Webcrawling mit Python

Webcrawling ist eine leistungsstarke Technik zum Sammeln von Daten aus dem Web, indem alle URLs für eine oder mehrere Domains gefunden werden. Python verfügt über mehrere beliebte Webcrawling-Bibliotheken und -Frameworks.
In diesem Artikel stellen wir zunächst verschiedene Crawling-Strategien und Anwendungsfälle vor. Dann werden wir einen einfachen Webcrawler von Grund auf in Python mit zwei Bibliotheken erstellen: requests und Beautiful Soup. Als nächstes werden wir sehen, warum es besser ist, ein Webcrawling-Framework wie Scrapy zu verwenden. Schließlich werden wir einen Beispiel-Crawler mit Scrapy erstellen, um Filmmetadaten aus der IMDb zu sammeln und zu sehen, wie Scrapy auf Websites mit mehreren Millionen Seiten skaliert werden kann.
Was ist ein Webcrawler?
Webcrawling und Web Scraping sind zwei verschiedene, aber verwandte Konzepte. Die Crawler-Logik findet URLs, die vom Scraper-Code verarbeitet werden sollen.
Ein Webcrawler beginnt mit einer Liste der zu besuchenden URLs, dem sogenannten Seed. Für jede URL findet der Crawler Links im HTML-Code, filtert diese Links nach bestimmten Kriterien und fügt die neuen Links einer Warteschlange hinzu. Der gesamte HTML-Code oder bestimmte Informationen werden extrahiert, um von einer anderen Pipeline verarbeitet zu werden.
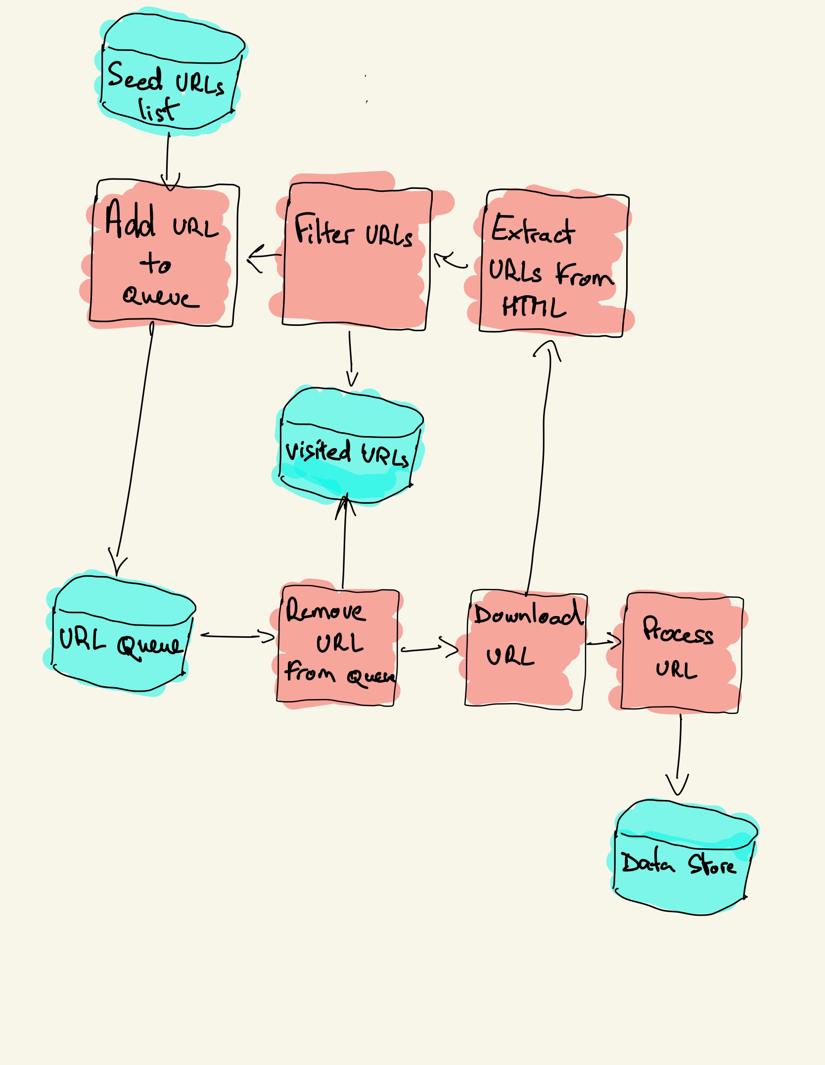
Webcrawling-Strategien
In der Praxis besuchen Webcrawler nur eine Teilmenge von Seiten, abhängig vom Crawler-Budget, das eine maximale Anzahl von Seiten pro Domain, Tiefe oder Ausführungszeit sein kann.
