Web indeksoi Pythonia

Web crawling on tehokas tekniikka kerätä tietoja web etsimällä kaikki URL yhden tai useita verkkotunnuksia. Pythonilla on useita suosittuja web-indeksointikirjastoja ja-kehyksiä.
tässä artikkelissa esitellään ensin erilaisia indeksointistrategioita ja käyttötapauksia. Sitten rakennamme yksinkertaisen web crawlerin tyhjästä Pythonissa käyttäen kahta kirjastoa: pyyntöjä ja kaunista keittoa. Seuraava, näemme, miksi se on parempi käyttää web indeksointi puitteet kuten Scrapy. Lopuksi, rakennamme esimerkki crawler kanssa Scrapy kerätä elokuvan metatiedot IMDb ja nähdä, miten Scrapy asteikot sivustot useita miljoonia sivuja.
mikä on verkkohyökkääjä?
Web crawling ja web scraping ovat kaksi eri mutta toisiinsa liittyvää käsitettä. Web crawling on osa web kaavinta, crawler logiikka löytää URL-osoitteet käsitellään kaavin koodi.
verkkohyökkääjä aloittaa vierailtavien URL-osoitteiden luettelosta, jota kutsutaan siemeneksi. Kuhunkin URL-osoitteeseen crawler löytää linkkejä HTML: stä, suodattaa nämä linkit joidenkin kriteerien perusteella ja lisää uudet linkit jonoon. Kaikki HTML tai joitakin erityisiä tietoja uutetaan käsitellä eri putki.
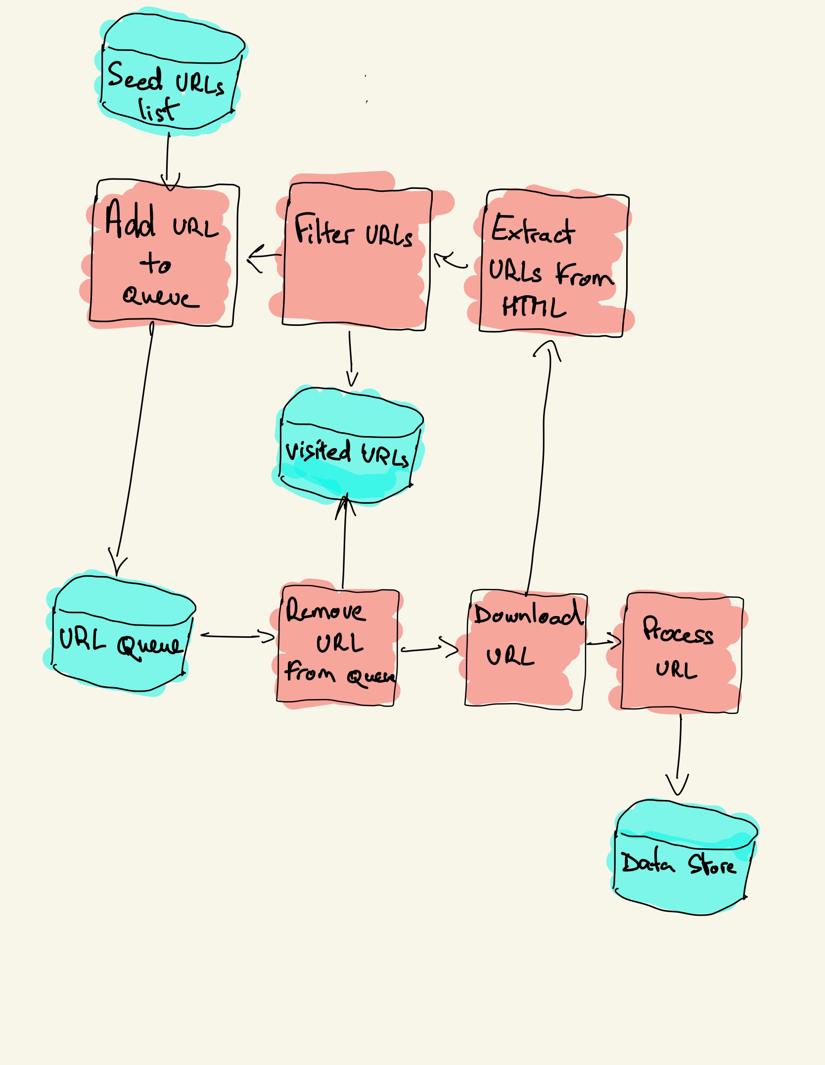
Web-indeksointistrategiat
käytännössä web-indeksoijat käyvät vain indeksointibudjetista riippuvan sivujoukon, joka voi olla maksimimäärä sivuja verkkotunnusta kohti, syvyys tai suoritusaika.
