Tutoriel Log4j: Comment configurer l’enregistreur pour une journalisation efficace des applications Java
Obtenir une visibilité sur votre application est crucial lors de l’exécution de votre code en production. Qu’entendons-nous par visibilité ? Principalement des éléments tels que les performances des applications via les métriques, l’état et la disponibilité des applications, ses journaux si vous devez les dépanner ou ses traces si vous devez comprendre ce qui les rend lents et comment les rendre plus rapides. Les métriques
vous donnent des informations sur les performances de chacun des éléments de votre infrastructure. Les traces vous montreront une vue plus large de l’exécution et du flux de code ainsi que des métriques d’exécution de code. Enfin, des journaux bien conçus fourniront un aperçu inestimable de l’exécution de la logique de code et de ce qui se passait dans votre code. Chacune des pièces mentionnées est cruciale pour votre application et même pour l’observabilité globale du système. Aujourd’hui, nous ne nous concentrerons que sur une seule pièce – les bûches. Pour être plus précis – sur les journaux d’applications Java. Si vous êtes intéressé par les métriques, consultez notre article sur les métriques clés de la JVM à surveiller.
Cependant, avant d’y entrer, abordons un problème qui a eu un impact sur la communauté en utilisant ce cadre. Le 9 décembre 2021, une vulnérabilité critique baptisée Log4Shell a été signalée. Identifié comme CVE-2021-44228, il permet à un attaquant de prendre le contrôle complet d’une machine exécutant Apache Log4j 2 version 2.14.1 ou inférieure, ce qui lui permet d’exécuter du code arbitraire sur le serveur vulnérable. Dans notre récent article de blog sur la vulnérabilité Log4jShell, nous avons détaillé comment déterminer si vous êtes affecté, comment résoudre le problème et ce que nous avons fait, chez Sematext, pour protéger notre système et nos utilisateurs.
Log4j 1.x Fin de vie
N’oubliez pas que le 5 août 2015, le Comité de gestion du projet Logging Services a annoncé que le Log4j 1.x avait atteint sa fin de vie. Tous les utilisateurs sont invités à migrer vers Log4j 2.x. Dans cet article de blog, nous vous aiderons à comprendre votre configuration actuelle de Log4j, en particulier le log4j 2.version x – et après cela, je vous aiderai à migrer vers la dernière et la plus grande version de Log4j.
« J’utilise Log4j 1.x, que dois-je faire? ». Ne paniquez pas, il n’y a rien de mal à cela. Faites un plan de transition vers Log4j 2.x. Je vais vous montrer comment continuer à lire :). Votre candidature vous en remerciera. Vous obtiendrez les correctifs de sécurité, les améliorations des performances et bien plus de fonctionnalités après la migration.
« Je commence un nouveau projet, que dois-je faire ? ». Utilisez simplement le Log4j 2.x tout de suite, ne pensez même pas à Log4j 1.x. Si vous avez besoin d’aide pour cela, consultez ce tutoriel de journalisation Java où j’explique tout ce dont vous avez besoin.
Se connecter à Java
Il n’y a pas de magie derrière se connecter à Java. Tout se résume à utiliser une classe Java appropriée et ses méthodes pour générer des événements de journal. Comme nous l’avons discuté dans le guide de journalisation Java, il existe plusieurs façons de démarrer
Bien sûr, la plus naïve et pas la meilleure voie à suivre consiste simplement à utiliser le système.dehors et système.cours d’erreur. Oui, vous pouvez le faire et vos messages iront simplement à la sortie standard et à l’erreur standard. Habituellement, cela signifie qu’il sera imprimé sur la console ou écrit dans un fichier quelconque ou même envoyé à /dev/null et sera oublié à jamais. Un exemple d’un tel code pourrait ressembler à ceci:
public class SystemExample { public static void main(String args) { System.out.println("Starting my awesome application"); // some work to be done System.out.println( String.format("My application %s started successfully", SystemExample.class) ); }}
La sortie de l’exécution de code ci-dessus serait la suivante:
Starting my awesome applicationMy application class com.sematext.logging.log4jsystem.SystemExample started successfully
Ce n’est pas parfait, non? Je n’ai aucune information sur la classe qui a généré le message et beaucoup, beaucoup d’autres « petites » choses cruciales et importantes lors du débogage.
