Le Passé, le Présent et l’avenir du PageRank de Google
L’algorithme PageRank (ou PR en abrégé) est un système de classement des pages Web développé par Larry Page et Sergey Brin à l’Université de Stanford à la fin des années 90. PageRank était en fait la page de base et Brin a créé le moteur de recherche Google.
De nombreuses années se sont écoulées depuis et, bien sûr, les algorithmes de classement de Google sont devenus beaucoup plus compliqués. Sont-ils toujours basés sur le PageRank? Comment le PageRank influence-t-il exactement le classement et à quoi les référenceurs devraient-ils se préparer à l’avenir ? Maintenant, nous allons trouver et résumer tous les faits et mystères autour de PageRank pour rendre l’image claire. Autant que possible.
Le passé du PageRank
Comme mentionné ci-dessus, dans leur projet de recherche universitaire, Brin et Page ont tenté d’inventer un système d’estimation de l’autorité des pages Web. Ils ont décidé de construire ce système sur des liens, qui servaient de votes de confiance donnés à une page. Selon la logique de ce mécanisme, plus il y a de ressources externes liées à une page, plus il y a d’informations précieuses pour les utilisateurs. Et PageRank (un score de 0 à 10 calculé en fonction de la quantité et de la qualité des liens entrants) a montré l’autorité relative d’une page sur Internet.
Formule originale du PageRank
Voyons comment fonctionne le PageRank. Chaque lien d’une page (A) à une autre (B) émet un vote dit, dont le poids dépend du poids collectif de toutes les pages qui renvoient à la page A. Et nous ne pouvons pas connaître leur poids avant de le calculer, donc le processus se déroule par cycles.
La formule mathématique du PageRank d’origine est la suivante:
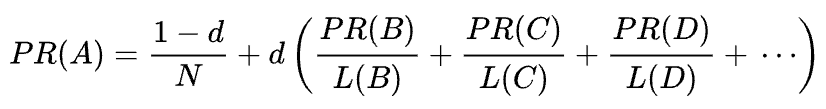
Où A, B, C et D sont quelques pages, L est le nombre de liens sortant de chacun d’eux et N est le nombre total de pages de la collection (c’est-à-dire sur Internet).
Quant à d, d est le facteur dit d’amortissement. Considérant que le PageRank est calculé en simulant le comportement d’un utilisateur qui accède au hasard à une page et clique sur des liens, nous appliquons ce facteur d’amortissement d comme la probabilité que l’utilisateur s’ennuie et quitte une page.
Comme vous pouvez le voir dans la formule, s’il n’y a pas de pages pointant vers la page, son PR ne sera pas nul mais
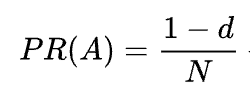
Car il y a une probabilité que l’utilisateur puisse accéder à cette page non pas à partir d’autres pages mais, disons, à partir de signets.
Vulnérabilité de manipulation de PageRank et guerre de Google contre le spam de liens
Au début, le score de PageRank était visible publiquement dans la barre d’outils de Google, et chaque page avait son score de 0 à 10, très probablement sur une échelle logarithmique.
Les algorithmes de classement de Google à cette époque étaient très simples — une forte densité de relations publiques et de mots clés étaient les deux seules choses dont une page avait besoin pour se classer haut sur un SERP. En conséquence, les pages Web étaient bourrées de mots-clés et les propriétaires de sites Web ont commencé à manipuler le PageRank en augmentant artificiellement les backlinks spammés. C’était facile à faire — les fermes de liens et la vente de liens étaient là pour donner un coup de main aux propriétaires de sites Web. »
Google a décidé de lutter contre le spam de lien. En 2003, Google a pénalisé le site Web de la société de réseau publicitaire SearchKing pour les manipulations de liens. SearchKing a poursuivi Google, mais Google a gagné. C’était une façon pour Google d’empêcher tout le monde de manipuler des liens, mais cela n’a rien donné. Les fermes Link sont juste entrées dans la clandestinité et leur quantité s’est considérablement multipliée.
De plus, les commentaires de spam sur les blogs se sont multipliés. Les robots ont attaqué les commentaires de n’importe quel blog WordPress, disons, et ont laissé un nombre énorme de commentaires « cliquez ici pour acheter des pilules magiques ». Pour éviter le spam et la manipulation des relations publiques dans les commentaires, Google a introduit la balise nofollow en 2005. Et encore une fois, ce que Google voulait dire devenir une étape réussie dans la guerre de la manipulation de liens a été mis en œuvre de manière tordue. Les gens ont commencé à utiliser les balises nofollow pour canaliser artificiellement le PageRank vers les pages dont ils avaient besoin. Cette tactique est devenue connue sous le nom de sculpture de PageRank.
Pour éviter la sculpture des relations publiques, Google a modifié le flux du PageRank. Auparavant, si une page avait à la fois des liens nofollow et dofollow, tout le volume de relations publiques de la page était transmis à d’autres pages liées avec les liens dofollow. En 2009, Google a commencé à diviser également les relations publiques d’une page entre tous les liens de la page, mais en ne transmettant que les partages qui ont été donnés aux liens dofollow.

Terminé avec la sculpture PageRank, Google n’a pas arrêté la guerre du spam de liens et a commencé par conséquent à retirer le score PageRank des yeux du public. Tout d’abord, Google a lancé le nouveau navigateur Chrome sans barre d’outils Google où le score de relations publiques était affiché. Ensuite, ils ont cessé de signaler le score de relations publiques dans la console de recherche Google. Ensuite, le navigateur Firefox a cessé de prendre en charge la barre d’outils Google. En 2013, PageRank a été mis à jour pour Internet Explorer pour la dernière fois, et en 2016, Google a officiellement fermé la barre d’outils pour le public.

Une autre façon utilisée par Google pour lutter contre les schémas de liens était Penguin update, qui désendettait les sites Web avec des profils de backlink louches. Déployé en 2012, Penguin n’est pas devenu une partie de l’algorithme en temps réel de Google, mais était plutôt un « filtre » mis à jour et réappliqué aux résultats de recherche de temps en temps. Si un site Web était pénalisé par Penguin, les référenceurs devaient examiner attentivement leurs profils de liens et supprimer les liens toxiques, ou les ajouter à une liste de désaveu (une fonctionnalité introduite à l’époque pour indiquer à Google les liens entrants à ignorer lors du calcul du PageRank). Après avoir audité les profils de liens de cette façon, les référenceurs ont dû attendre environ six mois jusqu’à ce que l’algorithme Penguin recalcule les données.