suosituimmat sivustot tarjoavat robottia.txt-tiedosto ilmoittaa, mitkä sivuston alueet ovat kiellettyjä indeksoida kunkin käyttäjän agentti. Vastakohta robotit tiedosto on sivukartta.xml-tiedosto, joka listaa sivut, jotka voidaan indeksoida.
suosittuja web-telaketjujen käyttötapauksia ovat:
- hakukoneet (Googlebot, Bingbot, Yandex Bot…) kerätä kaikki HTML merkittävä osa Web. Nämä tiedot indeksoidaan, jotta ne voidaan hakea.
- HTML: n keräämisen lisäksi SEO-analytiikkatyökalut keräävät myös metatietoja, kuten vasteajan, vastaustilan rikkinäisten sivujen havaitsemiseksi ja eri verkkotunnusten väliset linkit takaisinkytkentöjen keräämiseksi.
- Hintaseurantatyökalut ryömivät verkkokauppasivustoja etsiäkseen tuotesivuja ja poimiakseen metatietoja, erityisesti hintaa. Tämän jälkeen tuotesivuja tarkistetaan säännöllisesti.
- Common Crawl ylläpitää avointa web crawl-tietojen arkistoa. Esimerkiksi lokakuusta 2020 alkaen arkistossa on 2,71 miljardia verkkosivua.
seuraavaksi vertaamme kolmea eri strategiaa web-telaketjujen rakentamiseksi Pythonissa. Ensin käytetään vain standardikirjastoja, sitten kolmannen osapuolen kirjastoja HTTP-pyyntöjen tekemiseen ja HTML: n jäsentämiseen ja lopuksi web-indeksointikehys.
yksinkertaisen web crawlerin rakentaminen Pythonissa tyhjästä
yksinkertaisen web crawlerin rakentaminen Pythonissa tarvitsemme ainakin yhden kirjaston HTML: n lataamiseen URL-osoitteesta ja HTML: n jäsennyskirjaston linkkien poimimiseen. Python tarjoaa STANDARDIKIRJASTOT urlibin HTTP-pyyntöjen ja html: n tekemiseen.jäsennin HTML: n jäsentämiseen. Esimerkki Python-telaketjusta, joka on rakennettu vain standardikirjastoilla, löytyy GitHubista.
Python-standardikirjastot pyyntöjä ja HTML-jäsennystä varten eivät ole kovin kehittäjäystävällisiä. Muut suositut kirjastot kuten ihmisille HTTP-merkkiset pyynnöt ja kaunis keitto tarjoavat paremman kehittäjäkokemuksen.
jos haluat lisätietoja, voit tarkistaa tämän oppaan parhaasta Python HTTP-asiakasohjelmasta.
voit asentaa nämä kaksi kirjastoa paikallisesti.
pip install requests bs4peruslaturi voidaan rakentaa edellisen arkkitehtuurikaavion mukaisesti.
import loggingfrom urllib.parse import urljoinimport requestsfrom bs4 import BeautifulSouplogging.basicConfig( format='%(asctime)s %(levelname)s:%(message)s', level=logging.INFO)class Crawler: def __init__(self, urls=): self.visited_urls = self.urls_to_visit = urls def download_url(self, url): return requests.get(url).text def get_linked_urls(self, url, html): soup = BeautifulSoup(html, 'html.parser') for link in soup.find_all('a'): path = link.get('href') if path and path.startswith('/'): path = urljoin(url, path) yield path def add_url_to_visit(self, url): if url not in self.visited_urls and url not in self.urls_to_visit: self.urls_to_visit.append(url) def crawl(self, url): html = self.download_url(url) for url in self.get_linked_urls(url, html): self.add_url_to_visit(url) def run(self): while self.urls_to_visit: url = self.urls_to_visit.pop(0) logging.info(f'Crawling: {url}') try: self.crawl(url) except Exception: logging.exception(f'Failed to crawl: {url}') finally: self.visited_urls.append(url)if __name__ == '__main__': Crawler(urls=).run()koodi edellä määritellään Crawler Luokka helper menetelmiä download_url käyttäen pyynnöt kirjasto, get_linked_urls käyttäen kaunis keitto kirjasto ja add_url_to_visit suodattaa URL. Vierailtavat ja vieraillut URL-osoitteet tallennetaan kahteen erilliseen luetteloon. Voit ajaa telaketjua päätteessäsi.
python crawler.pycrawler kirjaa yhden rivin jokaista vierailtua URL-osoitetta kohti.
