Exploration Web avec Python

L’exploration Web est une technique puissante pour collecter des données sur le Web en trouvant toutes les URL pour un ou plusieurs domaines. Python possède plusieurs bibliothèques et frameworks d’analyse Web populaires.
Dans cet article, nous allons d’abord introduire différentes stratégies d’exploration et des cas d’utilisation. Ensuite, nous allons construire un simple robot d’exploration Web à partir de zéro en Python en utilisant deux bibliothèques: requests et Beautiful Soup. Ensuite, nous verrons pourquoi il est préférable d’utiliser un framework d’exploration Web comme Scrapy. Enfin, nous allons construire un exemple de robot d’exploration avec Scrapy pour collecter des métadonnées de film à partir d’IMDb et voir comment Scrapy évolue vers des sites Web de plusieurs millions de pages.
Qu’est-ce qu’un robot d’exploration web ?
Web crawling et web scraping sont deux concepts différents mais liés. L’exploration Web est un composant du grattage Web, la logique du robot d’exploration trouve les URL à traiter par le code du grattoir.
Un robot d’exploration Web commence par une liste d’URL à visiter, appelée la graine. Pour chaque URL, le robot d’exploration trouve des liens dans le code HTML, filtre ces liens en fonction de certains critères et ajoute les nouveaux liens à une file d’attente. Tout le code HTML ou certaines informations spécifiques sont extraits pour être traités par un pipeline différent.
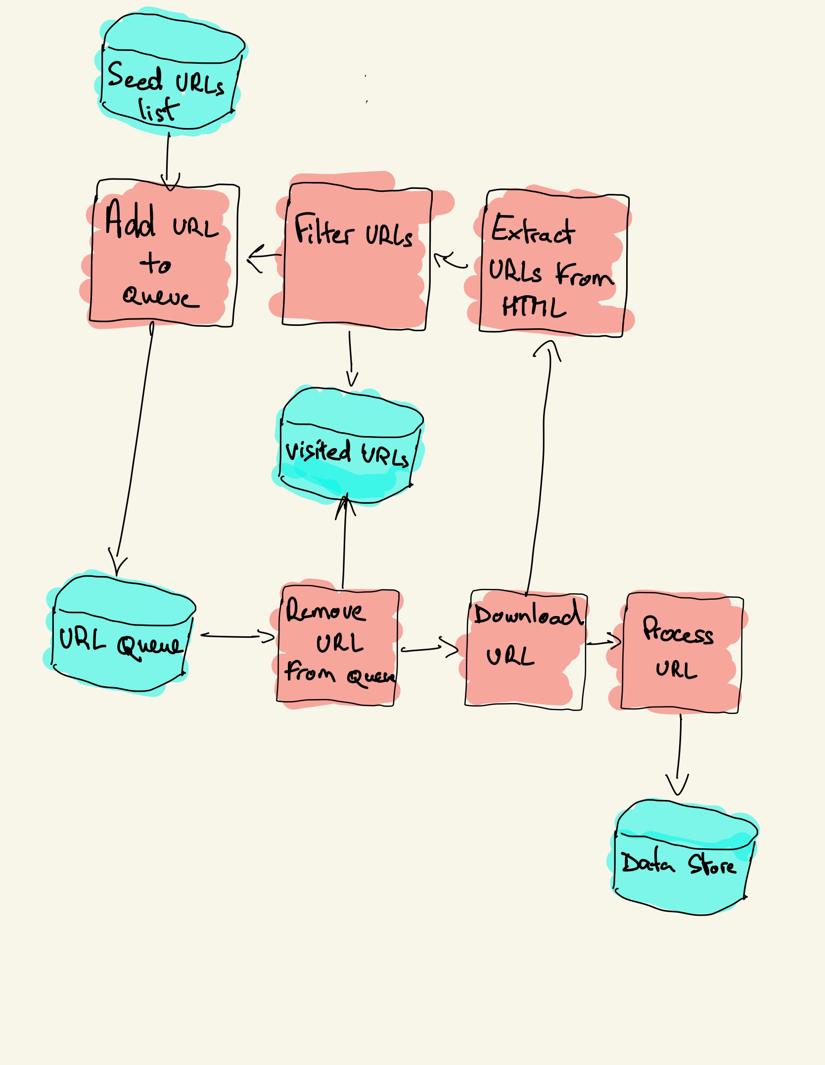
Stratégies d’exploration Web
En pratique, les robots d’exploration Web ne visitent qu’un sous-ensemble de pages en fonction du budget du robot, qui peut être un nombre maximum de pages par domaine, profondeur ou temps d’exécution.
