.imdb.com/whitelist-offsite?url=https%3A%2F%2Fwww.amazon.com%2Fb%2F%3F%26node%3D5160028011%26ref_%3Dft_iba&page-action=ft-iba&ref=ft_iba)>az IMDb átirányítja az URL-ek útvonalait a whitelist-offsite és whitelist alatt a külső tartományokra. Van egy nyitott Scrapy Github probléma, amely azt mutatja, hogy a külső URL-ek nem szűrődnek ki, amikor az OffsiteMiddleware-t a RedirectMiddleware előtt alkalmazzák. A probléma megoldásához konfigurálhatjuk a linkkivonatot úgy, hogy megtagadja az URL-eket két reguláris kifejezéssel kezdve.
class ImdbCrawler(CrawlSpider): name = 'imdb' allowed_domains = start_urls = rules = ( Rule(LinkExtractor( deny=, )), )a Rule és a LinkExtractor osztályok számos argumentumot támogatnak az URL-ek kiszűrésére. Például figyelmen kívül hagyhatja az adott URL-kiterjesztéseket, és lekérdezési karakterláncok rendezésével csökkentheti az ismétlődő URL-ek számát. Ha nem talál konkrét argumentumot a használati esethez, átadhat egy egyéni függvényt a process_links-nek a LinkExtractor-ban vagy a process_values-nek a szabályban.
például az IMDb-nek két különböző URL-je van ugyanazzal a tartalommal.
https://www.imdb.com/név/nm1156914/
https://www.imdb.com/név / nm1156914/?mode = desktop& ref_=m_ft_dsk
a feltérképezett URL-ek számának korlátozásához az url_query_cleaner funkcióval az összes lekérdezési karakterláncot eltávolíthatjuk az URL-ekből a w3lib könyvtárból, és felhasználhatjuk a process_links programban.
from w3lib.url import url_query_cleanerdef process_links(links): for link in links: link.url = url_query_cleaner(link.url) yield linkclass ImdbCrawler(CrawlSpider): name = 'imdb' allowed_domains = start_urls = rules = ( Rule(LinkExtractor( deny=, ), process_links=process_links), )most, hogy korlátoztuk a feldolgozandó kérések számát, hozzáadhatunk egy parse_item metódust az egyes oldalak adatainak kinyeréséhez, és továbbíthatjuk azokat egy folyamatba, hogy tárolják. Például kivonhatjuk a teljes választ.szöveg feldolgozásához egy másik folyamat, vagy válassza ki a HTML metaadatokat. A HTML metaadatok kiválasztásához a fejléccímkében kódolhatjuk a saját XPath-jainkat, de jobb, ha egy könyvtárat használunk, extruct, amely kivonja az összes metaadatot egy HTML oldalról. Lehet telepíteni a pip install kivonat.
import refrom scrapy.linkextractors import LinkExtractorfrom scrapy.spiders import CrawlSpider, Rulefrom w3lib.url import url_query_cleanerimport extructdef process_links(links): for link in links: link.url = url_query_cleaner(link.url) yield linkclass ImdbCrawler(CrawlSpider): name = 'imdb' allowed_domains = start_urls = rules = ( Rule( LinkExtractor( deny=, ), process_links=process_links, callback='parse_item', follow=True ), ) def parse_item(self, response): return { 'url': response.url, 'metadata': extruct.extract( response.text, response.url, syntaxes= ), }a follow attribútumot True értékre állítottam, hogy a Scrapy továbbra is kövesse az egyes válaszok összes linkjét, még akkor is, ha egyéni elemzési módszert adtunk meg. Az extruct-ot úgy is konfiguráltam, hogy csak az Open Graph metaadatokat és a JSON-LD-t, az IMDB által használt népszerű módszert használja a kapcsolt adatok kódolására a JSON segítségével a weben. Futtathatja a bejárót, és az elemeket JSON vonalak formátumban tárolhatja egy fájlban.
scrapy crawl imdb --logfile imdb.log -o imdb.jl -t jsonlinesa kimeneti fájl imdb.a jl minden feltérképezett elemhez egy sort tartalmaz. Például a HTML <meta> címkéiből vett film kibontott Open Graph metaadatai így néznek ki.
{ "url": "http://www.imdb.com/title/tt2442560/", "metadata": {"opengraph": , , , , , ] }]}}a JSON-LD egyetlen elem túl hosszú ahhoz, hogy tartalmazza a cikket, itt van egy minta, amit Scrapy kivonatok a <script type=”application/ld+json”> tag.