Die beliebtesten Websites bieten einen Roboter.txt-Datei, um anzugeben, welche Bereiche der Website von jedem Benutzeragenten nicht gecrawlt werden dürfen. Das Gegenteil der Robots-Datei ist die Sitemap.XML-Datei, die die Seiten auflistet, die gecrawlt werden können.
Beliebte Webcrawler-Anwendungsfälle sind:
- Suchmaschinen (Googlebot, Bingbot, Yandex Bot …) sammeln den gesamten HTML-Code für einen erheblichen Teil des Webs. Diese Daten werden indiziert, um sie durchsuchbar zu machen.
- SEO-Analysetools sammeln neben dem Sammeln des HTML-Codes auch Metadaten wie die Antwortzeit, den Antwortstatus, um defekte Seiten zu erkennen, und die Links zwischen verschiedenen Domains, um Backlinks zu sammeln.
- Preisüberwachungstools crawlen E-Commerce-Websites, um Produktseiten zu finden und Metadaten zu extrahieren, insbesondere den Preis. Produktseiten werden dann regelmäßig überarbeitet.
- Common Crawl verwaltet ein offenes Repository von Webcrawl-Daten. So enthält das Archiv ab Oktober 2020 2,71 Milliarden Webseiten.
Als nächstes werden wir drei verschiedene Strategien zum Erstellen eines Webcrawlers in Python vergleichen. Verwenden Sie zunächst nur Standardbibliotheken, dann Bibliotheken von Drittanbietern zum Erstellen von HTTP-Anforderungen und zum Analysieren von HTML und schließlich ein Webcrawling-Framework.
Erstellen eines einfachen Webcrawlers in Python von Grund auf neu
Um einen einfachen Webcrawler in Python zu erstellen, benötigen wir mindestens eine Bibliothek zum Herunterladen des HTML-Codes von einer URL und eine HTML-Parsing-Bibliothek zum Extrahieren von Links. Python bietet Standardbibliotheken urllib für HTTP-Anfragen und HTML.parser zum Parsen von HTML. Ein Beispiel für einen Python-Crawler, der nur mit Standardbibliotheken erstellt wurde, finden Sie auf Github.
Die Standard-Python-Bibliotheken für Anfragen und HTML-Parsing sind nicht sehr entwicklerfreundlich. Andere beliebte Bibliotheken wie Requests, die als HTTP für Menschen gebrandmarkt sind, und Beautiful Soup bieten ein besseres Entwicklererlebnis.
Wenn Sie mehr erfahren möchten, können Sie dieses Handbuch über den besten Python-HTTP-Client lesen.
Sie können die beiden Bibliotheken lokal installieren.
pip install requests bs4Ein grundlegender Crawler kann nach dem vorherigen Architekturdiagramm erstellt werden.
import loggingfrom urllib.parse import urljoinimport requestsfrom bs4 import BeautifulSouplogging.basicConfig( format='%(asctime)s %(levelname)s:%(message)s', level=logging.INFO)class Crawler: def __init__(self, urls=): self.visited_urls = self.urls_to_visit = urls def download_url(self, url): return requests.get(url).text def get_linked_urls(self, url, html): soup = BeautifulSoup(html, 'html.parser') for link in soup.find_all('a'): path = link.get('href') if path and path.startswith('/'): path = urljoin(url, path) yield path def add_url_to_visit(self, url): if url not in self.visited_urls and url not in self.urls_to_visit: self.urls_to_visit.append(url) def crawl(self, url): html = self.download_url(url) for url in self.get_linked_urls(url, html): self.add_url_to_visit(url) def run(self): while self.urls_to_visit: url = self.urls_to_visit.pop(0) logging.info(f'Crawling: {url}') try: self.crawl(url) except Exception: logging.exception(f'Failed to crawl: {url}') finally: self.visited_urls.append(url)if __name__ == '__main__': Crawler(urls=).run()Der obige Code definiert eine Crawler-Klasse mit Hilfsmethoden für download_url mithilfe der Anforderungsbibliothek, get_linked_urls mithilfe der Beautiful Soup-Bibliothek und add_url_to_visit zum Filtern von URLs. Die zu besuchenden URLs und die besuchten URLs werden in zwei separaten Listen gespeichert. Sie können den Crawler auf Ihrem Terminal ausführen.
python crawler.pyDer Crawler protokolliert eine Zeile für jede besuchte URL.