Il manque d’autres choses qui ne sont pas vraiment connectées au débogage. Pensez à l’environnement d’exécution, aux applications multiples ou aux microservices et à la nécessité d’unifier la journalisation pour simplifier la configuration du pipeline de centralisation des journaux. Utilisation du système.out, ou / et Système.une erreur dans notre code à des fins de journalisation nous obligerait à refaire tous les endroits où nous l’utilisons chaque fois que nous devons ajuster le format de journalisation. Je sais que c’est extrême, mais croyez-moi, nous avons vu l’utilisation du système.en code de production dans les modèles de déploiement d’applications » traditionnels » ! Bien sûr, se connecter au système.out est une solution appropriée pour les applications conteneurisées et vous devez utiliser la sortie qui correspond à votre environnement. Souvenez-vous de ça!
Pour toutes les raisons mentionnées et bien d’autres auxquelles nous ne pensons même pas, vous devriez regarder l’une des bibliothèques de journalisation possibles, comme Log4 j, Log4j 2, Logback, ou même java.util.journalisation qui fait partie du kit de développement Java. Pour cet article de blog, nous utiliserons Log4j.
La couche d’abstraction – SLF4J
Le sujet du choix de la bonne solution de journalisation pour votre application Java est quelque chose que nous avons déjà discuté dans notre tutoriel sur la journalisation en Java. Nous vous recommandons fortement de lire au moins la section mentionnée.
Nous utiliserons SLF4J, une couche d’abstraction entre notre code Java et Log4j – la bibliothèque de journalisation de notre choix. La façade de journalisation simple fournit des liaisons pour les frameworks de journalisation courants tels que Log4j, Logback et java.util.journalisation. Imaginez le processus d’écriture d’un message de journal de la manière simplifiée suivante:
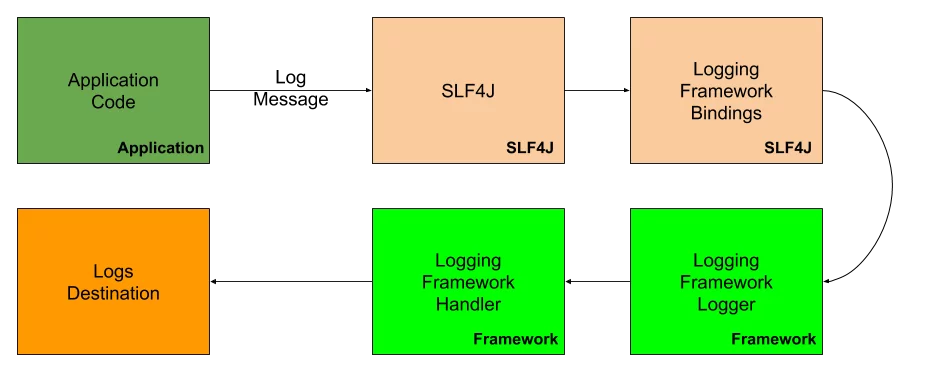
Vous pouvez vous demander pourquoi utiliser une couche d’abstraction? Eh bien, la réponse est assez simple – éventuellement, vous voudrez peut-être changer le cadre de journalisation, le mettre à niveau, l’unifier avec le reste de votre pile technologique. Lorsque vous utilisez une couche d’abstraction, une telle opération est assez simple – il vous suffit d’échanger les dépendances du framework de journalisation et de fournir un nouveau package. Si nous ne devions pas utiliser une couche d’abstraction, nous devrions changer le code, potentiellement beaucoup de code. Chaque classe qui enregistre quelque chose. Pas une très belle expérience de développement.
L’enregistreur
Le code de votre application Java interagira avec un ensemble standard d’éléments clés permettant la création et la manipulation d’événements de journal. Nous avons couvert les éléments cruciaux dans notre tutoriel de journalisation Java, mais permettez–moi de vous rappeler l’une des classes que nous utiliserons constamment – l’enregistreur.