2020-12-04 18:10:10,737 INFO:Crawling: https://www.imdb.com/2020-12-04 18:10:11,599 INFO:Crawling: https://www.imdb.com/?ref_=nv_home2020-12-04 18:10:12,868 INFO:Crawling: https://www.imdb.com/calendar/?ref_=nv_mv_cal2020-12-04 18:10:13,526 INFO:Crawling: https://www.imdb.com/list/ls016522954/?ref_=nv_tvv_dvd2020-12-04 18:10:19,174 INFO:Crawling: https://www.imdb.com/chart/top/?ref_=nv_mv_2502020-12-04 18:10:20,624 INFO:Crawling: https://www.imdb.com/chart/moviemeter/?ref_=nv_mv_mpm2020-12-04 18:10:21,556 INFO:Crawling: https://www.imdb.com/feature/genre/?ref_=nv_ch_grkoodi on hyvin yksinkertainen, mutta on olemassa monia suorituskykyä ja käytettävyyttä kysymyksiä ratkaista ennen onnistuneesti indeksointi täydellinen verkkosivuilla.
- tela on hidas eikä tue yhdensuuntaisuutta. Kuten aikaleimoista näkyy, jokaisen URL-osoitteen ryömiminen kestää noin sekunnin. Aina kun tela tekee pyynnön, se odottaa, että pyyntö ratkeaa, eikä siinä välissä tehdä töitä.
- lataus-URL-logiikassa ei ole uudelleenyritysmekanismia, URL-jono ei ole todellinen jono eikä kovin tehokas runsaalla URL-osoitteiden määrällä.
- linkkien poistologiikka ei tue URL-osoitteiden standardointia poistamalla URL-kyselyn merkkijonoparametreja, ei käsittele # – alkuisia URL-osoitteita, ei tue verkko-osoitteiden suodattamista toimialueen mukaan tai pyyntöjen suodattamista staattisiin tiedostoihin.
- tela ei tunnista itseään ja jättää robotit huomioimatta.txt-tiedosto.
seuraavaksi nähdään, miten Scrapy tarjoaa kaikki nämä toiminnot ja tekee siitä helpon laajennuksen mukautetuille ryöminnöille.
Web crawling with Scrapy
Scrapy on suosituin web scraping ja crawling Python framework 40K-tähdillä GitHubilla. Yksi Scrapyn eduista on se, että pyynnöt ajoitetaan ja käsitellään asynkronisesti. Tämä tarkoittaa, että Scrapy voi lähettää toisen pyynnön ennen edellisen valmistumista tai tehdä jotain muuta työtä välissä. Scrapy voi käsitellä monia samanaikaisia pyyntöjä, mutta se voidaan myös määrittää kunnioittamaan verkkosivustoja mukautetuilla asetuksilla, kuten näemme myöhemmin.
Scrapy on arkkitehtuuriltaan monikomponenttinen. Normaalisti toteutat vähintään kaksi eri luokkaa: Spider ja Pipeline. Web scraping voidaan ajatella ETL, jossa voit poimia tietoja verkosta ja ladata sen omaan tallennustilaan. Hämähäkit ottavat datan talteen ja putkistot lastaavat sen varastoon. Transformaatio voi tapahtua sekä hämähäkeissä että putkistoissa, mutta suosittelen, että asetat custom Scrapy-putken, joka muuttaa jokaisen kohteen toisistaan riippumatta. Näin kohteen käsittelemättä jättämisellä ei ole vaikutusta muihin kohteisiin.
kaiken päälle voi lisätä Spider-ja downloader-välisarjoja komponenttien väliin, kuten alla olevasta kaaviosta käy ilmi.