Les sites Web les plus populaires fournissent un robot.fichier txt pour indiquer quelles zones du site Web sont interdites à l’exploration par chaque agent utilisateur. L’opposé du fichier robots est le plan du site.fichier xml, qui répertorie les pages qui peuvent être explorées.
Les cas d’utilisation populaires du robot d’exploration Web incluent:
- Les moteurs de recherche (Googlebot, Bingbot, Yandex Bot…) collectent tout le HTML pour une partie importante du Web. Ces données sont indexées pour les rendre consultables.
- Les outils d’analyse SEO en plus de la collecte du code HTML collectent également des métadonnées telles que le temps de réponse, l’état de la réponse pour détecter les pages cassées et les liens entre différents domaines pour collecter des backlinks.
- Les outils de suivi des prix explorent les sites de commerce électronique pour trouver des pages de produits et extraire des métadonnées, notamment le prix. Les pages produits sont ensuite périodiquement revisitées.
- Common Crawl maintient un référentiel ouvert de données d’analyse Web. Par exemple, l’archive d’octobre 2020 contient 2,71 milliards de pages Web.
Ensuite, nous comparerons trois stratégies différentes pour construire un robot d’exploration Web en Python. Tout d’abord, en utilisant uniquement des bibliothèques standard, puis des bibliothèques tierces pour faire des requêtes HTTP et analyser du HTML et enfin, un framework d’analyse Web.
Création d’un robot d’exploration web simple en Python à partir de zéro
Pour créer un robot d’exploration web simple en Python, nous avons besoin d’au moins une bibliothèque pour télécharger le code HTML à partir d’une URL et d’une bibliothèque d’analyse HTML pour extraire des liens. Python fournit des bibliothèques standard urllib pour faire des requêtes HTTP et html.analyseur pour analyser HTML. Un exemple de robot d’exploration Python construit uniquement avec des bibliothèques standard peut être trouvé sur Github.
Les bibliothèques Python standard pour les requêtes et l’analyse HTML ne sont pas très conviviales pour les développeurs. D’autres bibliothèques populaires comme requests, étiquetées HTTP pour les humains, et Beautiful Soup offrent une meilleure expérience de développeur.
Si vous souhaitez en savoir plus, vous pouvez consulter ce guide sur le meilleur client HTTP Python.
Vous pouvez installer les deux bibliothèques localement.
pip install requests bs4Un robot de base peut être construit en suivant le schéma d’architecture précédent.
import loggingfrom urllib.parse import urljoinimport requestsfrom bs4 import BeautifulSouplogging.basicConfig( format='%(asctime)s %(levelname)s:%(message)s', level=logging.INFO)class Crawler: def __init__(self, urls=): self.visited_urls = self.urls_to_visit = urls def download_url(self, url): return requests.get(url).text def get_linked_urls(self, url, html): soup = BeautifulSoup(html, 'html.parser') for link in soup.find_all('a'): path = link.get('href') if path and path.startswith('/'): path = urljoin(url, path) yield path def add_url_to_visit(self, url): if url not in self.visited_urls and url not in self.urls_to_visit: self.urls_to_visit.append(url) def crawl(self, url): html = self.download_url(url) for url in self.get_linked_urls(url, html): self.add_url_to_visit(url) def run(self): while self.urls_to_visit: url = self.urls_to_visit.pop(0) logging.info(f'Crawling: {url}') try: self.crawl(url) except Exception: logging.exception(f'Failed to crawl: {url}') finally: self.visited_urls.append(url)if __name__ == '__main__': Crawler(urls=).run()Le code ci-dessus définit une classe de robot avec des méthodes d’assistance pour download_url à l’aide de la bibliothèque de requêtes, get_linked_urls à l’aide de la belle bibliothèque Soup et add_url_to_visit pour filtrer les URL. Les URL à visiter et les URL visitées sont stockées dans deux listes distinctes. Vous pouvez exécuter le robot sur votre terminal.
python crawler.pyLe robot enregistre une ligne pour chaque URL visitée.