En 2016, Google a intégré Penguin à son algorithme de classement principal. Depuis lors, il fonctionne en temps réel, traitant algorithmiquement le spam avec beaucoup plus de succès.
Dans le même temps, Google a travaillé sur la facilitation de la qualité plutôt que de la quantité de liens, en le clouant dans ses directives de qualité contre les schémas de liens.
Le présent du PageRank
Eh bien, nous en avons fini avec le passé du PageRank. Que se passe-t-il maintenant ?
En 2019, un ancien employé de Google a déclaré que l’algorithme PageRank d’origine n’avait pas été utilisé depuis 2006 et avait été remplacé par un autre algorithme moins gourmand en ressources à mesure que l’Internet s’agrandissait. Ce qui pourrait bien être vrai, comme en 2006, Google a déposé le nouveau brevet de classement des pages utilisant des distances dans un graphique de lien Web.
L’algorithme PageRank est-il appliqué aujourd’hui ?
Oui, c’est le cas. Ce n’est pas le même PageRank qu’au début des années 2000, mais Google continue de s’appuyer fortement sur l’autorité des liens. Par exemple, un ancien employé de Google, Andrey Lipattsev, l’a mentionné en 2016. Dans un Google Q & Un lieu de rencontre, un utilisateur lui a demandé quels étaient les principaux signaux de classement utilisés par Google. La réponse d’Andrey était assez simple.
Je peux vous dire ce qu’ils sont. C’est du contenu et des liens pointant vers votre site.
Andrey Lipattsev

En 2020, John Mueller a confirmé qu’une fois de plus:
Oui, nous utilisons PageRank en interne, parmi beaucoup, beaucoup d’autres signaux. Ce n’est pas tout à fait la même chose que le papier original, il y a beaucoup de bizarreries (par exemple, des liens désavoués, des liens ignorés, etc.), et, encore une fois, nous utilisons beaucoup d’autres signaux qui peuvent être beaucoup plus forts.
John Mueller

Comme vous pouvez le voir, PageRank est toujours en vie et activement utilisé par Google lors du classement des pages sur le Web.
Ce qui est intéressant, c’est que les employés de Google ne cessent de nous rappeler qu’il y a beaucoup, beaucoup, BEAUCOUP d’autres signaux de classement. Mais nous regardons cela avec un grain de sel. Compte tenu de l’effort que Google a consacré à la lutte contre le spam de liens, il pourrait être intéressant pour Google de détourner l’attention des référents sur les facteurs vulnérables à la manipulation (comme le sont les backlinks) et d’attirer cette attention sur quelque chose d’innocent et de gentil. Mais comme les référenceurs sont bons pour lire entre les lignes, ils continuent de considérer le PageRank comme un signal de classement fort et de développer les backlinks de toutes les manières possibles. Ils utilisent encore des PBN, pratiquent la construction de liens à plusieurs niveaux à chapeau gris, achètent des liens, etc., comme c’était le cas il y a longtemps. Comme PageRank vit, le spam de lien vivra aussi. Nous ne recommandons rien de tout cela, mais c’est la réalité du référencement, et nous devons le comprendre.
Surfeur aléatoire vs Modèles de surfeur raisonnables de PageRank
Eh bien, vous avez l’idée que le PageRank n’est plus le PageRank qu’il était il y a 20 ans.
L’une des principales modernisations des relations publiques a été de passer du modèle de Surfeur aléatoire brièvement mentionné ci-dessus au modèle de Surfeur Raisonnable en 2012. Un internaute raisonnable suppose que les utilisateurs ne se comportent pas de manière chaotique sur une page et ne cliquent que sur les liens qui les intéressent pour le moment. Par exemple, en lisant un article de blog, vous êtes plus susceptible de cliquer sur un lien dans le contenu de l’article plutôt que sur un lien sur les conditions d’utilisation dans le pied de page.
De plus, un internaute raisonnable peut potentiellement utiliser une grande variété d’autres facteurs lors de l’évaluation de l’attractivité d’un lien. Tous ces facteurs ont été soigneusement examinés par Bill Slawski dans son article, mais j’aimerais me concentrer sur les deux facteurs, dont les référents discutent plus souvent. Ce sont la position du lien et le trafic de la page. Que pouvons-nous dire de ces facteurs?
Corrélation entre la position du lien et l’autorité du lien
Un lien peut être situé n’importe où sur la page — dans son contenu, son menu de navigation, la biographie de l’auteur, le pied de page et en fait tout élément structurel que contient la page. Et différents emplacements de lien affectent la valeur du lien. John Mueller l’a confirmé, affirmant que les liens placés dans le contenu principal pèsent plus que tous les autres:
C’est la zone de la page où vous avez votre contenu principal, le contenu de cette page, pas le menu, la barre latérale, le pied de page, l’en-tête Then Alors c’est quelque chose que nous prenons en compte et nous essayons d’utiliser ces liens.
John Mueller
Ainsi, on dit que les liens de pied de page et les liens de navigation ont moins de poids. Et ce fait est de temps en temps confirmé non seulement par les porte-parole de Google, mais par des cas réels.
Dans un cas récent présenté par Martin Hayman chez BrightonSEO, Martin a ajouté le lien qu’il avait déjà dans son menu de navigation vers le contenu principal des pages. En conséquence, ces pages de catégories et les pages auxquelles elles étaient liées ont connu une augmentation de trafic de 25%.
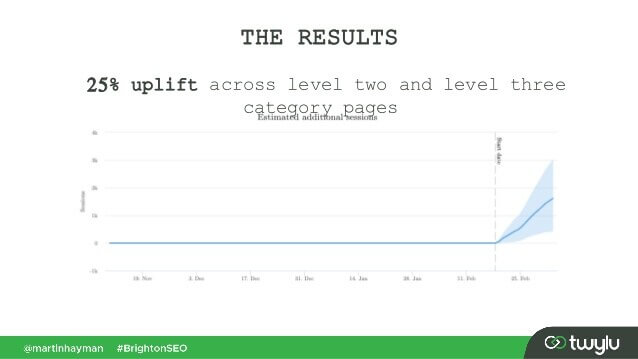
Cette expérience prouve que les liens de contenu ont plus de poids que les autres.
