Log4j Tutorial: So konfigurieren Sie den Logger für eine effiziente Protokollierung von Java-Anwendungen
Wenn Sie Ihren Code in der Produktion ausführen, ist es wichtig, Einblick in Ihre Anwendung zu erhalten. Was verstehen wir unter Sichtbarkeit? In erster Linie Dinge wie Anwendungsleistung über Metriken, Anwendungszustand und Verfügbarkeit, seine Protokolle, falls Sie Fehler beheben müssen, oder seine Spuren, wenn Sie herausfinden müssen, was es langsam macht und wie es schneller gemacht werden kann.
Metriken geben Ihnen Informationen über die Leistung der einzelnen Elemente Ihrer Infrastruktur. Traces zeigen Ihnen eine umfassendere Ansicht der Codeausführung und des Codeflusses zusammen mit Codeausführungsmetriken. Schließlich bieten gut gestaltete Protokolle einen unschätzbaren Einblick in die Ausführung der Codelogik und die Vorgänge in Ihrem Code. Jedes der genannten Teile ist entscheidend für Ihre Anwendung und in der Tat für die Beobachtbarkeit des Gesamtsystems. Heute konzentrieren wir uns nur auf ein einziges Stück – die Protokolle. Um genauer zu sein – in Java-Anwendungsprotokollen. Wenn Sie an Metriken interessiert sind, lesen Sie unseren Artikel über wichtige JVM-Metriken, die Sie überwachen sollten.
Bevor wir jedoch darauf eingehen, wollen wir uns mit einem Problem befassen, das die Community mit diesem Framework beeinflusst hat. Am 9. Dezember 2021 wurde eine kritische Sicherheitsanfälligkeit mit dem Spitznamen Log4Shell gemeldet. Es wurde als CVE-2021-44228 identifiziert und ermöglicht es einem Angreifer, die vollständige Kontrolle über einen Computer zu übernehmen, auf dem Apache Log4j 2 Version 2.14.1 oder niedriger ausgeführt wird, sodass er beliebigen Code auf dem anfälligen Server ausführen kann. In unserem letzten Blogbeitrag über die Log4jShell-Sicherheitsanfälligkeit haben wir detailliert beschrieben, wie Sie feststellen können, ob Sie betroffen sind, wie Sie das Problem beheben können und was wir bei Sematext getan haben, um unser System und unsere Benutzer zu schützen.
Log4j 1.x Ende der Lebensdauer
Beachten Sie, dass das Logging Services Project Management Committee am 5. August 2015 bekannt gab, dass der Log4j 1.x hatte sein Lebensende erreicht. Allen Benutzern wird empfohlen, auf Log4j 2 zu migrieren.x. In diesem Blogbeitrag helfen wir Ihnen, Ihr aktuelles Log4j–Setup zu verstehen – insbesondere das log4j 2.x-Version – und danach helfe ich Ihnen bei der Migration auf die neueste und beste Log4j-Version.
„Ich verwende Log4j 1.x, was soll ich tun?“. Keine Panik, daran ist nichts auszusetzen. Machen Sie einen Plan für den Übergang zu Log4j 2.x. Ich zeige Ihnen, wie Sie einfach weiter lesen :). Ihre Bewerbung wird es Ihnen danken. Sie erhalten die Sicherheitsupdates, Leistungsverbesserungen und weitaus mehr Funktionen nach der Migration.
„Ich starte ein neues Projekt, was soll ich tun?“. Verwenden Sie einfach das Log4j 2.x Denken Sie sofort nicht einmal an Log4j 1.x. Wenn Sie dabei Hilfe benötigen, lesen Sie dieses Java-Logging-Tutorial, in dem ich alles erkläre, was Sie brauchen.
Anmeldung in Java
Hinter der Anmeldung in Java steckt keine Magie. Es kommt darauf an, eine geeignete Java-Klasse und ihre Methoden zum Generieren von Protokollereignissen zu verwenden. Wie wir im Java Logging Guide besprochen haben, gibt es mehrere Möglichkeiten, wie Sie
Natürlich ist der naivste und nicht der beste Weg, nur das System zu verwenden.aus und System.err Klassen. Ja, Sie können das tun und Ihre Nachrichten werden nur zur Standardausgabe und zum Standardfehler weitergeleitet. Normalerweise bedeutet dies, dass es auf der Konsole gedruckt oder in eine Datei geschrieben oder sogar an / dev / null gesendet wird und für immer vergessen wird. Ein Beispiel für einen solchen Code könnte folgendermaßen aussehen:
public class SystemExample { public static void main(String args) { System.out.println("Starting my awesome application"); // some work to be done System.out.println( String.format("My application %s started successfully", SystemExample.class) ); }}
Die Ausgabe der obigen Codeausführung wäre wie folgt:
Starting my awesome applicationMy application class com.sematext.logging.log4jsystem.SystemExample started successfully
Das ist nicht perfekt, oder? Ich habe keine Informationen darüber, welche Klasse die Nachricht generiert hat, und viele, viele weitere „kleine“ Dinge, die beim Debuggen entscheidend und wichtig sind.
