Gennemsøgning med Python

gennemsøgning er en kraftfuld teknik til at indsamle data fra internettet ved at finde alle URL ‘ er til et eller flere domæner. Python har flere populære Internet gennemsøgning biblioteker og rammer.
i denne artikel introducerer vi først Forskellige gennemsøgningsstrategier og brugssager. Derefter bygger vi en simpel banekrydser fra bunden i Python ved hjælp af to biblioteker: anmodninger og smuk suppe. Dernæst vil vi se, hvorfor det er bedre at bruge en gennemsøgningsramme som Scrapy. Endelig vil vi bygge et eksempel larvebånd med Scrapy at indsamle film metadata fra IMDb og se, hvordan Scrapy skalaer til hjemmesider med flere millioner sider.
hvad er en larvebånd?
gennemsøgning og skrabning på nettet er to forskellige, men beslægtede begreber. Gennemsøgning på nettet er en komponent i skrabning på nettet, larvelogikken finder URL ‘ er, der skal behandles af skraberkoden.
en internetsøgemaskine starter med en liste over URL ‘ er, der skal besøges, kaldet frøet. For hver URL finder søgeren links i HTML ‘ en, filtrerer disse links baseret på nogle kriterier og tilføjer de nye links til en kø. Al HTML eller nogle specifikke oplysninger udvindes for at blive behandlet af en anden pipeline.
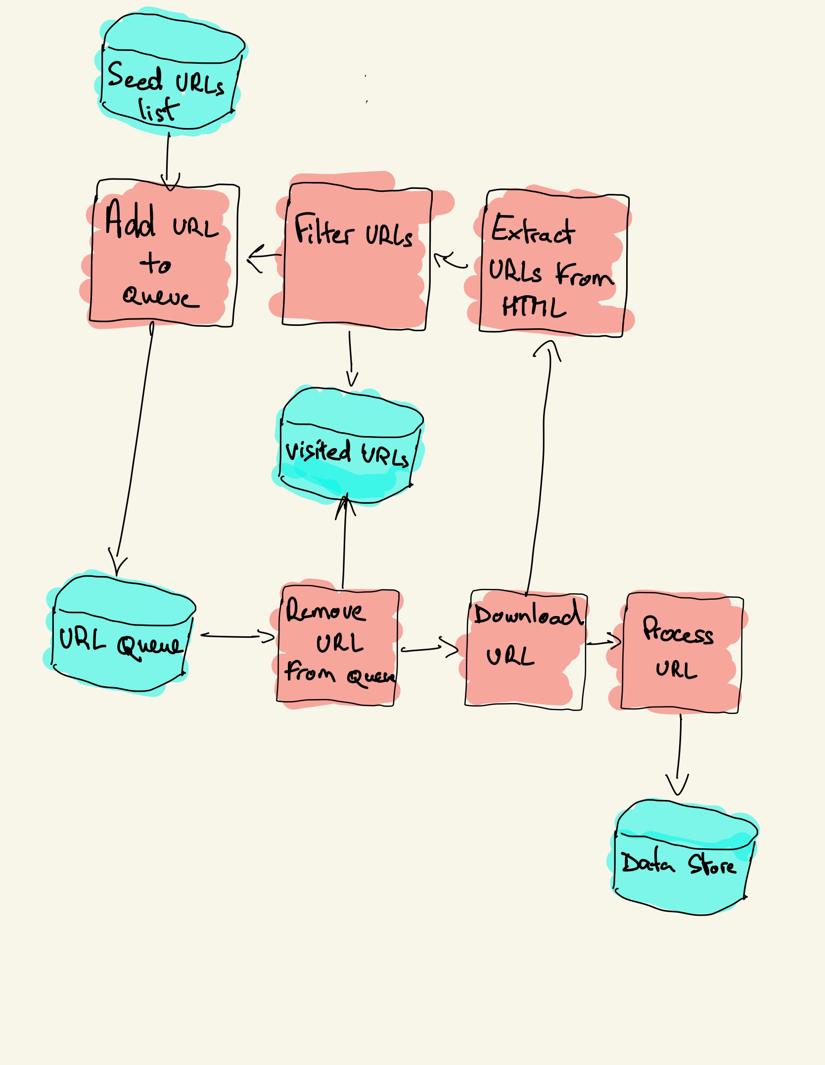
søgestrategier
i praksis besøger søgere kun en delmængde af sider afhængigt af søgebudgettet, som kan være et maksimalt antal sider pr.domæne, dybde eller eksekveringstid.