En ce qui concerne les liens dans la biographie de l’auteur, les référentiels supposent que les liens bio pèsent quelque chose, mais ont moins de valeur que, disons, les liens de contenu. Bien que nous n’ayons pas beaucoup de preuves ici, mais pour ce que Matt Cutts a dit lorsque Google luttait activement contre les blogs invités excessifs pour les backlinks.
Corrélation entre le trafic, le comportement de l’utilisateur et l’autorité de liaison
John Mueller a clarifié la manière dont Google traite le trafic et le comportement de l’utilisateur en termes de transmission de jus de lien dans l’un des hangouts centraux de la Console de recherche. Un utilisateur a demandé à Mueller si Google tenait compte de la probabilité de clics et du nombre de clics sur un lien lors de l’évaluation de la qualité d’un lien. Les principaux points à retenir de la réponse de Mueller étaient:
-
Google ne prend pas en compte les clics sur les liens et la probabilité de clics lors de l’évaluation de la qualité du lien.
-
Google comprend que des liens sont souvent ajoutés au contenu comme des références et que les utilisateurs ne sont pas tenus de cliquer sur tous les liens qu’ils rencontrent.
Pourtant, comme toujours, les référenceurs doutent que cela vaut la peine de croire aveuglément tout ce que dit Google et continuent d’expérimenter. Ainsi, les gars d’Ahrefs ont mené une étude pour vérifier si la position d’une page sur un SERP est connectée au nombre de backlinks qu’elle possède à partir de pages à fort trafic. L’étude a révélé qu’il n’y avait pratiquement aucune corrélation. De plus, certaines pages les mieux classées ne comportaient aucun lien retour provenant de pages riches en trafic.
Cette étude nous indique dans une direction similaire aux mots de John Mueller – vous n’avez pas besoin de créer des backlinks générant du trafic sur votre page pour obtenir des positions élevées sur un SERP. D’un autre côté, le trafic supplémentaire n’a jamais nui à aucun site Web. Le seul message ici est que les backlinks riches en trafic ne semblent pas influencer les classements Google.
Balises Nofollow, sponsorisées et UGC
Comme vous vous en souvenez, Google a introduit la balise nofollow en 2005 comme moyen de lutter contre le spam de liens. Quelque chose a-t-il changé aujourd’hui ? En fait, oui.
Tout d’abord, Google a récemment introduit deux autres types d’attribut nofollow. Avant cela, Google a suggéré de marquer tous les backlinks que vous ne souhaitez pas participer au calcul du PageRank comme nofollow, qu’il s’agisse de commentaires de blog ou d’annonces payantes. Aujourd’hui, Google recommande d’utiliser rel= »sponsored » pour les liens payants et d’affiliation et rel= »ugc » pour le contenu généré par l’utilisateur.
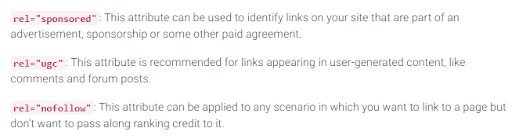
Il est intéressant de noter que ces nouvelles balises ne sont pas obligatoires (du moins pas encore), et Google souligne que vous n’avez pas à changer manuellement tous les rel= »nofollow » en rel= »sponsored » et rel= »ugc ». Ces deux nouveaux attributs fonctionnent désormais de la même manière qu’une balise nofollow ordinaire.
Deuxièmement, Google dit désormais que les balises nofollow, ainsi que les nouvelles, sponsored et ugc, sont traitées comme des indices, plutôt que comme une directive lors de l’indexation des pages.
Liens sortants et leur influence sur les classements
En plus des liens entrants, il existe également des liens sortants, c’est-à-dire des liens qui pointent vers d’autres pages de la vôtre.
De nombreux référenceurs pensent que les liens sortants peuvent avoir un impact sur les classements, mais cette hypothèse a été traitée comme un mythe SEO. Mais il y a une étude intéressante à examiner à cet égard.
Reboot Online a réalisé une expérience en 2015 et l’a relancée en 2020. Ils voulaient déterminer si la présence de liens sortants vers des pages de haute autorité influençait la position de la page sur un SERP. Ils ont créé 10 sites Web avec des articles de 300 mots, tous optimisés pour un mot-clé non existant – Phylandocic. 5 sites Web n’ont pas du tout de liens sortants et 5 sites Web contenaient des liens sortants vers des ressources de la haute autorité. En conséquence, les sites Web avec des liens sortants faisant autorité ont commencé à se classer le plus haut, et ceux n’ayant aucun lien du tout ont pris les positions les plus basses.

D’une part, les résultats de cette recherche peuvent nous dire que les liens sortants influencent les positions des pages. D’un autre côté, le terme de recherche dans la recherche est tout nouveau et le contenu des sites Web a pour thème la médecine et les médicaments. Il y a donc de fortes chances que la requête ait été classée comme YMYL. Et Google a plusieurs fois déclaré l’importance de l’E-A-T pour les sites Web YMYL. Ainsi, les outlinks auraient bien pu être traités comme un signal E-A-T, prouvant que les pages ont un contenu factuellement précis.
En ce qui concerne les requêtes ordinaires (pas YMYL), John Mueller a souvent dit que vous n’aviez pas à craindre de créer des liens vers des sources externes à partir de votre contenu, car les liens sortants sont bons pour vos utilisateurs.
De plus, les liens sortants peuvent également être bénéfiques pour le référencement, car ils peuvent être pris en compte par Google AI lors du filtrage du web contre le spam. Parce que les pages de spam ont tendance à avoir peu de liens sortants, voire aucun. Ils sont soit liés aux pages du même domaine (s’ils pensent un jour au référencement), soit ne contiennent que des liens payants. Donc, si vous créez un lien vers des ressources crédibles, vous montrez en quelque sorte à Google que votre page n’est pas une page de spam.
Il y avait une fois une opinion selon laquelle Google pourrait vous infliger une pénalité manuelle pour avoir trop de liens sortants, mais John Mueller a déclaré que cela n’était possible que lorsque les liens sortants faisaient évidemment partie d’un schéma d’échange de liens, plus le site Web est en général de mauvaise qualité. Ce que Google signifie sous obvious est en fait un mystère, alors gardez à l’esprit le bon sens, un contenu de haute qualité et un référencement de base.