2020-12-04 18:10:10,737 INFO:Crawling: https://www.imdb.com/2020-12-04 18:10:11,599 INFO:Crawling: https://www.imdb.com/?ref_=nv_home2020-12-04 18:10:12,868 INFO:Crawling: https://www.imdb.com/calendar/?ref_=nv_mv_cal2020-12-04 18:10:13,526 INFO:Crawling: https://www.imdb.com/list/ls016522954/?ref_=nv_tvv_dvd2020-12-04 18:10:19,174 INFO:Crawling: https://www.imdb.com/chart/top/?ref_=nv_mv_2502020-12-04 18:10:20,624 INFO:Crawling: https://www.imdb.com/chart/moviemeter/?ref_=nv_mv_mpm2020-12-04 18:10:21,556 INFO:Crawling: https://www.imdb.com/feature/genre/?ref_=nv_ch_grDer Code ist sehr einfach, aber es gibt viele Performance- und Usability-Probleme zu lösen, bevor eine komplette Website erfolgreich gecrawlt wird.
- Der Crawler ist langsam und unterstützt keine Parallelität. Wie aus den Zeitstempeln hervorgeht, dauert das Crawlen jeder URL etwa eine Sekunde. Jedes Mal, wenn der Crawler eine Anfrage stellt, wartet er darauf, dass die Anfrage gelöst wird, und dazwischen wird keine Arbeit geleistet.
- Die Download-URL-Logik hat keinen Wiederholungsmechanismus, die URL-Warteschlange ist keine echte Warteschlange und bei einer hohen Anzahl von URLs nicht sehr effizient.
- Die Linkextraktionslogik unterstützt keine Standardisierung von URLs durch Entfernen von URL-Abfragezeichenfolgenparametern, behandelt keine URLs, die mit # beginnen, unterstützt keine Filterung von URLs nach Domäne oder das Herausfiltern von Anforderungen an statische Dateien.
- Der Crawler identifiziert sich nicht und ignoriert die Roboter.txt-Datei.
Als nächstes werden wir sehen, wie Scrapy all diese Funktionen bietet und die Erweiterung für Ihre benutzerdefinierten Crawls vereinfacht.
Web Crawling mit Scrapy
Scrapy ist das beliebteste Web Scraping und Crawling Python Framework mit 40k Sternen auf Github. Einer der Vorteile von Scrapy besteht darin, dass Anforderungen asynchron geplant und verarbeitet werden. Dies bedeutet, dass Scrapy eine weitere Anfrage senden kann, bevor die vorherige abgeschlossen ist, oder dazwischen andere Arbeiten ausführen kann. Scrapy kann viele gleichzeitige Anforderungen verarbeiten, kann aber auch so konfiguriert werden, dass die Websites mit benutzerdefinierten Einstellungen respektiert werden, wie wir später sehen werden.
Scrapy hat eine Mehrkomponentenarchitektur. Normalerweise implementieren Sie mindestens zwei verschiedene Klassen: Spider und Pipeline. Web Scraping kann als ETL betrachtet werden, bei der Sie Daten aus dem Web extrahieren und in Ihren eigenen Speicher laden. Spinnen extrahieren die Daten und Pipelines laden sie in den Speicher. Ich empfehle jedoch, eine benutzerdefinierte Scrapy-Pipeline festzulegen, um jedes Element unabhängig voneinander zu transformieren. Auf diese Weise hat die Nichtverarbeitung eines Elements keine Auswirkungen auf andere Elemente.
Darüber hinaus können Sie Spider- und Downloader-Middlewares zwischen den Komponenten hinzufügen, wie im folgenden Diagramm zu sehen ist.