mest populære hjemmesider giver en robotter.for at angive, hvilke områder af hjemmesiden der ikke er tilladt at gennemgå af hver brugeragent. Det modsatte af robotfilen er sitemap.der viser de sider, der kan gennemsøges.
populære sager til brug af larvebånd inkluderer:
- søgemaskiner (Googlebot, Bingbot, Yandeks Bot…) indsamle alle HTML for en væsentlig del af internettet. Disse data er indekseret for at gøre det søgbart.
- SEO-analyseværktøjer ud over at indsamle HTML indsamler også metadata som responstid, responsstatus for at registrere ødelagte sider og linkene mellem forskellige domæner for at indsamle backlinks.
- pris overvågning værktøjer gennemgå e-handel hjemmesider for at finde produktsider og udtrække metadata, især prisen. Produktsider revideres derefter med jævne mellemrum.
- almindelig gennemgang opretholder et åbent lager af internetgennemsøgningsdata. For eksempel indeholder arkivet fra oktober 2020 2,71 milliarder hjemmesider.
Dernæst vil vi sammenligne tre forskellige strategier til opbygning af en internetspor i Python. Først ved kun at bruge standardbiblioteker, derefter tredjepartsbiblioteker til at lave HTTP-anmodninger og analysere HTML og endelig en ramme til gennemsøgning af internettet.
opbygning af et simpelt internetspor i Python fra bunden
for at opbygge et simpelt internetspor i Python har vi brug for mindst et bibliotek for at hente HTML fra en URL og et HTML-parsing-bibliotek for at udtrække links. Python giver standard biblioteker urllib for at gøre HTTP-anmodninger og html.parser til parsing HTML. Et eksempel på Python-larvebånd, der kun er bygget med standardbiblioteker, findes på Github.
standard Python biblioteker for anmodninger og HTML parsing er ikke meget udvikler-venlige. Andre populære biblioteker som anmodninger, mærket som HTTP for mennesker, og smuk suppe giver en bedre udvikleroplevelse.
hvis du vil lære mere, kan du tjekke denne vejledning om den bedste Python HTTP-klient.
du kan installere de to biblioteker lokalt.
pip install requests bs4en grundlæggende larvebånd kan bygges efter det foregående arkitekturdiagram.
import loggingfrom urllib.parse import urljoinimport requestsfrom bs4 import BeautifulSouplogging.basicConfig( format='%(asctime)s %(levelname)s:%(message)s', level=logging.INFO)class Crawler: def __init__(self, urls=): self.visited_urls = self.urls_to_visit = urls def download_url(self, url): return requests.get(url).text def get_linked_urls(self, url, html): soup = BeautifulSoup(html, 'html.parser') for link in soup.find_all('a'): path = link.get('href') if path and path.startswith('/'): path = urljoin(url, path) yield path def add_url_to_visit(self, url): if url not in self.visited_urls and url not in self.urls_to_visit: self.urls_to_visit.append(url) def crawl(self, url): html = self.download_url(url) for url in self.get_linked_urls(url, html): self.add_url_to_visit(url) def run(self): while self.urls_to_visit: url = self.urls_to_visit.pop(0) logging.info(f'Crawling: {url}') try: self.crawl(url) except Exception: logging.exception(f'Failed to crawl: {url}') finally: self.visited_urls.append(url)if __name__ == '__main__': Crawler(urls=).run()koden ovenfor definerer en Bælteklasse med hjælpemetoder til at hente ved hjælp af anmodningsbiblioteket, get_linked_urls ved hjælp af det smukke Suppebibliotek og add_url_to_visit for at filtrere URL ‘ er. De URL ‘er, der skal besøges, og de besøgte URL’ er gemmes i to separate lister. Du kan køre Larvebånd på din terminal.
python crawler.pylarven logger en linje for hver besøgt URL.