Es fehlen andere Dinge, die nicht wirklich mit dem Debuggen zusammenhängen. Denken Sie an die Ausführungsumgebung, mehrere Anwendungen oder Microservices und die Notwendigkeit, die Protokollierung zu vereinheitlichen, um die Konfiguration der Protokollzentralisierungspipeline zu vereinfachen. Verwenden des Systems.out, oder/und System.ein Fehler in unserem Code für Protokollierungszwecke würde uns zwingen, alle Stellen, an denen wir ihn verwenden, zu wiederholen, wenn wir das Protokollierungsformat anpassen müssen. Ich weiß, es ist extrem, aber glauben Sie mir, wir haben den Einsatz von System gesehen.out im Produktionscode in „traditionellen“ Anwendungsbereitstellungsmodellen! Natürlich Protokollierung im System.out ist eine geeignete Lösung für containerisierte Anwendungen, und Sie sollten die Ausgabe verwenden, die zu Ihrer Umgebung passt. Denken Sie daran!
Aufgrund all der genannten Gründe und vieler weiterer, an die wir nicht einmal denken, sollten Sie sich eine der möglichen Protokollierungsbibliotheken wie Log4j, Log4j 2, Logback oder sogar Java ansehen.util.protokollierung, die Teil des Java Development Kits ist. Für diesen Blogbeitrag werden wir Log4j verwenden.
Die Abstraktionsschicht – SLF4J
Das Thema der Auswahl der richtigen Protokollierungslösung für Ihre Java-Anwendung haben wir bereits in unserem Tutorial zur Protokollierung in Java behandelt. Wir empfehlen dringend, zumindest den genannten Abschnitt zu lesen.
Wir werden SLF4J verwenden, eine Abstraktionsschicht zwischen unserem Java–Code und Log4j – der Logging-Bibliothek unserer Wahl. Die einfache Logging-Fassade bietet Bindungen für gängige Logging-Frameworks wie Log4j, Logback und Java.util.Logging. Stellen Sie sich den Prozess des Schreibens einer Protokollnachricht auf folgende vereinfachte Weise vor:
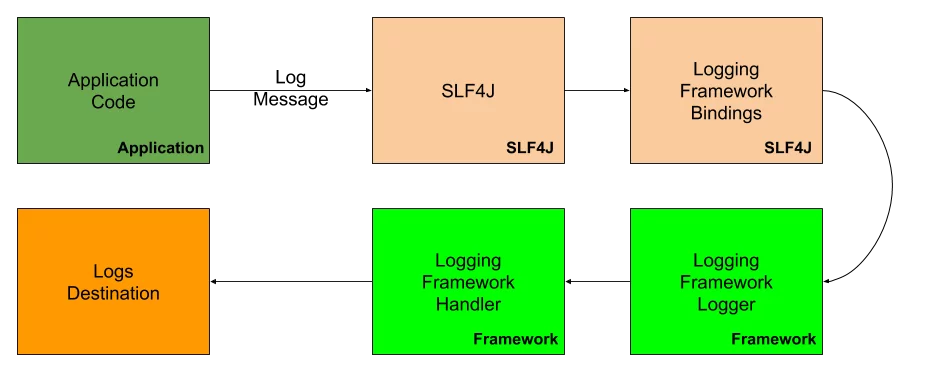
Sie fragen sich vielleicht, warum überhaupt eine Abstraktionsschicht verwendet wird? Nun, die Antwort ist ganz einfach: Möglicherweise möchten Sie das Protokollierungsframework ändern, aktualisieren und mit dem Rest Ihres Technologie-Stacks vereinheitlichen. Wenn Sie eine Abstraktionsschicht verwenden, ist eine solche Operation ziemlich einfach – Sie tauschen einfach die Abhängigkeiten des Protokollierungsframeworks aus und stellen ein neues Paket bereit. Wenn wir keine Abstraktionsschicht verwenden würden, müssten wir den Code ändern, möglicherweise viel Code. Jede Klasse, die etwas protokolliert. Keine sehr schöne Entwicklungserfahrung.