2020-12-04 18:10:10,737 INFO:Crawling: https://www.imdb.com/2020-12-04 18:10:11,599 INFO:Crawling: https://www.imdb.com/?ref_=nv_home2020-12-04 18:10:12,868 INFO:Crawling: https://www.imdb.com/calendar/?ref_=nv_mv_cal2020-12-04 18:10:13,526 INFO:Crawling: https://www.imdb.com/list/ls016522954/?ref_=nv_tvv_dvd2020-12-04 18:10:19,174 INFO:Crawling: https://www.imdb.com/chart/top/?ref_=nv_mv_2502020-12-04 18:10:20,624 INFO:Crawling: https://www.imdb.com/chart/moviemeter/?ref_=nv_mv_mpm2020-12-04 18:10:21,556 INFO:Crawling: https://www.imdb.com/feature/genre/?ref_=nv_ch_grLe code est très simple, mais il y a de nombreux problèmes de performances et d’utilisabilité à résoudre avant d’explorer avec succès un site Web complet.
- Le robot d’exploration est lent et ne supporte aucun parallélisme. Comme on peut le voir sur les horodatages, il faut environ une seconde pour analyser chaque URL. Chaque fois que le robot d’exploration fait une demande, il attend que la demande soit résolue et aucun travail n’est effectué entre les deux.
- La logique d’URL de téléchargement n’a pas de mécanisme de nouvelle tentative, la file d’attente d’URL n’est pas une vraie file d’attente et peu efficace avec un nombre élevé d’URL.
- La logique d’extraction de lien ne prend pas en charge la standardisation des URL en supprimant les paramètres de chaîne de requête d’URL, ne gère pas les URL commençant par #, ne prend pas en charge le filtrage des URL par domaine ou le filtrage des demandes vers des fichiers statiques.
- Le robot ne s’identifie pas et ignore les robots.fichier txt.
Ensuite, nous verrons comment Scrapy fournit toutes ces fonctionnalités et facilite l’extension de vos analyses personnalisées.
Web crawling avec Scrapy
Scrapy est le framework Python de grattage et d’exploration Web le plus populaire avec 40k étoiles sur Github. L’un des avantages de Scrapy est que les requêtes sont planifiées et traitées de manière asynchrone. Cela signifie que Scrapy peut envoyer une autre demande avant que la précédente ne soit terminée ou effectuer un autre travail entre les deux. Scrapy peut gérer de nombreuses demandes simultanées mais peut également être configuré pour respecter les sites Web avec des paramètres personnalisés, comme nous le verrons plus loin.
Scrapy a une architecture multi-composants. Normalement, vous implémenterez au moins deux classes différentes : Spider et Pipeline. Le grattage Web peut être considéré comme une ETL dans laquelle vous extrayez des données du Web et les chargez sur votre propre stockage. Les araignées extraient les données et les pipelines les chargent dans le stockage. La transformation peut se produire à la fois dans les araignées et les pipelines, mais je vous recommande de définir un pipeline Scrapy personnalisé pour transformer chaque élément indépendamment les uns des autres. De cette façon, ne pas traiter un élément n’a aucun effet sur les autres éléments.
En plus de tout cela, vous pouvez ajouter des middlewares spider et downloader entre les composants, comme on peut le voir dans le diagramme ci-dessous.