2020-12-04 18:10:10,737 INFO:Crawling: https://www.imdb.com/2020-12-04 18:10:11,599 INFO:Crawling: https://www.imdb.com/?ref_=nv_home2020-12-04 18:10:12,868 INFO:Crawling: https://www.imdb.com/calendar/?ref_=nv_mv_cal2020-12-04 18:10:13,526 INFO:Crawling: https://www.imdb.com/list/ls016522954/?ref_=nv_tvv_dvd2020-12-04 18:10:19,174 INFO:Crawling: https://www.imdb.com/chart/top/?ref_=nv_mv_2502020-12-04 18:10:20,624 INFO:Crawling: https://www.imdb.com/chart/moviemeter/?ref_=nv_mv_mpm2020-12-04 18:10:21,556 INFO:Crawling: https://www.imdb.com/feature/genre/?ref_=nv_ch_grkoden er meget enkel, men der er mange problemer med ydeevne og brugervenlighed, der skal løses, før du med succes gennemsøger en komplet hjemmeside.
- larven er langsom og understøtter ingen parallelitet. Som det fremgår af tidsstemplerne, tager det cirka et sekund at gennemgå hver URL. Hver gang kravlen fremsætter en anmodning, venter den på, at anmodningen løses, og der udføres intet Arbejde imellem.
- Hent URL-logikken har ingen prøvemekanisme, URL-køen er ikke en rigtig kø og ikke særlig effektiv med et stort antal URL ‘ er.
- linkekstraktionslogikken understøtter ikke standardisering af URL ‘er ved at fjerne URL-forespørgselsstrengparametre, håndterer ikke URL’ er, der starter med#, understøtter ikke filtrering af URL ‘ er efter domæne eller filtrering af anmodninger til statiske filer.
- larven identificerer sig ikke og ignorerer robotterne.tekstfil.
Dernæst vil vi se, hvordan Scrapy leverer alle disse funktionaliteter og gør det nemt at udvide til dine brugerdefinerede gennemsøgninger.
netsøgning med Scrapy
Scrapy er den mest populære ramme for skrabning og gennemsøgning af Python med 40K stjerner på Github. En af fordelene ved Scrapy er, at anmodninger planlægges og håndteres asynkront. Dette betyder, at Scrapy kan sende en anden anmodning, før den forrige er afsluttet eller udføre noget andet arbejde imellem. Scrapy kan håndtere mange samtidige anmodninger, men kan også konfigureres til at respektere hjemmesider med brugerdefinerede indstillinger, som vi vil se senere.
Scrapy har en multikomponentarkitektur. Normalt implementerer du mindst to forskellige klasser: Spider og Pipeline. Skrabning på nettet kan betragtes som en ETL, hvor du udtrækker data fra internettet og indlæser dem til dit eget lager. Edderkopper udtrække data og rørledninger indlæse den i lageret. Transformation kan ske både i edderkopper og rørledninger, men jeg anbefaler, at du indstiller en brugerdefineret Scrapy-rørledning til at transformere hvert element uafhængigt af hinanden. På denne måde har manglende behandling af en vare ingen effekt på andre varer.
oven i alt det, kan du tilføje spider og hent mellemvare mellem komponenter, som det kan ses i diagrammet nedenfor.