L’enregistreur est l’entité principale qu’une application utilise pour effectuer des appels de journalisation – créer des événements de journal. L’objet Logger est généralement utilisé pour une seule classe ou un seul composant pour fournir un contexte lié à un cas d’utilisation spécifique. Il fournit des méthodes pour créer des événements de journal avec un niveau de journal approprié et les transmettre pour un traitement ultérieur. Vous créerez généralement un objet statique avec lequel vous interagirez, par exemple comme ceci:
... Logger LOGGER = LoggerFactory.getLogger(MyAwesomeClass.class);
Et c’est tout. Maintenant que nous savons à quoi nous pouvons nous attendre, regardons la bibliothèque Log4j.
Log4j
Le moyen le plus simple de démarrer avec Log4j est d’inclure la bibliothèque dans le chemin de classe de votre application Java. Pour ce faire, nous incluons la plus récente bibliothèque log4j disponible, ce qui signifie la version 1.2.17 dans notre fichier de construction.
Nous utilisons Gradle et dans notre application simple et la section dépendances pour le fichier de construction Gradle se présente comme suit:
dependencies { implementation 'log4j:log4j:1.2.17'}
Nous pouvons commencer à développer le code et inclure la journalisation à l’aide de Log4j:
package com.sematext.blog;import org.apache.log4j.Logger;public class ExampleLog4j { private static final Logger LOGGER = Logger.getLogger(ExampleLog4j.class); public static void main(String args) { LOGGER.info("Initializing ExampleLog4j application"); }}
Comme vous pouvez le voir dans le code ci-dessus, nous avons initialisé l’objet Logger en utilisant la méthode getLogger statique et nous avons fourni le nom de la classe. Après cela, nous pouvons facilement accéder à l’objet Logger statique et l’utiliser pour produire des événements de journal. Nous pouvons le faire dans la méthode principale.
Note latérale – la méthode getLogger peut également être appelée avec une chaîne comme argument, par exemple:
private static final Logger LOGGER = Logger.getLogger("com.sematext.blog");
Cela signifierait que nous voulons créer un enregistreur et associer le nom de com.sematext.blog avec elle. Si nous utilisons le même nom ailleurs dans le code, Log4j renverra la même instance d’enregistreur. Cela est utile si nous souhaitons combiner la journalisation de plusieurs classes différentes en un seul endroit. Par exemple, les journaux liés au paiement dans un seul fichier journal dédié.
Log4j fournit une liste de méthodes permettant la création de nouveaux événements de journal à l’aide d’un niveau de journal approprié. Ce sont:
- trace de vide public (Message d’objet)
- débogage de vide public (message d’objet)
- informations de vide public (message d’objet)
- avertissement de vide public (message d’objet)
- erreur de vide public (message d’objet)
- fatal de vide public (message d’objet)
Et une méthode générique:
- journal des vides publics (Niveau de niveau, message d’objet)
Nous avons parlé des niveaux de journalisation Java dans notre article de blog sur le tutoriel de journalisation Java. Si vous ne les connaissez pas, veuillez prendre quelques minutes pour vous y habituer car les niveaux de journalisation sont cruciaux pour la journalisation. Si vous ne faites que commencer avec les niveaux de journalisation, nous vous recommandons également de consulter notre guide des niveaux de journalisation. Nous expliquons tout, de ce qu’ils sont à la façon de choisir le bon et comment les utiliser pour obtenir des informations significatives.