Der Logger
Der Code Ihrer Java-Anwendung interagiert mit einem Standardsatz von Schlüsselelementen, die die Erstellung und Bearbeitung von Protokollereignissen ermöglichen. Wir haben die entscheidenden in unserem Java-Logging-Tutorial behandelt, aber ich möchte Sie an eine der Klassen erinnern, die wir ständig verwenden werden – den Logger.
Der Logger ist die Hauptentität, mit der eine Anwendung Protokollierungsaufrufe ausführt – Erstellen von Protokollereignissen. Das Logger-Objekt wird normalerweise für eine einzelne Klasse oder eine einzelne Komponente verwendet, um kontextgebunden an einen bestimmten Anwendungsfall bereitzustellen. Es bietet Methoden, um Protokollereignisse mit einer geeigneten Protokollebene zu erstellen und zur weiteren Verarbeitung weiterzugeben. Normalerweise erstellen Sie ein statisches Objekt, mit dem Sie interagieren, z. B. wie folgt:
... Logger LOGGER = LoggerFactory.getLogger(MyAwesomeClass.class);
Und das ist alles. Nun, da wir wissen, was wir erwarten können, schauen wir uns die Log4j-Bibliothek an.
Log4j
Der einfachste Weg, mit Log4j zu beginnen, besteht darin, die Bibliothek in den Klassenpfad Ihrer Java-Anwendung aufzunehmen. Dazu haben wir die neueste verfügbare log4j-Bibliothek, also Version 1.2.17, in unsere Build-Datei aufgenommen.
Wir verwenden Gradle und in unserer einfachen Anwendung sieht der Abschnitt Abhängigkeiten für die Gradle-Build-Datei wie folgt aus:
dependencies { implementation 'log4j:log4j:1.2.17'}
Wir können mit der Entwicklung des Codes beginnen und die Protokollierung mit Log4j einbeziehen:
package com.sematext.blog;import org.apache.log4j.Logger;public class ExampleLog4j { private static final Logger LOGGER = Logger.getLogger(ExampleLog4j.class); public static void main(String args) { LOGGER.info("Initializing ExampleLog4j application"); }}
Wie Sie im obigen Code sehen können, haben wir das Logger-Objekt mithilfe der statischen getLogger-Methode initialisiert und den Namen der Klasse angegeben. Danach können wir leicht auf das statische Logger-Objekt zugreifen und es verwenden, um Protokollereignisse zu erzeugen. Wir können das in der Hauptmethode tun.
Eine Randnotiz – die getLogger Methode kann auch mit einem String als Argument aufgerufen werden, zum Beispiel:
private static final Logger LOGGER = Logger.getLogger("com.sematext.blog");
Dies würde bedeuten, dass wir einen Logger erstellen und den Namen com zuordnen möchten.semantik.bloggen Sie damit. Wenn wir denselben Namen an einer anderen Stelle im Code verwenden, gibt Log4j dieselbe Logger-Instanz zurück. Dies ist nützlich, wenn wir die Protokollierung aus mehreren verschiedenen Klassen an einem einzigen Ort kombinieren möchten. Zum Beispiel Protokolle im Zusammenhang mit Zahlungen in einer einzigen, dedizierten Protokolldatei.
Log4j bietet eine Liste von Methoden, die die Erstellung neuer Protokollereignisse mit einer geeigneten Protokollebene ermöglichen. Das sind:
- public void trace(Objektnachricht)
- public void debug(Objektnachricht)
- public void info(Objektnachricht)
- public void warn(Objektnachricht)
- public void error(Objektnachricht)
- public void fatal (Objektnachricht)
Und eine generische Methode:
- public void log(Ebene Ebene, Objektnachricht)
Wir haben in unserem Blogbeitrag zum Java-Logging-Tutorial über Java-Logging-Levels gesprochen. Wenn Sie sie nicht kennen, nehmen Sie sich bitte ein paar Minuten Zeit, um sich daran zu gewöhnen, da die Protokollebenen für die Protokollierung entscheidend sind. Wenn Sie jedoch gerade erst mit den Protokollierungsstufen beginnen, empfehlen wir Ihnen, auch unseren Leitfaden zu den Protokollstufen durchzugehen. Wir erklären Ihnen alles, von dem, was sie sind, bis hin zur Auswahl der richtigen und wie Sie sie nutzen können, um aussagekräftige Einblicke zu erhalten.