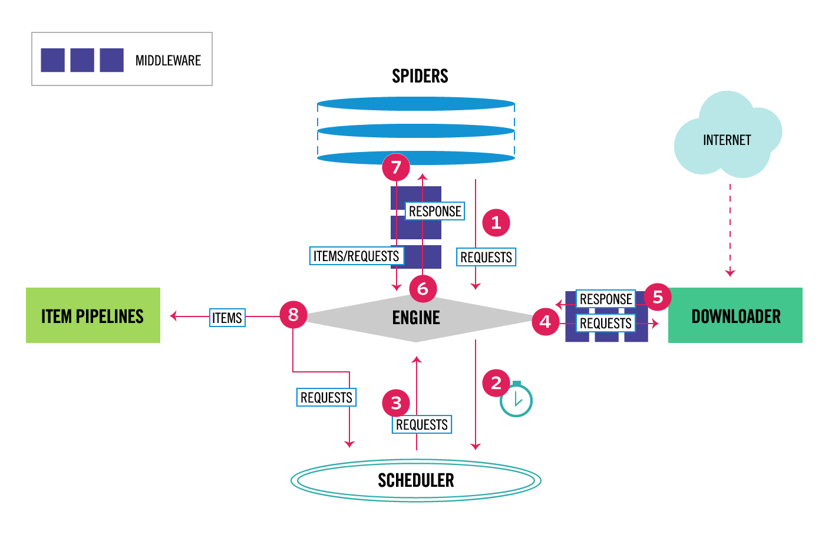
Scrapy Architecture oversigt
hvis du har brugt Scrapy før, ved du, at en baneskraber er defineret som en klasse, der arver fra base Spider-klassen og implementerer en parse-metode til at håndtere hvert svar. Hvis du er ny til Scrapy, kan du læse denne artikel for nem skrabning med Scrapy.
from scrapy.spiders import Spiderclass ImdbSpider(Spider): name = 'imdb' allowed_domains = start_urls = def parse(self, response): passScrapy tilbyder også flere generiske edderkoppeklasser: Csvfeedspider, Csvfeedspider og SitemapSpider. Klassen arver fra Base Spider-klassen og giver en ekstra regelattribut til at definere, hvordan man gennemsøger en hjemmeside. Hver regel bruger en Linkekstraktor til at specificere, hvilke links der udvindes fra hver side. Dernæst vil vi se, hvordan du bruger hver enkelt af dem ved at opbygge en Larvebånd til IMDb, Internet Movie Database.
opbygning af et eksempel Scrapy Larvebånd til IMDb
før jeg prøvede at gennemgå IMDb, kontrollerede jeg IMDb-robotter.for at se, hvilke URL-stier der er tilladt. Robots-filen tillader kun 26 stier for alle brugeragenter. Scrapy læser robotterne.fil på forhånd og respekterer det, når indstillingen ROBOTSTH_OBEY er indstillet til sand. Dette er tilfældet for alle projekter genereret med Scrapy-kommandoen startproject.
scrapy startproject scrapy_crawlerdenne kommando opretter et nyt projekt med standard Scrapy projektmappestruktur.
scrapy_crawler/├── scrapy.cfg└── scrapy_crawler ├── __init__.py ├── items.py ├── middlewares.py ├── pipelines.py ├── settings.py └── spiders ├── __init__.pyderefter kan du oprette en edderkop i scrapy_crawler/spiders/imdb.py med en regel for at udtrække alle links.
from scrapy.spiders import CrawlSpider, Rulefrom scrapy.linkextractors import LinkExtractorclass ImdbCrawler(CrawlSpider): name = 'imdb' allowed_domains = start_urls = rules = (Rule(LinkExtractor()),)du kan starte larven i terminalen.
scrapy crawl imdb --logfile imdb.logDu får masser af logfiler, inklusive en log for hver anmodning. Udforskning af logfilerne jeg bemærkede, at selvom vi satte tilladed_domains til kun at gennemgå hjemmesider under https://www.imdb.com, var der anmodninger om eksterne domæner, såsom amazon.com.