Si nous devions exécuter le code ci-dessus, la sortie que nous obtiendrions sur la console standard serait la suivante:
log4j:WARN No appenders could be found for logger (com.sematext.blog.ExampleLog4j).log4j:WARN Please initialize the log4j system properly.log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
Nous n’avons pas vu le message de journal auquel nous nous attendions. Log4j nous a informés qu’il n’y a pas de configuration présente. Oooops, parlons de la façon de configurer Log4j
Configuration Log4j
Il existe plusieurs façons de configurer notre journalisation Log4j. Nous pouvons le faire par programmation – par exemple en incluant un bloc d’initialisation statique:
static { BasicConfigurator.configure();}
Le code ci-dessus configure Log4j pour afficher les journaux sur la console au format par défaut. La sortie de l’exécution de notre exemple d’application se présenterait comme suit:
0 INFO com.sematext.blog.ExampleLog4jProgrammaticConfig - Initializing ExampleLog4j application
Cependant, la configuration de Log4j par programme n’est pas très courante. Le moyen le plus courant serait d’utiliser un fichier de propriétés ou un fichier XML. Nous pouvons modifier notre code et inclure le fichier log4j.properties avec le contenu suivant:
log4j.rootLogger=DEBUG, MAINlog4j.appender.MAIN=org.apache.log4j.ConsoleAppenderlog4j.appender.MAIN.layout=org.apache.log4j.PatternLayoutlog4j.appender.MAIN.layout.ConversionPattern=%r %-5p %c %x - %m%n
De cette façon, nous avons dit à Log4j que nous créons l’enregistreur racine, qui sera utilisé par défaut. Son niveau de journalisation par défaut est défini sur DEBUG, ce qui signifie que les événements de journal avec sévérité DEBUG ou supérieure seront inclus. Donc DÉBOGUER, INFO, AVERTIR, ERREUR et FATAL. Nous avons également donné à notre enregistreur un nom – MAIN. Ensuite, nous configurons l’enregistreur, en définissant sa sortie sur console et en utilisant la disposition du motif. Nous en parlerons plus tard dans le billet de blog. La sortie de l’exécution du code ci-dessus serait la suivante:
0 INFO com.sematext.blog.ExampleLog4jProperties - Initializing ExampleLog4j application
Si nous le souhaitons, nous pouvons également modifier le fichier log4j.properties et en utiliser un appelé log4j.xml . La même configuration utilisant le format XML se présenterait comme suit:
<!DOCTYPE log4j:configuration SYSTEM "log4j.dtd"><log4j:configuration> <appender name="MAIN" class="org.apache.log4j.ConsoleAppender"> <param name="Target" value="System.out"/> <layout class="org.apache.log4j.PatternLayout"> <param name="ConversionPattern" value="%r %-5p %c %x - %m%n" /> </layout> </appender> <root> <priority value ="debug"></priority> <appender-ref ref="MAIN" /> </root></log4j:configuration>
Si nous changions maintenant les log4j.properties pour log4j.xml un et le garder dans le chemin de classe l’exécution de notre exemple d’application serait la suivante:
0 INFO com.sematext.blog.ExampleLog4jXML - Initializing ExampleLog4j application
Alors, comment Log4j sait-il quel fichier utiliser? Examinons ça.
Processus d’initialisation
Il est crucial de savoir que Log4j ne fait aucune hypothèse concernant l’environnement dans lequel il s’exécute. Log4j ne suppose aucun type de destinations d’événements de journal par défaut. Lorsqu’il démarre, il recherche la propriété log4j.configuration et essaie de charger le fichier spécifié comme configuration. Si l’emplacement du fichier ne peut pas être converti en URL ou si le fichier n’est pas présent, il essaie de charger le fichier à partir du chemin de classe.