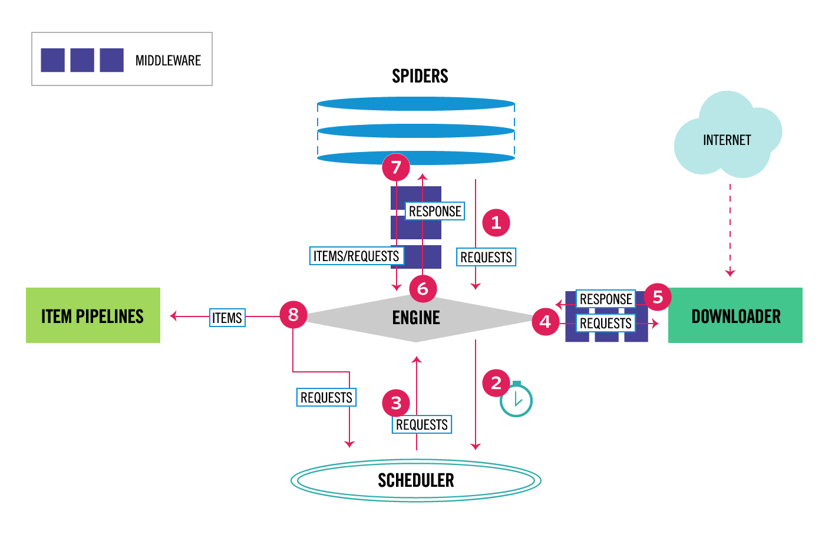
Scrapy-Architekturübersicht
Wenn Sie Scrapy bereits verwendet haben, wissen Sie, dass ein Web Scraper als eine Klasse definiert ist, die von der Basis-Spider-Klasse erbt und eine Parse-Methode implementiert, um jede Antwort zu verarbeiten. Wenn Sie neu in Scrapy sind, können Sie diesen Artikel zum einfachen Kratzen mit Scrapy lesen.
from scrapy.spiders import Spiderclass ImdbSpider(Spider): name = 'imdb' allowed_domains = start_urls = def parse(self, response): passScrapy bietet auch mehrere generische Spider-Klassen: CrawlSpider, XMLFeedSpider, CSVFeedSpider und SitemapSpider. Die CrawlSpider-Klasse erbt von der Basis-Spider-Klasse und bietet ein zusätzliches Regelattribut, um zu definieren, wie eine Website gecrawlt wird. Jede Regel verwendet einen LinkExtractor, um anzugeben, welche Links von jeder Seite extrahiert werden. Als nächstes werden wir sehen, wie Sie jeden von ihnen verwenden, indem Sie einen Crawler für IMDb, die Internet Movie Database, erstellen.
Erstellen eines Beispiel-Scrapy-Crawlers für IMDb
Bevor ich versuchte, IMDb zu crawlen, habe ich IMDb robots überprüft.txt-Datei, um zu sehen, welche URL-Pfade zulässig sind. Die Robots-Datei verbietet nur 26 Pfade für alle Benutzeragenten. Scrapy liest die Roboter.txt-Datei und respektiert sie, wenn die ROBOTSTXT_OBEY-Einstellung auf true gesetzt ist. Dies gilt für alle Projekte, die mit dem Scrapy-Befehl startproject generiert werden.
scrapy startproject scrapy_crawlerDieser Befehl erstellt ein neues Projekt mit der standardmäßigen Scrapy-Projektordnerstruktur.
scrapy_crawler/├── scrapy.cfg└── scrapy_crawler ├── __init__.py ├── items.py ├── middlewares.py ├── pipelines.py ├── settings.py └── spiders ├── __init__.pyDann können Sie eine Spinne in erstellen scrapy_crawler/spiders/imdb.py mit einer Regel, um alle Links zu extrahieren.
from scrapy.spiders import CrawlSpider, Rulefrom scrapy.linkextractors import LinkExtractorclass ImdbCrawler(CrawlSpider): name = 'imdb' allowed_domains = start_urls = rules = (Rule(LinkExtractor()),)Sie können den Crawler im Terminal starten.
scrapy crawl imdb --logfile imdb.logSie erhalten viele Protokolle, einschließlich eines Protokolls für jede Anfrage. Beim Durchsuchen der Protokolle stellte ich fest, dass selbst wenn wir allowed_domains so einstellen, dass nur Webseiten unter https://www.imdb.com gecrawlt werden, Anforderungen an externe Domänen gestellt wurden, z amazon.com.