2020-12-06 12:25:18 DEBUG: Redirecting (302) to <GET https://www.amazon.com/b/?&node=5160028011&ref_=ft_iba> from <GET (https://www.imdb.com/whitelist-offsite?url=https%3A%2F%2Fwww.amazon.com%2Fb%2F%3F%26node%3D5160028011%26ref_%3Dft_iba&page-action=ft-iba&ref=ft_iba)>IMDb omdirigerer fra URL-stier under hvidliste-offsite og hvidliste til eksterne domæner. Der er et åbent Scrapy Github-problem, der viser, at eksterne URL ‘ er ikke bliver filtreret ud, når Offsitemiddle-programmet anvendes før Redirectmiddle-programmet. For at løse dette problem kan vi konfigurere linkekstraktoren til at nægte URL ‘ er startende med to regulære udtryk.
class ImdbCrawler(CrawlSpider): name = 'imdb' allowed_domains = start_urls = rules = ( Rule(LinkExtractor( deny=, )), )regel-og Linkekstraktorklasser understøtter flere argumenter for at filtrere URL ‘ er ud. Du kan f.eks. ignorere specifikke URL-udvidelser og reducere antallet af dublerede URL ‘ er ved at sortere forespørgselsstrenge. Hvis du ikke finder et specifikt argument for din brugssag, kan du overføre en brugerdefineret funktion til process_links i Linkekstraktor eller process_values i regel.
for eksempel har IMDb to forskellige URL ‘ er med det samme indhold.
https://www.imdb.com/navn / nm1156914/
https://www.imdb.com/navn / nm1156914/?mode = desktop&ref_=m_ft_dsk
for at begrænse antallet af gennemsøgte URL ‘er kan vi fjerne alle forespørgselsstrenge fra URL’ er med funktionen url_cleaner fra biblioteket og bruge den i process_links.
from w3lib.url import url_query_cleanerdef process_links(links): for link in links: link.url = url_query_cleaner(link.url) yield linkclass ImdbCrawler(CrawlSpider): name = 'imdb' allowed_domains = start_urls = rules = ( Rule(LinkExtractor( deny=, ), process_links=process_links), )nu hvor vi har begrænset antallet af anmodninger, der skal behandles, kan vi tilføje en parse_item-metode til at udtrække data fra hver side og videregive dem til en pipeline for at gemme dem. For eksempel kan vi enten udtrække hele svaret.tekst til at behandle det i en anden pipeline eller vælge HTML-metadata. For at vælge HTML-metadataene i header-tagget kan vi kode vores egne stier, men jeg finder det bedre at bruge et bibliotek, ekstruct, der udtrækker alle metadata fra en HTML-side. Du kan installere det med pip install uddrag.
import refrom scrapy.linkextractors import LinkExtractorfrom scrapy.spiders import CrawlSpider, Rulefrom w3lib.url import url_query_cleanerimport extructdef process_links(links): for link in links: link.url = url_query_cleaner(link.url) yield linkclass ImdbCrawler(CrawlSpider): name = 'imdb' allowed_domains = start_urls = rules = ( Rule( LinkExtractor( deny=, ), process_links=process_links, callback='parse_item', follow=True ), ) def parse_item(self, response): return { 'url': response.url, 'metadata': extruct.extract( response.text, response.url, syntaxes= ), }jeg indstiller følgende attribut til sand, så Scrapy stadig følger alle links fra hvert svar, selvom vi leverede en brugerdefineret parse-metode. Jeg konfigurerede også ekstruct til kun at udtrække Open Graph metadata og JSON-LD, en populær metode til kodning af sammenkædede data ved hjælp af JSON på nettet, brugt af IMDb. Du kan køre overvågningen og gemme elementer i JSON lines-format til en fil.
scrapy crawl imdb --logfile imdb.log -o imdb.jl -t jsonlinesoutputfilen imdb.jl indeholder en linje for hver gennemsøgt vare. For eksempel ser de udpakkede Open Graph-metadata for en film taget fra <meta> tags i HTML sådan ud.
{ "url": "http://www.imdb.com/title/tt2442560/", "metadata": {"opengraph": , , , , , ] }]}}JSON-LD for en enkelt vare er for lang til at blive inkluderet i artiklen, her er en prøve af, hvad Scrapy uddrag fra <script type=”application/ld+json”> tag.