Bataille de Google contre le spam de liens
Tant que le PageRank existe, les référenceurs chercheront de nouvelles façons de le manipuler.
En 2012, Google était plus susceptible de publier des actions manuelles pour la manipulation de liens et le spam. Mais maintenant, avec ses algorithmes anti-spam bien formés, Google est capable d’ignorer certains liens de spam lors du calcul du PageRank plutôt que de déclasser l’ensemble du site Web en général. Comme l’a dit John Mueller,
Les liens aléatoires collectés au fil des ans ne sont pas nécessairement nocifs, nous les avons vus depuis longtemps aussi, et nous pouvons ignorer tous ces morceaux étranges de graffitis sur le Web d’il y a longtemps.
John Mueller
Cela est également vrai pour le référencement négatif lorsque votre profil de backlink est compromis par vos concurrents:
En général, nous les prenons automatiquement en compte et nous essayons de ignore les ignorer automatiquement lorsque nous les voyons se produire. Pour la plupart, je soupçonne que cela fonctionne assez bien. Je vois très peu de gens avec des problèmes réels autour de cela. Donc, je pense que cela fonctionne généralement bien. En ce qui concerne le désaveu de ces liens, je soupçonne que s’il ne s’agit que de liens de spam normaux qui apparaissent juste pour votre site Web, je ne m’inquiéterais pas trop pour eux. Nous l’avons probablement compris nous-mêmes.
John Mueller
Cependant, cela ne signifie pas que vous n’avez rien à craindre. Si les backlinks de votre site Web sont trop et trop souvent ignorés, vous avez toujours de fortes chances d’obtenir une action manuelle. Comme le dit Marie Haynes dans ses conseils sur la gestion des liens en 2021:
Les actions manuelles sont réservées aux cas où un site autrement décent a des liens non naturels qui le pointent à une échelle si grande que les algorithmes de Google ne sont pas à l’aise de les ignorer.
Marie Haynes

Pour essayer de comprendre quels liens déclenchent le problème, vous pouvez utiliser un vérificateur de backlink comme SEO SpyGlass. Dans l’outil, accédez à la section Profil de Backlink > Risque de pénalité. Faites attention aux backlinks à risque élevé et moyen.
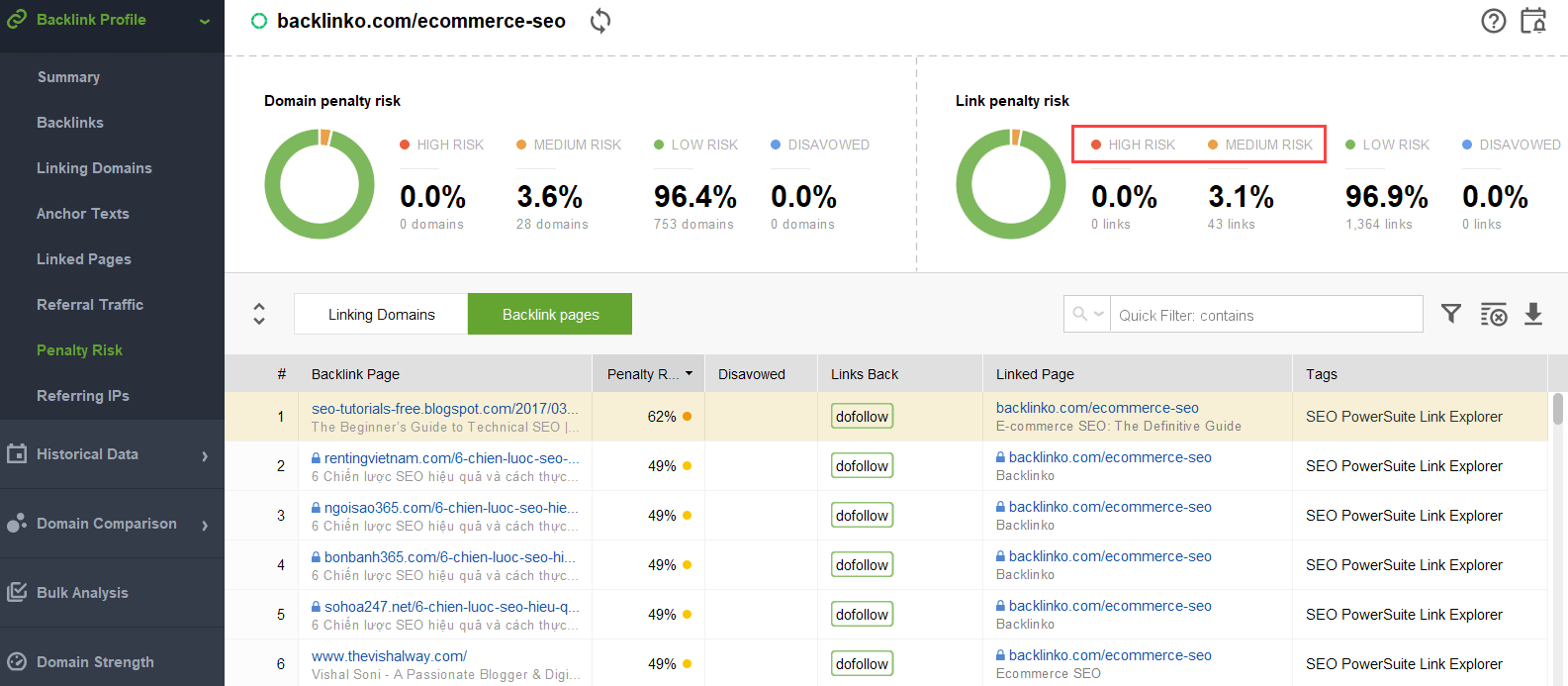
Pour étudier plus en détail pourquoi tel ou tel lien est signalé comme dangereux, cliquez sur je me connecte dans la colonne Risque de pénalité. Ici, vous verrez pourquoi l’outil a considéré le lien comme mauvais et vous déciderez si vous désavoueriez un lien ou non.