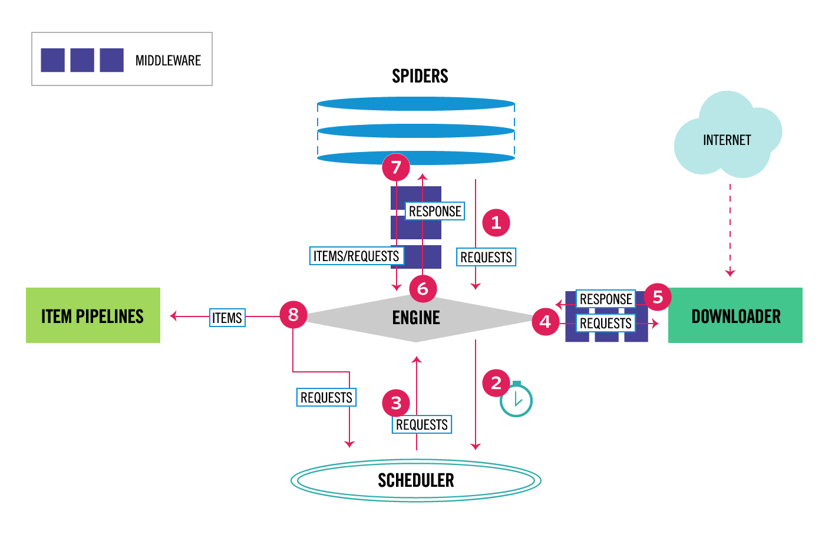
Aperçu de l’architecture Scrapy
Si vous avez déjà utilisé Scrapy, vous savez qu’un grattoir Web est défini comme une classe qui hérite de la classe Spider de base et implémente une méthode d’analyse pour gérer chaque réponse. Si vous êtes nouveau sur Scrapy, vous pouvez lire cet article pour un grattage facile avec Scrapy.
from scrapy.spiders import Spiderclass ImdbSpider(Spider): name = 'imdb' allowed_domains = start_urls = def parse(self, response): passScrapy fournit également plusieurs classes d’araignées génériques : CrawlSpider, XMLFeedSpider, CSVFeedSpider et SitemapSpider. La classe CrawlSpider hérite de la classe Spider de base et fournit un attribut de règles supplémentaire pour définir comment analyser un site Web. Chaque règle utilise un LinkExtractor pour spécifier les liens extraits de chaque page. Ensuite, nous verrons comment utiliser chacun d’eux en construisant un robot d’exploration pour IMDb, la base de données de films sur Internet.
Construire un exemple de robot Scrapy pour IMDb
Avant d’essayer d’explorer IMDb, j’ai vérifié les robots IMDb.fichier txt pour voir quels chemins d’URL sont autorisés. Le fichier robots n’autorise que 26 chemins pour tous les agents utilisateurs. Scrapy lit les robots.fichier txt au préalable et le respecte lorsque le paramètre ROBOTSTXT_OBEY est défini sur true. C’est le cas pour tous les projets générés avec la commande Scrapy startproject.
scrapy startproject scrapy_crawlerCette commande crée un nouveau projet avec la structure de dossier de projet Scrapy par défaut.
scrapy_crawler/├── scrapy.cfg└── scrapy_crawler ├── __init__.py ├── items.py ├── middlewares.py ├── pipelines.py ├── settings.py └── spiders ├── __init__.pyEnsuite, vous pouvez créer une araignée dans scrapy_crawler/spiders/imdb.py avec une règle pour extraire tous les liens.
from scrapy.spiders import CrawlSpider, Rulefrom scrapy.linkextractors import LinkExtractorclass ImdbCrawler(CrawlSpider): name = 'imdb' allowed_domains = start_urls = rules = (Rule(LinkExtractor()),)Vous pouvez lancer le robot d’exploration dans le terminal.
scrapy crawl imdb --logfile imdb.logVous obtiendrez beaucoup de journaux, y compris un journal pour chaque demande. En explorant les journaux, j’ai remarqué que même si nous définissions allowed_domains pour analyser uniquement les pages Web sous https://www.imdb.com, il y avait des requêtes vers des domaines externes, tels que amazon.com.