"json-ld": , "contentRating": "TV-MA", "actor": ... }]når jeg udforskede logfilerne, bemærkede jeg et andet almindeligt problem med krybere. Ved sekventielt at klikke på filtre genererer larvebånd URL ‘ er med det samme indhold, kun at filtrene blev anvendt i en anden rækkefølge.
https://www.imdb.com/navn / nm2900465 / videogalleri / content_type-trailer / related_titles-tt0479468
https://www.imdb.com/navn / nm2900465 / videogallery/related_titles-tt0479468 / content_type-trailer
langt filter og Søgeadresser er et vanskeligt problem, der delvist kan løses ved at begrænse længden af URL ‘ er med en Scrapy indstilling, URLLENGTH_LIMIT.
jeg brugte IMDb som et eksempel for at vise det grundlæggende ved at bygge en banebaner i Python. Jeg lod ikke krybben køre længe, da jeg ikke havde en bestemt brugssag til dataene. Hvis du har brug for specifikke data fra IMDb, kan du kontrollere IMDb Datasets-projektet, der giver en daglig eksport af IMDb-data og IMDbPY, en Python-pakke til hentning og styring af dataene.
internetsøgning i skala
hvis du forsøger at gennemgå en stor hjemmeside som IMDb, med over 45m sider baseret på Google, er det vigtigt at gennemgå ansvarligt ved at konfigurere følgende indstillinger. Du kan identificere din larvebånd og angive kontaktoplysninger i BOT_NAME-indstillingen. For at begrænse det pres, du lægger på hjemmesidens servere, kan du øge overførslen, begrænse den samtidige anmodning eller indstille AUTOTHROTTLE_ENABLED, der vil tilpasse disse indstillinger dynamisk baseret på svartiderne fra serveren.
Bemærk, at Scrapy-gennemsøgninger som standard er optimeret til et enkelt domæne. Hvis du gennemsøger flere domæner, skal du kontrollere disse indstillinger for at optimere til brede gennemsøgninger, herunder ændre standard gennemsøgningsrækkefølgen fra dybde-først til åndedræt-først. For at begrænse dit gennemsøgningsbudget kan du begrænse antallet af anmodninger med indstillingen CLOSESPIDER_PAGECOUNT i udvidelsen close spider.
med standardindstillingerne gennemsøger Scrapy omkring 600 sider i minuttet for en hjemmeside som IMDb. For at gennemgå 45m sider vil det tage mere end 50 dage for en enkelt robot. Hvis du har brug for at gennemgå flere hjemmesider, kan det være bedre at starte separate gennemsøgere for hver stor hjemmeside eller gruppe af hjemmesider. Hvis du er interesseret i distribuerede gennemsøgninger, kan du læse, hvordan en udvikler gennemsøgte 250m sider med Python på 40 timer ved hjælp af 20 EC2-maskinforekomster.
i nogle tilfælde kan du løbe ind på hjemmesider, der kræver, at du udfører JavaScript-kode for at gengive al HTML. Undlader at gøre det, og du må ikke indsamle alle links på hjemmesiden. Fordi i dag er det meget almindeligt for hjemmesider at gengive indhold dynamisk i bro. ser skrev jeg en Scrapy mellemvare til rendering JavaScript-sider ved hjælp af ScrapingBee API.
konklusion
vi sammenlignede koden til en Python-larvebånd ved hjælp af tredjepartsbiblioteker til at hente URL ‘ er og analysere HTML med en larvebånd bygget ved hjælp af en populær ramme til gennemsøgning af internettet. Scrapy er en meget effektiv ramme for gennemsøgning af nettet, og det er nemt at udvide med din brugerdefinerede kode. Men du skal kende alle de steder, hvor du kan tilslutte din egen kode og indstillingerne for hver komponent.
konfiguration af Scrapy korrekt bliver endnu vigtigere, når du gennemsøger hjemmesider med millioner af sider. Hvis du vil vide mere om internetsøgning, foreslår jeg, at du vælger en populær hjemmeside og forsøger at gennemgå den. Du vil helt sikkert løbe ind i nye problemer, hvilket gør emnet fascinerende!