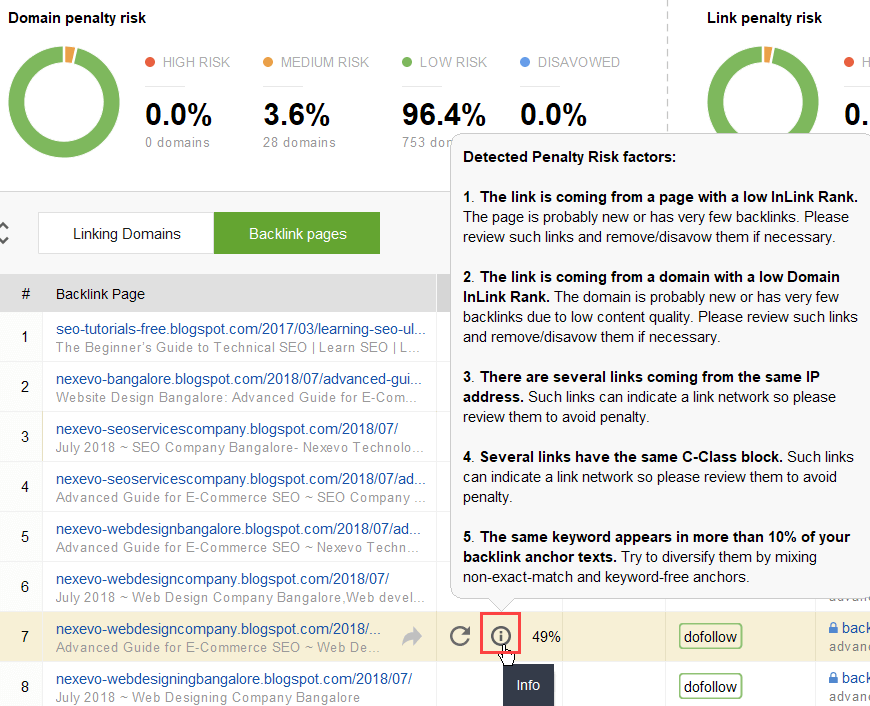
Si vous décidez de désavouer un lien d’un groupe de liens, cliquez dessus avec le bouton droit de la souris et choisissez l’option Désavouer le(s) backlink(s):
Une fois que vous avez formé une liste de liens à exclure, vous pouvez exporter le fichier de désaveu de SEO SpyGlass et le soumettre à Google via GSC.
Liens internes
En parlant de PageRank, nous ne pouvons que mentionner les liens internes. Le PageRank entrant est une sorte de chose que nous ne pouvons pas contrôler, mais nous pouvons totalement contrôler la façon dont les relations publiques sont réparties sur les pages de notre site Web.
Google a également souligné l’importance des liens internes à plusieurs reprises. John Mueller l’a souligné une fois de plus dans l’un des derniers hangouts centraux de la console de recherche. Un utilisateur a demandé comment rendre certaines pages Web plus puissantes. Et John Mueller a dit ce qui suit:
…Vous pouvez aider avec la liaison interne. Ainsi, au sein de votre site Web, vous pouvez vraiment mettre en évidence les pages que vous souhaitez mettre davantage en évidence et vous assurer qu’elles sont vraiment bien liées en interne. Et peut-être que les pages que vous ne trouvez pas si importantes, assurez-vous qu’elles sont un peu moins liées en interne.
John Mueller
La liaison interne signifie beaucoup. Il vous aide à partager le PageRank entrant entre différentes pages de votre site Web, renforçant ainsi vos pages sous-performantes et renforçant globalement votre site Web.
En ce qui concerne les approches de liaison interne, les référentiels ont de nombreuses théories différentes. Une approche populaire est liée à la profondeur de clic sur le site Web. Cette idée dit que toutes les pages de votre site Web doivent être à une distance maximale de 3 clics de la page d’accueil. Bien que Google ait souligné à plusieurs reprises l’importance d’une structure de site Web superficielle, cela semble en réalité inaccessible pour tous les sites Web plus grands que petits.
Une autre approche est basée sur le concept de liaison interne centralisée et décentralisée. Comme le décrit Kevin Indig:
Les sites centralisés ont un flux et un entonnoir d’utilisateurs uniques qui pointent vers une page clé. Les sites avec des liens internes décentralisés ont plusieurs points de contact de conversion ou différents formats d’inscription.
Kevin Indig

Dans le cas de la liaison interne centralisée, nous avons un petit groupe de pages de conversion ou une page, que nous voulons être puissants. Si nous appliquons des liens internes décentralisés, nous voulons que toutes les pages du site Web soient également puissantes et aient un PageRank égal pour les classer toutes pour vos requêtes.
Quelle option est la meilleure? Tout dépend des particularités de votre site Web et de votre créneau d’activité, ainsi que des mots-clés que vous allez cibler. Par exemple, la liaison interne centralisée convient mieux aux mots clés avec des volumes de recherche élevés et moyens, car elle se traduit par un ensemble étroit de pages super puissantes.
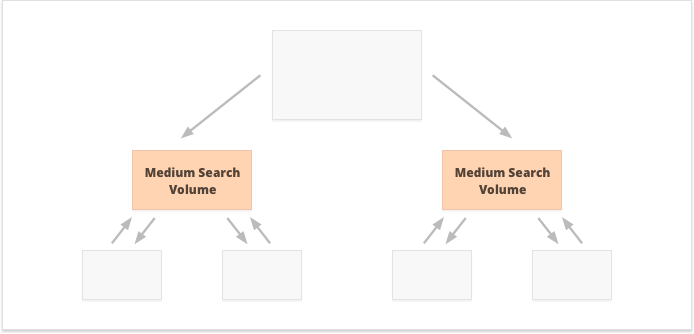
Les mots-clés à longue queue avec un faible volume de recherche, au contraire, sont meilleurs pour les liens internes décentralisés, car ils répartissent également les relations publiques entre de nombreuses pages de site Web.