2020-12-06 12:25:18 DEBUG: Redirecting (302) to <GET https://www.amazon.com/b/?&node=5160028011&ref_=ft_iba> from <GET (https://www.imdb.com/whitelist-offsite?url=https%3A%2F%2Fwww.amazon.com%2Fb%2F%3F%26node%3D5160028011%26ref_%3Dft_iba&page-action=ft-iba&ref=ft_iba)>IMDb redirige des chemins d’URL sous liste blanche – hors site et liste blanche vers des domaines externes. Il existe un problème Github Scrapy ouvert qui montre que les URL externes ne sont pas filtrées lorsque le OffsiteMiddleware est appliqué avant le RedirectMiddleware. Pour résoudre ce problème, nous pouvons configurer l’extracteur de liens pour refuser les URL commençant par deux expressions régulières.
class ImdbCrawler(CrawlSpider): name = 'imdb' allowed_domains = start_urls = rules = ( Rule(LinkExtractor( deny=, )), )Les classes Rule et LinkExtractor prennent en charge plusieurs arguments pour filtrer les URL. Par exemple, vous pouvez ignorer des extensions d’URL spécifiques et réduire le nombre d’URL en double en triant les chaînes de requête. Si vous ne trouvez pas d’argument spécifique pour votre cas d’utilisation, vous pouvez passer une fonction personnalisée à process_links dans LinkExtractor ou process_values dans la règle.
Par exemple, IMDb a deux URL différentes avec le même contenu.
https://www.imdb.com/ nom / nm1156914/
https://www.imdb.com/ nom / nm1156914 /?mode=desktop& ref_=m_ft_dsk
Pour limiter le nombre d’URL explorées, nous pouvons supprimer toutes les chaînes de requête des URL avec la fonction url_query_cleaner de la bibliothèque w3lib et l’utiliser dans process_links.
from w3lib.url import url_query_cleanerdef process_links(links): for link in links: link.url = url_query_cleaner(link.url) yield linkclass ImdbCrawler(CrawlSpider): name = 'imdb' allowed_domains = start_urls = rules = ( Rule(LinkExtractor( deny=, ), process_links=process_links), )Maintenant que nous avons limité le nombre de demandes à traiter, nous pouvons ajouter une méthode parse_item pour extraire des données de chaque page et les transmettre à un pipeline pour les stocker. Par exemple, nous pouvons soit extraire la réponse entière.texte pour le traiter dans un pipeline différent ou sélectionner les métadonnées HTML. Pour sélectionner les métadonnées HTML dans la balise d’en-tête, nous pouvons coder nos propres XPATHs mais je trouve préférable d’utiliser une bibliothèque, extruct, qui extrait toutes les métadonnées d’une page HTML. Vous pouvez l’installer avec l’extrait d’installation pip.
import refrom scrapy.linkextractors import LinkExtractorfrom scrapy.spiders import CrawlSpider, Rulefrom w3lib.url import url_query_cleanerimport extructdef process_links(links): for link in links: link.url = url_query_cleaner(link.url) yield linkclass ImdbCrawler(CrawlSpider): name = 'imdb' allowed_domains = start_urls = rules = ( Rule( LinkExtractor( deny=, ), process_links=process_links, callback='parse_item', follow=True ), ) def parse_item(self, response): return { 'url': response.url, 'metadata': extruct.extract( response.text, response.url, syntaxes= ), }J’ai défini l’attribut follow sur True afin que Scrapy suive toujours tous les liens de chaque réponse, même si nous avons fourni une méthode d’analyse personnalisée. J’ai également configuré extruct pour extraire uniquement les métadonnées Open Graph et JSON-LD, une méthode populaire d’encodage des données liées à l’aide de JSON sur le Web, utilisée par IMDb. Vous pouvez exécuter le robot d’exploration et stocker des éléments au format lignes JSON dans un fichier.
scrapy crawl imdb --logfile imdb.log -o imdb.jl -t jsonlinesLe fichier de sortie imdb.jl contient une ligne pour chaque élément analysé. Par exemple, les métadonnées de graphe ouvert extraites d’un film provenant des balises < meta > du code HTML ressemblent à ceci.
{ "url": "http://www.imdb.com/title/tt2442560/", "metadata": {"opengraph": , , , , , ] }]}}Le JSON-LD pour un seul élément est trop long pour être inclus dans l’article, voici un exemple de ce que Scrapy extrait de la balise < script type= »application/ld + json » >.