Wenn wir den obigen Code ausführen würden, wäre die Ausgabe, die wir auf der Standardkonsole erhalten würden, wie folgt:
log4j:WARN No appenders could be found for logger (com.sematext.blog.ExampleLog4j).log4j:WARN Please initialize the log4j system properly.log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
Wir haben nicht die erwartete Protokollmeldung angezeigt. Log4j hat uns mitgeteilt, dass keine Konfiguration vorhanden ist. Oooops, lass uns darüber reden, wie man Log4j konfiguriert…
Log4j-Konfiguration
Es gibt mehrere Möglichkeiten, wie wir unsere Log4j-Protokollierung konfigurieren können. Wir können dies programmgesteuert tun – zum Beispiel durch Einfügen eines statischen Initialisierungsblocks:
static { BasicConfigurator.configure();}
Der obige Code konfiguriert Log4j so, dass die Protokolle im Standardformat an die Konsole ausgegeben werden. Die Ausgabe der Ausführung unserer Beispielanwendung würde wie folgt aussehen:
0 INFO com.sematext.blog.ExampleLog4jProgrammaticConfig - Initializing ExampleLog4j application
Das programmgesteuerte Einrichten von Log4j ist jedoch nicht sehr häufig. Am gebräuchlichsten wäre es, entweder eine Eigenschaftendatei oder eine XML-Datei zu verwenden. Wir können unseren Code ändern und die Datei log4j.properties mit folgendem Inhalt einfügen:
log4j.rootLogger=DEBUG, MAINlog4j.appender.MAIN=org.apache.log4j.ConsoleAppenderlog4j.appender.MAIN.layout=org.apache.log4j.PatternLayoutlog4j.appender.MAIN.layout.ConversionPattern=%r %-5p %c %x - %m%n
Auf diese Weise haben wir Log4j mitgeteilt, dass wir den Root-Logger erstellen, der standardmäßig verwendet wird. Die Standardprotokollierungsstufe ist auf DEBUG festgelegt, was bedeutet, dass Protokollereignisse mit dem Schweregrad DEBUG oder höher einbezogen werden. Also DEBUG, INFO, WARN, ERROR und FATAL. Wir haben unserem Logger auch einen Namen gegeben – MAIN. Als nächstes konfigurieren wir den Logger, indem wir seine Ausgabe auf Konsole setzen und das Musterlayout verwenden. Wir werden später im Blogbeitrag mehr darüber sprechen. Die Ausgabe des obigen Codes wäre wie folgt:
0 INFO com.sematext.blog.ExampleLog4jProperties - Initializing ExampleLog4j application
Wenn wir möchten, können wir auch die Datei log4j.properties ändern und eine mit dem Namen verwenden log4j.xml. Die gleiche Konfiguration im XML-Format würde wie folgt aussehen:
<!DOCTYPE log4j:configuration SYSTEM "log4j.dtd"><log4j:configuration> <appender name="MAIN" class="org.apache.log4j.ConsoleAppender"> <param name="Target" value="System.out"/> <layout class="org.apache.log4j.PatternLayout"> <param name="ConversionPattern" value="%r %-5p %c %x - %m%n" /> </layout> </appender> <root> <priority value ="debug"></priority> <appender-ref ref="MAIN" /> </root></log4j:configuration>
Wenn wir jetzt die log4j.properties für log4j.xml eins und behalte es im Klassenpfad Die Ausführung unserer Beispielanwendung wäre wie folgt:
0 INFO com.sematext.blog.ExampleLog4jXML - Initializing ExampleLog4j application
Woher weiß Log4j, welche Datei verwendet werden soll? Schauen wir uns das an.
Initialisierungsprozess
Es ist wichtig zu wissen, dass Log4j keine Annahmen bezüglich der Umgebung macht, in der es ausgeführt wird. Log4j geht nicht von standardmäßigen Protokollereigniszielen aus. Beim Start wird nach der Eigenschaft log4j.configuration gesucht und versucht, die angegebene Datei als Konfiguration zu laden. Wenn der Speicherort der Datei nicht in eine URL konvertiert werden kann oder die Datei nicht vorhanden ist, wird versucht, die Datei aus dem Klassenpfad zu laden.