Cela signifie que nous pouvons écraser la configuration Log4j à partir du chemin de classe en fournissant le fichier -Dlog4j.configuration au démarrage et en le pointant vers le bon emplacement. Par exemple, si nous incluons un fichier appelé autre.xml avec le contenu suivant:
<!DOCTYPE log4j:configuration SYSTEM "log4j.dtd"><log4j:configuration> <appender name="MAIN" class="org.apache.log4j.ConsoleAppender"> <param name="Target" value="System.out"/> <layout class="org.apache.log4j.PatternLayout"> <param name="ConversionPattern" value="%r %-5p %c %x - %m%n" /> </layout> </appender> <root> <priority value ="debug"></priority> <appender-ref ref="MAIN" /> </root></log4j:configuration>
Et puis exécutez le code avec -Dlog4j.configuration=/opt/sematext/other.xml la sortie de notre code sera la suivante:
0 INFO com.sematext.blog.ExampleLog4jXML - Initializing ExampleLog4j application
Log4j Appenders
Nous avons déjà utilisé des appenders dans nos exemples well eh bien, vraiment un seul – le ConsoleAppender. Son seul but est d’écrire les événements du journal sur la console. Bien sûr, avec un grand nombre d’événements de journal et de systèmes s’exécutant dans différents environnements, écrire des données de texte pur sur la sortie standard n’est peut-être pas la meilleure idée, sauf si vous utilisez des conteneurs. C’est pourquoi Log4j prend en charge plusieurs types d’Appenders. Voici quelques exemples courants d’appenders Log4j:
- ConsoleAppender – l’appender qui ajoute les événements de journal au système.out ou système.erreur avec le système par défaut.hors. Lorsque vous utilisez cet appender, vous verrez vos journaux dans la console de votre application.
- FileAppender – l’appender qui ajoute les événements de journal à un fichier défini les stockant sur le système de fichiers.
- RollingFileAppender – l’appender qui étend le FileAppender et fait pivoter le fichier lorsqu’il atteint une taille définie. L’utilisation de RollingFileAppender empêche les fichiers journaux de devenir très volumineux et difficiles à maintenir.
- SyslogAppender – l’appender qui envoie les événements du journal à un démon Syslog distant.
- JDBCAppender – l’appender qui stocke les événements de journal dans la base de données. Gardez à l’esprit que cet appender ne stockera pas les erreurs et que ce n’est généralement pas la meilleure idée de stocker les événements de journal dans une base de données.
- SocketAppender – l’appender qui envoie les événements de journal sérialisés à un socket distant. Gardez à l’esprit que cet appender n’utilise pas de mises en page car il envoie les événements de journal bruts sérialisés.
- NullAppender – l’appender qui supprime simplement les événements du journal.
De plus, vous pouvez configurer plusieurs Appenders pour une seule application. Par exemple, vous pouvez envoyer des journaux à la console et à un fichier. Le log4j suivant.le contenu du fichier de propriétés ferait exactement cela:
log4j.rootLogger=DEBUG, MAIN, ROLLINGlog4j.appender.MAIN=org.apache.log4j.ConsoleAppenderlog4j.appender.MAIN.layout=org.apache.log4j.PatternLayoutlog4j.appender.MAIN.layout.ConversionPattern=%r %-5p %c %x - %m%nlog4j.appender.ROLLING=org.apache.log4j.RollingFileAppenderlog4j.appender.ROLLING.File=/var/log/sematext/awesome.loglog4j.appender.ROLLING.MaxFileSize=1024KBlog4j.appender.ROLLING.MaxBackupIndex=10log4j.appender.ROLLING.layout=org.apache.log4j.PatternLayoutlog4j.appender.ROLLING.layout.ConversionPattern=%r %-5p %c %x - %m%n
Notre enregistreur racine est configuré pour tout enregistrer à partir de la gravité du DÉBOGAGE et pour envoyer les journaux à deux Appenders – le PRINCIPAL et le ROLLING. L’enregistreur PRINCIPAL est celui que nous avons déjà vu – celui qui envoie les données à la console.
Le deuxième enregistreur, celui appelé ROLLING est le plus intéressant dans cet exemple. Il utilise le RollingFileAppender qui écrit les données dans le fichier et définissons la taille du fichier et le nombre de fichiers à conserver. Dans notre cas, les fichiers journaux devraient être appelés géniaux.enregistrez et écrivez les données dans le répertoire /var/log/sematext/. Chaque fichier doit être d’un maximum de 1024 Ko et il ne doit pas y avoir plus de 10 fichiers stockés. S’il y a plus de fichiers, ils seront supprimés du système de fichiers dès que log4j les verra.