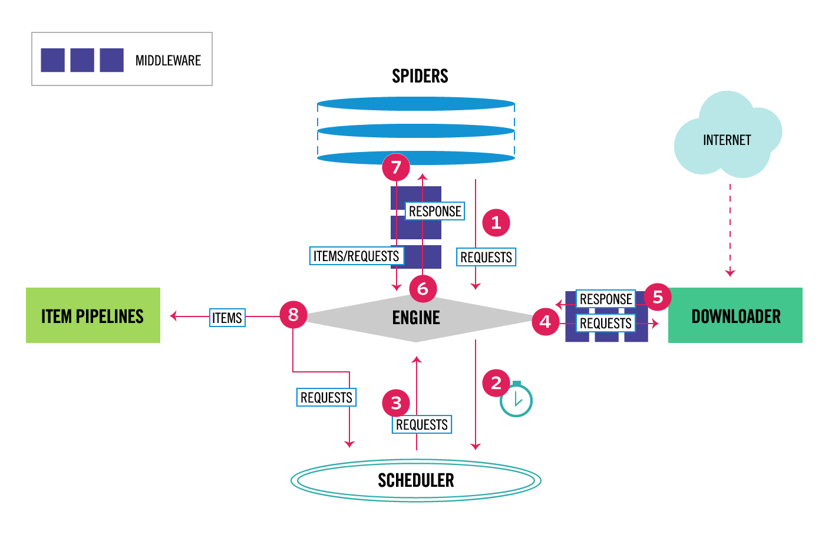
Scrapy Architecture Overview
jos olet käyttänyt Scrapya aiemmin, tiedät, että web scraper määritellään luokaksi, joka periytyy base Spider-luokasta ja toteuttaa jäsennysmenetelmän jokaisen vastauksen käsittelemiseksi. Jos olet uusi Scrapy, voit lukea tämän artikkelin helppo kaavinta Scrapy.
from scrapy.spiders import Spiderclass ImdbSpider(Spider): name = 'imdb' allowed_domains = start_urls = def parse(self, response): passScrapy tarjoaa myös useita yleisiä hämähäkkiluokkia: CrawlSpider, XMLFeedSpider, CSVFeedSpider ja SitemapSpider. CrawlSpider-Luokka periytyy base Spider-luokasta ja tarjoaa ylimääräiset säännöt-attribuutin, jonka avulla voit määritellä, miten verkkosivustoa ryömitään. Jokainen sääntö käyttää Linkkiextractor määrittää, mitkä linkit poimitaan jokaiselta sivulta. Seuraavaksi näemme, miten käyttää jokaista niistä rakentamalla telaketjua IMDb: hen, Internet Movie Databaseen.
rakensin IMDb: lle
ennen kuin yritin ryömiä IMDb: tä, tarkistin IMDb: n robotit.txt-tiedosto nähdäksesi, mitkä URL-polut ovat sallittuja. Robotit-tiedosto estää vain 26 polkua kaikille käyttäjä-agenteille. Scrapy lukee robotteja.txt tiedosto etukäteen ja kunnioittaa sitä, kun ROBOTSTXT_OBEY asetus on asetettu true. Tämä koskee kaikkia projekteja, jotka on luotu Scrapy-komennolla startproject.
scrapy startproject scrapy_crawlertämä komento luo uuden projektin scrapy-projektin oletuskansiorakenteella.
scrapy_crawler/├── scrapy.cfg└── scrapy_crawler ├── __init__.py ├── items.py ├── middlewares.py ├── pipelines.py ├── settings.py └── spiders ├── __init__.pysitten voit luoda hämähäkki scrapy_crawler/spiders/imdb.py säännöllä purkaa kaikki linkit.
from scrapy.spiders import CrawlSpider, Rulefrom scrapy.linkextractors import LinkExtractorclass ImdbCrawler(CrawlSpider): name = 'imdb' allowed_domains = start_urls = rules = (Rule(LinkExtractor()),)voit käynnistää tela terminaalissa.
scrapy crawl imdb --logfile imdb.logsaat paljon lokit, mukaan lukien yksi loki jokaista pyyntöä. Lokien tutkiminen huomasin, että vaikka asetamme allowed_domains vain indeksoida web-sivuja alle https://www.imdb.com, oli pyyntöjä ulkoisille verkkotunnuksille, kuten amazon.com.