Das bedeutet, dass wir die Log4j-Konfiguration aus dem Klassenpfad überschreiben können, indem wir beim Start die -Dlog4j.configuration angeben und auf den richtigen Speicherort verweisen. Zum Beispiel, wenn wir eine Datei namens other .xml mit folgendem Inhalt:
<!DOCTYPE log4j:configuration SYSTEM "log4j.dtd"><log4j:configuration> <appender name="MAIN" class="org.apache.log4j.ConsoleAppender"> <param name="Target" value="System.out"/> <layout class="org.apache.log4j.PatternLayout"> <param name="ConversionPattern" value="%r %-5p %c %x - %m%n" /> </layout> </appender> <root> <priority value ="debug"></priority> <appender-ref ref="MAIN" /> </root></log4j:configuration>
Und dann Code mit -Dlog4j.configuration=/opt/sematext/other ausführen.xml Die Ausgabe unseres Codes lautet wie folgt:
0 INFO com.sematext.blog.ExampleLog4jXML - Initializing ExampleLog4j application
Log4j Appenders
Wir haben bereits Appender in unseren Beispielen verwendet … nun, wirklich nur einen – den ConsoleAppender. Sein einziger Zweck ist es, die Protokollereignisse in die Konsole zu schreiben. Bei einer großen Anzahl von Protokollereignissen und Systemen, die in verschiedenen Umgebungen ausgeführt werden, ist es natürlich nicht die beste Idee, reine Textdaten in die Standardausgabe zu schreiben, es sei denn, Sie werden in Containern ausgeführt. Aus diesem Grund unterstützt Log4j mehrere Arten von Appendern. Hier sind einige gängige Beispiele für Log4j-Appender:
- ConsoleAppender – der Appender, der die Protokollereignisse an das System anhängt.aus oder System.err mit dem Standardsystem.aus. Wenn Sie diesen Appender verwenden, werden Ihre Protokolle in der Konsole Ihrer Anwendung angezeigt.
- FileAppender – Der Appender, der die Protokollereignisse an eine definierte Datei anhängt, die sie im Dateisystem speichert.
- RollingFileAppender – Der Appender, der den FileAppender erweitert und die Datei dreht, wenn sie eine definierte Größe erreicht. Die Verwendung von RollingFileAppender verhindert, dass die Protokolldateien sehr groß und schwer zu pflegen werden.
- SyslogAppender – der Appender, der die Protokollereignisse an einen entfernten Syslog-Daemon sendet.
- JDBCAppender – der Appender, der die Protokollereignisse in der Datenbank speichert. Beachten Sie, dass dieser Appender keine Fehler speichert und es im Allgemeinen nicht die beste Idee ist, die Protokollereignisse in einer Datenbank zu speichern.
- SocketAppender – Der Appender, der die serialisierten Protokollereignisse an einen Remote-Socket sendet. Beachten Sie, dass dieser Appender keine Layouts verwendet, da er die serialisierten unformatierten Protokollereignisse sendet.
- NullAppender – der Appender, der nur die Protokollereignisse verwirft.
Darüber hinaus können Sie mehrere Appender für eine einzelne Anwendung konfigurieren. Sie können beispielsweise Protokolle an die Konsole und an eine Datei senden. Das folgende log4j.eigenschaften Dateiinhalt würde genau das tun:
log4j.rootLogger=DEBUG, MAIN, ROLLINGlog4j.appender.MAIN=org.apache.log4j.ConsoleAppenderlog4j.appender.MAIN.layout=org.apache.log4j.PatternLayoutlog4j.appender.MAIN.layout.ConversionPattern=%r %-5p %c %x - %m%nlog4j.appender.ROLLING=org.apache.log4j.RollingFileAppenderlog4j.appender.ROLLING.File=/var/log/sematext/awesome.loglog4j.appender.ROLLING.MaxFileSize=1024KBlog4j.appender.ROLLING.MaxBackupIndex=10log4j.appender.ROLLING.layout=org.apache.log4j.PatternLayoutlog4j.appender.ROLLING.layout.ConversionPattern=%r %-5p %c %x - %m%n
Unser Root-Logger ist so konfiguriert, dass er alles ab dem DEBUG–Schweregrad protokolliert und die Protokolle an zwei Appender sendet – den HAUPT- und den ROLLING. Der Hauptlogger ist derjenige, den wir bereits gesehen haben – derjenige, der die Daten an die Konsole sendet.
Der zweite Logger, der ROLLING genannt wird, ist in diesem Beispiel der interessantere. Es verwendet den RollingFileAppender, der die Daten in die Datei schreibt und definiert, wie groß die Datei sein kann und wie viele Dateien aufbewahrt werden sollen. In unserem Fall sollten die Protokolldateien awesome genannt werden.protokollieren und schreiben Sie die Daten in das Verzeichnis /var/log/sematext/. Jede Datei sollte maximal 1024 KB groß sein und nicht mehr als 10 Dateien gespeichert sein. Wenn mehr Dateien vorhanden sind, werden sie aus dem Dateisystem entfernt, sobald log4j sie sieht.