2020-12-06 12:25:18 DEBUG: Redirecting (302) to <GET https://www.amazon.com/b/?&node=5160028011&ref_=ft_iba> from <GET (https://www.imdb.com/whitelist-offsite?url=https%3A%2F%2Fwww.amazon.com%2Fb%2F%3F%26node%3D5160028011%26ref_%3Dft_iba&page-action=ft-iba&ref=ft_iba)>IMDb leitet von URLs-Pfaden unter Whitelist-Offsite und Whitelist zu externen Domains um. Es gibt ein offenes Scrapy Github-Problem, das zeigt, dass externe URLs nicht herausgefiltert werden, wenn die OffsiteMiddleware vor der RedirectMiddleware angewendet wird. Um dieses Problem zu beheben, können wir den Link Extractor so konfigurieren, dass URLs, die mit zwei regulären Ausdrücken beginnen, abgelehnt werden.
class ImdbCrawler(CrawlSpider): name = 'imdb' allowed_domains = start_urls = rules = ( Rule(LinkExtractor( deny=, )), )Rule- und LinkExtractor-Klassen unterstützen mehrere Argumente zum Herausfiltern von URLs. Sie können beispielsweise bestimmte URL-Erweiterungen ignorieren und die Anzahl der doppelten URLs reduzieren, indem Sie Abfragezeichenfolgen sortieren. Wenn Sie kein bestimmtes Argument für Ihren Anwendungsfall finden, können Sie eine benutzerdefinierte Funktion an process_links in LinkExtractor oder process_values in Rule .
IMDb hat beispielsweise zwei verschiedene URLs mit demselben Inhalt.
https://www.imdb.com/ name/nm1156914/
https://www.imdb.com/ name/nm1156914/?mode=desktop&ref_=m_ft_dsk
Um die Anzahl der gecrawlten URLs zu begrenzen, können wir alle Abfragezeichenfolgen aus URLs mit der Funktion url_query_cleaner aus der w3lib-Bibliothek entfernen und in process_links .
from w3lib.url import url_query_cleanerdef process_links(links): for link in links: link.url = url_query_cleaner(link.url) yield linkclass ImdbCrawler(CrawlSpider): name = 'imdb' allowed_domains = start_urls = rules = ( Rule(LinkExtractor( deny=, ), process_links=process_links), )Nachdem wir die Anzahl der zu verarbeitenden Anforderungen begrenzt haben, können wir eine parse_item-Methode hinzufügen, um Daten von jeder Seite zu extrahieren und an eine Pipeline zum Speichern zu übergeben. Zum Beispiel können wir entweder die gesamte Antwort extrahieren.text, um ihn in einer anderen Pipeline zu verarbeiten, oder wählen Sie die HTML-Metadaten aus. Um die HTML-Metadaten im Header-Tag auszuwählen, können wir unsere eigenen XPaths codieren, aber ich finde es besser, eine Bibliothek, extruct , zu verwenden, die alle Metadaten von einer HTML-Seite extrahiert. Sie können es mit pip install extract installieren.
import refrom scrapy.linkextractors import LinkExtractorfrom scrapy.spiders import CrawlSpider, Rulefrom w3lib.url import url_query_cleanerimport extructdef process_links(links): for link in links: link.url = url_query_cleaner(link.url) yield linkclass ImdbCrawler(CrawlSpider): name = 'imdb' allowed_domains = start_urls = rules = ( Rule( LinkExtractor( deny=, ), process_links=process_links, callback='parse_item', follow=True ), ) def parse_item(self, response): return { 'url': response.url, 'metadata': extruct.extract( response.text, response.url, syntaxes= ), }Ich habe das follow-Attribut auf True gesetzt, damit Scrapy weiterhin allen Links aus jeder Antwort folgt, auch wenn wir eine benutzerdefinierte Analysemethode bereitgestellt haben. Ich habe extruct auch so konfiguriert, dass nur Open Graph-Metadaten und JSON-LD extrahiert werden, eine beliebte Methode zum Codieren verknüpfter Daten mit JSON im Web, die von IMDb verwendet wird. Sie können den Crawler ausführen und Elemente im JSON-Zeilenformat in einer Datei speichern.
scrapy crawl imdb --logfile imdb.log -o imdb.jl -t jsonlinesDie Ausgabedatei imdb.jl enthält eine Zeile für jedes gecrawlte Element. Beispielsweise sehen die extrahierten Open Graph-Metadaten für einen Film aus den <meta> -Tags im HTML-Code folgendermaßen aus.
{ "url": "http://www.imdb.com/title/tt2442560/", "metadata": {"opengraph": , , , , , ] }]}}Das JSON-LD für ein einzelnes Element ist zu lang, um in den Artikel aufgenommen zu werden, hier ist ein Beispiel dafür, was Scrapy aus dem <script type=“application/ld+json“> Tag extrahiert.