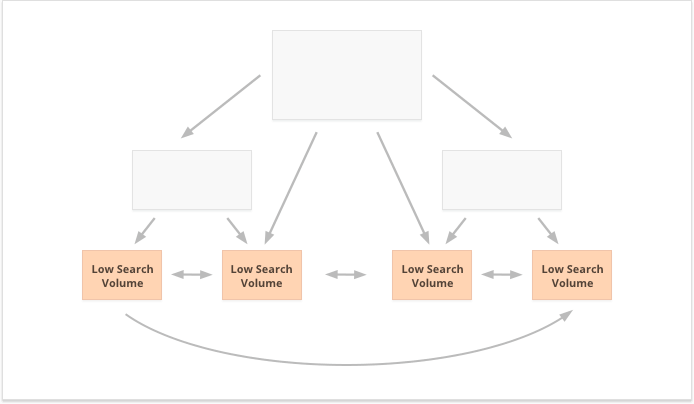
Un autre aspect d’une liaison interne réussie est l’équilibre des liens entrants et sortants sur la page. À cet égard, de nombreux référenceurs utilisent CheiRank (CR), qui est en fait un PageRank inverse. Mais alors que PageRank est le pouvoir reçu, CheiRank est le pouvoir de lien donné. Une fois que vous avez calculé PR et CR pour vos pages, vous pouvez voir quelles pages ont des anomalies de lien, c’est-à-dire les cas où une page reçoit beaucoup de PageRank mais passe un peu plus loin, et vice versa.
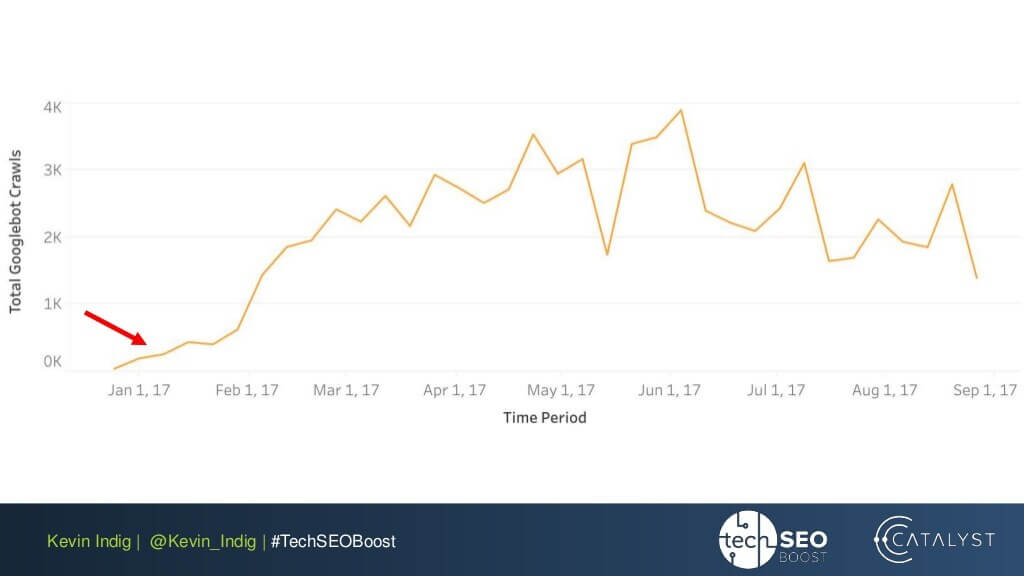
Une expérience intéressante ici est l’aplatissement des anomalies de liaison par Kevin Indig. Le simple fait de s’assurer que le PageRank entrant et sortant est équilibré sur chaque page du site Web a donné des résultats très impressionnants. La flèche rouge indique ici le moment où les anomalies ont été corrigées:
Les anomalies de liaison ne sont pas la seule chose qui peut nuire au flux de PageRank. Assurez-vous de ne pas vous retrouver avec des problèmes techniques, qui pourraient détruire vos relations publiques durement gagnées:
-
Pages orphelines. Les pages orphelines ne sont liées à aucune autre page de votre site Web, elles restent donc inactives et ne reçoivent aucun jus de lien. Google ne peut pas les voir et ne sait pas qu’ils existent réellement.
-
Rediriger les chaînes. Bien que Google indique que les redirections passent désormais 100% des relations publiques, il est toujours recommandé d’éviter les longues chaînes de redirection. D’abord, ils mangent de toute façon votre budget d’exploration. Deuxièmement, nous savons que nous ne pouvons pas croire aveuglément tout ce que dit Google.
-
Liens en JavaScript non séparable. Comme Google ne peut pas les lire, ils ne passeront pas PageRank.
-
404 liens. les liens 404 ne mènent nulle part, donc PageRank ne va nulle part aussi.
-
Liens vers des pages sans importance. Bien sûr, vous ne pouvez laisser aucune de vos pages sans aucun lien, mais les pages ne sont pas créées égales. Si une page est moins importante, il n’est pas rationnel de faire trop d’efforts pour optimiser le profil de lien de cette page.
-
Pages trop éloignées. Si une page est située trop profondément sur votre site Web, elle risque de recevoir peu ou pas de relations publiques du tout. Comme Google peut ne pas réussir à le trouver et à l’indexer.