Nach dem Ausführen des Codes mit der obigen Konfiguration druckt die Konsole den folgenden Inhalt:
0 INFO com.sematext.blog.ExampleAppenders - Starting ExampleAppenders application1 WARN com.sematext.blog.ExampleAppenders - Ending ExampleAppenders application
In der Datei /var/log/sematext/awesome.protokolldatei, die wir sehen würden:
0 INFO com.sematext.blog.ExampleAppenders - Starting ExampleAppenders application1 WARN com.sematext.blog.ExampleAppenders - Ending ExampleAppenders application
Appender Log Level
Das Schöne an Appendern ist, dass sie ihre Ebene haben können, die bei der Protokollierung berücksichtigt werden sollte. Alle Beispiele, die wir bisher gesehen haben, protokollierten jede Nachricht mit dem Schweregrad DEBUG oder höher. Was wäre, wenn wir das für alle Klassen in der com ändern wollten.semantik.blog-Paket? Wir müssten nur unsere Datei log4j.properties ändern:
log4j.rootLogger=DEBUG, MAINlog4j.appender.MAIN=org.apache.log4j.ConsoleAppenderlog4j.appender.MAIN.layout=org.apache.log4j.PatternLayoutlog4j.appender.MAIN.layout.ConversionPattern=%r %-5p %c %x - %m%nlog4j.logger.com.sematext.blog=WARN
Schauen Sie sich die letzte Zeile in der obigen Konfigurationsdatei an. Wir haben das Präfix log4j.logger verwendet und gesagt, dass der Logger com heißt.semantik.blog sollte nur für die Schweregrade WARN und höher verwendet werden, also FEHLER und FATAL.
Unser Beispielanwendungscode sieht folgendermaßen aus:
public static void main(String args) { LOGGER.info("Starting ExampleAppenderLevel application"); LOGGER.warn("Ending ExampleAppenderLevel application");}
Mit der obigen Log4j-Konfiguration sieht die Ausgabe der Protokollierung wie folgt aus:
0 WARN com.sematext.blog.ExampleAppenderLevel - Ending ExampleAppenderLevel application
Wie Sie sehen können, war nur das WARN Level Log enthalten. Genau das wollten wir.
Log4j–Layouts
Schließlich der Teil des Log4j-Protokollierungsframeworks, der die Struktur unserer Daten in unserer Protokolldatei steuert – das Layout. Log4j bietet einige Standardimplementierungen wie PatternLayout, SimpleLayout, XMLLayout, HTMLLayout, EnchancedPatternLayout und DateLayout .
In den meisten Fällen wird das PatternLayout auftreten. Die Idee hinter diesem Layout ist, dass Sie eine Vielzahl von Formatierungsoptionen bereitstellen können, um die Struktur der Protokolle zu definieren. Einige der Beispiele sind:
- d – Datum und Uhrzeit des Protokollereignisses,
- m – dem Protokollereignis zugeordnete Nachricht,
- t – Thread-Name,
- n – plattformabhängiges Zeilentrennzeichen,
- p – Protokollebene.
Weitere Informationen zu den verfügbaren Optionen finden Sie in den offiziellen Log4j-Javadocs für das PatternLayout.
Wenn wir das PatternLayout verwenden, können wir konfigurieren, welche Option wir verwenden möchten. Nehmen wir an, wir möchten das Datum, den Schweregrad des Protokollereignisses, den von eckigen Klammern umgebenen Thread und die Nachricht des Protokollereignisses schreiben. Wir könnten ein Muster wie dieses verwenden:
%d %-5p - %m%n
Die vollständige Datei log4j.properties könnte in diesem Fall wie folgt aussehen:
log4j.rootLogger=DEBUG, MAINlog4j.appender.MAIN=org.apache.log4j.ConsoleAppenderlog4j.appender.MAIN.layout=org.apache.log4j.PatternLayoutlog4j.appender.MAIN.layout.ConversionPattern=%d %-5p - %m%n
Wir verwenden %d, um das Datum anzuzeigen, % -5p, um den Schweregrad mit 5 Zeichen anzuzeigen, % t für Thread, % m für die Nachricht und % n für Zeilentrennzeichen. Die Ausgabe, die nach dem Ausführen unseres Beispielcodes in die Konsole geschrieben wird, sieht wie folgt aus:
2021-02-02 11:49:49,003 INFO - Initializing ExampleLog4jFormatter application
Verschachtelter Diagnosekontext