"json-ld": , "contentRating": "TV-MA", "actor": ... }]Beim Durchsuchen der Protokolle bemerkte ich ein weiteres häufiges Problem mit Crawlern. Durch sequentielles Klicken auf Filter generiert der Crawler URLs mit demselben Inhalt, nur dass die Filter in einer anderen Reihenfolge angewendet wurden.
https://www.imdb.com/ name/nm2900465/videogalerie/content_type-Anhänger/related_titles-tt0479468
https://www.imdb.com/ name/nm2900465/videogallery/related_titles-tt0479468/content_type-trailer
Lange Filter- und Such-URLs sind ein schwieriges Problem, das teilweise gelöst werden kann, indem die Länge von URLs mit einer Scrapy-Einstellung, URLLENGTH_LIMIT, begrenzt wird.
Ich habe IMDb als Beispiel verwendet, um die Grundlagen zum Erstellen eines Webcrawlers in Python zu zeigen. Ich habe den Crawler nicht lange laufen lassen, da ich keinen bestimmten Anwendungsfall für die Daten hatte. Falls Sie bestimmte Daten aus IMDb benötigen, können Sie das IMDb Datasets-Projekt überprüfen, das einen täglichen Export von IMDb-Daten und IMDbPY , ein Python-Paket zum Abrufen und Verwalten der Daten, bereitstellt.
Webcrawling im Maßstab
Wenn Sie versuchen, eine große Website wie IMDb mit über 45 Millionen Seiten basierend auf Google zu crawlen, ist es wichtig, verantwortungsbewusst zu crawlen, indem Sie die folgenden Einstellungen konfigurieren. Sie können Ihren Crawler identifizieren und Kontaktdaten in der Einstellung BOT_NAME angeben. Um den Druck auf die Website-Server zu begrenzen, können Sie die DOWNLOAD_DELAY erhöhen, die CONCURRENT_REQUESTS_PER_DOMAIN begrenzen oder AUTOTHROTTLE_ENABLED festlegen, um diese Einstellungen dynamisch an die Antwortzeiten des Servers anzupassen.
Beachten Sie, dass Scrapy-Crawls standardmäßig für eine einzelne Domain optimiert sind. Wenn Sie mehrere Domänen crawlen, überprüfen Sie diese Einstellungen, um für umfassende Crawls zu optimieren, einschließlich der Änderung der Standard-Crawling-Reihenfolge von depth-first in breath-first. Um Ihr Crawling-Budget zu begrenzen, können Sie die Anzahl der Anforderungen mit der Einstellung CLOSESPIDER_PAGECOUNT der close Spider-Erweiterung begrenzen.
Mit den Standardeinstellungen crawlt Scrapy etwa 600 Seiten pro Minute für eine Website wie IMDb. Das Crawlen von 45 Millionen Seiten dauert für einen einzelnen Roboter mehr als 50 Tage. Wenn Sie mehrere Websites crawlen müssen, kann es besser sein, separate Crawler für jede große Website oder Gruppe von Websites zu starten. Wenn Sie an verteilten Webcrawls interessiert sind, können Sie lesen, wie ein Entwickler 250 Millionen Seiten mit Python in 40 Stunden mit 20 Amazon EC2-Maschineninstanzen gecrawlt hat.
In einigen Fällen können Sie auf Websites stoßen, auf denen Sie JavaScript-Code ausführen müssen, um den gesamten HTML-Code zu rendern. Wenn Sie dies nicht tun, sammeln Sie möglicherweise nicht alle Links auf der Website. Da es heutzutage sehr üblich ist, dass Websites Inhalte dynamisch im Browser rendern, habe ich eine Scrapy-Middleware zum Rendern von JavaScript-Seiten mit der API von ScrapingBee geschrieben.
Fazit
Wir haben den Code eines Python-Crawlers, der Bibliotheken von Drittanbietern zum Herunterladen von URLs und zum Parsen von HTML verwendet, mit einem Crawler verglichen, der mit einem beliebten Webcrawling-Framework erstellt wurde. Scrapy ist ein sehr leistungsfähiges Web-Crawling-Framework und kann einfach mit Ihrem benutzerdefinierten Code erweitert werden. Sie müssen jedoch alle Stellen kennen, an denen Sie Ihren eigenen Code und die Einstellungen für jede Komponente einbinden können.
Die korrekte Konfiguration von Scrapy wird beim Crawlen von Websites mit Millionen von Seiten noch wichtiger. Wenn Sie mehr über Webcrawling erfahren möchten, schlage ich vor, dass Sie eine beliebte Website auswählen und versuchen, sie zu crawlen. Sie werden auf jeden Fall auf neue Themen stoßen, was das Thema faszinierend macht!