Pour vous assurer que votre site Web est exempt de ces risques de PageRank, vous pouvez l’auditer avec WebSite Auditor. Cet outil dispose d’un ensemble complet de modules dans la section Audit de Site Structure >, qui vous permettent de vérifier l’optimisation globale de votre site Web et, bien sûr, de trouver et de résoudre tous les problèmes liés aux liens, tels que les longues redirections:
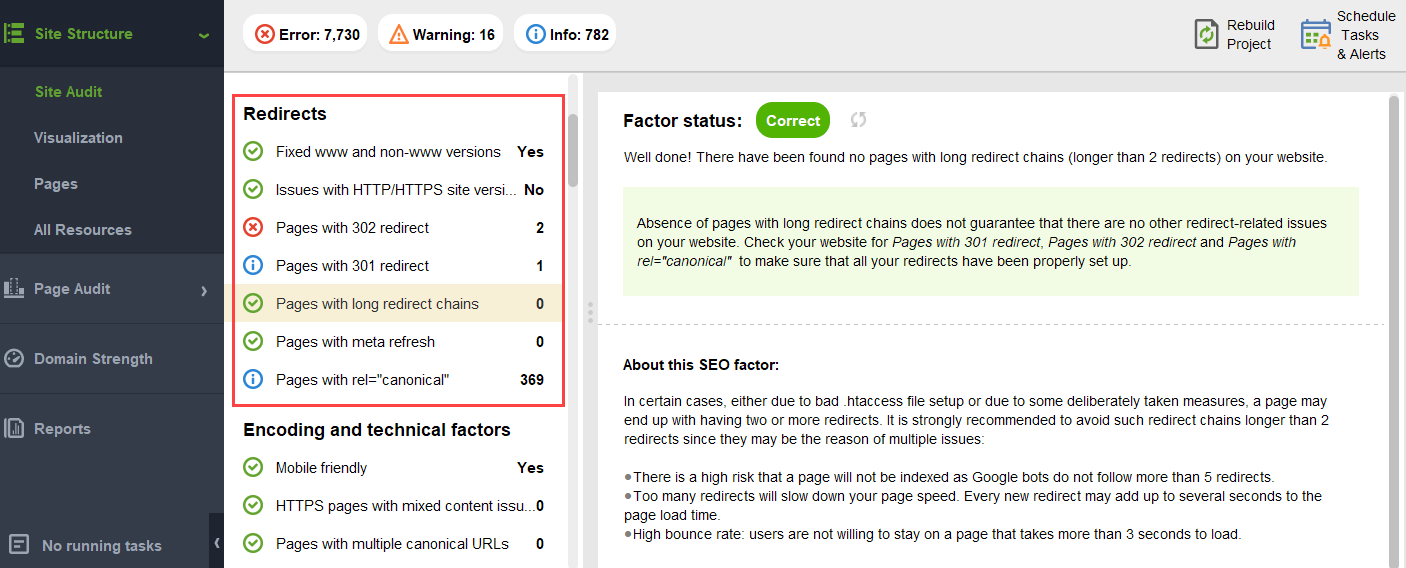
et liens rompus:
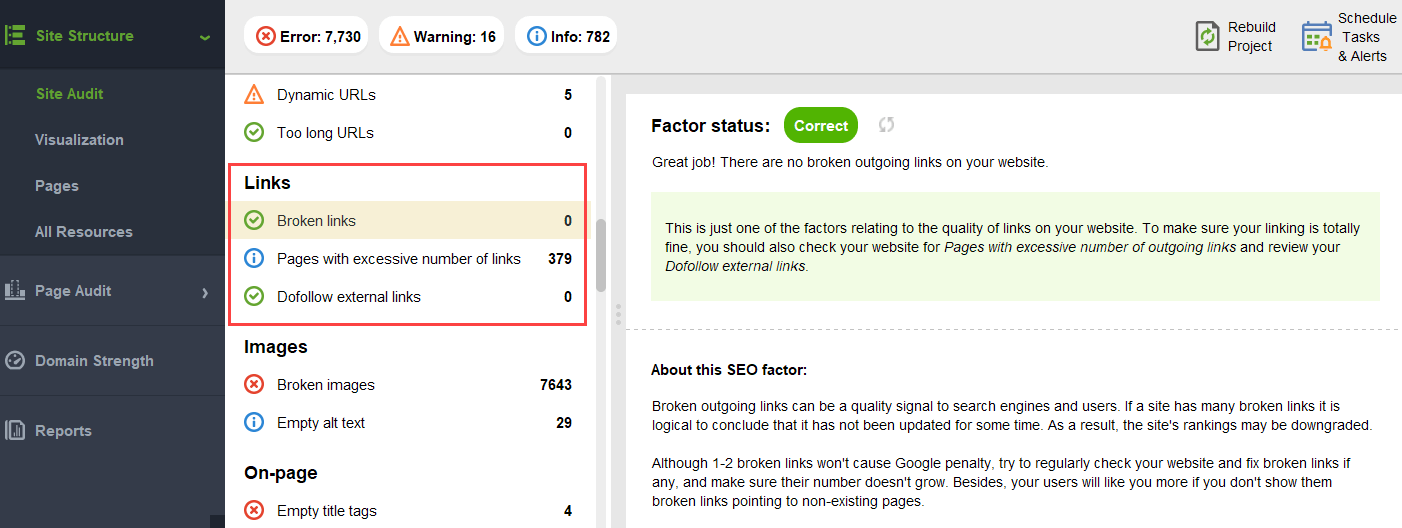
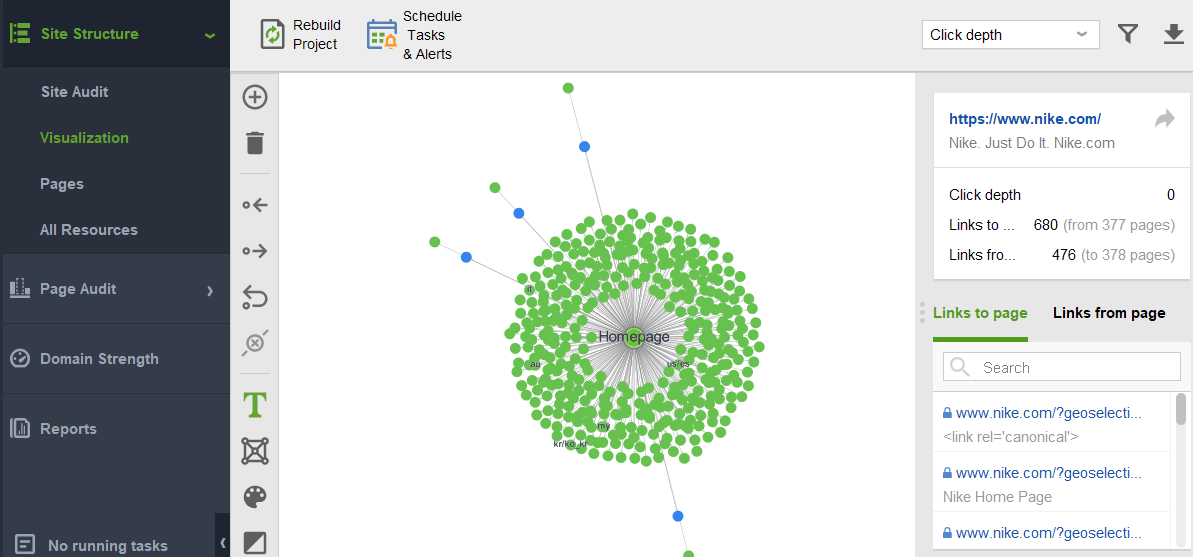
Pour rechercher sur votre site des pages orphelines ou des pages trop éloignées, passez à la visualisation Structure du site >:
L’avenir du PageRank
Cette année, le PageRank a 23 ans. Et je suppose que c’est plus vieux que certains de nos lecteurs aujourd’hui 🙂 Mais qu’est-ce qui va arriver pour PageRank à l’avenir? Va-t-il disparaître un jour ?