In den meisten realen Anwendungen existiert das Protokollereignis nicht für sich. Es ist von einem bestimmten Kontext umgeben. Um einen solchen Kontext pro Thread bereitzustellen, stellt Log4j den sogenannten verschachtelten Diagnosekontext bereit. Auf diese Weise können wir einen bestimmten Thread mit zusätzlichen Informationen binden, z. B. einer Sitzungskennung, genau wie in unserer Beispielanwendung:
NDC.push(String.format("Session ID: %s", "1234-5678-1234-0987"));LOGGER.info("Initializing ExampleLog4jNDC application");
Wenn Sie ein Muster verwenden, das die Variable x enthält, werden in jeder Protokollzeile für den angegebenen Thread zusätzliche Informationen enthalten sein. In unserem Fall sieht die Ausgabe folgendermaßen aus:
0 INFO com.sematext.blog.ExampleLog4jNDC Session ID: 1234-5678-1234-0987 - Initializing ExampleLog4jNDC application
Sie können sehen, dass sich die Informationen zur Sitzungskennung in der Protokollzeile befinden. Nur als Referenz sieht die Datei log4j.properties, die wir in diesem Beispiel verwendet haben, wie folgt aus:
log4j.rootLogger=DEBUG, MAINlog4j.appender.MAIN=org.apache.log4j.ConsoleAppenderlog4j.appender.MAIN.layout=org.apache.log4j.PatternLayoutlog4j.appender.MAIN.layout.ConversionPattern=%r %-5p %c %x - %m%n
Zugeordneter Diagnosekontext
Die zweite Art von Kontextinformationen, die wir in unsere Protokollereignisse aufnehmen können, ist der zugeordnete Diagnosekontext. Mit der MDC-Klasse können wir zusätzliche schlüsselwertbezogene Informationen bereitstellen. Ähnlich wie der verschachtelte Diagnosekontext ist der zugeordnete Diagnosekontext threadgebunden.
Schauen wir uns unseren Beispielanwendungscode an:
MDC.put("user", "[email protected]");MDC.put("step", "initial");LOGGER.info("Initializing ExampleLog4jNDC application");MDC.put("step", "launch");LOGGER.info("Starting ExampleLog4jNDC application");
Wir haben zwei Kontextfelder – den Benutzer und den Schritt. Um alle zugeordneten Diagnosekontextinformationen anzuzeigen, die mit dem Protokollereignis verknüpft sind, verwenden wir einfach die Variable X in unserer Musterdefinition. Zum Beispiel:
log4j.rootLogger=DEBUG, MAINlog4j.appender.MAIN=org.apache.log4j.ConsoleAppenderlog4j.appender.MAIN.layout=org.apache.log4j.PatternLayoutlog4j.appender.MAIN.layout.ConversionPattern=%r %-5p %c %X - %m%n
Das Starten des obigen Codes zusammen mit der Konfiguration würde zu der folgenden Ausgabe führen:
0 INFO com.sematext.blog.ExampleLog4jMDC {{step,initial}{user,[email protected]}} - Initializing ExampleLog4jNDC application1 INFO com.sematext.blog.ExampleLog4jMDC {{step,launch}{user,[email protected]}} - Starting ExampleLog4jNDC application
Wir können auch auswählen, welche Informationen verwendet werden sollen, indem wir das Muster ändern. Um beispielsweise den Benutzer aus dem zugeordneten Diagnosekontext einzuschließen, könnten wir ein Muster wie dieses schreiben:
%r %-5p %c %X{user} - %m%n
Dieses Mal würde die Ausgabe wie folgt aussehen:
0 INFO com.sematext.blog.ExampleLog4jMDC [email protected] - Initializing ExampleLog4jNDC application0 INFO com.sematext.blog.ExampleLog4jMDC [email protected] - Starting ExampleLog4jNDC application
Sie können sehen, dass wir anstelle des allgemeinen %X %X{user} verwendet haben. Das bedeutet, dass wir an der Benutzervariablen aus dem zugeordneten Diagnosekontext interessiert sind, der einem bestimmten Protokollereignis zugeordnet ist.
Migration zu Log4j 2
Migration von Log4j 1.x zu Log4j 2.x ist nicht schwer und in einigen Fällen kann es sehr einfach sein. Wenn Sie kein internes Log4j 1 verwendet haben.x-Klassen, Sie haben Konfigurationsdateien über das programmgesteuerte Einrichten von Loggern verwendet und die DOMConfigurator- und PropertyConfigurator-Klassen nicht verwendet Die Migration sollte so einfach sein wie das Einbeziehen der log4j-1.2-api.jar JAR-Datei anstelle des Log4j 1.x JAR-Dateien. Das würde Log4j 2 erlauben.x, um mit Ihrem Code zu arbeiten. Sie müssten das Log4j 2 hinzufügen.x JAR-Dateien, passen Sie die Konfiguration an und voilà – fertig.