Après avoir exécuté le code avec la configuration ci-dessus, la console imprimerait le contenu suivant:
0 INFO com.sematext.blog.ExampleAppenders - Starting ExampleAppenders application1 WARN com.sematext.blog.ExampleAppenders - Ending ExampleAppenders application
Dans le fichier /var/log/sematext/awesome.fichier journal que nous verrions:
0 INFO com.sematext.blog.ExampleAppenders - Starting ExampleAppenders application1 WARN com.sematext.blog.ExampleAppenders - Ending ExampleAppenders application
Niveau de journal d’Appender
La bonne chose à propos des Appenders est qu’ils peuvent avoir leur niveau qui doit être pris en compte lors de la journalisation. Tous les exemples que nous avons vus jusqu’à présent ont enregistré tous les messages ayant la gravité du DÉBOGAGE ou supérieure. Et si nous voulions changer cela pour toutes les classes de la com.sematext.forfait blog? Nous n’aurions qu’à modifier notre fichier log4j.properties:
log4j.rootLogger=DEBUG, MAINlog4j.appender.MAIN=org.apache.log4j.ConsoleAppenderlog4j.appender.MAIN.layout=org.apache.log4j.PatternLayoutlog4j.appender.MAIN.layout.ConversionPattern=%r %-5p %c %x - %m%nlog4j.logger.com.sematext.blog=WARN
Regardez la dernière ligne du fichier de configuration ci-dessus. Nous avons utilisé le préfixe log4j.logger et dit que l’enregistreur appelé com.sematext.le blog ne doit être utilisé que pour les niveaux de gravité WARN et plus, donc ERREUR et FATAL.
Notre exemple de code d’application ressemble à ceci:
public static void main(String args) { LOGGER.info("Starting ExampleAppenderLevel application"); LOGGER.warn("Ending ExampleAppenderLevel application");}
Avec la configuration Log4j ci-dessus, la sortie de la journalisation se présente comme suit:
0 WARN com.sematext.blog.ExampleAppenderLevel - Ending ExampleAppenderLevel application
Comme vous pouvez le voir, seul le journal de niveau WARN était inclus. C’est exactement ce que nous voulions.
Log4j Layouts
Enfin, la partie du cadre de journalisation Log4j qui contrôle la façon dont nos données sont structurées dans notre fichier journal – la mise en page. Log4j fournit quelques implémentations par défaut comme PatternLayout, SimpleLayout, XMLLayout, HTMLLayout, EnchancedPatternLayout et DateLayout.
Dans la plupart des cas, vous rencontrerez le PatternLayout. L’idée derrière cette mise en page est que vous pouvez fournir une variété d’options de formatage pour définir la structure des journaux. Certains des exemples sont:
- d – date et heure de l’événement de journal,
- m – message associé à l’événement de journal,
- t – nom du thread,
- n – séparateur de ligne dépendant de la plate-forme,
- p – niveau de journal.
Pour plus d’informations sur les options disponibles, rendez-vous sur les Javadocs officiels Log4j pour le PatternLayout.