2020-12-06 12:25:18 DEBUG: Redirecting (302) to <GET https://www.amazon.com/b/?&node=5160028011&ref_=ft_iba> from <GET (https://www.imdb.com/whitelist-offsite?url=https%3A%2F%2Fwww.amazon.com%2Fb%2F%3F%26node%3D5160028011%26ref_%3Dft_iba&page-action=ft-iba&ref=ft_iba)>IMDb ohjaa URL-polut whitelist-offsite ja whitelist ulkoisiin verkkotunnuksiin. On avoin Scrapy Github-ongelma, joka osoittaa, että ulkoiset URL-osoitteet eivät saa suodatettua pois, kun OffsiteMiddleware käytetään ennen uudelleenohjausta. Voit korjata tämän ongelman, voimme määrittää link extractor kieltää URL alkaa kaksi säännöllistä lauseketta.
class ImdbCrawler(CrawlSpider): name = 'imdb' allowed_domains = start_urls = rules = ( Rule(LinkExtractor( deny=, )), )sääntö-ja LinkExtractor-luokat tukevat useita argumentteja URL-osoitteiden suodattamiseksi. Voit esimerkiksi sivuuttaa tietyt URL-laajennukset ja vähentää päällekkäisten URL-osoitteiden määrää lajittelemalla kyselymerkkijonoja. Jos et löydä tiettyä argumenttia käyttötapauksellesi, voit siirtää mukautetun toiminnon Process_links-ohjelmaan Linkextractorissa tai process_values-sääntöön.
esimerkiksi IMDb: ssä on kaksi eri URL-osoitetta, joissa on sama sisältö.
https://www.imdb.com/nimi / nm1156914/
https://www.imdb.com/nimi / nm1156914/?mode=desktop&ref_ = m_ft_dsk
ryömittyjen URL-osoitteiden määrän rajoittamiseksi voimme poistaa kaikki kyselymerkkijonot URL-osoitteista url_query_cleaner-funktiolla w3lib-kirjastosta ja käyttää sitä process_linksissä.
from w3lib.url import url_query_cleanerdef process_links(links): for link in links: link.url = url_query_cleaner(link.url) yield linkclass ImdbCrawler(CrawlSpider): name = 'imdb' allowed_domains = start_urls = rules = ( Rule(LinkExtractor( deny=, ), process_links=process_links), )nyt kun olemme rajoittaneet pyyntöjen määrä käsitellä, voimme lisätä parse_item menetelmä poimia tietoja jokaiselta sivulta ja siirtää sen putki tallentaa sen. Voimme esimerkiksi joko poimia koko vastauksen.teksti sen käsittelemiseksi eri putkessa tai HTML-metatiedon valitsemiseksi. Voit valita HTML metatiedot otsikko tag voimme koodata omia XPATHs mutta mielestäni on parempi käyttää kirjastoa, extruct, joka poimii kaikki metatiedot HTML-sivu. Voit asentaa sen pip install extract.
import refrom scrapy.linkextractors import LinkExtractorfrom scrapy.spiders import CrawlSpider, Rulefrom w3lib.url import url_query_cleanerimport extructdef process_links(links): for link in links: link.url = url_query_cleaner(link.url) yield linkclass ImdbCrawler(CrawlSpider): name = 'imdb' allowed_domains = start_urls = rules = ( Rule( LinkExtractor( deny=, ), process_links=process_links, callback='parse_item', follow=True ), ) def parse_item(self, response): return { 'url': response.url, 'metadata': extruct.extract( response.text, response.url, syntaxes= ), }asetan seuraa attribuutin True niin, että Scrapy seuraa edelleen kaikkia linkkejä jokaisesta vastauksesta, vaikka annoimme mukautetun jäsennysmenetelmän. Olen myös konfiguroinut extruct poimia vain avoin Graph metadata ja JSON-LD, suosittu menetelmä koodata linkitettyjä tietoja käyttäen JSON Web, jota IMDb. Voit ajaa crawler ja tallentaa kohteita JSON lines muodossa tiedostoon.
scrapy crawl imdb --logfile imdb.log -o imdb.jl -t jsonlinestulostiedosto imdb.jl sisältää yhden rivin jokaista ryömittyä kohdetta kohti. Esimerkiksi HTML: n <meta> tageista otetun elokuvan uutettu Open Graph metadata näyttää tältä.
{ "url": "http://www.imdb.com/title/tt2442560/", "metadata": {"opengraph": , , , , , ] }]}}yksittäisen esineen JSON-LD on liian pitkä sisältyäkseen artikkeliin, tässä näyte siitä, mitä Raaputusotteita <script type=”application/LD+json”> tagista.