Wenn Sie mehr über Log4j 2 erfahren möchten.x schauen Sie sich unser Java Logging Tutorial und sein Log4j 2 an.x gewidmet abschnitt.
Wenn Sie jedoch internes Log4j 1 verwendet haben.x-Klassen, der offizielle Migrationsleitfaden zum Wechsel von Log4j 1.x zu Log4j 2.x wird sehr hilfreich sein. Es beschreibt die erforderlichen Code- und Konfigurationsänderungen und ist im Zweifelsfall von unschätzbarem Wert.
Zentralisierte Protokollierung mit Protokollverwaltungstools
Das Senden von Protokollereignissen an eine Konsole oder eine Datei kann für eine einzelne Anwendung gut sein, aber das Behandeln mehrerer Instanzen Ihrer Anwendung und das Korrelieren der Protokolle aus mehreren Quellen macht keinen Spaß, wenn sich die Protokollereignisse in Textdateien auf verschiedenen Computern befinden. In solchen Fällen wird die Datenmenge schnell unüberschaubar und erfordert dedizierte Lösungen – entweder selbst gehostet oder von einem der Anbieter. Und was ist mit Containern, in denen Sie normalerweise nicht einmal Protokolle in Dateien schreiben? Wie beheben und debuggen Sie eine Anwendung, deren Protokolle an die Standardausgabe ausgegeben wurden oder deren Container beendet wurde?
Hier kommen Protokollverwaltungsdienste, Protokollanalysetools und Cloud-Protokollierungsdienste ins Spiel. Es ist eine ungeschriebene Java Logging Best Practice unter Ingenieuren, solche Lösungen zu verwenden, wenn Sie es ernst meinen, Ihre Protokolle zu verwalten und das Beste aus ihnen herauszuholen. Zum Beispiel löst Sematext Logs, unsere Protokollüberwachungs- und Verwaltungssoftware, alle oben genannten Probleme und vieles mehr.
Mit einer vollständig verwalteten Lösung wie Sematext Logs müssen Sie keinen weiteren Teil der Umgebung verwalten – Ihre DIY-Protokollierungslösung, die normalerweise aus Teilen des Elastic Stack besteht. Solche Setups können klein und billig beginnen, Sie werden jedoch oft groß und teuer. Nicht nur in Bezug auf die Infrastrukturkosten, sondern auch in Bezug auf die Verwaltungskosten. Wissen Sie, Zeit und Gehaltsabrechnung. Wir erklären mehr über die Vorteile der Verwendung eines Managed Service in unserem Blogbeitrag über Best Practices für die Protokollierung.
Alarmierung und Log-Aggregation sind auch bei Problemen von entscheidender Bedeutung. Für Java-Anwendungen möchten Sie möglicherweise Garbage Collection-Protokolle haben, sobald Sie die Garbage Collection-Protokollierung aktivieren und mit der Analyse der Protokolle beginnen. Solche mit Metriken korrelierten Protokolle sind eine unschätzbare Informationsquelle für die Fehlerbehebung bei Problemen im Zusammenhang mit der Garbage Collection.
Zusammenfassung
Obwohl Log4j 1.x hat vor langer Zeit sein Lebensende erreicht Es ist immer noch in einer großen Anzahl von Legacy-Anwendungen vorhanden, die auf der ganzen Welt verwendet werden. Die Migration auf die jüngere Version ist recht einfach, erfordert jedoch möglicherweise erhebliche Ressourcen und Zeit und hat normalerweise keine oberste Priorität. Insbesondere in großen Unternehmen, in denen die Verfahren, gesetzlichen Anforderungen oder beides Audits erfordern, gefolgt von langen und teuren Tests, bevor an einem bereits laufenden System etwas geändert werden kann. Aber für diejenigen von uns, die gerade erst anfangen oder über Migration nachdenken – denken Sie daran, Log4j 2.x ist da, es ist bereits ausgereift, schnell, sicher und sehr leistungsfähig.
Unabhängig von dem Framework, das Sie für die Protokollierung Ihrer Java-Anwendungen verwenden, empfehlen wir auf jeden Fall, Ihre Bemühungen mit einer vollständig verwalteten Protokollverwaltungslösung wie Sematext Logs zu verbinden. Probieren Sie es aus! Es gibt eine 14-tägige kostenlose Testversion für Sie, um es zu testen.
Viel Spaß beim Protokollieren!