Moteurs de recherche sans backlinks
Lorsque vous essayez de penser à un moteur de recherche populaire n’utilisant pas de backlinks dans leur algorithme, la seule idée que je peux trouver est l’expérience Yandex en 2014. Le moteur de recherche a annoncé que la suppression des backlinks de leur algorithme pourrait enfin empêcher les spammeurs de liens de manipulations et aider à orienter leurs efforts vers la création de sites Web de qualité.
Cela aurait pu être un véritable effort pour aller vers des facteurs de classement alternatifs, ou simplement une tentative de persuader les masses de supprimer le spam de lien. Mais en tout cas, dans un an à peine après l’annonce, Yandex a confirmé que les facteurs de backlink étaient de retour dans leur système.
Mais pourquoi les backlinks sont-ils si indispensables pour les moteurs de recherche ?
Bien qu’il existe d’innombrables autres points de données pour réorganiser les résultats de recherche après avoir commencé à les afficher (comme le comportement de l’utilisateur et les ajustements du BERT), les backlinks restent l’un des critères d’autorité les plus fiables nécessaires pour former le SERP initial. Leur seul concurrent ici est probablement des entités.
Comme le dit Bill Slawski lorsqu’on l’interroge sur l’avenir de PageRank:
Google explore l’apprentissage automatique et l’extraction de faits et comprend les paires de valeurs clés pour les entités commerciales, ce qui signifie un mouvement vers la recherche sémantique et une meilleure utilisation des données structurées et de la qualité des données.
Bill Slawski, SEO au bord de la mer
.png)
Pourtant, Google est tout à fait différent de jeter quelque chose dans lequel ils ont investi des dizaines d’années de développement.
Google est très doué pour l’analyse de liens, qui est maintenant une technologie Web très mature. Pour cette raison, il est tout à fait possible que le PageRank continue d’être utilisé pour classer les SERPs organiques.
Bill Slawski, SEO au bord de la mer
Nouvelles et autres résultats sensibles au temps
Une autre tendance que Bill Slawski a soulignée était les nouvelles et d’autres types de résultats de recherche de courte durée:
Google nous a dit qu’il s’appuyait moins sur le PageRank pour les pages où l’actualité est plus importante, comme les résultats en temps réel (comme ceux de Twitter), ou les résultats des actualités, où l’actualité est très importante.
Bill Slawski, SEO au bord de la mer
En effet, une nouvelle vit beaucoup trop peu dans les résultats de recherche pour accumuler suffisamment de backlinks. Google a donc été et pourrait continuer à travailler pour remplacer les backlinks par d’autres facteurs de classement lorsqu’il s’agit de nouvelles.
Cependant, pour l’instant, les classements de nouvelles sont fortement déterminés par l’autorité de niche de l’éditeur, et nous lisons toujours l’autorité comme des backlinks:
» Les signaux d’autorité aident à hiérarchiser les informations de haute qualité provenant des sources les plus fiables disponibles. Pour ce faire, nos systèmes sont conçus pour identifier les signaux pouvant aider à déterminer quelles pages font preuve d’expertise, d’autorité et de fiabilité sur un sujet donné, en fonction des commentaires des évaluateurs de recherche. Ces signaux peuvent indiquer si d’autres personnes apprécient la source pour des requêtes similaires ou si d’autres sites Web importants sur le sujet renvoient à l’histoire. »
Les nouveaux attributs rel = »sponsored » et rel = »UGC »
Last but not least, j’ai été assez surpris par les efforts déployés par Google pour pouvoir identifier les backlinks sponsorisés et générés par les utilisateurs et les distinguer des autres liens non suivis.
Si tous ces backlinks doivent être ignorés, pourquoi se soucier de le dire à l’autre? Surtout avec John Muller suggérant que plus tard, Google pourrait essayer de traiter ces types de liens différemment.
Ma supposition la plus folle ici était que peut-être Google valide-t-il si la publicité et les liens générés par les utilisateurs pourraient devenir un signal de classement positif.
Après tout, la publicité sur les plateformes populaires nécessite des budgets énormes, et les budgets énormes sont un attribut d’une marque grande et populaire.
Le contenu généré par l’utilisateur, lorsqu’il est considéré en dehors du paradigme du spam de commentaires, concerne de vrais clients donnant leurs endossements réels.
Cependant, les experts que j’ai contactés ne croyaient pas que c’était possible:
Je doute que Google considère jamais les liens sponsorisés comme un signal positif.
Barry Schwartz, Table ronde sur les moteurs de recherche

L’idée ici, semble-t-il, est qu’en distinguant différents types de liens, Google essaierait de déterminer lequel des liens nofollow doit être suivi à des fins de création d’entités:
Google n’a aucun problème avec le contenu généré par l’utilisateur ou le contenu sponsorisé sur un site Web, mais les deux ont été historiquement utilisés comme méthodes de manipulation du pagerank. En tant que tels, les webmasters sont encouragés à placer un attribut nofollow sur ces liens (entre autres raisons d’utiliser nofollow).Cependant, les liens non suivis peuvent toujours être utiles à Google pour des choses (comme la reconnaissance d’entités par exemple), ils ont donc noté précédemment qu’ils pouvaient traiter cela comme une suggestion et non comme une directive comme un robot.la règle d’interdiction txt serait sur votre propre site.La déclaration de John Mueller était « Je pouvais imaginer dans nos systèmes que nous pourrions apprendre avec le temps à les traiter légèrement différemment. »Cela pourrait faire référence aux cas où Google traite un nofollow comme une suggestion. Hypothétiquement, il est possible que les systèmes de Google puissent savoir quels liens non suivis suivre en fonction des informations recueillies à partir des types de liens marqués comme ugc et sponsorisés. Encore une fois, cela ne devrait pas avoir beaucoup d’impact sur le classement d’un site – mais cela pourrait théoriquement avoir un impact sur le site lié également.
Callum Scott, Marie Haynes Consulting