"json-ld": , "contentRating": "TV-MA", "actor": ... }]a naplók feltárása, észrevettem egy másik gyakori problémát a robotokkal. A szűrőkre való egymás utáni kattintással a bejáró azonos tartalmú URL-eket generál, csak azt, hogy a szűrőket más sorrendben alkalmazták.
https://www.imdb.com/név / nm2900465 / videó galéria / tartalom_type-trailer / kapcsolódó termékek_címek-tt0479468
https://www.imdb.com/name/nm2900465/videogallery/related_titles-tt0479468 / content_type-trailer
a hosszú szűrő és keresési URL-ek egy nehéz probléma, amelyet részben meg lehet oldani az URL-ek hosszának korlátozásával egy Scrapy beállítással, URLLENGTH_LIMIT.
az IMDb-t használtam példaként, hogy bemutassam a webbejáró felépítésének alapjait Pythonban. Nem hagytam, hogy a bejáró hosszú ideig működjön, mivel nem volt konkrét felhasználási esetem az adatokhoz. Abban az esetben, ha konkrét adatokra van szüksége az IMDb-től, ellenőrizheti az IMDb Datasets projektet, amely napi exportálást biztosít az IMDb-adatok és az IMDbPY, egy Python csomag az adatok lekéréséhez és kezeléséhez.
web crawling at scale
ha egy olyan nagy webhelyet próbál meg feltérképezni, mint az IMDb, amely több mint 45 millió oldalt tartalmaz a Google alapján, fontos, hogy felelősségteljesen feltérképezzen az alábbi beállítások konfigurálásával. A robot azonosítható, és a bot_név beállításban megadhatja a kapcsolattartási adatokat. A weboldal szervereire nehezedő nyomás korlátozásához növelheti a DOWNLOAD_DELAY értéket, korlátozhatja a CONCURRENT_REQUESTS_PER_DOMAIN értéket, vagy beállíthatja az AUTOTHROTTLE_ENABLED beállítást, amely dinamikusan adaptálja ezeket a beállításokat a szerver válaszideje alapján.
vegye figyelembe, hogy a Scrapy feltérképezések alapértelmezés szerint egyetlen tartományra vannak optimalizálva. Ha több tartományt is feltérképez, ellenőrizze ezeket a beállításokat, hogy optimalizálja a széles körű feltérképezéseket, beleértve az alapértelmezett feltérképezési sorrend megváltoztatását a mélységről a lélegzetre. A feltérképezési költségkeret korlátozásához korlátozhatja a kérelmek számát A closespider_pagecount beállítással a close spider kiterjesztés.
az alapértelmezett beállításokkal a Scrapy percenként körülbelül 600 oldalt térképez fel egy olyan webhelyen, mint az IMDb. A 45 millió oldal feltérképezése több mint 50 napot vesz igénybe egyetlen robot számára. Ha több webhelyet kell feltérképeznie, akkor jobb, ha külön bejárókat indít minden nagy webhelyhez vagy webhelycsoporthoz. Ha érdekli az elosztott webbejárók, elolvashatja, hogy egy fejlesztő hogyan mászott fel 250 millió oldalt Pythonnal 40 óra alatt 20 Amazon EC2 gépi példány használatával.
egyes esetekben előfordulhat, hogy befut weboldalak, amelyek megkövetelik, hogy végre JavaScript kódot renderelni az összes HTML. Ezt elmulasztja, és előfordulhat, hogy nem gyűjti össze az összes linket a weboldalon. Mivel manapság nagyon gyakori, hogy a webhelyek dinamikusan jelenítik meg a tartalmat a böngészőben, írtam egy Scrapy köztes szoftvert a Javascript oldalak megjelenítéséhez a ScrapingBee API-jával.
következtetés
összehasonlítottuk egy Python bejáró kódját, amely harmadik féltől származó könyvtárakat használ URL-ek letöltésére és HTML elemzésére egy népszerű webes feltérképezési keretrendszer segítségével épített bejáróval. A Scrapy egy nagyon hatékony webes feltérképezési keretrendszer, amelyet könnyű kiterjeszteni az egyéni kóddal. De tudnia kell minden olyan helyet, ahol a saját kódját és az egyes összetevők beállításait összekapcsolhatja.
a Scrapy megfelelő Konfigurálása még fontosabbá válik, ha több millió oldalt tartalmazó webhelyeket feltérképez. Ha többet szeretne megtudni a webes feltérképezésről, azt javaslom, hogy válasszon egy népszerű webhelyet, és próbálja meg feltérképezni. Biztosan új kérdésekbe fog ütközni, ami lenyűgözővé teszi a témát!