Lors de l’utilisation de PatternLayout, nous pouvons configurer l’option que nous aimerions utiliser. Supposons que nous souhaitions écrire la date, la gravité de l’événement de journal, le thread entouré de crochets et le message de l’événement de journal. Nous pourrions utiliser un modèle comme celui-ci:
%d %-5p - %m%n
Le fichier log4j.properties complet dans ce cas pourrait se présenter comme suit:
log4j.rootLogger=DEBUG, MAINlog4j.appender.MAIN=org.apache.log4j.ConsoleAppenderlog4j.appender.MAIN.layout=org.apache.log4j.PatternLayoutlog4j.appender.MAIN.layout.ConversionPattern=%d %-5p - %m%n
Nous utilisons le %d pour afficher la date, le %-5p pour afficher la gravité en utilisant 5 caractères, %t pour le thread, %m pour le message et %n pour le séparateur de ligne. La sortie qui est écrite dans la console après l’exécution de notre exemple de code se présente comme suit:
2021-02-02 11:49:49,003 INFO - Initializing ExampleLog4jFormatter application
Contexte de diagnostic imbriqué
Dans la plupart des applications du monde réel, l’événement de journal n’existe pas seul. Il est entouré d’un certain contexte. Pour fournir un tel contexte, par thread, Log4j fournit le contexte de diagnostic dit imbriqué. De cette façon, nous pouvons lier un thread donné avec des informations supplémentaires, par exemple un identifiant de session, comme dans notre exemple d’application:
NDC.push(String.format("Session ID: %s", "1234-5678-1234-0987"));LOGGER.info("Initializing ExampleLog4jNDC application");
Lorsque vous utilisez un modèle qui inclut x variable, des informations supplémentaires seront incluses dans chaque ligne de connexion pour le thread donné. Dans notre cas, la sortie ressemblera à ceci:
0 INFO com.sematext.blog.ExampleLog4jNDC Session ID: 1234-5678-1234-0987 - Initializing ExampleLog4jNDC application
Vous pouvez voir que les informations sur l’identifiant de session se trouvent dans la ligne de connexion. Juste pour référence, le fichier log4j.properties que nous avons utilisé dans cet exemple se présente comme suit:
log4j.rootLogger=DEBUG, MAINlog4j.appender.MAIN=org.apache.log4j.ConsoleAppenderlog4j.appender.MAIN.layout=org.apache.log4j.PatternLayoutlog4j.appender.MAIN.layout.ConversionPattern=%r %-5p %c %x - %m%n
Contexte de diagnostic cartographié
Le deuxième type d’informations contextuelles que nous pouvons inclure dans nos événements de journal est le contexte de diagnostic cartographié. En utilisant la classe MDC, nous pouvons fournir des informations supplémentaires liées à la valeur clé. Similaire au contexte de diagnostic imbriqué, le contexte de diagnostic mappé est lié à un thread.
Regardons notre exemple de code d’application:
MDC.put("user", "[email protected]");MDC.put("step", "initial");LOGGER.info("Initializing ExampleLog4jNDC application");MDC.put("step", "launch");LOGGER.info("Starting ExampleLog4jNDC application");
Nous avons deux champs de contexte – l’utilisateur et l’étape. Pour afficher toutes les informations de contexte de diagnostic mappées associées à l’événement de journal, nous utilisons simplement la variable X dans notre définition de modèle. Par exemple:
log4j.rootLogger=DEBUG, MAINlog4j.appender.MAIN=org.apache.log4j.ConsoleAppenderlog4j.appender.MAIN.layout=org.apache.log4j.PatternLayoutlog4j.appender.MAIN.layout.ConversionPattern=%r %-5p %c %X - %m%n
Le lancement du code ci-dessus avec la configuration entraînerait la sortie suivante:
0 INFO com.sematext.blog.ExampleLog4jMDC {{step,initial}{user,[email protected]}} - Initializing ExampleLog4jNDC application1 INFO com.sematext.blog.ExampleLog4jMDC {{step,launch}{user,[email protected]}} - Starting ExampleLog4jNDC application
Nous pouvons également choisir les informations à utiliser en modifiant le motif. Par exemple, pour inclure l’utilisateur à partir du contexte de diagnostic mappé, nous pourrions écrire un modèle comme celui-ci:
%r %-5p %c %X{user} - %m%n
Cette fois, la sortie se présenterait comme suit:
0 INFO com.sematext.blog.ExampleLog4jMDC [email protected] - Initializing ExampleLog4jNDC application0 INFO com.sematext.blog.ExampleLog4jMDC [email protected] - Starting ExampleLog4jNDC application
Vous pouvez voir qu’au lieu du %X général, nous avons utilisé le %X{user}. Cela signifie que nous nous intéressons à la variable utilisateur à partir du contexte de diagnostic mappé associé à un événement de journal donné.