"json-ld": , "contentRating": "TV-MA", "actor": ... }]tutkimalla lokit, huomasin toinen yhteinen ongelma indeksoijat. Napsauttamalla suodattimia peräkkäin tela luo URL-osoitteita, joissa on sama sisältö, vain että suodattimia käytettiin eri järjestyksessä.
https://www.imdb.com/nimi/nm2900465 / videogallery / content_type-trailer / related_titles-tt0479468
https://www.imdb.com/name/nm2900465/videogallery/related_titles-tt0479468 / content_type-trailer
Long filter and search URL on vaikea ongelma, joka voidaan osittain ratkaista rajoittamalla URL-osoitteiden pituutta Scrapy-asetuksella, URLLENGTH_LIMIT.
käytin IMDb: tä esimerkkinä näyttääkseni Pythonissa verkkohelastimen rakentamisen perusteet. En antanut telaketjua pyörimään pitkään, koska minulla ei ollut datalle erityistä käyttötapausta. Jos tarvitset tiettyjä tietoja IMDb: stä, voit tarkistaa IMDb-tietokokonaisuudet-projektin, joka tarjoaa päivittäisen IMDb-tietojen viennin ja imdbpy-paketin, joka on Python-paketti tietojen hakemista ja hallintaa varten.
Web crawling asteikolla
jos yrität ryömiä IMDb: n kaltaista isoa verkkosivustoa, jossa on yli 45m sivuja Googlen varassa, on tärkeää ryömiä vastuullisesti määrittämällä seuraavat asetukset. Voit tunnistaa telaketjusi ja antaa yhteystietosi BOT_NAME-asetuksessa. Rajoittaaksesi verkkosivuston palvelimille asettamaasi painetta voit lisätä DOWNLOAD_DELAYTA, rajoittaa SAMANAIKAISTA_REQUESTS_PER_DOMAINIA tai asettaa AUTOMAATTIROTTLE_ENABLED-järjestelmän, joka mukauttaa näitä asetuksia dynaamisesti palvelimelta tulevien vasteaikojen perusteella.
huomaa, että Scrapy crawls on oletusarvoisesti optimoitu yhdelle verkkotunnukselle. Jos indeksoit useita verkkotunnuksia, tarkista nämä asetukset optimoidaksesi laajat ryömintätilaukset, mukaan lukien oletusarvoisen ryömintäjärjestyksen muuttaminen syvyys-ensin-hengitykseen-ensin. Jos haluat rajoittaa ryömimisbudjettiasi, voit rajoittaa pyyntöjen määrää close spider-laajennuksen closespider_pagecount-asetuksella.
oletusasetuksilla Scrapy ryömii noin 600 sivua minuutissa IMDb: n kaltaiselle verkkosivustolle. 45m sivujen ryömiminen vie yli 50 päivää yhdeltä robotilta. Jos haluat indeksoida useita sivustoja, voi olla parempi käynnistää erilliset indeksoijat jokaiselle isolle verkkosivustolle tai verkkosivustoryhmälle. Jos olet kiinnostunut hajautetuista web-indekseistä, voit lukea, miten kehittäjä ryömi 250m sivuja Pythonilla 40 tunnissa käyttäen 20 Amazon EC2 – koneyksityiskohtaa.
joissakin tapauksissa saatat törmätä verkkosivustoihin, jotka edellyttävät JavaScript-koodin suorittamista kaiken HTML: n renderöimiseksi. Jos et tee niin, et välttämättä kerää kaikkia linkkejä sivustolla. Koska nykyään se on hyvin yleistä sivustot tehdä sisältöä dynaamisesti selaimessa kirjoitin Scrapy väliohjelmisto renderöinti JavaScript sivuja käyttäen ScrapingBee API.
johtopäätös
vertasimme kolmannen osapuolen kirjastoja käyttävän Python-indeksoijan koodia URL-osoitteiden lataamiseen ja HTML: n jäsentämiseen suositun web-indeksointikehyksen avulla rakennettuun telaketjuun. Scrapy on erittäin tehokas web indeksointi puitteet ja se on helppo laajentaa mukautetun koodin. Mutta sinun täytyy tietää kaikki paikat, joissa voit kytkeä oman koodin ja asetukset kunkin komponentin.
Scrapyn määrittäminen oikein tulee entistä tärkeämmäksi, kun indeksoidaan miljoonia sivuja. Jos haluat oppia lisää web indeksointi ehdotan, että valitset suosittu sivusto ja yrittää indeksoida sitä. Törmäät varmasti uusiin kysymyksiin, mikä tekee aiheesta kiehtovan!