"json-ld": , "contentRating": "TV-MA", "actor": ... }]En explorant les journaux, j’ai remarqué un autre problème courant avec les robots d’exploration. En cliquant séquentiellement sur les filtres, le robot génère des URL avec le même contenu, seulement que les filtres ont été appliqués dans un ordre différent.
https://www.imdb.com/ nom / nm2900465 / galerie vidéo / content_type-trailer / related_titles-tt0479468
https://www.imdb.com/ name/nm2900465 /videogallery /related_titles-tt0479468/content_type-trailer
Le filtre long et les URL de recherche sont un problème difficile qui peut être partiellement résolu en limitant la longueur des URL avec un paramètre Scrapy, URLLENGTH_LIMIT.
J’ai utilisé IMDb comme exemple pour montrer les bases de la construction d’un robot d’exploration Web en Python. Je n’ai pas laissé le robot fonctionner longtemps car je n’avais pas de cas d’utilisation spécifique pour les données. Si vous avez besoin de données spécifiques d’IMDb, vous pouvez consulter le projet IMDb Datasets qui fournit une exportation quotidienne des données IMDb et IMDbPY, un package Python pour récupérer et gérer les données.
Analyse Web à grande échelle
Si vous essayez d’explorer un grand site Web comme IMDb, avec plus de 45 millions de pages basées sur Google, il est important d’analyser de manière responsable en configurant les paramètres suivants. Vous pouvez identifier votre robot d’exploration et fournir les coordonnées dans le paramètre BOT_NAME. Pour limiter la pression que vous exercez sur les serveurs du site Web, vous pouvez augmenter le DÉLAI de TÉLÉCHARGEMENT, limiter le domaine CONCURRENT_REQUESTS_PER_DOMAIN ou définir AUTOTHROTTLE_ENABLED qui adaptera ces paramètres dynamiquement en fonction des temps de réponse du serveur.
Notez que les analyses Scrapy sont optimisées par défaut pour un seul domaine. Si vous analysez plusieurs domaines, vérifiez ces paramètres pour optimiser les analyses générales, y compris en modifiant l’ordre d’analyse par défaut de profondeur d’abord à respiration d’abord. Pour limiter votre budget d’exploration, vous pouvez limiter le nombre de requêtes avec le paramètre CLOSESPIDER_PAGECOUNT de l’extension close spider.
Avec les paramètres par défaut, Scrapy explore environ 600 pages par minute pour un site Web comme IMDb. Pour parcourir 45 millions de pages, il faudra plus de 50 jours pour un seul robot. Si vous avez besoin d’explorer plusieurs sites Web, il peut être préférable de lancer des robots d’exploration distincts pour chaque grand site Web ou groupe de sites Web. Si vous êtes intéressé par les analyses Web distribuées, vous pouvez lire comment un développeur a analysé 250 millions de pages avec Python en 40 heures à l’aide de 20 instances de machine Amazon EC2.
Dans certains cas, vous pouvez rencontrer des sites Web qui vous obligent à exécuter du code JavaScript pour afficher tout le code HTML. Ne le faites pas et vous ne pouvez pas collecter tous les liens sur le site Web. Parce que de nos jours, il est très courant que les sites Web rendent le contenu dynamiquement dans le navigateur, j’ai écrit un middleware Scrapy pour le rendu des pages JavaScript à l’aide de l’API de ScrapingBee.
Conclusion
Nous avons comparé le code d’un robot d’exploration Python utilisant des bibliothèques tierces pour télécharger des URL et analyser du HTML avec un robot d’exploration construit à l’aide d’un framework d’exploration Web populaire. Scrapy est un framework d’exploration Web très performant et il est facile à étendre avec votre code personnalisé. Mais vous devez connaître tous les endroits où vous pouvez accrocher votre propre code et les paramètres de chaque composant.
Configurer correctement Scrapy devient encore plus important lors de l’exploration de sites Web contenant des millions de pages. Si vous voulez en savoir plus sur l’exploration Web, je vous suggère de choisir un site Web populaire et d’essayer de l’explorer. Vous rencontrerez certainement de nouveaux problèmes, ce qui rend le sujet fascinant!