Migration vers Log4j 2
Migration depuis Log4j 1.x à Log4j 2.x n’est pas difficile et, dans certains cas, cela peut être très facile. Si vous n’avez utilisé aucun Log4j interne 1.x classes, vous avez utilisé des fichiers de configuration sur la configuration par programme des enregistreurs et vous n’avez pas utilisé les classes DOMConfigurator et PropertyConfigurator la migration doit être aussi simple que d’inclure l’api log4j-1.2.fichier jar jar au lieu du Log4j 1.x fichiers jar. Cela permettrait Log4j 2.x pour travailler avec votre code. Vous devrez ajouter le Log4j 2.x fichiers jar, ajustez la configuration, et voilà, c’est terminé.
Si vous souhaitez en savoir plus sur Log4j 2.x consultez notre tutoriel de journalisation Java et son Log4j 2.x section dédiée.
Cependant, si vous avez utilisé Log4j interne 1.x classes, le guide de migration officiel sur la façon de passer de Log4j 1.x à Log4j 2.x sera très utile. Il traite des modifications de code et de configuration nécessaires et sera inestimable en cas de doute.
Journalisation centralisée avec des outils de gestion des journaux
Envoyer des événements de journal à une console ou à un fichier peut être utile pour une seule application, mais gérer plusieurs instances de votre application et corréler les journaux à partir de plusieurs sources n’est pas amusant lorsque les événements de journal sont dans des fichiers texte sur différentes machines. Dans de tels cas, la quantité de données devient rapidement ingérable et nécessite des solutions dédiées – auto-hébergées ou provenant de l’un des fournisseurs. Et qu’en est-il des conteneurs où vous n’écrivez généralement même pas de journaux dans des fichiers? Comment dépannez-vous et déboguez-vous une application dont les journaux ont été émis sur la sortie standard ou dont le conteneur a été tué ?
C’est là que les services de gestion des journaux, les outils d’analyse des journaux et les services de journalisation dans le cloud entrent en jeu. C’est une bonne pratique de journalisation Java non écrite parmi les ingénieurs d’utiliser de telles solutions lorsque vous souhaitez sérieusement gérer vos journaux et en tirer le meilleur parti. Par exemple, Sematext Logs, notre logiciel de surveillance et de gestion des journaux, résout tous les problèmes mentionnés ci-dessus, et plus encore.
Avec une solution entièrement gérée comme Sematext Logs, vous n’avez pas à gérer une autre partie de l’environnement – votre solution de journalisation de BRICOLAGE, généralement construite à l’aide de morceaux de la pile élastique. De telles configurations peuvent commencer petites et bon marché, cependant, elles deviennent souvent grandes et chères. Pas seulement en termes de coûts d’infrastructure, mais aussi de coûts de gestion. Tu sais, le temps et la paie. Nous expliquons plus sur les avantages de l’utilisation d’un service géré dans notre article de blog sur les meilleures pratiques de journalisation.
Les alertes et l’agrégation de journaux sont également cruciales pour traiter les problèmes. Finalement, pour les applications Java, vous voudrez peut-être avoir des journaux de collecte des ordures une fois que vous aurez activé la connexion à la collecte des ordures et que vous commencerez à analyser les journaux. Ces journaux en corrélation avec les métriques sont une source d’informations inestimable pour résoudre les problèmes liés à la collecte des ordures.
Résumé
Même si Log4j 1.x a atteint sa fin de vie il y a longtemps il est encore présent dans un grand nombre d’applications héritées utilisées partout dans le monde. La migration vers sa version plus jeune est assez simple, mais peut nécessiter des ressources et du temps importants et n’est généralement pas une priorité absolue. Surtout dans les grandes entreprises où les procédures, les exigences légales, ou les deux nécessitent des audits suivis de tests longs et coûteux avant que quoi que ce soit puisse être modifié dans un système déjà en cours d’exécution. Mais pour ceux d’entre nous qui commencent tout juste ou qui pensent à la migration – rappelez-vous, Log4j 2.x est là, il est déjà mature, rapide, sûr et très capable.
Mais quel que soit le framework que vous utilisez pour enregistrer vos applications Java, nous vous recommandons de combiner vos efforts avec une solution de gestion des journaux entièrement gérée, telle que les journaux Sematext. Essayez-le! Un essai gratuit de 14 jours est disponible pour que vous puissiez le tester.
Bonne journalisation!